深浅copy 和 集合
1 对于赋值运算,就是共同指向一个内存地址.将一个值赋予一个变量,那么它的内存地址同时也赋予了他,如果值是不可变类型,改变值,就会产生一个新值和新内存地址,
如果值是可变类型那么内存地址不会变.
s1 = 'alex'
s2 = s1
print(s1,id(s1))
print(s2,id(s2))
结果:

当值是可变类型时
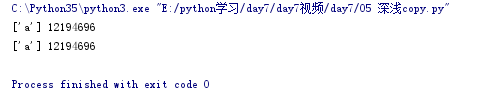
s1 = []
s2 = s1
s2.append("a")
print(s1,id(s1))
print(s2,id(s2))
结果:
2 浅层copy 拷贝第一层的数据独立,第二层及以后公用一个内存地址
#copy
l1 = [1,2,3]
l2 = l1.copy()
l1.append(666) #在第一层里添加数据
print(l1,id(l1))
print(l2,id(l2))
l1 = [1,[22,33],2,3]
l2 = l1.copy()
l1[1].append(666) #在第二层添加数据
print(l1,id(l1))
print(l2,id(l2))
结果:

3 深层copy 要引用模块 import copy 对于深copy,无论多少层,在内存中都是两个独立的内存地址
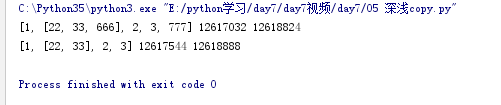
import copy
l1 = [1,[22,33,],2,3]
l2 = copy.deepcopy(l1)
l1.append(777)
l1[1].append(666)
print(l1,id(l1),id(l1[1]))
print(l2,id(l2),id(l2[1]))
结果:
4 面试题
l1 = [1,[1,2],2,3]
l2 = l1[:] # 是浅copy
l1[1].append(111)
print(l1,l2)
#l2 是什么?
结果:

5 在列表循环过程中,如果删除数据,可能会报错,举例:
将下列数据中奇数位删掉
#方法一:
l1 = [111,222,333,444,555] # 删掉奇数就是保留偶数,将偶数数据找到,建个新列表代替原来列表
l2 = []
for i in range(len(l1)):
if i % 2 == 0:
l2.append(l1[i])
l1 = l2
print(l1) #方法二:
l1 = [111,222,333,444,555,666,777] # 通过切片的步长删掉奇数数据
del l1[1::2]
print(l1)
#方法三
l1 = [111,222,333,444,555] # 将索引倒序找奇数位 这样删掉数据就不会影响前面元素的索引
for i in range(len(l1)-1,-1,-1):
if i % 2 == 1:
del l1[i]
print(l1)
结果:

6 字典在循环过程中,如果删掉数据也会报错
dic = {'k1':'alex','k2':'太白','k3':'日天','name':'wusir'}
#不可变的数据类型:可哈希
# for i in dic:
# if 'k' in i:
# del dic[i]
print(dic)
结果: 在迭代过程中字典大小改变

对应方法dic = {'k1':'alex','k2':'太白','k3':'日天','name':'wusir'}
l1 = []
for i in dic:
if 'k' in i:
l1.append(i) for k in l1:
del dic[k]
print(dic)
结果; 在字典循环中不能改变字典,但是新建个列表,把要删除的数据放到列表里,在循环列表,再循环列表过程中修改字典就不会报错.

7 数据类型转换 元祖变列表list(tuple) 列表变元祖 tuple(list)
#tuple <---> list
l1 = [1,2,3]
tu = tuple(l1) #将列表换成元祖
l2 = list(tu) #将元祖变成列表
print(tu,l2)
结果:
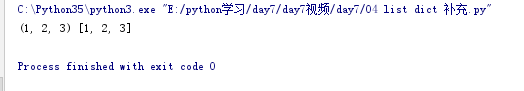
字典专属类型转换 可以变列表,元祖 但是元祖是不可变类型 一般转换成列表
dic = {'k1':'alex','k2':'太白','k3':'日天','name':'wusir'}
print(list(dic.keys()))
print(list(dic.values()))
print(list(dic.items()))
结果:

8 集合
集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的。
以下是集合最重要的两点:
去重,把一个列表变成集合,就自动去重了。
关系测试,测试两组数据之前的交集、差集、并集等关系。
9 集合的增。
set1 = {'alex','wusir','ritian','egon','barry'}
set1.add('景女神')
print(set1)
#update:迭代着增加
set1.update('景女神')
print(set1)
结果:

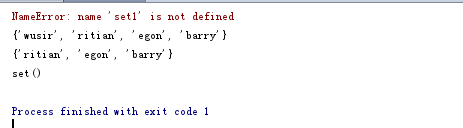
10 集合的删。
set1 = {'alex','wusir','ritian','egon','barry'}
set1.remove('alex') # 删除一个元素
print(set1)
set1.pop() # 随机删除一个元素
print(set1)
set1.clear() # 清空集合
print(set1)
del set1 # 删除集合
print(set1)
结果:
11 集合的交 并,反交 差集,超集和子集
交集 (& 或者 intersection)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 & set2) # {4, 5}
print(set1.intersection(set2)) # {4, 5}
结果:

并集。(| 或者 union)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7}
print(set2.union(set1)) # {1, 2, 3, 4, 5, 6, 7}
结果:
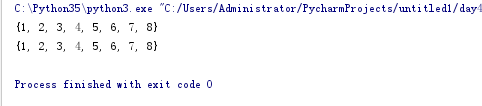
差集。(- 或者 difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 - set2) # {1, 2, 3}
print(set1.difference(set2)) # {1, 2, 3}
结果:
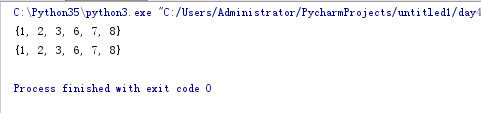
反交集。 (^ 或者 symmetric_difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 ^ set2) # {1, 2, 3, 6, 7, 8}
print(set1.symmetric_difference(set2)) # {1, 2, 3, 6, 7, 8}
结果:
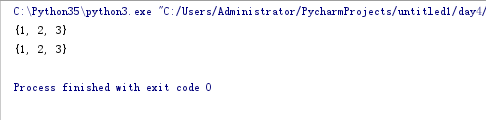
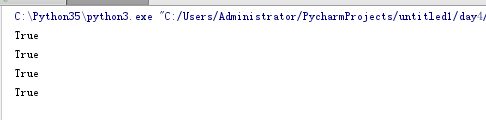
子集与超集
set1 = {1,2,3}
set2 = {1,2,3,4,5,6}
print(set1 < set2)
print(set1.issubset(set2)) # 这两个相同,都是说明set1是set2子集。
print(set2 > set1)
print(set2.issuperset(set1)) # 这两个相同,都是说明set2是set1超集。
结果:
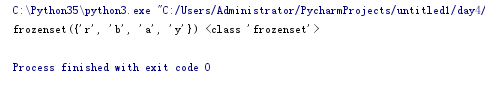
frozenset不可变集合,让集合变成不可变类型。把一个可迭代的元素添加到集合 如果有重复元素,自动删掉.
s = frozenset('barry')
print(s,type(s)) # frozenset({'a', 'y', 'b', 'r'}) <class 'frozenset'>
结果:
深浅copy 和 集合的更多相关文章
- python基础3(元祖、字典、深浅copy、集合、文件处理)
本次内容: 元祖 字典 浅copy和深copy 集合 文件处理 1.1元祖 元祖(tuple)与列表类似,不同之处在于元祖的元素不能修改,元祖使用小括号(),列表使用方括号[].元祖创建很简单,只需要 ...
- 【python】-- 深浅copy、集合
深浅copy 1.数字.字符串的copy: 赋值(=).浅拷贝(copy)和深拷贝(deepcopy)其实都一样,因为它们永远指向同一个内存地址: >>> import copy & ...
- Python 第三篇(下):collections系列、集合(set)、单双队列、深浅copy、内置函数
一.collections系列: collections其实是python的标准库,也就是python的一个内置模块,因此使用之前导入一下collections模块即可,collections在py ...
- Python 集合 深浅copy
一,集合. 集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的.以下是集合最重要的两点: 去重,把一个列表变成集合,就自动去重了. ...
- python集合深浅copy
一,集合. 集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的.以下是集合最重要的两点: 去重,把一个列表变成集合,就自动去重了. ...
- Python基础数据类型之集合以及其他和深浅copy
一.基础数据类型汇总补充 list 在循环一个列表时,最好不要删除列表中的元素,这样会使索引发生改变,从而报错(可以从后向前循环删除,这样不会改变未删元素的索引). 错误示范: lis = [,,, ...
- python之集合,深浅copy
一. 集合 集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的.以下是集合最重要的两点: 去重,把一个列表变成集合,就自动去重了. ...
- python之数据类型补充、集合、深浅copy
一.内容回顾 代码块: 一个函数,一个模块,一个类,一个文件,交互模式下,每一行就是一个代码块. is == id id()查询对象的内存地址 == 比较的是两边的数值. is 比较的是两边的内存地址 ...
- day 07 数据类型,集合,深浅copy
1.day 06 内容回顾 小数据池 int :-5-256 str:特殊字符 ,*20 ascii:8位 1字节 表示一个字符 unicode:32位 4个字节 , 表示一个字符 字节表示8位表示一 ...
随机推荐
- CALayer的基本使用
CALayer需要导入这个框架:#import <QuartzCore/QuartzCore.h> 一.CALayer常用属性 属性 说明 是否支持隐式动画 anchorPoint 和中心 ...
- Windows平台上通过git下载github的开源代码
常见指令整理: (1)检查ssh密钥是否已经存在.GitBash. 查看是否已经有了ssh密钥:cd ~/.ssh.示例中说明已经存在密钥 (2)生成公钥和私钥 $ ssh-keygen -t rsa ...
- 面试题:hibernate 第二天 快照 session oid 有用
## Hibernate第二天 ## ### 回顾与反馈 ### Hibernate第一天 1)一种思想 : ORM OM(数据库表与实体类之间的映射) RM 2)一个项目 : CRM 客户关系管理系 ...
- Camera 3D概念
1. integration time即积分时间是以行为单位表示曝光时间(exposure time)的,比如说INT TIM为159,就是指sensor曝光时间为159行,两者所代表的意思是相同的, ...
- R: 控制流: if & for & while
################################################### 问题:if 判断 18.4.29 if 的应用与??...... 解决方案: # if(){ ...
- p3203 弹飞绵羊
传送门 分析 基本的lct操作,建一个点N表示弹飞出去的点,每次输出N的左子树的大小即可 代码 #include<iostream> #include<cstdio> #inc ...
- kindeditor坑
用document.getElementById("form1").submit提交,存在缓存问题,经常接收不到textarea数据
- MySQL安装与管理
数据库服务器.数据库和表的关系 –所谓安装数据库服务器,只是在机器上装了一个数据库管理程序,这个管理程序可以管理多个数据库,一般开发人员会针对每一个应用创建一个数据库. –为保存应用中实体的数据,一般 ...
- [译]如何在visual studio中调试Javascript
本文翻译youtube上的up主kudvenkat的javascript tutorial播放单 源地址在此: https://www.youtube.com/watch?v=PMsVM7rjupU& ...
- iOS symbolicatecrash工具crash日志分析
若一个App没有加入Crashlytics或者Buggly这些崩溃日志监控,那么我们在App崩溃的时候如何获取崩溃信息呢? 此时我们可以通过symbolicatecrash工具对手机日志来进行分析定位 ...