笔记-scrapy与twisted
笔记-scrapy与twisted
Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码。
在任何情况下,都不要写阻塞的代码。阻塞的代码包括:
- 访问文件、数据库或者Web
- 产生新的进程并需要处理新进程的输出,如运行shell命令
- 执行系统层次操作的代码,如等待系统队列
Twisted提供了允许执行上面的操作但不会阻塞代码执行的方法。至于Twisted异步代码与多线程代码的比较可以参考一下下图:
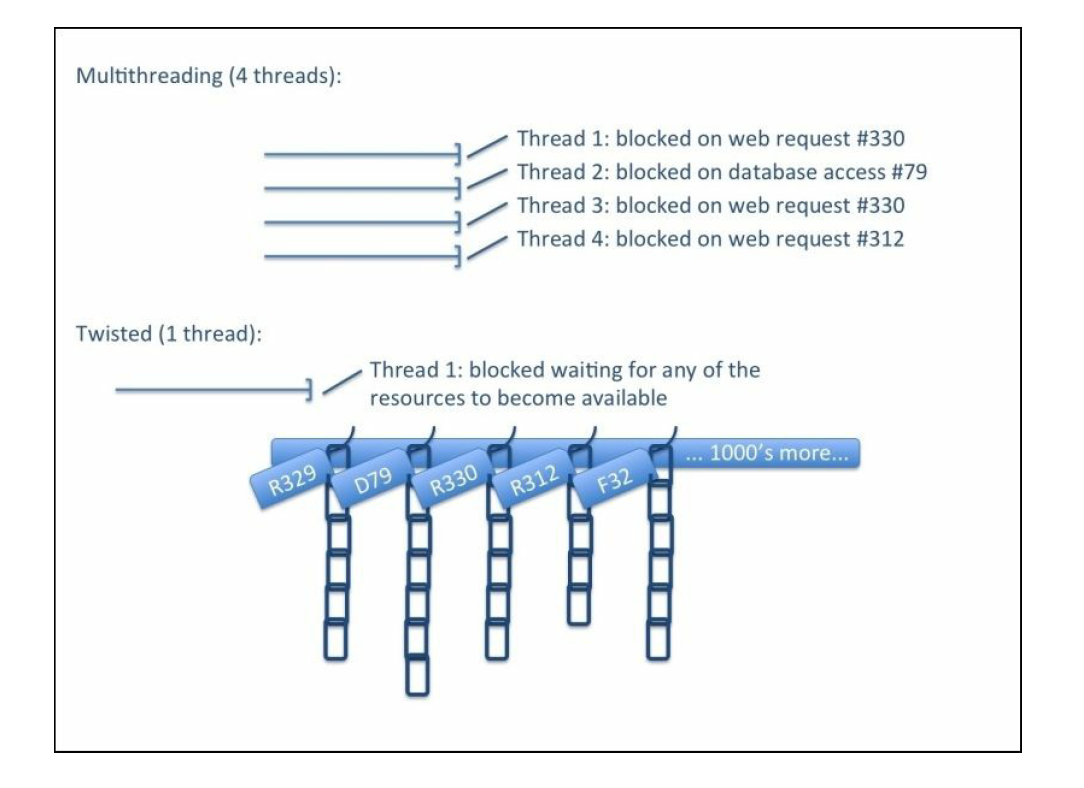
多线程的代码会有多个线程,在任何给定的时刻,不大可能所有的线程都在等待某个阻塞事件的发生。当等待的带伤发生时,线程开始工作,执行一些运算,然后可能再等待其他阻塞事件。这样服务器运行多个应用,就有很多线程,经过仔细地调整调度CPU就能很好地被利用。
而Twisted只采用一个线程,它使用了操作系统的I/O复用函数,如select()、poll()和epoll()作为”hanger”。当遇到阻塞的操作,如result = i_block()时,Twisted会提供另一种立即可以返回的实现方式。不过返回的不是具体的值而是一个钩子,如defered = i_dont_block(),这个钩子可以挂载一个函数,里面包含着当值处于可获取状态的时候我们想要执行的代码,例如deferred.addCallback(process_result)。Twisted程序就是用这些defered操作串起来的链,它的主线程叫做Twisted Event Reactor,这个线程负责监视哪些hanger上面的资源已经就位(比如服务器对爬虫的Request有响应了)。此时,它解除链最上面的defered的阻塞状态,这个defered可以会完成一些计算然后反过来又解除了另一个defered的阻塞状态。也有一些defered需要I/O操作,它就会把这个链放回hanger,并释放CPU以执行其他任务。因为只有一个线程,Twisted不会有上下文切换的负担,并且可以节省多个线程所额外需要的资源(比如内存)。换句话说,使用这种非阻塞的结构,虽然只有一个线程,所得到的性能却和数千个线程相似。
不过说句实话,操作系统的开发者们已经对线程操作优化进行了数十年,现在性能问题已经显得不如以前那么重要了。另一个问题是,多线程的编程要写出线程安全的代码非常困难。如果你已经了解了defereds/callbacks,你会发现Twisted的代码远远要比多线程的代码简单。inlineCallbacks生成器的使用甚至会使用代码更加容易。
笔记-scrapy与twisted的更多相关文章
- twisted学习笔记4 部署Twisted 应用程序
原创博文,转载请注明出处. Twisted是一个可扩展,跨平台的网络服务器和客户端引擎. Twisted Application 框架有五个主要基础部分组成:服务,应用程序,TAC文件插件和twist ...
- Scrapy笔记10- 动态配置爬虫
Scrapy笔记10- 动态配置爬虫 有很多时候我们需要从多个网站爬取所需要的数据,比如我们想爬取多个网站的新闻,将其存储到数据库同一个表中.我们是不是要对每个网站都得去定义一个Spider类呢? 其 ...
- twisted学习笔记 No.1
原创博文,转载请注明出处 . 1.安装twisted ,然后安装PyOpenSSL(一个Python开源OpenSSL库),这个软件包用于给Twisted提供加密传输支持(SSL).最后,安装PyCr ...
- Python Scrapy环境配置教程+使用Scrapy爬取李毅吧内容
Python爬虫框架Scrapy Scrapy框架 1.Scrapy框架安装 直接通过这里安装scrapy会提示报错: error: Microsoft Visual C++ 14.0 is requ ...
- python Scrapy安装和介绍
python Scrapy安装和介绍 Windows7下安装1.执行easy_install Scrapy Centos6.5下安装 1.库文件安装yum install libxslt-devel ...
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- 同时运行多个scrapy爬虫的几种方法(自定义scrapy项目命令)
试想一下,前面做的实验和例子都只有一个spider.然而,现实的开发的爬虫肯定不止一个.既然这样,那么就会有如下几个问题:1.在同一个项目中怎么创建多个爬虫的呢?2.多个爬虫的时候是怎么将他们运行起来 ...
- Scrapy开发
最近要开发一个软件需要爬取网站信息,于是选择了python 和scrapy下面做一下简单介绍:Scrapy安装连接,scrapy官网连接 所谓网络爬虫,就是一个在网上到处或定向抓取数据的程序,当然,这 ...
- Python爬虫框架Scrapy获得定向打击批量招聘信息
爬虫,就是一个在网上到处或定向抓取数据的程序,当然,这样的说法不够专业,更专业的描写叙述就是.抓取特定站点网页的HTML数据.只是因为一个站点的网页非常多,而我们又不可能事先知道全部网页的URL地址, ...
随机推荐
- 栅格那点儿事(四C)
栅格渲染之拉伸(Stretch) 现在我们知道如何在ArcGIS中渲染栅格数据了,但是还有一个常常会碰到的问题,尤其是在使用老版本的ArcGIS的时候,为啥我加了一个栅格数据进来,啥也看不见,是黑色的 ...
- Android GreenDAO 3.0 不修改版本号的情况下增加、删除表、添加字段
最近项目中使用了GreenDAO的3.0以上的版本,出现需要增加删除表的需求,刚开始用,发现官方对增加和删除的方法是每次去修改数据库版本号,版本一旦升级,那么原来数据库中的表会全部删除再重建.太麻烦, ...
- 《ArcGIS Runtime SDK for Android开发笔记》——(6)、基于Android Studio的ArcGIS Android工程结构解析
1.前言 Android Studio 是第一个Google官方的 Android 开发环境.其他工具,例如 Eclipse,在 Android Studio 发布之前已经有了大规模的使用.为了帮助开 ...
- php网站修改默认访问文件的nginx配置
搭建好lnmp后,有时候并不需要直接访问index.php,配置其他的默认访问文件比如index.html这时候需要配置一下nginx才能访问到你想要设置的文件 直接上代码,如下是我的配置的一份简单的 ...
- April 23 2017 Week 17 Sunday
It is a characteristic of wisdom not to do desperate things. 不做孤注一掷的事情是智慧的表现. We are told that we ha ...
- Selenium入门15 截图
截图方法: 1 保存截图 get_screenshot_as_file('保存路径\\文件名.png') #有一个\是转义符 2 保存截图 save_screenshot('保存路径\\文件名 ...
- cocosBuilder生成cbbi文件,绑定到cocos2d-x
cocosBuilder生成cbbi文件,绑定到cocos2d-x 分类: Cocos2D-X2013-04-27 20:37 4651人阅读 评论(6) 收藏 举报 今天弄了一天.记录一下. 首 ...
- PHP设计模式练习——制作简单的投诉页面
---恢复内容开始--- <?php /* * 设计模式练习 * 1.数据库连接类(单例模式) * 2.调用接口实现留言本功能(工厂模式) * 3.实现分级举报处理功能(责任链模式) * 4.发 ...
- miller——rabin
突然发现自己在线性筛素数中有这个,忘了好久: #include<iostream> #include<cstdio> using namespace std; long lon ...
- git移除某文件夹的版本控制
thinkphp框架,Apps/Runtime下目录移出版本控制. git rm -r -n --cached */Runtime/\* //-n:加上这个参数,执行命令时,是不会删除任何 ...