mysql——单表查询——分组查询——示例
一、基本查询语句
select的基本语法格式如下:
select 属性列表 from 表名和视图列表
[ where 条件表达式1 ]
[ group by 属性名1 [ having 条件表达式2 ] ]
[ order by 属性名2 [ asc | desc ] ]
属性列表参数表示需要查询的字段名;
表名和视图列表参数表示从此处指定的表或者视图中查询数据,表和视图可以有多个;
条件表达式1参数指定查询条件;
属性名1参数指按照该字段的数据进行分组;
条件表达式2参数满足该表达式的数据才能输出;
属性名2参数指按照该字段中的数据进行排序;排序方式由asc和desc这两个参数指出;
asc参数表示升序,这是默认参数,desc表示降序;(升序表示从小到大)
对记录没有指定是asc或者desc,默认情况下是asc;
如果有where子句,就按照“条件表达式1”指定的条件进行查询;如果没有where子句,就查询所有记录;
如果有group by子句,就按照“属性名1”指定的字段进行分组,如果group by后面带having关键字,那么只有
满足“条件表达式2”中知道的条件才能输出。group by子句通常和count()、sum()等聚合函数一起使用;
如果有order by子句,就按照“属性名2”指定的字段进行排序,排序方式由asc和desc两个参数指出;默认情况下是asc;
================================================================================================
分组查询:
group by关键字可以将查询结果按照某个字段或多个字段进行分组,字段的值相等的为一组
语法格式:group by 属性名 [ having 条件表达式 ] [ with rollup ]
属性名参数是指按照该字段的值进行分组;
having 条件表达式 用来限制分组后的显示,满足条件表达式的结果将被显示;
with rollup关键字将会在所有记录的最后加上一条记录,该记录是上面所有记录的总和;
注意:group by关键字一般和聚合函数一起使用,如果不一起使用,那么查询结果就是字段取值的分组情况;
字段中取值相同的记录为一组,但只显示该组的第一条记录。
=======================================================================================
基础:前提:

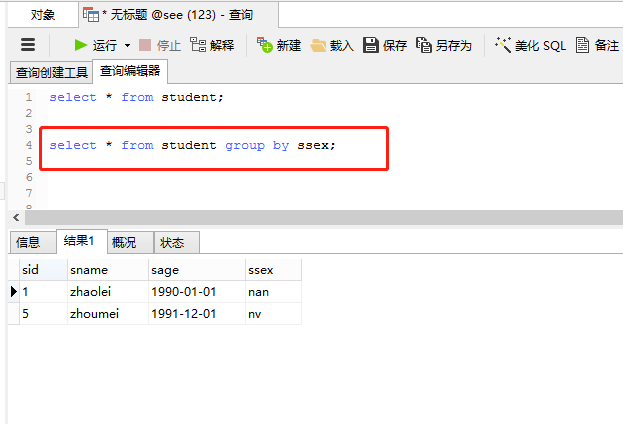
(1)单独使用group by关键字来分组
如果单独使用group by关键字,查询结果只显示一个分组的一条记录;
执行语句:
select * from student group by ssex;
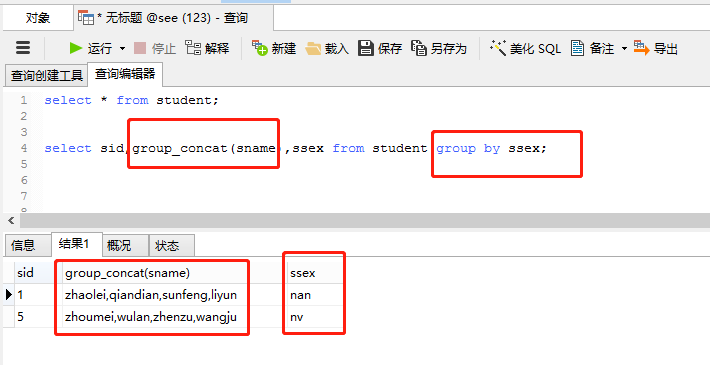
(2)group by关键字与group_concat()函数一起使用
group by关键字与group_concat()函数一起使用时,每个分组中指定字段值都显示出来;
执行语句:
select sid,group_concat(sname),ssex from student group by ssex;
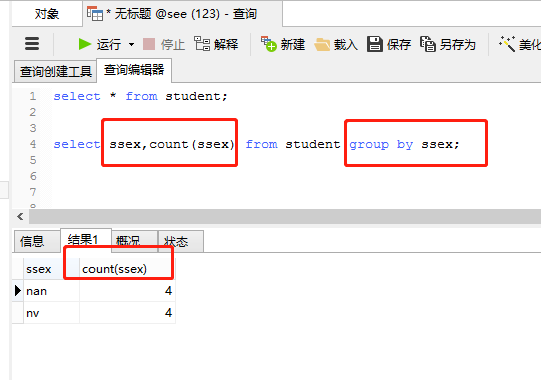
(3)group by关键字与集合函数一起使用
count()用来统计记录的条数;
sum()用来计算记录的值的总和;
avg()用来计算字段的值的平均值;
max()用来查询字段的最大值;
min()用来查询记录的最小值;
执行语句:
select ssex,count(ssex) from student group by ssex;
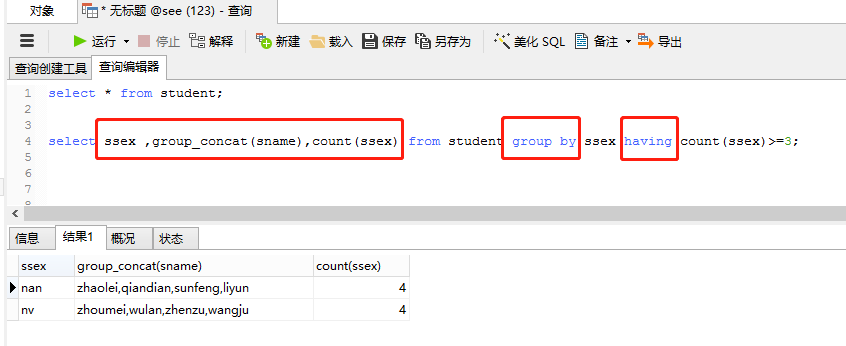
(4)group by关键字与having一起使用
如果加上having 条件表达式可以限制输出结果
举例:select sex ,count(sex) from employee group by sex having count(sex)>=3;
注释:"having 条件表达式"与"where 条件表达式"都是用来限制显示的,但是两者起的作用又不相同,
"where 条件表达式"作用于表或者视图,是表和视图的查询条件;
"having 条件表达式"作用于分组后的记录,用于选择满足条件的组;
执行语句:
select ssex ,group_concat(sname),count(ssex) from student group by ssex having count(ssex)>=3;
(5)group by关键字与rollup一起使用
使用rollup时,将会在所有记录的最后加上一条记录,这条记录是上面所有记录的总和;
举例:select sex,concat(name) from employee group by sex with rollup;
select ssex ,group_concat(sname),count(ssex) from student group by ssex with rollup;

(5)按多个字段进行分组
举例:select * from employee group by d_id,sex;
查询结果显示,记录先按照d_id字段进行分组,因为有2条记录的d_id值为1001,所以这2条记录再按照sex字段的值进行分组。
要修改一个sid,不然不好示例:
select * from student; update student set sid= '' where sname = 'qiandian'
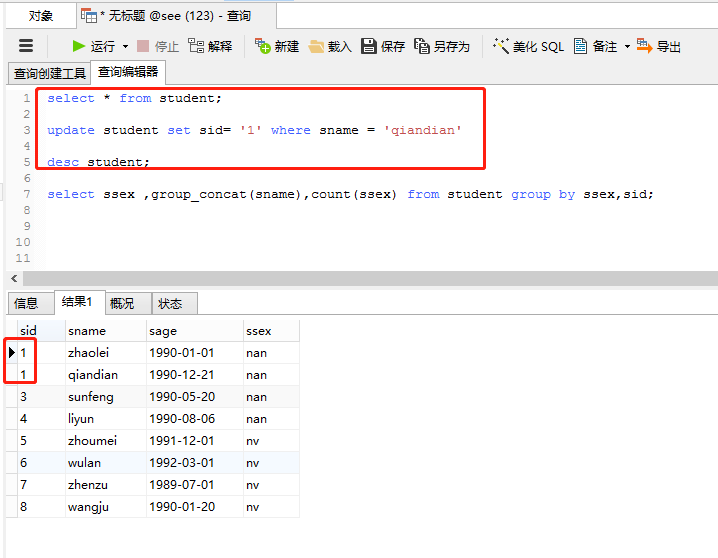
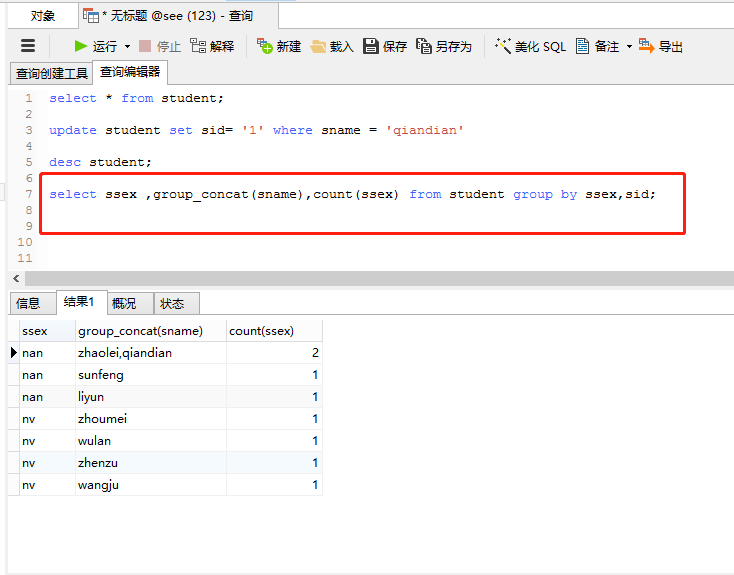
执行语句:
select ssex ,group_concat(sname),count(ssex) from student group by ssex,sid;
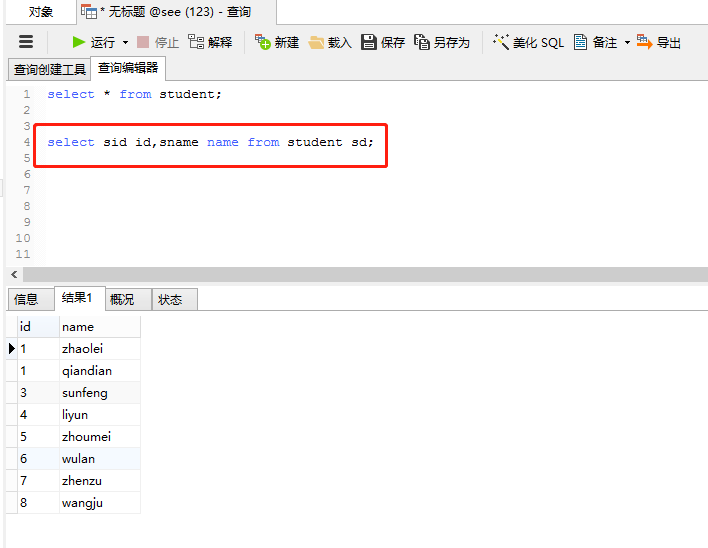
(7)、为表和字段取别名
为表和字段取别名
1、语法:表名 表的别名
select * from department d where d.d_id = 1001;
2、语法:属性名 [as] 别名
示例:select d_id as department_id,d_name department_name from department;
数据库中,可以同时为表和字段取别名
示例:select d_id as department_id,d_name department_name,d.functione,d.address from department d where d.d_id = 1001;
执行语句:
select sid id,sname name from student sd;
mysql——单表查询——分组查询——示例的更多相关文章
- MySQL单表多次查询和多表联合查询,哪个效率高?
很多高性能的应用都会对关联查询进行分解. 简单地,可以对每个表进行一次单表查询,然后将结果在应用程序中进行关联.例如,下面这个查询: select * from tag join tag_post o ...
- MYSQL 单表一对多查询,将多条记录合并成一条记录
一.描述: 在MySQL 5.6环境下,应工作需求:将一个表中多条某个相同字段的其他字段合并(不太会表达,有点绕,直接上图) 想要达到的效果: 实现SQL语句: SELECT a.books, GRO ...
- python 3 mysql 单表查询
python 3 mysql 单表查询 1.准备表 company.employee 员工id id int 姓名 emp_name varchar 性别 sex enum 年龄 age int 入职 ...
- Mysql 单表查询 子查询 关联查询
数据准备: ## 学院表create table department( d_id int primary key auto_increment, d_name varchar(20) not nul ...
- Mysql 单表查询-排序-分页-group by初识
Mysql 单表查询-排序-分页-group by初识 对于select 来说, 分组聚合(((group by; aggregation), 排序 (order by** ), 分页查询 (limi ...
- MySQL单表多字段模糊查询
今天工作时遇到一个功能问题:就是输入关键字搜索的字段不只一个字段,比如 我输入: 超天才 ,需要检索出 包含这个关键字的 name . company.job等多个字段.在网上查询了一会就找到了答案. ...
- MySQL对数据表进行分组查询
MySQL对数据表进行分组查询(GROUP BY) GROUP BY关键字可以将查询结果按照某个字段或多个字段进行分组.字段中值相等的为一组.基本的语法格式如下: GROUP BY 属性名 [HAVI ...
- MySQL对数据表进行分组查询(GROUP BY)
MySQL对数据表进行分组查询(GROUP BY) GROUP BY关键字可以将查询结果按照某个字段或多个字段进行分组.字段中值相等的为一组.基本的语法格式如下: GROUP BY 属性名 [HAVI ...
- Mysql 单表查询where初识
Mysql 单表查询where初识 准备数据 -- 创建测试库 -- drop database if exists student_db; create database student_db ch ...
- BBS--功能4:个人站点页面设计(ORM跨表与分组查询)
查询: 日期归档查询 1 date_format ============date,time,datetime=========== create table t_mul_new(d date,t t ...
随机推荐
- linux运维、架构之路-MongoDB单机部署
一.MongoDB介绍 MongoDB 是一个基于分布式文件存储的数据库.由 C++ 语言编写.旨在为 WEB 应用提供可扩展的高性能数据存储解决方案. MongoDB 是一个介于关系型数据库和非关系 ...
- Oracle存储结构-段区块
段 一个段建立以后首先会分配一个区,区中包括含8个块,这时执行insert插入数据,当这个区写满后,会在分配一个区 1.一个段建立以后,Oracle如何给段分配区? 2.段分配到区以后,有了空闲空间, ...
- hdu 2604 Queuing(推推推公式+矩阵快速幂)
Description Queues and Priority Queues are data structures which are known to most computer scientis ...
- <image>的src属性的使用
刚接触前端不久.怎么用image显示图片是个问题,怎么使用数据流还是base64呢?小小的研究一下 <image src="url"> 1.接口返回数据流,src可以直 ...
- EasyPrtSc sec[1.2] 发布!
//HOMETAG #include<bits/stdc++.h> namespace EasilyPrtSc{ //this namespace is for you to be mor ...
- CF1213E Two Small Strings
题目链接 问题分析 由于三个字母是等价的,所以大致可以分为如下几种情况: aa, ab ab, ac ab, ba ab, bc 不难发现,第\(3\)中情况可能造成无解(\(n>1\)时),而 ...
- VS2015 ASP.NET MVC5 EntityFramework6 Oracle 环境篇
//来源:https://www.cnblogs.com/lauer0246/articles/9576940.html Asp.Net MVC EF各版本区别 2009年發行ASP.NET MVC ...
- JavaWeb--Servlet 详解
一.基本概念 Servlet是运行在Web服务器上的小程序,通过http协议和客户端进行交互.这里的客户端一般为浏览器,发送http请求(request)给服务器(如Tomcat).服务器接收到请求后 ...
- 2018-2019-2 网络对抗技术 20165232 Exp 8 Web基础
2018-2019-2 网络对抗技术 20165232 Exp 8 Web基础 原理与实践说明 1.实践内容概述 Web前端HTML 能正常安装.启停Apache.理解HTML,理解表单,理解GET与 ...
- Mysql 基础操作命令
1,查看mysql的建表语句 show create table tableName; #tableName 库中已存在的表名