【原创】Talend ETL Job日志框架——基于P&G项目的一些思考和优化
一、背景
接触talend也挺长一段时间了,在P&G项目中每天都是使用它开发job,做ETL,也看了前辈开发的很多ETL Job,学到不少。也接触了TAC(talend administration center),也发现了TAC的一些优点和不足。
优点:
1、TAC可以更好的界面化管理job、部署、HA等,提升了job运行的良好环境。
2、通过plan可以更好的将不同的job进行关联成线,更好的对数据处理做到前后顺序有秩。
3、日志比较全,还可以选择不同的日志级别。
缺点:
1、整个管理前端是基于tomcat的,而且整个管理网站效率不是特别好,使用起来相对没有C/S端的流畅。
2、时不时会因为系统的一些稳定性问题,带来一些job运行上的异常,而且这部分监控无法捕获。
3、整个网页使用起来不是非常的顺手,主要体现在:卡顿、时不时刷新下、偶尔出现异常等。
4、运行统计上面不是符合所有的场景,比如P&G,他们job是分层(STG,DWD,DWS,DM)的,即每一层的数据都是不同的job,这个时候的统计就不能仅仅是按照job运行来统计,有时候要几个job合并,有时候要这个job取一点数据,另一个job取一点数据,这种场景下就不适合了。
还有一点就是P&G大部分都是通过job来调用存储过程来计算,这就带来2个不和谐的地方,其一无法得知那个job使用哪些存储过程或者调用过哪些存储过程,只能通过名称的约定来得知,显然这种方式对于追溯引用不是非常的方便。其次就是对于job和存储过程的统计无法产生关联性,对于后期的一些性能分析无法提供辅助数据依据。
因此,我们有这样子的一些需求:
1、能很方便的提供每个job执行的记录,比如常规的:开始时间、结束时间、耗时、属于哪块业务范围等。
2、Job和存储过程的关系,哪些job调用了哪些存储过程,并且这些存储过程的执行记录等。
二、实现
1、 数据库表设计
a) Job记录表
该表主要是记录每个job的信息,在一个job上了production环境的时候,就要在此表生成相应的记录。
|
IF (OBJECT_ID(N'[chk].[etl_job_list]', N'U') IS NOT NULL) BEGIN PRINT N'删除表:[chk].[etl_job_list]'; DROP TABLE [chk].[etl_job_list]; END GO CREATE TABLE [chk].[etl_job_list] ( [scope] NVARCHAR(200) NOT NULL,--业务板块说明,每个job归类于一类scope,如IDS,发货、零售等 [etl_job_id] NVARCHAR(100) NOT NULL,--UNIQUEIDENTIFIER用NEWID生成并转CHAR存储 [etl_job_name] NVARCHAR(200) NOT NULL,--etl job名称, [create_user] NVARCHAR(50) NOT NULL,--创建者 [create_date] DATETIME NOT NULL,--创建日期 [last_update_date] DATETIME NOT NULL,--最后更新日期 [remark] NVARCHAR(200) NULL--说明 ) GO |
对应的存储过程,因为adw不支持唯一索引,但是job name需要有唯一约束的,所以通过创建存储过程来创建可以避免唯一冲突。
存储过程:
|
IF (OBJECT_ID(N'[chk].[usp_insert_etl_job_list]', N'P') IS NOT NULL) BEGIN PRINT N'删除存储过程:[chk].[usp_insert_etl_job_list]'; DROP PROC [chk].[usp_insert_etl_job_list]; END GO CREATE PROC [chk].[usp_insert_etl_job_list] ( @scope NVARCHAR(200) ,@etl_job_name NVARCHAR(200) ,@create_user NVARCHAR(50) ,@remark NVARCHAR(200) ) AS --==================================================================================================================================== -- ProcedureName : chk.usp_insert_etl_job_list -- Author : john.xiong -- CreateDate : 2019-01-16 -- Description : insert data to chk.etl_job_list /*************************************Parameters参数说明******************************************************************************* -- @scope : 业务板块说明,每个job归类于一类scope,如IDS,发货、零售等 -- @etl_job_name : etl job 名称 -- @create_user : 创建用户 -- @remark : 说明/备注 **************************************Modfied List修改记录***************************************************************************** -- Modified Date Modified User Version Modified Reason ************************************************************************************************************************************** -- 2019-01-16 john.xiong V01.00.00 初始化版本 **************************************************************************************************************************************/ --==================================================================================================================================== BEGIN BEGIN TRY DECLARE @begin_time DATETIME ,@end_time DATETIME ,@cost_time INT ,@create_date DATETIME ,@last_update_date DATETIME ,@etl_job_id NVARCHAR(100) ,@row_count INT SET @begin_time = DATEADD(HOUR, 8, GETDATE()); INSERT INTO [chk].[tb_proc_cost_log] ( [proc_name] ,[Object_name] ,[execute_time] ,[action] ,[remark] ,[cost_time] ) SELECT N'chk.usp_insert_etl_job_list' AS [proc_name] ,N'chk.etl_job_list' AS [Object_name] ,@begin_time AS [execute_time] ,N'start' AS [action] ,'' AS [remark] ,0 AS [cost_time] IF (LTRIM(RTRIM(ISNULL(@etl_job_name, ''))) = '') BEGIN RAISERROR(N'etl job name不能为null或者空,请重新输入!', 16, 1); END SET @row_count = 0; SELECT @row_count = COUNT(*) FROM [chk].[etl_job_list] WHERE LOWER([etl_job_name]) = LOWER(@etl_job_name); IF (@row_count > 0)/*etl job name唯一性校验,保证唯一性*/ BEGIN RAISERROR(N'etl job name已经存在,请重新输入!', 16, 1); END SET @scope = ISNULL(@scope, '缺省'); SET @create_user = ISNULL(@create_user, CONVERT(NVARCHAR(50), SUSER_SNAME())); SET @remark = ISNULL(@remark, ''); SET @create_date = DATEADD(HOUR, 8, GETDATE()); SET @last_update_date = @create_date; SET @etl_job_id = CONVERT(NVARCHAR(100), NEWID()); INSERT INTO [chk].[etl_job_list] ( [scope] ,[etl_job_id] ,[etl_job_name] ,[create_user] ,[create_date] ,[last_update_date] ,[remark] ) SELECT @scope ,@etl_job_id ,@etl_job_name ,@create_user ,@create_date ,@last_update_date ,@remark SET @end_time = DATEADD(HOUR, 8, GETDATE()); SET @cost_time = DATEDIFF(SECOND, @begin_time, @end_time); INSERT INTO [chk].[tb_proc_cost_log] ( [proc_name] ,[Object_name] ,[execute_time] ,[action] ,[remark] ,[cost_time] ) SELECT N'chk.usp_insert_etl_job_list' AS [proc_name] ,N'chk.etl_job_list' AS [Object_name] ,@end_time AS [execute_time] ,N'end' AS [action] ,CONVERT(NVARCHAR(50), @etl_job_id) AS [remark] ,@cost_time AS [cost_time] PRINT N'Exec success'; PRINT N'curr_etl_job_id=' + @etl_job_id; END TRY BEGIN CATCH INSERT INTO [chk].[log_proc_error_rec] ( [proc_name] ,[error_source] ,[error_time] ,[error_severity] ,[error_state] ,[error_msg] ,[log_user] ) SELECT N'chk.usp_insert_etl_job_list' AS [proc_name] ,ERROR_PROCEDURE() AS [error_source] ,DATEADD(HOUR, 8, GETDATE()) AS [error_time] ,ERROR_SEVERITY() AS [error_severity] ,ERROR_STATE() AS [error_state] ,ERROR_MESSAGE() AS [error_msg] ,SUSER_SNAME() AS [log_user] PRINT N'Exec failed'; END CATCH END |
b) Job运行记录表
记录每个job的每次运行的情况,如开始结束时间,用于计算耗时,运行状态等是是否报错,用于后期弥补tac调度的不足,例如可以自定义循环判断job是否成功,自定义配置job之间的运行依赖等。
|
IF (OBJECT_ID(N'[chk].[etl_job_excc_history]', N'U') IS NOT NULL) BEGIN PRINT N'删除表:[chk].[etl_job_excc_history]'; DROP TABLE [chk].[etl_job_excc_history]; END GO CREATE TABLE [chk].[etl_job_excc_history] ( [exec_id] NVARCHAR(100) NOT NULL,--UNIQUEIDENTIFIER用NEWID生成并转CHAR存储 [etl_job_id] NVARCHAR(100) NOT NULL,--UNIQUEIDENTIFIER用NEWID生成并转CHAR存储 [etl_job_name] NVARCHAR(200) NOT NULL,--etl job名称, [begin_date] DATETIME NULL, --etl job运行开始时间 [end_date] DATETIME NULL, --etl job运行结束时间,如果没有结束时间就有可能是运行报错。 [exec_status] INT NULL, --0:运行报错,1运行成功,2正在运行 [remark] NVARCHAR(500) NULL,--说明,如果是报错就是错误信息。 [create_date] DATETIME NOT NULL, --创建日期 [create_user] NVARCHAR(50) NOT NULL--创建人 ) |
存储过程:分为insert和update两个,用于创建和更新
创建的exec_id参数其实可以在存储过程中生成,并且使用out属性输出,这样子就不用每次都传递一个参数进去,但是因为P&G的adw数据仓库不支持out参数,所以只能使用talend生成一个全局的guid传递进去,这样子才能保证同一个ID的操作和更新等。
|
IF (OBJECT_ID(N'[chk].[usp_insert_etl_job_excc_history]', N'P') IS NOT NULL) BEGIN PRINT N'删除存储过程:[chk].[usp_insert_etl_job_excc_history]'; DROP PROC [chk].[usp_insert_etl_job_excc_history]; END GO CREATE PROC [chk].[usp_insert_etl_job_excc_history] ( @exec_id NVARCHAR(100) ,@etl_job_name NVARCHAR(200) ,@begin_date DATETIME ) AS --==================================================================================================================================== -- ProcedureName : chk.usp_insert_etl_job_excc_history -- Author : john.xiong -- CreateDate : 2019-01-16 -- Description : insert data to chk.etl_job_excc_history /*************************************Parameters参数说明******************************************************************************* -- @exec_id : UNIQUEIDENTIFIER用NEWID生成并转CHAR存储 -- @etl_job_id : etl job id UNIQUEIDENTIFIER用NEWID生成并转CHAR存储 -- @etl_job_name : etl job 名称 -- @begin_date : job运行开始时间 **************************************Modfied List修改记录***************************************************************************** -- Modified Date Modified User Version Modified Reason ************************************************************************************************************************************** -- 2019-01-16 john.xiong V01.00.00 初始化版本 **************************************************************************************************************************************/ --==================================================================================================================================== BEGIN BEGIN TRY DECLARE @begin_time DATETIME ,@end_time DATETIME ,@cost_time INT ,@row_count INT ,@etl_job_id NVARCHAR(100) ,@end_date DATETIME ,@exec_status INT ,@remark NVARCHAR(500) ,@create_date DATETIME ,@create_user NVARCHAR(50) SET @begin_time = DATEADD(HOUR, 8, GETDATE()); INSERT INTO [chk].[tb_proc_cost_log] ( [proc_name] ,[Object_name] ,[execute_time] ,[action] ,[remark] ,[cost_time] ) SELECT N'chk.usp_insert_etl_job_excc_history' AS [proc_name] ,N'chk.etl_job_excc_history' AS [Object_name] ,@begin_time AS [execute_time] ,N'start' AS [action] ,'' AS [remark] ,0 AS [cost_time] SET @row_count = 0; SELECT @row_count = COUNT(*) FROM [chk].[etl_job_list] WHERE LOWER([etl_job_name]) = LOWER(@etl_job_name); IF (@row_count = 0)/*etl job name唯一性校验,保证唯一性*/ BEGIN RAISERROR(N'etl job name不存在,请重新输入!', 16, 1); END SELECT TOP (1) @etl_job_id = [etl_job_id] FROM [chk].[etl_job_list] WHERE LOWER([etl_job_name]) = LOWER(@etl_job_name) ORDER BY [create_date] DESC SET @begin_date = ISNULL(@begin_date, DATEADD(HOUR, 8, GETDATE())); SET @end_date = NULL; SET @exec_status = 2; SET @remark = NULL; SET @create_date = DATEADD(HOUR, 8, GETDATE()); SET @create_user = CONVERT(NVARCHAR(50), SUSER_SNAME()); INSERT INTO [chk].[etl_job_excc_history] ( [exec_id] ,[etl_job_id] ,[etl_job_name] ,[begin_date] ,[end_date] ,[exec_status] ,[remark] ,[create_date] ,[create_user] ) SELECT @exec_id ,@etl_job_id ,@etl_job_name ,@begin_date ,@end_date ,@exec_status ,@remark ,@create_date ,@create_user SET @end_time = DATEADD(HOUR, 8, GETDATE()); SET @cost_time = DATEDIFF(SECOND, @begin_time, @end_time); INSERT INTO [chk].[tb_proc_cost_log] ( [proc_name] ,[Object_name] ,[execute_time] ,[action] ,[remark] ,[cost_time] ) SELECT N'chk.usp_insert_etl_job_excc_history' AS [proc_name] ,N'chk.etl_job_excc_history' AS [Object_name] ,@end_time AS [execute_time] ,N'end' AS [action] ,CONVERT(NVARCHAR(50), @etl_job_id) AS [remark] ,@cost_time AS [cost_time] PRINT N'Exec success'; PRINT N'curr_exec_id=' + @exec_id; END TRY BEGIN CATCH INSERT INTO [chk].[log_proc_error_rec] ( [proc_name] ,[error_source] ,[error_time] ,[error_severity] ,[error_state] ,[error_msg] ,[log_user] ) SELECT N'chk.usp_insert_etl_job_excc_history' AS [proc_name] ,ERROR_PROCEDURE() AS [error_source] ,DATEADD(HOUR, 8, GETDATE()) AS [error_time] ,ERROR_SEVERITY() AS [error_severity] ,ERROR_STATE() AS [error_state] ,ERROR_MESSAGE() AS [error_msg] ,SUSER_SNAME() AS [log_user] PRINT N'Exec failed'; END CATCH END |
|
IF (OBJECT_ID(N'[chk].[usp_update_etl_job_excc_history_by_exec_id]', N'P') IS NOT NULL) BEGIN PRINT N'删除存储过程:[chk].[usp_update_etl_job_excc_history_by_exec_id]'; DROP PROC [chk].[usp_update_etl_job_excc_history_by_exec_id]; END GO CREATE PROC [chk].[usp_update_etl_job_excc_history_by_exec_id] ( @exec_id NVARCHAR(100) ,@end_date DATETIME ,@exec_status INT ,@remark NVARCHAR(500) ) AS --==================================================================================================================================== -- ProcedureName : chk.usp_update_etl_job_excc_history_by_exec_id -- Author : john.xiong -- CreateDate : 2019-01-16 -- Description : update data to chk.etl_job_excc_history /*************************************Parameters参数说明******************************************************************************* -- @exec_id : 执行的GUID -- @end_date : etl job 名称 -- @exec_status : job运行状态0运行错误,1运行成功,2正在运行.... -- @remark : 说明,如错误信息等 **************************************Modfied List修改记录***************************************************************************** -- Modified Date Modified User Version Modified Reason ************************************************************************************************************************************** -- 2019-01-16 john.xiong V01.00.00 初始化版本 **************************************************************************************************************************************/ --==================================================================================================================================== BEGIN BEGIN TRY DECLARE @begin_time DATETIME ,@end_time DATETIME ,@cost_time INT ,@row_count INT SET @begin_time = DATEADD(HOUR, 8, GETDATE()); INSERT INTO [chk].[tb_proc_cost_log] ( [proc_name] ,[Object_name] ,[execute_time] ,[action] ,[remark] ,[cost_time] ) SELECT N'chk.usp_update_etl_job_excc_history_by_exec_id' AS [proc_name] ,N'chk.etl_job_excc_history' AS [Object_name] ,@begin_time AS [execute_time] ,N'start' AS [action] ,'' AS [remark] ,0 AS [cost_time] SET @row_count = 0; SELECT @row_count = COUNT(*) FROM [chk].[etl_job_excc_history] WHERE [exec_id] = @exec_id; IF (@row_count = 0)/*检查exec id是否存在*/ BEGIN RAISERROR(N'exec id不存在,请重新输入!', 16, 1); END IF (ISNULL(@exec_status, -1) = -1) BEGIN RAISERROR(N'exec status不能为空,请重新输入!', 16, 1); END SET @end_date = ISNULL(@end_date, DATEADD(HOUR, 8, GETDATE())); SET @remark = ISNULL(@remark, ''); UPDATE [chk].[etl_job_excc_history] SET end_date = @end_date, [exec_status] = @exec_status, [remark] = @remark WHERE [exec_id] = @exec_id; SET @end_time = DATEADD(HOUR, 8, GETDATE()); SET @cost_time = DATEDIFF(SECOND, @begin_time, @end_time); INSERT INTO [chk].[tb_proc_cost_log] ( [proc_name] ,[Object_name] ,[execute_time] ,[action] ,[remark] ,[cost_time] ) SELECT N'chk.usp_update_etl_job_excc_history_by_exec_id' AS [proc_name] ,N'chk.etl_job_excc_history' AS [Object_name] ,@end_time AS [execute_time] ,N'end' AS [action] ,CONVERT(NVARCHAR(50), @exec_id) AS [remark] ,@cost_time AS [cost_time] PRINT N'Exec success'; PRINT N'curr_exec_id=' + @exec_id; END TRY BEGIN CATCH INSERT INTO [chk].[log_proc_error_rec] ( [proc_name] ,[error_source] ,[error_time] ,[error_severity] ,[error_state] ,[error_msg] ,[log_user] ) SELECT N'chk.usp_update_etl_job_excc_history_by_exec_id' AS [proc_name] ,ERROR_PROCEDURE() AS [error_source] ,DATEADD(HOUR, 8, GETDATE()) AS [error_time] ,ERROR_SEVERITY() AS [error_severity] ,ERROR_STATE() AS [error_state] ,ERROR_MESSAGE() AS [error_msg] ,SUSER_SNAME() AS [log_user] PRINT N'Exec failed'; END CATCH END |
c) Job&存储过程运行记录表
该表用于记录每个job 调用存储过程的情况,如开始结束时间等,也可以记录下哪些job调用了哪些存储过程,方便查询每个job和存储过程之间的关系。
Ø 参数中的etl_job_name需要用talend的jobName全局变量带入。
Ø 剩余的其它参数是该存储过程实际需要的,用于做业务逻辑处理的参数。
|
IF (OBJECT_ID(N'[chk].[etl_job_proc_exec_history]', N'U') IS NOT NULL) BEGIN PRINT N'删除表:[chk].[etl_job_proc_exec_history]'; DROP TABLE [chk].[etl_job_proc_exec_history]; END GO CREATE TABLE [chk].[etl_job_proc_exec_history] ( [exec_id] NVARCHAR(100) NOT NULL,--UNIQUEIDENTIFIER用NEWID生成并转CHAR存储 [proc_name] NVARCHAR(100) NOT NULL,--存储过程名 [object_name] NVARCHAR(100) NOT NULL,--操作的对象名字,大部分是表名字、也可以是其它的视图等 [etl_job_id] NVARCHAR(100) NOT NULL,--UNIQUEIDENTIFIER用NEWID生成并转CHAR存储 [etl_job_name] NVARCHAR(200) NOT NULL,--etl job名称, [begin_date] DATETIME NULL, --调用开始时间 [end_date] DATETIME NULL, --调用结束时间,如果没有结束时间就有可能是运行报错。 [error_msg] NVARCHAR(4000) NULL,--错误信息 [remark] NVARCHAR(500) NULL,--备注说明 [create_date] DATETIME NOT NULL, --创建日期 [create_user] NVARCHAR(50) NOT NULL,--创建人 [last_update_date] DATETIME NULL ) GO |
d) 业务执行的存储过程的改造
存储过程需要增加一个参数@etl_job_name,这个是在talend中调用存储过程的时候一起传递进来的。
其它的参数都是核心业务处理需要的,和以前的一样。
如下是一个测试的存储过程
|
IF (OBJECT_ID(N'[chk].[usp_job_proc_exec_his_test]', N'P') IS NOT NULL) BEGIN PRINT N'删除存储过程:[chk].[usp_job_proc_exec_his_test]'; DROP PROC [chk].[usp_job_proc_exec_his_test]; END GO CREATE PROC [chk].[usp_job_proc_exec_his_test] ( @etl_job_name NVARCHAR(200) ,@currDate NVARCHAR(20)/*业务处理逻辑需要用的参数*/ ) AS BEGIN BEGIN TRY DECLARE @exec_id NVARCHAR(100) ,@proc_name NVARCHAR(100) ,@object_name NVARCHAR(100) ,@etl_job_id NVARCHAR(100) ,@begin_date DATETIME ,@end_date DATETIME ,@error_msg NVARCHAR(4000) ,@remark NVARCHAR(500) ,@create_date DATETIME ,@create_user NVARCHAR(50) ,@last_update_date DATETIME SET @etl_job_id = ''; SELECT @etl_job_id = [a].[etl_job_id] FROM [chk].[etl_job_list] AS a WHERE LOWER([a].[etl_job_name]) = LOWER(@etl_job_name) SET @etl_job_id = ISNULL(@etl_job_id, ''); SET @exec_id = CONVERT(NVARCHAR(100), NEWID());/*生成exec_id*/ SET @proc_name = 'chk.job_proc_exec_his_test'; SET @object_name = 'you_table_name';/*例如:stg.envt_ids_sales_daily*/ SET @begin_date = DATEADD(HOUR, 8, GETDATE()); SET @create_date = @begin_date; SET @last_update_date = @create_date; SET @create_user = CONVERT(NVARCHAR(50), SUSER_SNAME()); SET @end_date = NULL; SET @remark = @currDate; /*记录开始*/ INSERT INTO [chk].[etl_job_proc_exec_history] ( [exec_id] ,[proc_name] ,[object_name] ,[etl_job_id] ,[etl_job_name] ,[begin_date] ,[end_date] ,[error_msg] ,[remark] ,[create_date] ,[create_user] ,[last_update_date] ) SELECT @exec_id ,@proc_name ,@object_name ,@etl_job_id ,@etl_job_name ,@begin_date ,@end_date ,NULL ,@remark ,@create_date ,@create_user ,@last_update_date /*其它的业务处理逻辑*/ --SELECT 1/0 AS [ret]/*样例:有意引发错误*/ SELECT DATEADD(HOUR, 8, GETDATE()); /*记录正常结束*/ SET @end_date = DATEADD(HOUR, 8, GETDATE()); SET @last_update_date = @end_date; UPDATE [chk].[etl_job_proc_exec_history] SET [end_date] = @end_date, [last_update_date] = @last_update_date WHERE [exec_id] = @exec_id; PRINT N'Exec success'; END TRY BEGIN CATCH INSERT INTO [chk].[log_proc_error_rec] ( [proc_name] ,[error_source] ,[error_time] ,[error_severity] ,[error_state] ,[error_msg] ,[log_user] ) SELECT N'chk.job_proc_exec_his_test' AS [proc_name] ,ERROR_PROCEDURE() AS [error_source] ,DATEADD(HOUR, 8, GETDATE()) AS [error_time] ,ERROR_SEVERITY() AS [error_severity] ,ERROR_STATE() AS [error_state] ,ERROR_MESSAGE() AS [error_msg] ,SUSER_SNAME() AS [log_user] /*记录异常结束*/ SET @end_date = DATEADD(HOUR, 8, GETDATE()); SET @last_update_date = @end_date; SET @error_msg = ERROR_MESSAGE(); UPDATE [chk].[etl_job_proc_exec_history] SET [end_date] = @end_date, [error_msg] = @error_msg, [last_update_date] = @last_update_date WHERE [exec_id] = @exec_id; PRINT N'Exec failed'; END CATCH END |
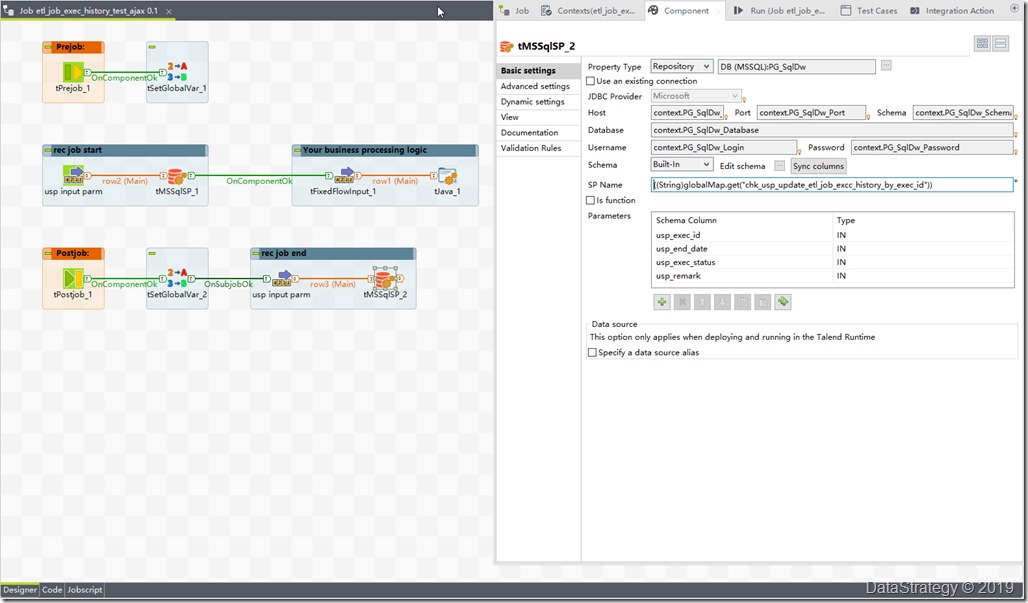
2、 talend job记录每个job的开始和结束信息
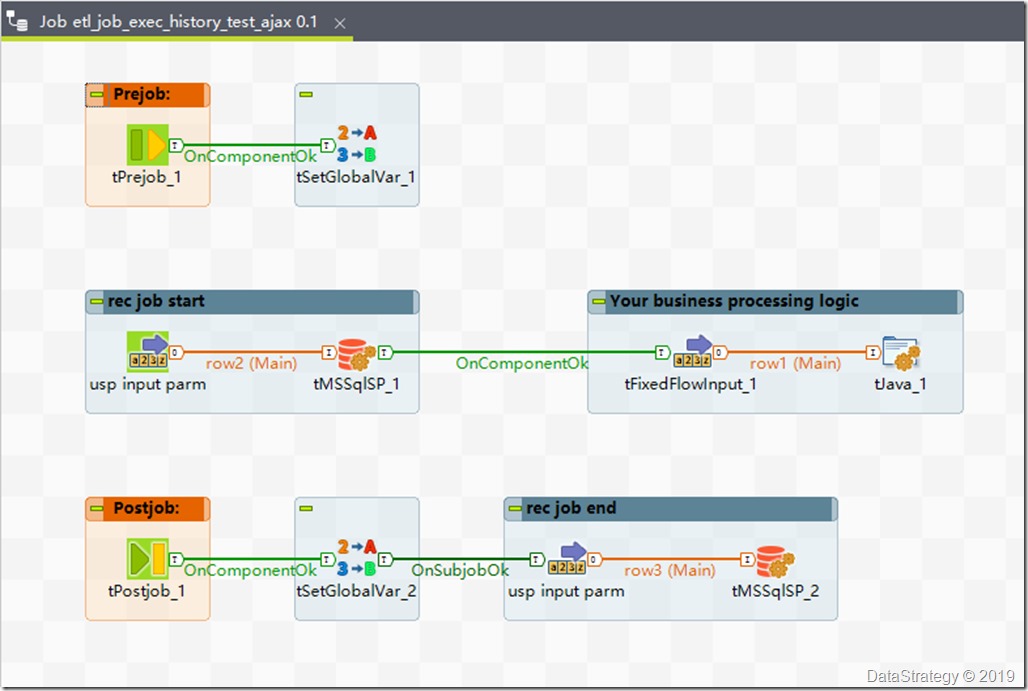
设置exec id,通过UUID获取,还有其它的一些变量
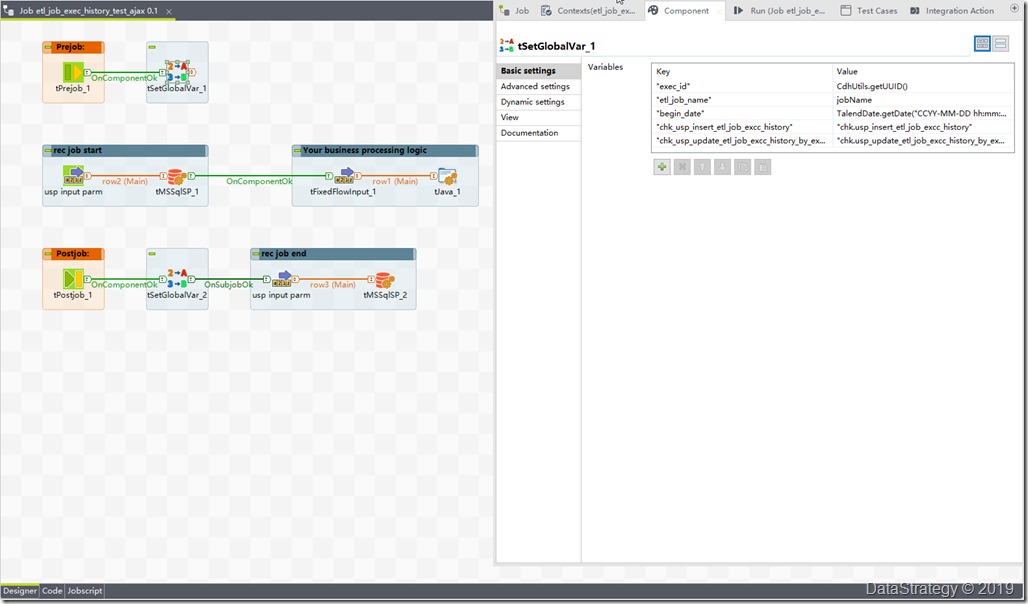
记录开始
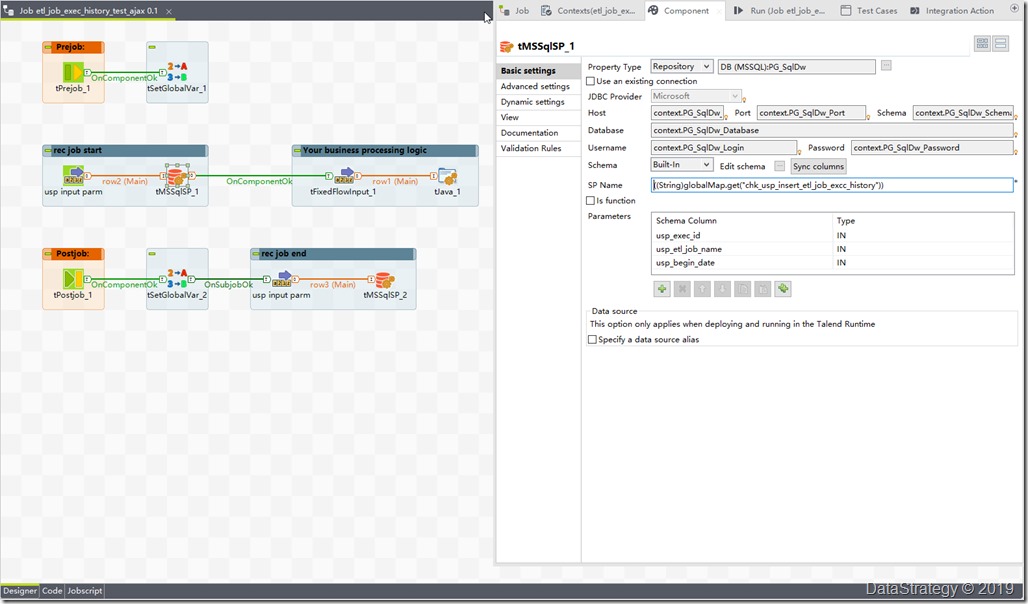
创建结束的一些参数
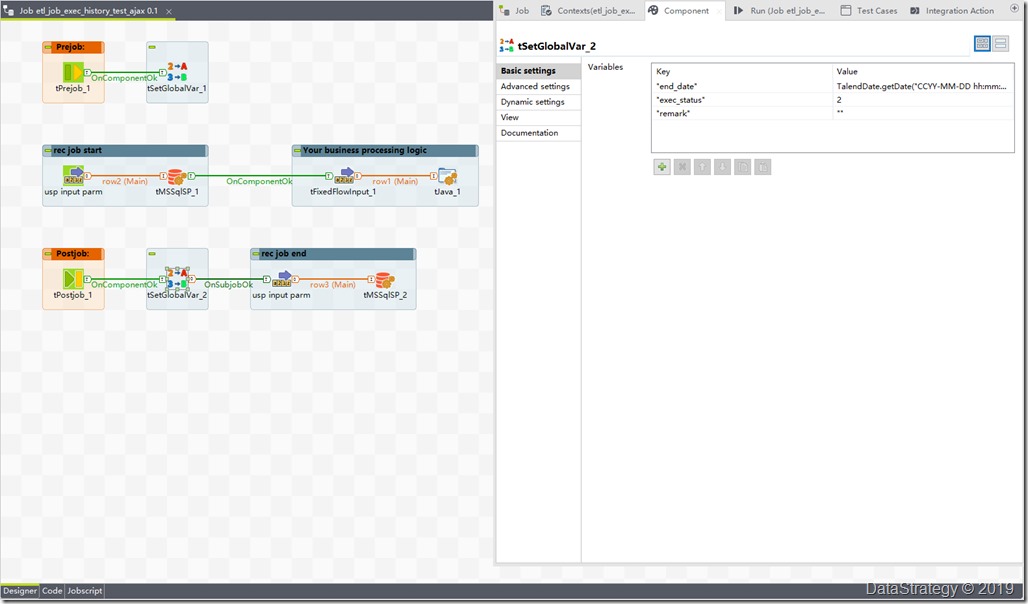
更新结束的记录
三、总结
1、 Talend 的tac因为一些调度薄弱,所以我们的job就需要记录更多的一些信息来辅助后期的管理和追查原因。
2、 借助这套日志小框架,我们也可以更好的管理talend通过调用存储过程这样子的方式的job,提升一些可管理性、错误识别方面的能力。
3、 Talend的job的统一错误处理感觉还是比较薄弱,就是能有一个统一的错误处理的如果,而不用依赖于每个组件去判断是否有发生错误。(可能我还没有发现吧)
如果您觉得此文章对您有帮助,请点击右下方【推荐】让更多人看到,thanks!
【原创】Talend ETL Job日志框架——基于P&G项目的一些思考和优化的更多相关文章
- AOP日志框架实现
AOP日志框架实现 JDK动态代理实现日志框架 首先,在项目包com.ay.test 下创建业务接口类BusinessClassService,具体代码如下: BusinessC lassServic ...
- iOS基于MVC的项目重构总结
关于MVC的争论 关于MVC的争论已经有很多,对此我的观点是:对于iOS开发中的绝大部分场景来说,MVC本身是没有问题的,你认为的MVC的问题,一定是你自己理解的问题(资深架构师请自动忽略本文). 行 ...
- 转:iOS基于MVC的项目重构总结
转:http://www.cocoachina.com/ios/20160519/16346.html 关于MVC的争论 关于MVC的争论已经有很多,对此我的观点是:对于iOS开发中的绝大部分场景来说 ...
- iOS 基于 MVC 的项目重构总结
关于MVC的争论 关于MVC的争论已经有非常多,对此我的观点是:对于iOS开发中的绝大部分场景来说,MVC本身是没有问题的,你觉得的MVC的问题,一定是你自己理解的问题(资深架构师请自己主动忽略本文) ...
- 转:Java程序员最常用的8个Java日志框架
作为一名Java程序员,我们开发了很多Java应用程序,包括桌面应用.WEB应用以及移动应用.然而日志系统是一个成熟Java应用所必不可少的,在开发和调试阶段,日志可以帮助我们更好更快地定位bug:在 ...
- Spring Boot干货系列:(七)默认日志框架配置
Spring Boot干货系列:(七)默认日志框架配置 原创 2017-04-05 嘟嘟MD 嘟爷java超神学堂 前言 今天来介绍下Spring Boot如何配置日志logback,我刚学习的时候, ...
- Spring Boot第四弹,一文教你如何无感知切换日志框架?
持续原创输出,点击上方蓝字关注我吧 目录 前言 Spring Boot 版本 什么是日志门面? 如何做到无感知切换? 如何切换? 引入依赖 指定配置文件 日志如何配置? 总结 前言 首先要感谢一下读者 ...
- 解读ASP.NET 5 & MVC6系列(9):日志框架
框架介绍 在之前的.NET中,微软还没有提供过像样的日志框架,目前能用的一些框架比如Log4Net.NLog.CommonLogging使用起来多多少少都有些费劲,和java的SLF4J根本无法相比. ...
- log4net 日志框架的配置
log4net 日志框架的配置——静态文件(一) 添加对log4net程序集的引用 选择程序集文件添加引用即可,需要注意的是需要添加相应程序版本的程序集,如果你的应用是基于.netFramework2 ...
随机推荐
- 5 Post实现django表单
本节大纲 1.article-detail 评论页面的准备工作 (1)model层创建评论模型 class Comment(models.Model): """创建评论模 ...
- mt_vqmon异常数据分析
mt_vqmon异常数据分析 1.首缓冲时间值异常(1) 分析:当第一个m3u8请求时,已经记录request时间,1423716972224, 正常情况会立即请求分片列表. 上述图表明请求了一个m3 ...
- 为什么工具类App,都要做一个社区?
非著名程序员涩郎 非著名程序员,字耿左直右,号涩郎,爱搞机,爱编程,是爬行在移动互联网中的一名码匠!个人微信号:loonggg,微博:涩郎,专注于移动互联网的开发和研究,本号致力于分享IT技术和程序猿 ...
- 【Matrix Factorization】林轩田机器学习技法
在NNet这个系列中讲了Matrix Factorization感觉上怪怪的,但是听完第一小节课程就明白了. 林首先介绍了机器学习里面比较困难的一种问题:categorical features 这种 ...
- leetcode 【 Remove Nth Node From End of List 】 python 实现
题目: Given a linked list, remove the nth node from the end of list and return its head. For example, ...
- Python学习-KindEditor-富文本编辑框
1.进入官网 2.下载 官网下载:http://kindeditor.net/down.php 本地下载:http://files.cnblogs.com/files/wupeiqi/kindedit ...
- [Ceres]C++优化库
官网教程: http://ceres-solver.org/nnls_tutorial.html 定义了一个最小二乘法求解器 自动求导的功能
- 膜拜膜拜c++
被一个virtual搞得脑袋疼了好几天,明天继续虚函数+虚继承混合,伤不起,伤不起
- Android M中 JNI的入门学习
今年谷歌推出了Android 6.0,作为安卓开发人员,对其学习掌握肯定是必不可少的,今天小编和大家分享的就是Android 6.0中的 JNI相关知识,这是在一个安卓教程网上看到的内容,感觉很不错, ...
- Linux系统——28个命令行下的工具
Unix/Linux下的28个命令行下的工具 下面是Kristóf Kovács收集的28个Unix/Linux下的28个命令行下的工具(原文链接),有一些是大家熟悉的,有一些是非常有用的,有一些是不 ...