Python修炼之路-模块
模块
模块与包
模块:用来从逻辑上组织python代码(可以定义变量、函数、类、逻辑:实现一个功能),本质就是.py结尾的python文件。
例如,文件名:test.py,对应的模块名为:test
包:用来从逻辑上组织模块的,本质就是一个目录(必须带有一个__init__.py文件)
导入方法
import 语句
import moudle_name; # 导入模块
import moudle_name,moudle_name2... # 导入多个模块
导入模块后,可以使用全限定名称访问模块中定义的成员:
模块名.函数名/变量名 # 使用包含模块的全限定名称调用模块中的成员
from ... import 语句
from moudle_name import 成员名 # 导入模块中的具体成员
from moudle_name import 成员名1,成员名2... # 导入模块中的多个成员
from moudle_name import * # 导入模块中的所有成员(变量,函数等)
from moudle_name import 成员名 as new_成员名 # 调用时使用new_成员名
导入后可以直接调用:
成员名 # 直接调用成员名,无需加上模块名
注意:
from...import可以简化代码,但不建议使用,因为可能导致名称冲突:导入多个模块时,模块中可能存在同一个名称的函数,或者模块的函数和主函数定义的函数同名;同时程序可读性差,无法准确定位某个名称的函数属于哪个模块。
import本质
导入模块的本质:就是把python文件解释一遍。
import moudle_name 相当于把该模块内的成员(变量、函数等)赋值给变量moudle_name(moudle_name = "moudle_name.py all code"),所以需要通过变量moudle来调用成员:moudle_name.函数名/变量名
from moudle_name import 成员名 相当于直接导入成员(成员名="code"),然后可以直接调用。
导入包的本质:就是解释执行包下面的__init__.py文件
import 包名.模块名 #导入包中的模块
导入包中的模块后,可以使用全限定名称访问包中模块定义的成员: 包名.模块名.函数名
from 包名.模块名 import 成员名 # 导入模块中的具体成员
from 包名 import * # 导入包中的所有模块
导入包也可以修改__init__.py文件,在文件中添加from . import 包下面的模块名
# 包里面包括__init__.py和模块test.py
__init__.py文件 from . import test # 其他文件导入包
import 包名
包名.test.方法
路径搜索:import moudle_name --->moudle_name.py --->moudle_name.py的路径---> sys.path
from . import 成员名 # .为当前路径,__init__.py文件的当前路径
包、模块的导入,要考虑好包或模块的路径(目录):同一个包的模块,可以直接导入相同包的模块,因为他们位于同一个目录。
导入优化
from moudle_name import 成员 指定导入成员名,优化来回检索成员名
动态导入模块
可以以字符串形式导入模块,建议使用importlib.import_moudle导入
# -*-coding:utf-8 -*-
#
# from dy_lib import aa
# obj = aa.Foo()
# print(obj.name)
#
# lib = __import__('dy_lib.aa') # 相当于导入了dy_lib
# obj = lib.aa.Foo()
# print(obj.name) import importlib
aa =importlib.import_module('dy_lib.aa')
obj = aa.Foo()
print(obj.name)
模块的分类:标准库(内置模块)、开源模块、自定义模块。
getpass
python3.x中用户输入函数input(),相当于python2.x中的raw_input()函数。
getpass模块中的getpass函数可用于读取密码,当用户输入密码时,不会和input()那样显现输入内容,但是在PyCharm运行会出问题。
import getpass
name = input("please input your name:" )
passwd = getpass.getpass("please input your password")
time与datetime
time
时间戳:以自从1970年1月1日午夜(历元)经过了多长秒来表示。
格式化的字符串:2017-11-28 13:52:36
结构化时间:元组的形式,包括年月日等九大元素
| 索引 | 字段 | 值 | 属性 |
| 0 | 4位年数 | 2017 | tm_year |
| 1 | 月 | 1-12 | tm_mon |
| 2 | 日 | 1-31 | tm_mday |
| 3 | 时 | 0-23 | tm_hour |
| 4 | 分 | 0-59 | tm_min |
| 5 | 秒 | 0-61(闰秒) | tm_sec |
| 6 | 一周的第几日 | 0-6(0为周一) | tm_wday |
| 7 | 一年的第几日 | 1-366 | tm_yday |
| 8 | 夏令时 | -1,0,1 | tm_isdst |
时间转换
help(time) # 查看帮助
time.sleep() # delay方法
time.timezone/3600 # 时区
time.time() # 获取当前时间戳
#1511846475.9762366 #将时间戳转化为元组形式
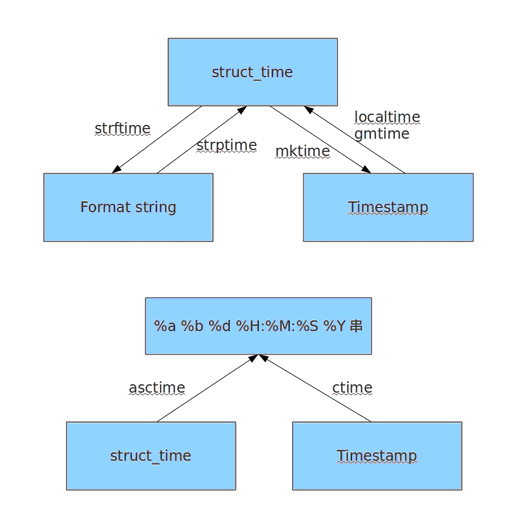
time.localtime() # 返回本地时区时间(struct_time(tuple)),无参数时传入当前时间,也可以传入秒数
x = time.localtime()
help(x)
print(x[0]) #
print(x.tm_year) #
print(time.localtime())
# time.struct_time(tm_year=2017, tm_mon=11, tm_mday=28, tm_hour=13, tm_min=21, tm_sec=16, tm_wday=1, tm_yday=332, tm_isdst=0) time.gmtime(seconds=) # 返回UTC时间,无参数时传入当前时间,也可以传入秒数 # 将元组转化为时间戳的形式
time.mktime() #格式化输出时间
time.strftime()
x = time.localtime()
print(time.strftime("%Y-%m-%d %H:%M:%S",x)) #x.tm_year 对应%Y,依次一一对应
#2017-11-28 13:52:36 # struct_time格式输出时间
time.strptime(string=,format=)
print(time.strptime("2017-11-28 13:52:36","%Y-%m-%d %H:%M:%S"))
#相当于tm_year=2017, tm_mon = 11,‘-’ 对应 ‘-’等等一一对应;time.struct_time(tm_year=2017, tm_mon=11, tm_mday=28, tm_hour=13, tm_min=52, tm_sec=36, tm_wday=1, tm_yday=332, tm_isdst=-1) time.asctime() # 把元组时间转化为字符串形式,接受元组为参数
print(time.asctime(time.localtime()))
#Tue Nov 28 14:24:45 2017 time.ctime() #将时间戳转化为字符串形式
# Tue Nov 28 14:24:45 2017
datetime
import datetime # datetime.date 表示日期的类,常用属性有year,month,day
# datetime.time 表示时间的类,常用属性有hour,minute,second,microsecond
# datetime.datetime 表示日期时间 '''
datetime.timedelta:表示时间间隔,即两个时间点之间的长度
timedelta([days[, seconds[, microseconds[, milliseconds[, minutes[, hours[, weeks]]]]]]])
strftime("%Y-%m-%d")
'''
print(datetime.datetime.now())
print(datetime.datetime.now() + datetime.timedelta(3))
print(datetime.datetime.now() + datetime.timedelta(-3))
print(datetime.datetime.now() + datetime.timedelta(hours=3))
"""
2017-11-28 15:02:22.181923
2017-12-01 15:02:22.181923
2017-11-25 15:02:22.181923
2017-11-28 18:02:22.181923
"""
#时间替换
# c_time = datetime.datetime.now()
# print(c_time.replace(minute=3,hour=2)) #时间替换
random模块
import random help(random) # 随机浮点数
print(random.random()) # 0.3565219516812477
print(random.uniform(1,8)) # 4.2968907288240725 # 随机整数[1,8]
print(random.randint(1,8)) # 随机整数[1,8)
print(random.randrange(1,8)) # 随机字符
print(random.choice([1,3,4])) # 选取特定数量的字符数
print(random.sample("hello",2)) #['e', 'o'] # 洗牌
L = [ 1,2,3,4,5,6]
print(L)
random.shuffle(L)
print(L)
# [1, 2, 3, 4, 5, 6]
# [5, 4, 3, 6, 2, 1]
实例
#生成验证码
import random checkcode = ""
for i in range(5):
current = random.randrange(0,5)
if i == current:
tmp = chr(random.randint(65,90))
else:
tmp = random.randint(0,9)
checkcode += str(tmp)
print(checkcode)
os模块
参考:https://docs.python.org/2/library/os.html?highlight=os#module-os
import os print(os.getcwd()) # 获取当前工作目录,即当前python脚本工作的目录路径
#D:\workspace\Python51\Day4
os.chdir("dirname") # 改变当前脚本工作目录;相当于shell下cd
os.curdir # 返回当前目录: ('.')
# .
os.pardir # 获取当前目录的父目录字符串名:('..')
# ..
os.makedirs(r'D:\workspace\Python51\Day_test\test') # 可生成多层递归目录
os.removedirs(r'D:\workspace\Python51\Day_test\test') # 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') # 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') # 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir(r'D:\workspace\Python51\Day4') # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() # 删除一个文件
os.rename("oldname","newname") # 重命名文件/目录
os.stat('path/filename') # 获取文件/目录信息
os.sep # 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep # 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep # 输出用于分割文件路径的字符串 os.name # 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") # 运行shell命令,直接显示
os.environ # 获取系统环境变量
os.path.abspath(path) # 返回path规范化的绝对路径
os.path.split(path) # 将path分割成目录和文件名二元组返回
os.path.dirname(path) # 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) # 返回path最后的文件名。如果path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) # 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) # 如果path是绝对路径,返回True
os.path.isfile(path) # 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) # 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) # 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) # 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) # 返回path所指向的文件或者目录的最后修改时间
sys模块
import sys print(sys.argv ) #命令行参数List,第一个元素是程序本身路径
#sys.exit(n) #退出程序,正常退出时exit(0)
print(sys.version ) #获取Python解释程序的版本信息
#print(sys.maxint) #最大的Int值
print(sys.path) #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
print(sys.platform) #返回操作系统平台名称
sys.stdout.write('please:')
val = sys.stdin.readline()[:-1]
实例
#************************进度条打印*******************
import sys, time for i in range(50):
sys.stdout.write("#")
sys.stdout.flush()
time.sleep(0.5)
shutil模块
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length]) 将文件内容拷贝到另一个文件中,可以部分内容 shutil.copyfile(src,dst) 拷贝文件,输入文件路径即可 shutil.copymode(src,dst) 仅拷贝权限,内容、组、用户均不变 shutil.copystat(src,dst) 拷贝状态的信息,包括:mode bits, atime, mtime, flags shutil.copy(src,dst) 拷贝文件和权限 shutil.copy2(src,dst) 拷贝文件和状态信息 shutil.copytree(src,dst) 递归的去拷贝文件 shutil.rmtree(src) 递归的去删除文件 shutil.move(src,dst) 递归的去移动文件 shutil.make_archive(base_name,format,…):
base_name:压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径
format: 压缩包类型,zip,tar,bztar,gztar
root_dir: 要压缩的文件夹路径
owner: 用户,默认当前
group: 组,默认当前
logger: 记录日志
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的
import shutil
f1 = open('shutil_test1','r')
f2 = open('shutil_test2','w')
shutil.copyfileobj(f1,f2)
# 直接传入文件,内部直接实现文件打开写入操作
shutil.copyfile('shutil_test1','shutil_test3')
shutil.make_archive('shutil_test1_zip','zip',"D:\workspace\Python51\Day1\homework1")
import tarfile
# 压缩
tar = tarfile.open('tar_test.tar','w')
tar.add('D:\workspace\Python51\Day4\zip_test.zip',arcname='day5.zip')
tar.add('D:\workspace\Python51\Day4\shutil_test1',arcname='shutil_test1')
tar.close()
# 解压
tar = tarfile.open('your.tar','r')
tar.extractall() # 可设置解压地址
tar.close()
hashlib模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib m = hashlib.md5()
m.update(b"Hello")
print(m.hexdigest())
m.update(b"It's me")
print(m.hexdigest())
m.update(b"It's been a long time since we spoken...") m2 = hashlib.md5()
m2.update("HelloIt's me天王盖地虎".encode(encoding="utf-8"))
print(m2.hexdigest()) s2 = hashlib.sha1()
s2.update(b"HelloIt's me")
print(s2.hexdigest())
subprocess模块
用于调用操作系统命令,区别os.system和os.popen。
py2.7 command模块也可调用系统命令,只支持linux os.system(命令) 输出命令结果到屏幕,返回命令执行状态
os.popen(命令)。read() 会保存命令的执行结果,不返回命令执行状态,不可知命令执行是否成功 subprocess.run() (python3.5才有的run方法) a = subprocess.run(['ipconfig', '/all'])
#直接输出ipconfig /all执行结果到屏幕
print(a)
# CompletedProcess(args=['ipconfig', '/all'], returncode=0)
注:如果涉及到管道运算符‘|’(linux),
subprocess.run('df -h |grep sda1',shell=True)
#shell=True是指不需要python解析,直接调用shell subprocess.call() # 相当于os.system
#执行命令,返回命令执行状态,0或非0
a=subprocess.call(['ipconfig', '/all'])
print(a)
subprocess.check_call()
#执行命令,如果命令结果为0,就正常返回,否则抛出异常
a = subprocess.check_call(['ipconfig', '/all'])
print(a)
subprocess.getstatusoutput
#接收字符串格式命令,返回元组形式,第1个元素是执行状态,第2个是命令结果 , 常用,推荐
a = subprocess.getstatusoutput(['wmic' ,'bios', 'get','serialnumber'])
print(a)
# (0, 'SerialNumber \n\n5CG5220HRD \n\n\n') #接收字符串格式命令,并返回结果
a = subprocess.getoutput(['wmic' ,'bios', 'get','serialnumber'])
print(a)
# 'SerialNumber \n\n5CG5220HRD \n\n\n' #执行命令,并返回结果,注意是返回结果,不是打印,下例结果返回给a
a = subprocess.check_output(['wmic' ,'bios', 'get','serialnumber'])
print(a)
# b'SerialNumber \r\r\n5CG5220HRD \r\r\n\r\r\n'
调用subprocess.run(...)是推荐的常用方法,在大多数情况下能满足需求,但如果你可能需要进行一些复杂的与系统的交互的话,你还可以用subprocess.Popen()
subprocess.Popen()
poll与wait方法,subprocess.Popen调用内部命令,程序执行后结果需要制定保存在管道中,然后通过stdout.read方法读取,这时可以通过poll或wait来判断是否执行完毕。
poll(): 执行系统内部命令,相当于启动一个子进程,poll可以查看子进程是否终止,即内部命令结束,并且返回执行状态号,若返回None,则未执行完成。
wait(): 等待命令执行结束,并且返回执行状态号。
terminate() 杀掉启动进程,如果调用系统命令执行中需要停止,则可以杀掉。
commmunicate() 等待任务结束
可用参数:
args:shell命令,可以是字符串或者序列类型(如:list,元组)
bufsize:指定缓冲。0 无缓冲,1 行缓冲,其他 缓冲区大小,负值 系统缓冲
stdin, stdout, stderr:分别表示程序的标准输入、输出、错误句柄,可参考linux标准输入输出
preexec_fn:只在Unix平台下有效,用于指定一个可执行对象(callable object),它将在子进程运行之前被调用
close_sfs:在windows平台下,如果close_fds被设置为True,则新创建的子进程将不会继承父进程的输入、输出、错误管道。所以不能将close_fds设置为True同时重定向子进程的标准输入、输出与错误(stdin, stdout, stderr)。
shell:True表示不通过python解释,直接调用
cwd:用于设置子进程的当前目录
env:用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父进程中继承。
universal_newlines:不同系统的换行符不同,True -> 同意使用 \n
startupinfo与createionflags只在windows下有效
将被传递给底层的CreateProcess()函数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等
p = subprocess.Popen('wmic bios get serialnumber', stdin=subprocess.PIPE,stdout=subprocess.PIPE)
print(p.stdout.read(), p.poll())
# b'SerialNumber \r\r\n5CG5220HRD \r\r\n\r\r\n'
实例
import subprocess echo = subprocess.Popen(['echo','password'],
stdout=subprocess.PIPE,
) sudo = subprocess.Popen(['sudo','-S','iptables','-L'],
stdin=echo.stdout,
stdout=subprocess.PIPE,
) end_of_pipe = sudo.stdout # 方式二
sudo = subprocess.Popen("echo 'password' | sudo -S iptables -L",
shell=True
stdout=subprocess.PIPE,
)
logging模块
import logging '''
#把日志简单打印到屏幕,日志级别CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
'''
'''
WARNING:root:warning message
ERROR:root:error message
CRITICAL:root:critical message
'''
'''
#将日志保存到example.log,定义level为INFO等级,可将大于或等于INFO的日志保存到文件
logging.basicConfig(filename='example.log', level=logging.INFO)
logging.debug('This message should go to the log file')
logging.info('So should this')
logging.warning('And this, too')
'''
'''
#格式化输出至屏幕
logging.basicConfig(format='%(asctime)s %(message)s', datefmt='%m/%d/%Y %I:%M:%S %p')
logging.warning('warning message')
#12/01/2017 10:13:39 AM warning message
''' '''
import logging
from logging import handlers
#create logger
logger = logging.getLogger('TEST-LOG')
logger.setLevel(logging.DEBUG) ''''''
# create console handler and set level to debug
#输出至屏幕
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG) # create file handler and set level to warning
#保存至文件
fh = logging.FileHandler("access.log")
fh.setLevel(logging.WARNING) #creat RotatingFileHandler handler 文件截断
rota = handlers.RotatingFileHandler(filename="log_file",mode="a", maxBytes=500, backupCount=3)
rota.setLevel(logging.DEBUG) #creat handlers.TimedRotatingFileHandler 文件截断
time_f = handlers.TimedRotatingFileHandler(filename="log_time.log",when='S',interval=5,backupCount=4)
time_f.setLevel(logging.INFO) # create formatter
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # add formatter to ch and fh
ch.setFormatter(formatter)
fh.setFormatter(formatter)
rota.setFormatter(formatter)
time_f.setFormatter(formatter) # add ch and fh to logger
logger.addHandler(ch)
logger.addHandler(fh)
logger.addHandler(rota)
logger.addHandler(time_f) # 'application' code
logger.debug('debug message')
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message')
'''
re模块
匹配模式
“.”:匹配除\n之外的任意一个字符
“^”:匹配字符开头
“+”:匹配前一规则一次或多次
“*”:匹配前一规则0次或多次
“?”:匹配前一规则1次或0次
“{m}”:匹配前一规则m次
“{n,m}”:匹配前一规则n到m次
“|”:匹配|左或|右的字符
“(…)”:分组匹配
“\A”:只从字符开头匹配
“\Z”:匹配字符结尾,同$
“\d”:匹配0-9数字
“\D”:匹配非数字
“\w”:匹配A-Za-z0-9字符
“\W”:匹配非A-Za-z0-9
“\s”:匹配空白字符
“(?P<name>…)”:分组匹配,使用groupdict()按name生成字典
\\\\可以匹配一个\
匹配对象方法
re.match(pattern,str):从头开始匹配搜索 re.search(pattern,str):从左往右开始匹配搜索 re.findall(pattern,str):生成所有符合规则的内容,返回一个列表 re.split(pattern,str):以匹配字符分割列表 re.sub(pattern,repl,str,count=?,flag=?):以匹配字符替换
flags设置
re.I(re.IGNORECASE):忽略大小写 M(MULTILINE):多行模式 S(DOTALL):点任意匹配模式,包括\n
json
序列化(Serialization):将对象的状态信息转换为可以存储或可以通过网络传输的过程。
反序列化:从存储区域读取反序列化对象的状态,重新创建该对象。
json:可以处理简单数据类型,用于字符串和python数据类型转换。可以用于和其他语言做交互。
json提供四个功能:
dumps, dump:将数据通过特殊的形式转换为所有程序语言都认识的字符串
loads, load:将json编码的字符串转换为python的数据结构
dump与load
import json #序列化
ariety = ["sweet","hot","dill"]
f = open("test","w")
# json.dump(ariety,f)
# 文件只能接受字符串或二进制形式写入,ariety被json转换成字符串形式并写入文件
f.write(json.dumps(shape))
# #相当于eval(ariety),转换为“ ["whole","spear","chip"]”
f.close() #反序列化
f = open("test","r")
for line in f:
print(json.loads(line)) # 可以读多行,但不建议使用读多行, data = jsom.loads(f.read()) date=json.load(f) # 用于数据文件读取数据
# 如果多次dumps或dump,再使用load,会报错,所以建议一次dump一次load,覆盖形式。
print(date)
f.close()
dumps与loads
import json data = ['aa', 'bb', 'cc']
j_str = json.dumps(data)
print(j_str,type(j_str)) #["aa", "bb", "cc"] <class 'str'>
mes = json.loads(j_str)
print(mes,type(mes)) #['aa', 'bb', 'cc'] <class 'list'>
data = {'a':True, 'b':False, 'c':None, 'd':(1,2), 1:'abc'}
j_str = json.dumps(data)
print(j_str,type(j_str)) #{"b": false, "a": true, "d": [1, 2], "c": null, "1": "abc"} <class 'str'>
注
如果多次dumps或dump,再使用load,会报错,所以建议一次dump一次load,覆盖形式。建议dump将字符串数据写入文件一次,load从文件读取数据一次,多次load容易出错。
如果直接在文件中编写一个字典等,并且使用json序列化,则使用双引号;例如使用双引号括起来键。
json编码的格式几乎和python语法一致,略有不同的是:True会被映射为true,False会被映射为false,None会被映射为null,元组()会被映射为列表[],因为其他语言没有元组的概念,只有数组,也就是列表。
pickle
通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
可以存储比较复杂的数据对象,如函数;但是不能和其他语言交互。用于bytes类型和python数据类型转换。
pickle提供了四个方法:dump、dumps、load、loads
dump与load
print("Pickling lists.")
variety = ["sweet","hot","dill"]
shape = ["whole","spear","chip"]
brand = ["Claussen","Heinz","Vlassic"]
f = open("file_pickles1.dat","wb")
pickle.dump(variety,f)
pickle.dump(shape,f)
pickle.dump(brand,f)
f.close()
print("Unpickleing lists.")
f = open("file_pickles1.dat","rb")
variety = pickle.load(f)
shape = pickle.load(f)
brand = pickle.load(f)
print(variety)
print(shape)
print(brand)
实例
import pickle
def sayhi(name):
print("hello,",name)
info = {
'name':'alex',
'age':22,
'func':sayhi
}
f = open("test.text","wb") #二进制形式写入
pickle.dump(info,f)
#f.write( pickle.dumps( info) )
f.close() import pickle def sayhi(name):
print("hello2,",name) f = open("test.text","rb")
data = pickle.load(f) #data = pickle.loads(f.read())
print(data["func"]("ABS")) f.close() #写入文件函数为sayhi,但是在读取程序,把函数sayhi修改后,以修改后的函数执行
dumps与loads
import pickle
data = {'a':True, 'b':False, 'c':None, 'd':(1,2), 1:'abc'}
j_str = pickle.dumps(data)
print(j_str,type(j_str))
#b'\x80\x03}q\x00(X\x01\x00\x00\x00aq\x01\x88X\x01\x00\x00\x00bq\x02\x89X\x01\x00\x00\x00cq
# \x03NX\x01\x00\x00\x00dq\x04K\x01K\x02\x86q\x05K\x01X\x03\x00\x00\x00abcq\x06u.' <class 'bytes'>
mes = pickle.loads(j_str)
print(mes,type(mes))
{'c': None, 'd': (1, 2), 'a': True, 'b': False, 1: 'abc'} <class 'dict'>
shelve
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式。
import shelve
d = shelve.open('shelve_test') #打开一个文件
class Test(object):
def __init__(self,n):
self.n = n
t = Test(123)
t2 = Test(123334)
name = ["alex","rain","test"]
d["test"] = name #持久化列表
d["t1"] = t #持久化类
d["t2"] = t2
d.close()
d = shelve.open('shelve_test') # 打开一个文件
print(d.get("t1"))
print(d.get("test"))
print(d.get("t2"))
d.close()
paramiko
基于SSH用于远程连接服务器并执行相关操作,paramiko.SSHClient()。
import paramiko ssh = paramiko.SSHClient() # 实例化ssh对象
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) # 允许连接不在know_hosts文件中的主机
ssh.connect(hostname='bejsrtl200.bj.intel.com', username='', password='') # 连接服务器
stdin, stdout, stderr = ssh.exec_command('ifconfig') # 执行命令 print(stdout.read().decode()) # 打印执行结果
ssh.close()
另一种实现方式
import paramiko
transport = paramiko.Transport(('bejsrtl184.bj.intel.com', 22))
transport.connect(username='jiawenyx', password='intel@7128')
ssh = paramiko.SSHClient()
ssh._transport = transport
stdin, stdout, stderr = ssh.exec_command('ifconfig')
print(stdout.read().decode()) # 打印执行结果
transport.close()
通过scp可以传输文件,python基于scp来发送命令,paramiko.Transport(('hostname', port))
import paramiko
transport = paramiko.Transport(('host',22))
transport.connect(username='root',password='')
sftp = paramiko.SFTPClient.from_transport(transport)
sftp.put('D:\Pycharm\hadoop_spark\ssh_files\id_rsa','/usr/local/id_rsa') # 文件名必须写上
transport.close()
xml模块
pyYAML模块
configparser模块
Python修炼之路-模块的更多相关文章
- Python学习之路——模块
一.模块: 模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能需 ...
- Python修炼之路-异常
异常处理 在程序出现bug时一般不会将错误信息直接显示给用户,而是可以自定义显示内容或处理. 常见异常 AttributeError # 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性 ...
- Python修炼之路-文件操作
Python编程之文件操作 文件操作流程 打开文件,得到文件句柄并赋值给一个变量 通过句柄对文件进行操作 关闭文件 每次文件打开.读取信息时,Python自动记录所达到的位置,好比一个书签,之后每一次 ...
- Python修炼之路-函数
Python编程之函数 程序的三种方式 面向对象:类------->class 面向过程:过程------>def 函数式编程:函数------>def 定义函数 函数:逻辑结构化与 ...
- python修炼之路---面向对象
面向对象编程 面向对象编程:使用类和对象实现一类功能. 类与对象 类:类就是一个模板,模板里可以包含多个函数,函数里实现一些功能. 对象:是根据模板创建的实例,通过实例对象可以执行类中的函数. 面向对 ...
- python修炼之路——控制语句
Python编程之print python2.x和python3.x的print函数区别:python3.x的print函数需要加括号(),python2.x可以不加. #-*- coding:utf ...
- Python修炼之路-数据类型
Python编程之列表 列表是一个使用一对中括号"[ ]" 括起来的有序的集合,可以通过索引访问列表元素,也可以增加和删除元素. 列表的索引:第一个元素索引为0,最后一个元素索 ...
- Python修炼之路-装饰器、生成器、迭代器
装饰器 本质:是函数,用来装饰其他函数,也就是为其他函数添加附加功能. 使用情景 1.不能修改被装饰的函数的源代码: 2.不能修改被装饰的函数的调用方式. 在这两种条件下,为函数添加附加 ...
- Python修炼之路-Socket
网络编程 socket套接字 socket通常也称作"套接字",用于描述IP地址和端口,是一个通信链的句柄,应用程序通常通过“套接字”向网络发出请求或者应答网络请求. socket ...
随机推荐
- php URL处理函数
parse_url() basename() pathinfo() dirname() 用法 parse_url() 是一计算机函数,功能是解析一个 URL 并返回一个关联数组,包含 ...
- 由于SID连接不匹配,监听器拒绝连接。
java.sql.SQLException: Listener refused the connection with the following error:ORA-12505, TNS:liste ...
- jeecms v9图标不显示问题
- java:struts框架5(Converter,Validation,Tags(Object-Graph Navigation Language))
1.Converter: struts.xml: <?xml version="1.0" encoding="UTF-8"?> <!DOCTY ...
- centos v7.0解决乱码
[root@localhost ~]# ll 鎬荤敤閲4-rw-------. 1 root root 1045 8鏈 24 21:17 anaconda-ks.cfg [root@localhost ...
- 【Ruby on Rails 学习四】简单的代码快和错误处理
第一个例子: 1 ... 5000的加法运算 1 sum = 0 2 i = 1 3 while true 4 sum += i 5 i += 1 6 break if i == 5001 7 end ...
- 【Java基础】Java创建对象的五种方式
Java中创建(实例化)对象的五种方式 1.用new语句直接创建对象,这是最常见的创建对象的方法. 2.通过工厂方法返回对象,如:String str = String.valueOf(23); 3. ...
- CSS:文字水平居中的写法
<view class='kk'> 水平垂直居中文字 </view> .kk{ border: 1px solid #000000; width: 200px; height: ...
- ArrayList(顺序表)和LinkedList(链表)的区别联系,优劣取舍问题
ArrayList和LinkedList都是List接口的实现类.主要区别如下: 最主要的区别是底层的数据结构不同: 1)ArrayList相当于一个动态数组,需要随机访问列表中的元素时,ArrayL ...
- 面试--hr常问的问题
程序员换工作,会有技术面试(可能不止一轮的技术面),还会有hr的面试,技术面主要是偏向于技术问题,hr面试主要问的一些问题,下面做下汇总: 1.你换工作的原因,你为何辞职 必问的问题,送分题或者送命题 ...