Hadoop实战:reduce端实现Join
项目描述
现在假设有两个数据集:气象站数据库和天气记录数据库,并考虑如何合二为一。一个典型的查询是:输出气象站的历史信息,同时各行记录也包含气象站的元数据信息。
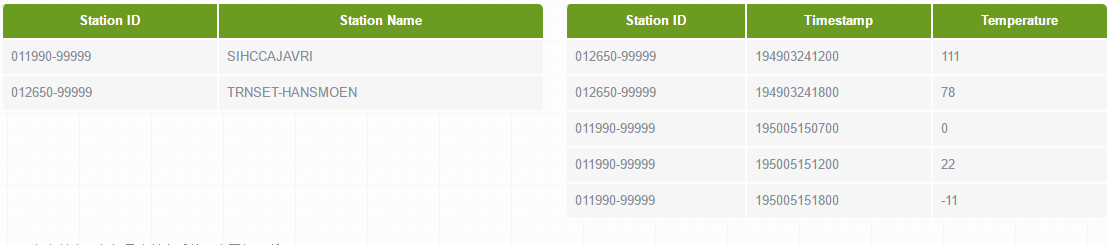
气象站和天气记录合并之后的示意图如下所示。

测试数据
启动Hadoop集群,然后在hdfs中创建join文件夹用于存放测试数据station.txt和records.txt,他们分别代表气象站数据库和天气记录数据库。
项目代码
JoinStationMapper.java
package com.hadoop.Join; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; /**
* @author Zimo
*
*/
public class JoinStationMapper extends Mapper<LongWritable,Text,TextPair,Text>
{
protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException
{
String line = value.toString();
String[] arr = line.split("\\s+");//解析气象站数据
int length = arr.length;
if(length==)
{//满足这种数据格式
//key=气象站id value=气象站名称
System.out.println("station="+arr[]+"");
context.write(new TextPair(arr[],""),new Text(arr[]));
}
}
}
JoinRecordMapper.java
package com.hadoop.Join; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; /**
* @author Zimo
*
*/
public class JoinRecordMapper extends Mapper<LongWritable,Text,TextPair,Text>
{
protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException
{
String line = value.toString();
String[] arr = line.split("\\s+",);//解析天气记录数据
int length = arr.length;
if(length==){
//key=气象站id value=天气记录数据
context.write(new TextPair(arr[],""),new Text(arr[]));
}
}
}
TextPair.java
package com.hadoop.Join; import java.io.*;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable; /**
* @author Zimo
*
*/
public class TextPair implements WritableComparable<TextPair>
{
private Text first; //Text 类型的实例变量first
private Text second;//Text 类型的实例变量second public TextPair() //无参构造方法
{
set(new Text(),new Text());
}
public TextPair(String first,String second) // Sting类型参数的构造方法
{
set(new Text(first),new Text(second));
}
public TextPair(Text first,Text second) // Text类型参数的构造方法
{
set(first,second);
}
public void set(Text first,Text second) //set方法
{
this.first=first;
this.second=second;
}
public Text getFirst() //getFirst方法
{
return first;
}
public Text getSecond() //getSecond方法
{
return second;
} //将对象转换为字节流并写入到输出流out中
@Override //------------ 序列化
public void write(DataOutput out) throws IOException //write方法
{
first.write(out);
second.write(out);
} //从输入流in中读取字节流反序列化为对象
@Override //------------反 序列化
public void readFields(DataInput in) throws IOException //readFields方法
{
first.readFields(in);
second.readFields(in);
} @Override
public int hashCode() //在mapreduce中,通过hashCode来选择reduce分区
{
return first.hashCode() *163+second.hashCode();
} @Override
public boolean equals(Object o) //equals方法,这里是两个对象的内容之间比较
{
if (o instanceof TextPair)
{
TextPair tp=(TextPair) o;
return first.equals(tp.first) && second.equals(tp.second);
}
return false;
} @Override
public String toString() //toString方法
{
return first +"\t"+ second;
}
@Override
public int compareTo(TextPair o)
{
// TODO Auto-generated method stub
if(!first.equals(o.first))
{
return first.compareTo(o.first);
}
else if(!second.equals(o.second))
{
return second.compareTo(o.second);
}
return 0;
} }
JoinReducer.java
package com.hadoop.Join; import java.io.IOException; import java.util.Iterator; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; /**
* @author Zimo
*
*/
public class JoinReducer extends Reducer< TextPair,Text,Text,Text>
{
protected void reduce(TextPair key, Iterable< Text> values,Context context) throws IOException,InterruptedException
{
Iterator< Text> iter = values.iterator();
Text stationName = new Text(iter.next());//气象站名称
while(iter.hasNext()){
Text record = iter.next();//天气记录的每条数据
Text outValue = new Text(stationName.toString()+"\t"+record.toString());
context.write(key.getFirst(),outValue);
}
}
}
JoinRecordWithStationName.java
package com.hadoop.Join; import java.io.InputStream;
import org.apache.hadoop.util.Tool;
import java.io.OutputStream;
import java.util.Set; import javax.lang.model.SourceVersion; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator; import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.ToolRunner; /**
* @author Zimo
*
*/
public class JoinRecordWithStationName extends Configured implements Tool
{
public static class KeyPartitioner extends Partitioner< TextPair,Text>
{ public int getPartition(TextPair key,Text value,int numPartitions)
{
return (key.getFirst().hashCode()&Integer.MAX_VALUE) % numPartitions;
}
} public static class GroupingComparator extends WritableComparator
{
protected GroupingComparator()
{
super(TextPair.class,true);
}
@Override
public int compare(WritableComparable w1,WritableComparable w2)
{
TextPair ip1=(TextPair) w1;
TextPair ip2=(TextPair) w2;
Text l=ip1.getFirst();
Text r=ip2.getFirst();
return l.compareTo(r); }
}
public int run(String[] args) throws Exception
{
Configuration conf = new Configuration();// 读取配置文件 Path mypath=new Path(args[]);
FileSystem hdfs=mypath.getFileSystem(conf);
if (hdfs.isDirectory(mypath))
{
hdfs.delete(mypath,true);
} Job job = Job.getInstance(conf,"join");// 新建一个任务
job.setJarByClass(JoinRecordWithStationName.class);// 主类 Path recordInputPath = new Path(args[]);//天气记录数据源,这里是牵扯到多路径输入和多路径输出的问题。默认是从args[0]开始
Path stationInputPath = new Path(args[]);//气象站数据源
Path outputPath = new Path(args[]);//输出路径 //若只有一个输入和一个输出,则输入是args[0],输出是args[1]。
//若有两个输入和一个输出,则输入是args[0]和args[1],输出是args[2] MultipleInputs.addInputPath(job,recordInputPath,TextInputFormat.class,JoinRecordMapper.class);//读取天气记录Mapper
MultipleInputs.addInputPath(job,stationInputPath,TextInputFormat.class,JoinStationMapper.class);//读取气象站Mapper
FileOutputFormat.setOutputPath(job,outputPath);
job.setReducerClass(JoinReducer.class);// Reducer
job.setNumReduceTasks(); job.setPartitionerClass(KeyPartitioner.class);//自定义分区
job.setGroupingComparatorClass(GroupingComparator.class);//自定义分组 job.setMapOutputKeyClass(TextPair.class);
job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); return job.waitForCompletion(true)?:;
} public static void main(String[] args) throws Exception
{
String[] args0={"hdfs://centpy:9000/join/records.txt"
,"hdfs://centpy:9000/join/station.txt"
,"hdfs://centpy:9000/join/out"
};
int exitCode=ToolRunner.run( new JoinRecordWithStationName(), args0);
System.exit(exitCode);
}
}
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。
Hadoop实战:reduce端实现Join的更多相关文章
- 第2节 mapreduce深入学习:15、reduce端的join算法的实现
reduce端的join算法: 例子: 商品表数据 product: pidp0001,小米5,1000,2000p0002,锤子T1,1000,3000 订单表数据 order: pid ...
- hadoop的压缩解压缩,reduce端join,map端join
hadoop的压缩解压缩 hadoop对于常见的几种压缩算法对于我们的mapreduce都是内置支持,不需要我们关心.经过map之后,数据会产生输出经过shuffle,这个时候的shuffle过程特别 ...
- Hadoop on Mac with IntelliJ IDEA - 10 陆喜恒. Hadoop实战(第2版)6.4.1(Shuffle和排序)Map端 内容整理
下午对着源码看陆喜恒. Hadoop实战(第2版)6.4.1 (Shuffle和排序)Map端,发现与Hadoop 1.2.1的源码有些出入.下面作个简单的记录,方便起见,引用自书本的语句都用斜体表 ...
- 升级版:深入浅出Hadoop实战开发(云存储、MapReduce、HBase实战微博、Hive应用、Storm应用)
Hadoop是一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力高速运算和存储.Hadoop实现了一个分布式文件系 ...
- Hadoop实战之三~ Hello World
本文介绍的是在Ubuntu下安装用三台PC安装完成Hadoop集群并运行好第一个Hello World的过程,软硬件信息如下: Ubuntu:12.04 LTS Master: 1.5G RAM,奔腾 ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- Hadoop实战实例
Hadoop实战实例 Hadoop实战实例 Hadoop 是Google MapReduce的一个Java实现.MapReduce是一种简化的分布式编程模式,让程序自动分布 ...
- Haoop MapReduce 的Partition和reduce端的二次排序
先贴一张原理图(摘自hadoop权威指南第三版) 实际中看了半天还是不太理解其中的Partition,和reduce端的二次排序,最终根据实验来结果来验证自己的理解 1eg 数据如下 20140101 ...
- Hadoop经典案例(排序&Join&topk&小文件合并)
①自定义按某列排序,二次排序 writablecomparable中的compareto方法 ②topk a利用treemap,缺点:map中的key不允许重复:https://blog.csdn.n ...
随机推荐
- 【转】 Pro Android学习笔记(四七):Dialog(4):一些补充和思考
目录(?)[-] 编程思想封装接口 fragment和activity以其他fragment之间的通信 编程思想:封装接口 在小例子中,fragment会调用activity的onDialogDone ...
- Java访问子类对象的实例变量
对于Java这种语言来说,一般来说,子类可以调用父类中的非private变量,但在一些特殊情况下, Java语言可以通过父类调用子类的变量 具体的还是请按下面的例子吧! package com.yon ...
- centos7安装etcd
http://blog.csdn.net/dream_broken/article/details/52671344
- Unity实现支持泛型的事件管理以减少使用object作为参数带来的频繁装拆箱
如果不用C#自身的event关键字而是要自己实现一个可统一管理游戏中各种消息事件通知管理的系统模块EventManger时,通常都是把事件delegate的参数定义为object类型以适应所有的数据类 ...
- docker里安装ubuntu
使用 Ubuntu 官方镜像 Ubuntu 相关的镜像有很多,这里使用 -s 10 参数,只搜索那些被收藏 10 次以上的镜像 $ docker search -s 10 ubuntu NAME DE ...
- easyui学习笔记1-(datagrid+dialog)
jQuery EasyUI是一组基于jQuery的UI插件集合体.我的理解:jquery是js的插件,easyui是基于jquery的插件.用easyui可以很轻松的打造出功能丰富并且美观的UI界面. ...
- 机器学习--PCA降维和Lasso算法
1.PCA降维 降维有什么作用呢?数据在低维下更容易处理.更容易使用:相关特征,特别是重要特征更能在数据中明确的显示出来:如果只有两维或者三维的话,更便于可视化展示:去除数据噪声降低算法开销 常见的降 ...
- HTML5与CSS3实例教程(第2版) 附源码 中文pdf扫描版
HTML5和CSS3技术是目前整个网页的基础.<HTML5与CSS3实例教程(第2版)>共分3部分,集中讨论了HTML5和CSS3规范及其技术的使用方法.这一版全面讲解了最新的HTML5和 ...
- HBase高可用原理与实践
前言 前段时间有套线上HBase出了点小问题,导致该套HBase集群服务停止了2个小时,从而造成使用该套HBase作为数据存储的应用也出现了服务异常.在排查问题之余,我们不禁也在思考,以后再出现类似的 ...
- 浅谈JavaScript -- 正则表达式
什么是正则表达式? 正则表达式是由一个字符序列形成的搜索模式.可用于文本搜索和文本替换. 语法:/正则表达式主体/修饰符(可选) var patt=new RegExp(pattern,modifie ...