mysql日常笔记(持续更新)
常用场景
- sql_mode问题:http://blog.csdn.net/ccccalculator/article/details/70432123
- 连续日期补全/数据补零操作
在不使用存储过程和函数来建表或单独建表的情况下用union匹配查询出数据
eg:查询当前日期前七天的记录,如果当中有不存在数据的时间则补0
SELECT
count(*) count,
DATE_FORMAT(CREATE_TIME,'%Y-%m-%d') date
FROM t_hip_user
WHERE
DATE_SUB(CURDATE(), INTERVAL 7 DAY) <= CREATE_TIME
GROUP BY DATE_FORMAT(CREATE_TIME,'%Y-%m-%d')
UNION (SELECT 0, CURDATE())
UNION (SELECT 0, DATE_SUB(CURDATE(), INTERVAL 1 DAY))
UNION (SELECT 0, DATE_SUB(CURDATE(), INTERVAL 2 DAY))
UNION (SELECT 0, DATE_SUB(CURDATE(), INTERVAL 3 DAY))
UNION (SELECT 0, DATE_SUB(CURDATE(), INTERVAL 4 DAY))
UNION (SELECT 0, DATE_SUB(CURDATE(), INTERVAL 5 DAY))
UNION (SELECT 0, DATE_SUB(CURDATE(), INTERVAL 6 DAY)) 参考:http://blog.csdn.net/AJian759447583/article/details/61421399附sql时间比较:https://www.cnblogs.com/wangcq/p/3781615.html
外键
设置外键
create table student
(
id int primary key,
name char(),
dept char()
sex char()
)
create table grade
(
id int ,
grade int
constraint id_fk foreign key (id) references student (id)
)
或创建了两表之后再建
alter table grade
add constraint id_fk foreign key (id) references student (id)
set FOREIGN_KEY_CHECKS =0 取消外键约束
set FOREIGN_KEY_CHECKS = 1 设置外键约束
函数:
- coalesce( expression [ ,...n ] )
遇到非null值即停止并返回该值。如果所有的表达式都是空值,最终将返回一个空值。使用COALESCE在于大部分包含空值的表达式最终将返回空值。
相似: isnull
select t0.id c0, t0.name c1, t0.icon c2, t0.order c3 from mj_category t0
where t0.id in (?, ?, ?, ?, ?, ?, ? )
and coalesce(t0.deleted,)=0
- case...when...then...else...end
case when 条件1 then 取值1 when 条件2 then 取值2 else 取值3 end
when后接条件语句,then后为字段取值(数值或字符串等都可以,但类型须一致)。
SELECT ageGroup,count(*) as number FROM
(SELECT
case
when age>=0 and age<=12 then '0-12'
when age>=13 and age<=18 then '13-18'
when age>=19 and age<=25 then '19-25'
when age>=26 and age<=30 then '26-30'
when age>=30 and age<=40 then '30-40'
when age>=41 and age<=50 then '41-50'
when age>=51 then '51-'
else 'notSet'
end
AS ageGroup
from t_hip_user ) a
group by a.ageGroup;
索引:
mysql性能分析方法
1.使用 explain或者DESCRIBE 语句去查看分析结果
语法:EXPLAIN tbl_name或:EXPLAIN [EXTENDED] SELECT select_options
explain SELECT * FROM `test`
返回:
| id | select_type | table | partitions | type | possible_key | key | key_len | ref | rows | filtered | Extra |
| 1 | SIMPLE | test | ALL | 350 | 100 |
id:select查询的序列号
select_type:select查询的类型,主要是区别普通查询和联合查询、子查询之类的复杂查询。
table:输出的行所引用的表。
type:联合查询所使用的类型。
type显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。
possible_keys:指出MySQL能使用哪个索引在表中找到行。如果是空的,没有相关的索引。这时要提高性能,可通过检验WHERE子句,看是否引用某些字段,或者检查字段不是适合索引。
key:显示MySQL实际决定使用的键。如果没有索引被选择,键是NULL。
key_len:显示MySQL决定使用的键长度。如果键是NULL,长度就是NULL。文档提示特别注意这个值可以得出一个多重主键里mysql实际使用了哪一部分。
ref:显示哪个字段或常数与key一起被使用。
rows:这个数表示mysql要遍历多少数据才能找到,在innodb上是不准确的。
Extra:如果是Only index,这意味着信息只用索引树中的信息检索出的,这比扫描整个表要快。
如果是where used,就是使用上了where限制。
如果是impossible where 表示用不着where,一般就是没查出来啥。
如果此信息显示Using filesort或者Using temporary的话会很吃力,WHERE和ORDER BY的索引经常无法兼顾,如果按照WHERE来确定索引,那么在ORDER BY时,就必然会 引起Using filesort,这就要看是先过滤再排序划算,还是先排序再过滤划算。
2.MYSQL中的组合索引
3.使用慢查询分析
4.MYISAM和INNODB的锁定
5.MYSQL的事务配置项
特别案例:排名
sql语句查询排名 思路:有点类似循环里面的自增一样,设置一个变量并赋予初始值,循环一次自增加1,从而实现排序; mysql里则是需要先将数据查询出来并先行按照需要排序的字段做好降序desc,或则升序asc,设置好排序的变量(初始值为0): a>.将已经排序好的数据从第一条依次取出来,取一条就自增加一,实现从1到最后的一个排名 b>.当出现相同的数据时,排名保持不变,此时则需要再设置一个变量,用来记录上一条数据的值,跟当前数据的值进行对比,如果相同,则排名不变,不相同则排名自增加1 c.当出现相同的数据时,排名保持不变,但是保持不变的排名依旧会占用一个位置,也就是类似于(1,2,2,2,5)这种排名就是属于中间的三个排名是一样的,但是第五个排名按照上面一种情况是(1,2,2,2,3),现在则是排名相同也会占据排名的位置 准备数据(用户id,分数): CREATE TABLE `sql_rank` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(11) unsigned NOT NULL,
`score` tinyint(3) unsigned NOT NULL,
`add_time` date NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1; 插入数据: INSERT INTO sql_rank (user_id, score, add_time)
VALUES
(100, 50, '2016-05-01'),
(101, 30, '2016-05-01'),
(102, 20, '2016-05-01'),
(103, 60, '2016-05-01'),
(104, 80, '2016-05-01'),
(105, 50, '2016-05-01'),
(106, 70, '2016-05-01'),
(107, 85, '2016-05-01'),
(108, 60, '2016-05-01') 当前数据库数据: 一、sql1{不管数据相同与否,排名依次排序(1,2,3,4,5,6,7.....)} 复制代码
SELECT
obj.user_id,obj.score,@rownum := @rownum + 1 AS rownum
FROM
(
SELECT
user_id,
score
FROM
`sql_rank`
ORDER BY
score DESC
) AS obj,
(SELECT @rownum := 0) r
复制代码
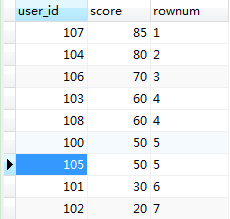
执行的结果如下图:

可以看到,现在按照分数从1到9都排好序了,但是有些分数相同的用户排名却不一样,这就是接下来要说的第二种sql 二、sql2{只要数据有相同的排名就一样,排名依次排序(1,2,2,3,3,4,5.....)} 复制代码
SELECT
obj.user_id,
obj.score,
CASE
WHEN @rowtotal = obj.score THEN
@rownum
WHEN @rowtotal := obj.score THEN
@rownum :=@rownum + 1
WHEN @rowtotal = 0 THEN
@rownum :=@rownum + 1
END AS rownum
FROM
(
SELECT
user_id,
score
FROM
`sql_rank`
ORDER BY
score DESC
) AS obj,
(SELECT @rownum := 0 ,@rowtotal := NULL) r
复制代码
这时候就新增加了一个变量,用于记录上一条数据的分数了,只要当前数据分数跟上一条数据的分数比较,相同分数的排名就不变,不相同分数的排名就加一,并且更新变量的分数值为该条数据的分数,依次比较 如下图结果:
跟第一条sql的结果相对比你会发现,分数相同的排名也相同,并且最后一名的名次由第9名变成了第7名; 如果你需要分数相同的排名也相同,但是后面的排名不能受到分数相同排名相同而不占位的影响,也就是哪怕你排名相同,你也占了这个位置(比如:1,2,2,4,5,5,7....这种形式的,虽然排名有相同,但是你占位了,后续的排名根据占位来排) 三、sql2{只要数据有相同的排名就一样,但是相同排名也占位,排名依次排序(1,2,2,4,5,5,7.....)} 此时需呀再增加一个变量,来记录排序的号码(自增) 复制代码
SELECT
obj_new.user_id,
obj_new.score,
obj_new.rownum
FROM
(
SELECT
obj.user_id,
obj.score,
@rownum := @rownum + 1 AS num_tmp,
@incrnum := CASE
WHEN @rowtotal = obj.score THEN
@incrnum
WHEN @rowtotal := obj.score THEN
@rownum
END AS rownum
FROM
(
SELECT
user_id,
score
FROM
`sql_rank`
ORDER BY
score DESC
) AS obj,
(
SELECT
@rownum := 0 ,@rowtotal := NULL ,@incrnum := 0
) r
) AS obj_new
复制代码
上面sql执行的结果如下:
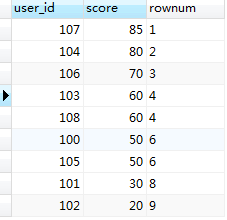
结果集中分数相同的,排名相同,同时它也占据了那个位置,中间的一个数据过程本人截图了,请往下看(跟上图做对比你就明白了):
..............
SELECT
temp.article_id,
temp.view_count,
temp.rank
FROM
(
SELECT
ta.*,
@index := @index + 1,
@rank := (CASE
WHEN @temp_view_count = ta.view_count THEN
@rank
WHEN @temp_view_count := ta.view_count THEN
@index
WHEN @temp_view_count = 0 OR @temp_view_count IS NULL THEN
@index
END) AS rank
FROM
(
SELECT article_id, view_count
FROM dev_article_view
ORDER BY view_count DESC
) AS ta,
( SELECT @rank := 0 ,@rowtotal := NULL ,@index := 0 ) r
) AS temp
查询进程,事务:
select * from information_schema.innodb_trx 事务锁的语句 select @@tx_isolation; 事务类型 show processlist; //进程
数据类型:
存储结构:
底层原理:\
优化:
SHOW PROCESSLIST 显示哪些线程正在运行
https://blog.csdn.net/sunqingzhong44/article/details/70570728
mysql日常笔记(持续更新)的更多相关文章
- Mysql操作笔记(持续更新)
1.mysqldump备份导出 备份成sql mysqldump -hlocalIp -uuserName -p --opt --default-character-set=utf8 --hex-bl ...
- BLE资料应用笔记 -- 持续更新
BLE资料应用笔记 -- 持续更新 BLE 应用笔记 小书匠 简而言之,蓝牙无处不在,易于使用,低耗能和低使用成本.'让我们'更深入地探索这些方面吧. 蓝牙无处不在-,您可以在几乎每一台电话.笔记本电 ...
- [读书]10g/11g编程艺术深入体现结构学习笔记(持续更新...)
持续更新...) 第8章 1.在过程性循环中提交更新容易产生ora-01555:snapshot too old错误.P257 (这种情况我觉得应该是在高并发的情况下才会产生) 假设的一个场景是系统一 ...
- react-native-storage 使用笔记 持续更新
React-native-storage是在AsyncStorage之上封装的一个缓存操作插件库,刚开始接触这个也遇到了一些问题,在这里简单记录总结一下,碰到了就记下来,持续更新吧 1.安卓下stor ...
- web前端开发随手笔记 - 持续更新
本文仅为个人常用代码整理,供自己日常查阅 html 浏览器内核 <!--[if IE]><![endif]--> <!--[if IE 6]><![endif ...
- MySQL问题总结(持续更新)
CHAR和VARCHAR的区别 存储方式和检索方式不同: 1.CHAR固定长度字符类型.CHAR存储定长数据,CHAR字段上的索引效率高,比如定义char(10),那么不论你存储的数据是否达到了10个 ...
- 数据分析之Pandas和Numpy学习笔记(持续更新)<1>
pandas and numpy notebook 最近工作交接,整理电脑资料时看到了之前的基于Jupyter学习数据分析相关模块学习笔记.想着拿出来分享一下,可是Jupyter导出来h ...
- mysql问题汇总——持续更新
1.this is incompatible with sql_mode=only_full_group_by set @@sql_mode='STRICT_TRANS_TABLES,NO_ZERO_ ...
- BLE资料应用笔记 -- 持续更新(转载)
简而言之,蓝牙无处不在,易于使用,低耗能和低使用成本.’让我们’更深入地探索这些方面吧. 蓝牙无处不在—,您可以在几乎每一台电话.笔记本电脑 .台式电脑和平板电脑中找到蓝牙.因此,您可以便利地连接键盘 ...
随机推荐
- In-Memory:内存优化表的DMV
SQL Server 在执行查询时,自动将活动的相关信息保存在内存中,这些活动信息称作DMV(Dynamic Management View),DMV记录SQL Server实例级别上的活动信息.由于 ...
- 如何有效的报告bug?
对于比较棘手的bug,反馈务须清晰.详细.精确,我们给出以下6个建议: 1.现场演示:重复bug出现的操作步骤.这个适用于公司内部人员. 2.详细描述:在什么系统使用哪个版本的YoMail,做了什 ...
- cbuild-一个创建和管理C++项目的工具
cbuild-一个创建和管理C++项目的工具 介绍: 这是个人开发的一个管理C++项目的工具,用shell脚本编写. 可能会不定期更新,也欢迎大家一起完善. 当前开发版本0.5.各版本功能如下: ve ...
- 开源一个最近写的spring与mongodb结合的demo(spring-mongodb-demo)
由于工作需要,给同事们分享了一下mongodb的使用,其中主要就是做了一个spring-data+mongodb的小例子,本着分享的精神,就上传到了github.com上,有需要的同学请移步githu ...
- 2-Eighteenth Scrum Meeting-20151218
任务安排 成员 今日完成 明日任务 闫昊 写完学习进度记录的数据库操作 写完学习进度记录的数据库操作 唐彬 编写与服务器交互的代码 和服务器老师交流讨论区后台接口 史烨轩 获取视频url 尝试使用 ...
- Android 7.0+相机、相册、裁剪适配问题
Android 7.0+相机.相册.裁剪适配问题 在manifest中: <provider android:name="android.support.v4.content.File ...
- 团队项目:安卓端用百度地图api定位显示跑道
因为安卓调用api对我来说是一个完全陌生的领域,我在经过很长时间终于弄出来了,这段时间还是很有成效的,我得到了历练. 第一步:注册成为百度开发者 在百度地图开放平台创建应用.地址http://lbsy ...
- 4种PHP回调函数风格
4种PHP回调函数风格 匿名函数 $server->on('Request', function ($req, $resp) use ($a, $b, $c) { echo "hell ...
- Redis的相关问题总结
一.Redis的优缺点及适用场景 Redis 是一个基于内存的高性能key-value数据库.很像memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘 ...
- wordpress 点击文章图片 不能编辑(chrome下面) wordpress Uncaught DOMException: Failed to execute 'setBaseAndExtent' on 'Selection': There is no child at offset 1.
说明:在chrome下面,编辑文章插入的图片,点击到图片上面,没有菜单显示. 报错: tinymce.min.js:10 Uncaught DOMException: Failed to execut ...