《Using Databases with Python》Week3 Data Models and Relational SQL 课堂笔记
Coursera课程《Using Databases with Python》 密歇根大学
Week3 Data Models and Relational SQL
15.4 Designing a Data Model
主要介绍了数据模型的重要性,以及数据模型构建的一些思考过程。
15.5 Representing a Data Model in Tables
概念模型
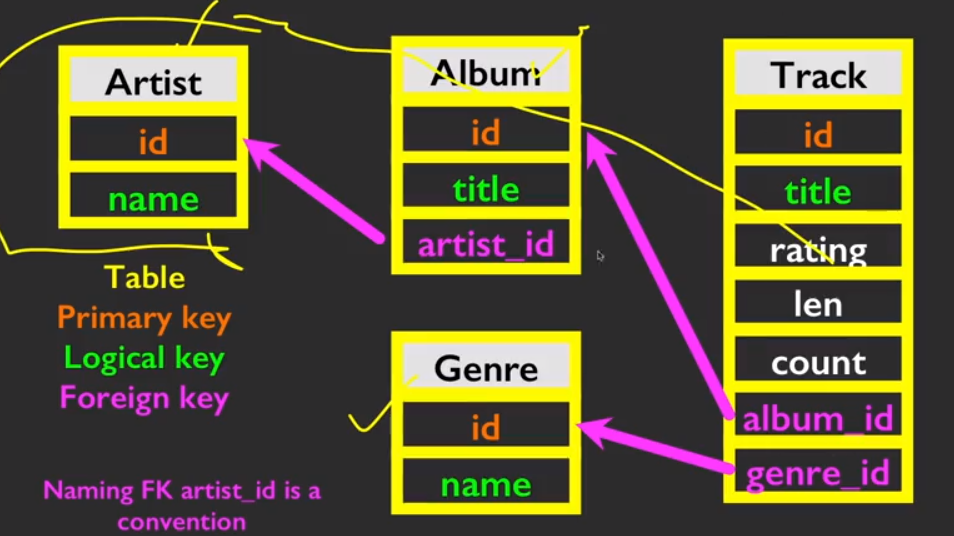
主键(Primary key),指的是一个列或多列的组合,其值能唯一地标识表中的每一行,通过它可强制表的实体完整性。主键主要是用于其他表的外键关联,以及本记录的修改与删除。
外键(Foreign key),作用是保持数据一致性,完整性,主要目的是控制存储在外键表中的数据。 使两张表形成关联,外键只能引用外表中的列的值。
如果我们要构建上面概念模型所表示的数据库,那么我们用到的一些SQL语句有:
CREATE TABLE Genre(
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
name TEXT
)
CREATE TABLE Album(
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
artist_id INTEGER
title TEXT
)
CREATE TABLE Track(
id INTEGER NOT NULL PRIMARY KEY
AUTOINCREMENT UNIQUE,
title TEXT,
album_id INTEGER,
genre_id INTEGER,
len INTEGER,
rating INTEGER,
count INTEGER
)
15.6 Inserting Relational Data
插入数据
insert into Artist(name) values ('Led Zepplin')
insert into Artist(name) values ('AC/DC')
像上面这样就往Artist表中加入了两行数据。
而对于Album表来说,它连接了Artist表,有两列数据要插入,那么这样。
insert into Album(title,artist_id) values ('Who Made Who',2)
insert into Album(title,artist_id) values ('IV',1)
所以这样之后,我们就建立起了数据之间的关系。

15.7 Reconstructing Data with JOIN
JOIN操作像是在几个表之间的SELECT操作。
而我们告诉JOIN怎么使用这些key则需要用到ON语句。有点像WHERE语句。

select Album.title, Artist.name from Album join Artist on Album.artist_id = Artist.id
如果把事情变复杂一些……

Work Example: Tracks.py
import xml.etree.ElementTree as ET
import sqlite3
conn = sqlite3.connect('trackdb.sqlite')
cur = conn.cursor()
# Make some fresh tables using executescript()
cur.executescript('''
DROP TABLE IF EXISTS Artist;
DROP TABLE IF EXISTS Album;
DROP TABLE IF EXISTS Track;
CREATE TABLE Artist (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
name TEXT UNIQUE
);
CREATE TABLE Album (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
artist_id INTEGER,
title TEXT UNIQUE
);
CREATE TABLE Track (
id INTEGER NOT NULL PRIMARY KEY
AUTOINCREMENT UNIQUE,
title TEXT UNIQUE,
album_id INTEGER,
len INTEGER, rating INTEGER, count INTEGER
);
''')
fname = input('Enter file name: ')
if ( len(fname) < 1 ) : fname = 'Library.xml'
# <key>Track ID</key><integer>369</integer>
# <key>Name</key><string>Another One Bites The Dust</string>
# <key>Artist</key><string>Queen</string>
def lookup(d, key):
found = False
for child in d:
if found : return child.text
if child.tag == 'key' and child.text == key :
found = True
return None
stuff = ET.parse(fname)
all = stuff.findall('dict/dict/dict')
print('Dict count:', len(all))
for entry in all:
if ( lookup(entry, 'Track ID') is None ) : continue
name = lookup(entry, 'Name')
artist = lookup(entry, 'Artist')
album = lookup(entry, 'Album')
count = lookup(entry, 'Play Count')
rating = lookup(entry, 'Rating')
length = lookup(entry, 'Total Time')
if name is None or artist is None or album is None :
continue
print(name, artist, album, count, rating, length)
cur.execute('''INSERT OR IGNORE INTO Artist (name)
VALUES ( ? )''', ( artist, ) )
cur.execute('SELECT id FROM Artist WHERE name = ? ', (artist, ))
artist_id = cur.fetchone()[0]
cur.execute('''INSERT OR IGNORE INTO Album (title, artist_id)
VALUES ( ?, ? )''', ( album, artist_id ) )
cur.execute('SELECT id FROM Album WHERE title = ? ', (album, ))
album_id = cur.fetchone()[0]
cur.execute('''INSERT OR REPLACE INTO Track
(title, album_id, len, rating, count)
VALUES ( ?, ?, ?, ?, ? )''',
( name, album_id, length, rating, count ) )
conn.commit()
使用python脚本建立数据库的过程,注意其中的关键字IGNORE,它的作用是如果当期数据存在,那就不插入,否则插入。在这个地方十分有用,因为索引不能随意变化。
作业代码
import xml.etree.ElementTree as ET
import sqlite3
conn = sqlite3.connect('trackdb.sqlite')
cur = conn.cursor()
# Make some fresh tables using executescript()
cur.executescript('''
DROP TABLE IF EXISTS Artist;
DROP TABLE IF EXISTS Album;
DROP TABLE IF EXISTS Track;
DROP TABLE IF EXISTS Genre;
CREATE TABLE Artist (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
name TEXT UNIQUE
);
CREATE TABLE Genre (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
name TEXT UNIQUE
);
CREATE TABLE Album (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
artist_id INTEGER,
title TEXT UNIQUE
);
CREATE TABLE Track (
id INTEGER NOT NULL PRIMARY KEY
AUTOINCREMENT UNIQUE,
title TEXT UNIQUE,
album_id INTEGER,
genre_id INTEGER,
len INTEGER, rating INTEGER, count INTEGER
);
''')
fname = input('Enter file name: ')
if ( len(fname) < 1 ) : fname = 'Library.xml'
# <key>Track ID</key><integer>369</integer>
# <key>Name</key><string>Another One Bites The Dust</string>
# <key>Artist</key><string>Queen</string>
def lookup(d, key):
found = False
for child in d:
if found : return child.text
if child.tag == 'key' and child.text == key :
found = True
return None
stuff = ET.parse(fname)
all = stuff.findall('dict/dict/dict')
print('Dict count:', len(all))
for entry in all:
if ( lookup(entry, 'Track ID') is None ) : continue
name = lookup(entry, 'Name')
artist = lookup(entry, 'Artist')
album = lookup(entry, 'Album')
genre = lookup(entry,'Genre')
count = lookup(entry, 'Play Count')
rating = lookup(entry, 'Rating')
length = lookup(entry, 'Total Time')
if name is None or artist is None or album is None or genre is None:
continue
print(name, artist, album, genre, count, rating, length)
cur.execute('''INSERT OR IGNORE INTO Artist (name)
VALUES ( ? )''', ( artist, ) )
cur.execute('SELECT id FROM Artist WHERE name = ? ', (artist, ))
artist_id = cur.fetchone()[0]
cur.execute('''INSERT OR IGNORE INTO Album (title, artist_id)
VALUES ( ?, ? )''', ( album, artist_id ) )
cur.execute('SELECT id FROM Album WHERE title = ? ', (album, ))
album_id = cur.fetchone()[0]
cur.execute('''INSERT OR IGNORE INTO Genre (name)
VALUES ( ? )''', ( genre, ) )
cur.execute('SELECT id FROM Genre WHERE name = ? ', (genre, ))
genre_id = cur.fetchone()[0]
cur.execute('''INSERT OR REPLACE INTO Track
(title, album_id, genre_id, len, rating, count)
VALUES ( ?, ?, ?, ?, ? ,?)''',
( name, album_id, genre_id, length, rating, count ) )
conn.commit()
《Using Databases with Python》Week3 Data Models and Relational SQL 课堂笔记的更多相关文章
- 《Using Databases with Python》 Week2 Basic Structured Query Language 课堂笔记
Coursera课程<Using Databases with Python> 密歇根大学 Week2 Basic Structured Query Language 15.1 Relat ...
- 【Python学习笔记】Coursera课程《Using Databases with Python》 密歇根大学 Charles Severance——Week4 Many-to-Many Relationships in SQL课堂笔记
Coursera课程<Using Databases with Python> 密歇根大学 Week4 Many-to-Many Relationships in SQL 15.8 Man ...
- 《Python Data Structures》Week5 Dictionary 课堂笔记
Coursera课程<Python Data Structures> 密歇根大学 Charles Severance Week5 Dictionary 9.1 Dictionaries 字 ...
- 《Python Data Structures》 Week4 List 课堂笔记
Coursera课程<Python Data Structures> 密歇根大学 Charles Severance Week4 List 8.2 Manipulating Lists 8 ...
- 潭州课堂25班:Ph201805201 python 模块json,os 第六课 (课堂笔记)
json 模块 import json data = { 'name':'aa', 'age':18, 'lis':[1,3,4], 'tupe':(4,5,6), 'None':None } j = ...
- Mongodb Manual阅读笔记:CH3 数据模型(Data Models)
3数据模型(Data Models) Mongodb Manual阅读笔记:CH2 Mongodb CRUD 操作Mongodb Manual阅读笔记:CH3 数据模型(Data Models)Mon ...
- 《Using Databases with Python》Week1 Object Oriented Python 课堂笔记
Coursera课程<Using Databases with Python> 密歇根大学 Charles Severance Week1 Object Oriented Python U ...
- 数据分析---《Python for Data Analysis》学习笔记【04】
<Python for Data Analysis>一书由Wes Mckinney所著,中文译名是<利用Python进行数据分析>.这里记录一下学习过程,其中有些方法和书中不同 ...
- 数据分析---《Python for Data Analysis》学习笔记【03】
<Python for Data Analysis>一书由Wes Mckinney所著,中文译名是<利用Python进行数据分析>.这里记录一下学习过程,其中有些方法和书中不同 ...
随机推荐
- MySQL的简单条件判断语句
在MySQL中条件判断语句常用于数据转换,基于现有数据创建新的数据列,使用场景还是比较多. 基础样式: CASE WHEN`条件`THEN`结果` ELSE`默认结果` END 在同一条判断语句中可以 ...
- MongoDB入门_shell基本操作
使用shell客户端连接mongoDB数据库 [root@localhost mongodb_simple]# ./bin/mongo /admin mongoDB的简单基本操作 1. mongoDB ...
- netty学习第5章 netty整合websocket
学习netty之后,可能都有一个疑问,就是如何选择一个编码.解码器,在netty中的编解码可是和json这种编解码是不一样的,netty的编解码器主要是解决TCP粘包.拆包的问题.netty中有许多自 ...
- Python---面向对象的三大特征
# 面向对象的三大特征 - 继承 - 封装 - 多态 # 继承 - 子类可以使用父类定义的内容或者行为等 - 继承的实现 - 父类:基类,超类:被继承的类, Base Class, Super Cla ...
- oracle基本语句(第五章、数据库逻辑存储结构管理)
1.使用SYS用户以SYSDBA身份登录到SQL Plus,使用视图V$TABLESPACE查看表空间信息 SELECT * FROM V$TABLESPACE; 2.查看视图DBA_TABLESPA ...
- 【NOIP2016提高A组模拟8.15】Password
题目 分析 首先我们知道,原A序列其实表示一个矩阵,而这个矩阵的对角线上的数字就是答案B序列. 接着\(a.b>=gcd(a,b)\),所以序列A中的最大的数就是ans[1],第二大的数就是an ...
- shell练习--PAT题目1007:关于素数对(失败案例)
让我们定义dn为:dn=pn+1−pn,其中pi是第i个素数.显然有d1=1,且对于n>1有dn是偶数.“素数对猜想”认为“存在无穷多对相邻且差为2的素 ...
- mobx使用
1.mobx状态管理 安装:creact-react-app mobx action.store.reducer. action是一个函数,事件调用actions直接修改state,Actions是唯 ...
- eclipse在线安装ermaster插件
eclipse在线安装ermaster插件: https://www.jianshu.com/p/449fbcd9141a ERMaster的安装和使用 https://www.cnblogs.com ...
- Linux入门培训教程 linux系统中文件I/O教程
linux 文件I/O教程 一,文件描述符 对内核而言,所以打开的文件都通过文件描述符引用.每个进程都有一些与之关联的文件描述符.文件描述符是一个非负整数.当打开一个现有文件或创建一个新文件时,内核向 ...