【python】用python爬取中科院院士简介信息
018/07/09 23:43
项目名称:爬取中科院871个院士的简介信息
1.爬取目的:中科院871个院士的简介信息


2.爬取最终结果:
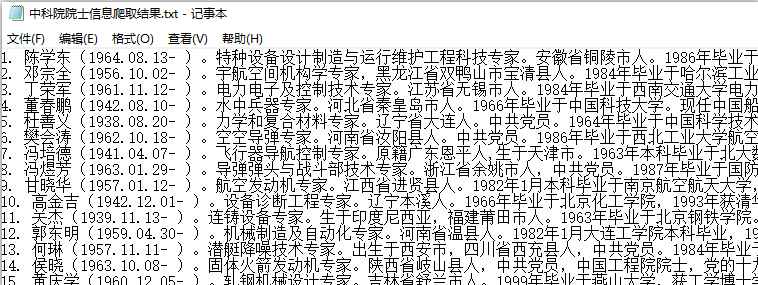

3.具体代码如下:
import re # 不用安装(注意!!)
import os # 文件夹等的操作(注意!!)
import time
import requests # http urllib2 url = 'http://www.cae.cn/cae/html/main/col48/column_48_1.html'
html = requests.get(url)
# print(html.status_code) # 状态码200 404 500 502
html.encoding = 'utf-8'
# print(html.text) # 以文本形式返回网页 # 提取数据
# + 一次或多次 大于等于一次
# findall返回的是列表(注意!!)
number = re.findall(
'<a href="/cae/html/main/colys/(\d+).html" target="_blank">', html.text) i = 1 # 这里的i变量是由我创造进行明确区分所抓取的院士的数量的;
for m in number[:871]:
# for m in number[:4]: # 这里控制要爬取的个数
# for m in number[28:88]:
nextUrl = 'http://www.cae.cn/cae/html/main/colys/{}.html'.format(m)
# 再次请求数据
nexthtml = requests.get(nextUrl)
nexthtml.encoding = 'utf-8'
# 注意正则表达式:
# () 提取数据
# . 匹配除了换行\n的任意单个字符
# * 匹配前面的表达式任意次 {1,5}
# ? 如果前面有限定符 非贪婪模式,注意!!!
# 尽量可能少的匹配所搜索的字符串
text = re.findall('<div class="intro">(.*?)</div>', nexthtml.text, re.S) # re.S匹配换行的
text2 = re.sub(r'<p>| | |</p>', '', text[0]).strip() # .strip()清楚空格 # 保存数据
with open(r'E:\02中科院院士信息爬取结果.txt', mode='a+', encoding="utf-8") as f: # 特别注意这里的要以编码utf-8方式打开
f.write('{}. '.format(i) + text2 + '\n')
i += 1 # 不要下载太快
# 限制下载的速度
time.sleep(1)
# 程序运行到这个地方 暂停1s
【python】用python爬取中科院院士简介信息的更多相关文章
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- Python爬虫项目--爬取自如网房源信息
本次爬取自如网房源信息所用到的知识点: 1. requests get请求 2. lxml解析html 3. Xpath 4. MongoDB存储 正文 1.分析目标站点 1. url: http:/ ...
- 【Python项目】爬取新浪微博个人用户信息页
微博用户信息爬虫 项目链接:https://github.com/RealIvyWong/WeiboCrawler/tree/master/WeiboUserInfoCrawler 1 实现功能 这个 ...
- python之scrapy爬取某集团招聘信息以及招聘详情
1.定义爬取的字段items.py # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See do ...
- Python爬虫项目--爬取某宝男装信息
本次爬取用到的知识点有: 1. selenium 2. pymysql 3 pyquery 正文 1. 分析目标网站 1. 打开某宝首页, 输入"男装"后点击"搜索&q ...
- python之crawlscrapy爬取某集团招聘信息以及招聘详情
针对这种招聘信息,使用crawlscrapy很适合. 1.settings.py # -*- coding: utf-8 -*- # Scrapy settings for gosuncn proje ...
- python之scrapy爬取某集团招聘信息
1.创建工程 scrapy startproject gosuncn 2.创建项目 cd gosuncn scrapy genspider gaoxinxing gosuncn.zhiye.com 3 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- python爬取 “得到” App 电子书信息
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 静觅 崔庆才 PS:如有需要Python学习资料的小伙伴可以加点击下 ...
随机推荐
- ADO.NET之一:连接层
ADO.NET大部分由System.Data.dll核心程序集来表示. ADO.NET类库有三种完全不听的方式来实现数据访问:连接式.断开式和通过Entity框架.连接式就是会一直占用网络资源,断开式 ...
- multi-view datasets
http://rll.berkeley.edu/2014_ICRA_dataset/ http://rgbd-dataset.cs.washington.edu/dataset/
- 6、SpringBoot+Mybatis整合------参数传递
开发工具:STS 代码下载链接:https://github.com/theIndoorTrain/SpringBoot_Mybatis/tree/7892801d804d2060774f3720f8 ...
- Spring Boot Shiro权限管理--自定义 FormAuthenticationFilter验证码整合
思路shiro使用FormAuthenticationFilter进行表单认证,验证校验的功能应该加在FormAuthenticationFilter中,在认证之前进行验证码校验. 需要写FormAu ...
- HTML5--混合布局
1.先上效果图,大家来看看 2.代码如下: <!doctype html> <meta charset='utf-8' content='text/html' /> <h ...
- C++指针之间的赋值与转换规则总结
C++指针之间的赋值与转换规则总结 Note:以下结论不适用于类的成员函数指针,关于类的成员函数指针会单独讨论. 一.任何类型的指针变量均可直接赋值给const void * 任何类型的非const指 ...
- python__高级 : GC垃圾回收相关
python的垃圾回收机制是以引用计数为主,加上标记-清除,分代收集等辅助方式组成的,如果想打开gc功能,需要 import gc 模块 ,然后 gc.enable() 就打开了这个功能,关闭是 gc ...
- JavaSE 第二次学习随笔(作业一)
package homework2; import java.io.ObjectInputStream.GetField; import java.util.Arrays; public class ...
- NOIP PJ游记
Day -1 感觉自信满满,一等奖应该稳了,毕竟初一时我这么菜都拿了二等奖,然后就睡觉了... Day 1 在大巴上玩元气骑士可开心了,车上欢欢喜喜,到了考场,一眼看题,以为很简单. T1硬模拟... ...
- 前端各种mate积累
<!DOCTYPE html> H5标准声明,使用 HTML5 doctype,不区分大小写 <head lang=”en”> 标准的 lang 属性写法 <meta c ...