mapreduce深入剖析5大视频










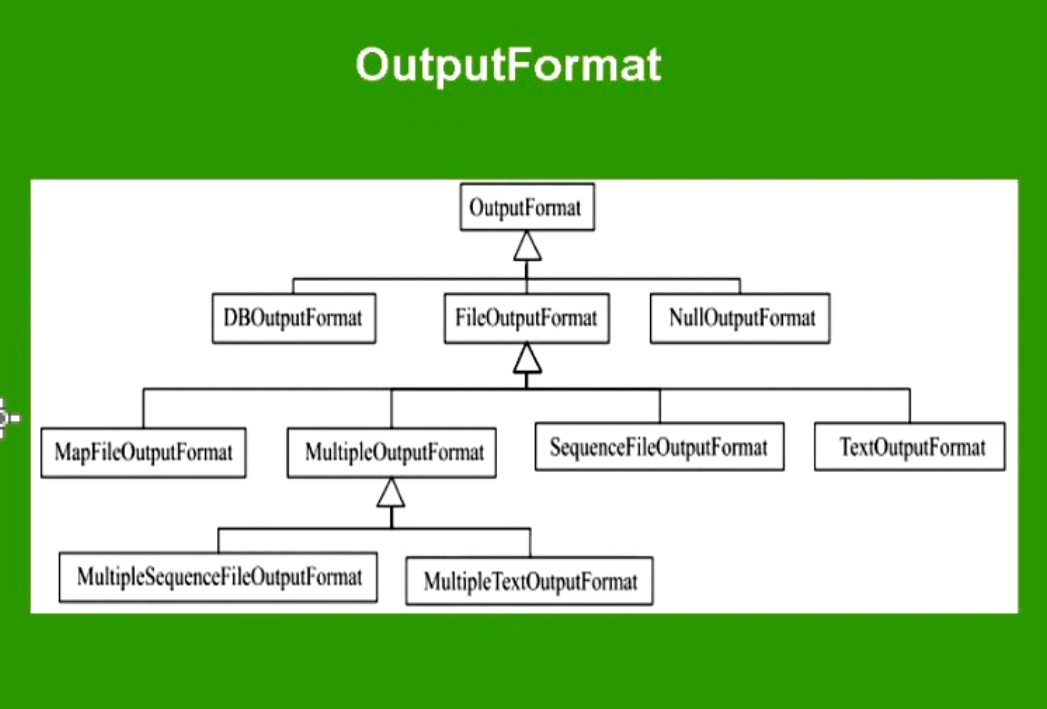
参考代码
TVPlayCount.java
package com.dajiangtai.hadoop.tvplay; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; import com.sun.org.apache.bcel.internal.generic.NEW; public class TVPlayCount extends Configured implements Tool{ public static class TVPlayMapper extends Mapper<Text, TVPlayData, Text, TVPlayData>{
@Override
protected void map(Text key, TVPlayData value,Context context)
throws IOException, InterruptedException
{
context.write(key, value);
}
} public static class TVPlayReducer extends Reducer<Text, TVPlayData, Text, Text>
{
private Text m_key=new Text();
private Text m_value = new Text();
private MultipleOutputs<Text, Text> mos; //将多路输出打开
protected void setup(Context context) throws IOException,InterruptedException
{
mos = new MultipleOutputs<Text, Text>(context);
} protected void reduce (Text Key,Iterable<TVPlayData> Values, Context context)
throws IOException, InterruptedException{
int daynumber = ;
int collectnumber = ;
int commentnumber = ;
int againstnumber = ;
int supportnumber = ; for (TVPlayData tv : Values){
daynumber+=tv.getDaynumber();
collectnumber+=tv.getCollectnumber();
commentnumber += tv.getCommentnumber();
againstnumber += tv.getAgainstnumber();
supportnumber += tv.getSupportnumber();
} String[] records=Key.toString().split("\t"); // 1优酷 2搜狐 3 土豆 4爱奇艺 5迅雷看看
String source =records[]; // 媒体类别
m_key.set(records[]);
m_value.set(daynumber+"\t"+collectnumber+"\t" +commentnumber+"\t"+againstnumber+"\t"+supportnumber);
if(source.equals("")){
mos.write("youku", m_key, m_value);
}else if (source.equals("")) {
mos.write("souhu", m_key, m_value);
} else if (source.equals("")) {
mos.write("tudou", m_key, m_value);
} else if (source.equals("")) {
mos.write("aiqiyi", m_key, m_value);
} else if (source.equals("")) {
mos.write("xunlei", m_key, m_value);
}
} //关闭 MultipleOutputs,也就是关闭 RecordWriter,并且是一堆 RecordWriter,因为这里会有很多 reduce 被调用。
protected void cleanup( Context context) throws IOException,InterruptedException {
mos.close();
}
} @Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration(); // 配置文件对象
Path mypath = new Path(args[]);
FileSystem hdfs = mypath.getFileSystem(conf);// 创建输出路径
if (hdfs.isDirectory(mypath)) {
hdfs.delete(mypath, true);
} Job job = new Job(conf, "tvplay");// 构造任务
job.setJarByClass(TVPlayCount.class);// 设置主类 job.setMapperClass(TVPlayMapper.class);// 设置Mapper
job.setMapOutputKeyClass(Text.class);// key输出类型
job.setMapOutputValueClass(TVPlayData.class);// value输出类型
job.setInputFormatClass(TVPlayInputFormat.class);//自定义输入格式 job.setReducerClass(TVPlayReducer.class);// 设置Reducer
job.setOutputKeyClass(Text.class);// reduce key类型
job.setOutputValueClass(Text.class);// reduce value类型
// 自定义文件输出格式,通过路径名(pathname)来指定输出路径
MultipleOutputs.addNamedOutput(job, "youku", TextOutputFormat.class,
Text.class, Text.class);
MultipleOutputs.addNamedOutput(job, "souhu", TextOutputFormat.class,
Text.class, Text.class);
MultipleOutputs.addNamedOutput(job, "tudou", TextOutputFormat.class,
Text.class, Text.class);
MultipleOutputs.addNamedOutput(job, "aiqiyi", TextOutputFormat.class,
Text.class, Text.class);
MultipleOutputs.addNamedOutput(job, "xunlei", TextOutputFormat.class,
Text.class, Text.class); FileInputFormat.addInputPath(job, new Path(args[]));// 输入路径
FileOutputFormat.setOutputPath(job, new Path(args[]));// 输出路径
job.waitForCompletion(true);
return ;
} public static void main(String[] args) throws Exception{
String[] args0={"hdfs://master:9000/tvplay/",
"hdfs://master:9000/tvplay/out"};
int ec = ToolRunner.run(new Configuration(), new TVPlayCount(), args0);
System.exit(ec);
}
}
TVPlayData.java
package com.dajiangtai.hadoop.tvplay; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.WritableComparable;
/**
*
* @author yangjun
* @function 自定义对象
*/
public class TVPlayData implements WritableComparable<Object>{
private int daynumber;
private int collectnumber;
private int commentnumber;
private int againstnumber;
private int supportnumber;
public TVPlayData(){}
public void set(int daynumber,int collectnumber,int commentnumber,int againstnumber,int supportnumber){
this.daynumber = daynumber;
this.collectnumber = collectnumber;
this.commentnumber = commentnumber;
this.againstnumber = againstnumber;
this.supportnumber = supportnumber;
}
public int getDaynumber() {
return daynumber;
}
public void setDaynumber(int daynumber) {
this.daynumber = daynumber;
}
public int getCollectnumber() {
return collectnumber;
}
public void setCollectnumber(int collectnumber) {
this.collectnumber = collectnumber;
}
public int getCommentnumber() {
return commentnumber;
}
public void setCommentnumber(int commentnumber) {
this.commentnumber = commentnumber;
}
public int getAgainstnumber() {
return againstnumber;
}
public void setAgainstnumber(int againstnumber) {
this.againstnumber = againstnumber;
}
public int getSupportnumber() {
return supportnumber;
}
public void setSupportnumber(int supportnumber) {
this.supportnumber = supportnumber;
}
@Override
public void readFields(DataInput in) throws IOException {
daynumber = in.readInt();
collectnumber = in.readInt();
commentnumber = in.readInt();
againstnumber = in.readInt();
supportnumber = in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(daynumber);
out.writeInt(collectnumber);
out.writeInt(commentnumber);
out.writeInt(againstnumber);
out.writeInt(supportnumber);
}
@Override
public int compareTo(Object o) {
return ;
};
}
TVPlayInputFormat.java
package com.dajiangtai.hadoop.tvplay; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.util.LineReader;
/**
*
* @author yangjun
* @function key vlaue 输入格式
*/
public class TVPlayInputFormat extends FileInputFormat<Text,TVPlayData>{ @Override
public RecordReader<Text, TVPlayData> createRecordReader(InputSplit input,
TaskAttemptContext context) throws IOException, InterruptedException {
return new TVPlayRecordReader();
} public class TVPlayRecordReader extends RecordReader<Text, TVPlayData>{
public LineReader in;
public Text lineKey;
public TVPlayData lineValue;
public Text line;
@Override
public void close() throws IOException {
if(in !=null){
in.close();
}
} @Override
public Text getCurrentKey() throws IOException, InterruptedException {
return lineKey;
} @Override
public TVPlayData getCurrentValue() throws IOException, InterruptedException {
return lineValue;
} @Override
public float getProgress() throws IOException, InterruptedException {
return ;
} @Override
public void initialize(InputSplit input, TaskAttemptContext context)
throws IOException, InterruptedException {
FileSplit split=(FileSplit)input;
Configuration job=context.getConfiguration();
Path file=split.getPath();
FileSystem fs=file.getFileSystem(job); FSDataInputStream filein=fs.open(file);
in=new LineReader(filein,job);
line=new Text();
lineKey=new Text();
lineValue = new TVPlayData();
} @Override
public boolean nextKeyValue() throws IOException, InterruptedException {
int linesize=in.readLine(line);
if(linesize==) return false;
String[] pieces = line.toString().split("\t");
if(pieces.length != ){
throw new IOException("Invalid record received");
}
lineKey.set(pieces[]+"\t"+pieces[]);
lineValue.set(Integer.parseInt(pieces[]),Integer.parseInt(pieces[]),Integer.parseInt(pieces[])
,Integer.parseInt(pieces[]),Integer.parseInt(pieces[]));
return true;
}
}
}
先启动3节点集群

与自己在本地搭建的3节点集群的hdfs连接上
在终端显示的运行结果,程序没有错误
-- ::, INFO [org.apache.hadoop.conf.Configuration.deprecation] - session.id is deprecated. Instead, use dfs.metrics.session-id
-- ::, INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with processName=JobTracker, sessionId=
-- ::, WARN [org.apache.hadoop.mapreduce.JobSubmitter] - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
-- ::, WARN [org.apache.hadoop.mapreduce.JobSubmitter] - No job jar file set. User classes may not be found. See Job or Job#setJar(String).
-- ::, INFO [org.apache.hadoop.mapreduce.lib.input.FileInputFormat] - Total input paths to process :
-- ::, INFO [org.apache.hadoop.mapreduce.JobSubmitter] - number of splits:
-- ::, INFO [org.apache.hadoop.conf.Configuration.deprecation] - user.name is deprecated. Instead, use mapreduce.job.user.name
-- ::, INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class
-- ::, INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.mapoutput.value.class is deprecated. Instead, use mapreduce.map.output.value.class
-- ::, INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapreduce.map.class is deprecated. Instead, use mapreduce.job.map.class
-- ::, INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.job.name is deprecated. Instead, use mapreduce.job.name
-- ::, INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapreduce.reduce.class is deprecated. Instead, use mapreduce.job.reduce.class
-- ::, INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapreduce.inputformat.class is deprecated. Instead, use mapreduce.job.inputformat.class
-- ::, INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
-- ::, INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
-- ::, INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
-- ::, INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.output.key.class is deprecated. Instead, use mapreduce.job.output.key.class
-- ::, INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.mapoutput.key.class is deprecated. Instead, use mapreduce.map.output.key.class
-- ::, INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir
-- ::, INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Submitting tokens for job: job_local300699497_0001
-- ::, WARN [org.apache.hadoop.conf.Configuration] - file:/tmp/hadoop-Administrator/mapred/staging/Administrator300699497/.staging/job_local300699497_0001/job.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring.
-- ::, WARN [org.apache.hadoop.conf.Configuration] - file:/tmp/hadoop-Administrator/mapred/staging/Administrator300699497/.staging/job_local300699497_0001/job.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring.
-- ::, WARN [org.apache.hadoop.conf.Configuration] - file:/tmp/hadoop-Administrator/mapred/local/localRunner/Administrator/job_local300699497_0001/job_local300699497_0001.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring.
-- ::, WARN [org.apache.hadoop.conf.Configuration] - file:/tmp/hadoop-Administrator/mapred/local/localRunner/Administrator/job_local300699497_0001/job_local300699497_0001.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring.
-- ::, INFO [org.apache.hadoop.mapreduce.Job] - The url to track the job: http://localhost:8080/
-- ::, INFO [org.apache.hadoop.mapreduce.Job] - Running job: job_local300699497_0001
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter set in config null
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for map tasks
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local300699497_0001_m_000000_0
-- ::, INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
-- ::, INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@1b9156ad
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - Processing split: hdfs://master:9000/tvplay/tvplay.txt:0+10833923
-- ::, INFO [org.apache.hadoop.mapreduce.Job] - Job job_local300699497_0001 running in uber mode : false
-- ::, INFO [org.apache.hadoop.mapreduce.Job] - map % reduce %
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) kvi ()
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb:
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - soft limit at
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - bufstart = ; bufvoid =
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - kvstart = ; length =
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] -
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - bufstart = ; bufend = ; bufvoid =
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - kvstart = (); kvend = (); length = /
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - Finished spill
-- ::, INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local300699497_0001_m_000000_0 is done. And is in the process of committing
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
-- ::, INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local300699497_0001_m_000000_0' done.
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local300699497_0001_m_000000_0
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - Map task executor complete.
-- ::, INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
-- ::, INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@fba110e
-- ::, INFO [org.apache.hadoop.mapred.Merger] - Merging sorted segments
-- ::, INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with segments left of total size: bytes
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] -
-- ::, INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
-- ::, INFO [org.apache.hadoop.mapreduce.Job] - map % reduce %
-- ::, INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local300699497_0001_r_000000_0 is done. And is in the process of committing
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] -
-- ::, INFO [org.apache.hadoop.mapred.Task] - Task attempt_local300699497_0001_r_000000_0 is allowed to commit now
-- ::, INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - Saved output of task 'attempt_local300699497_0001_r_000000_0' to hdfs://master:9000/tvplay/out/_temporary/0/task_local300699497_0001_r_000000
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > reduce
-- ::, INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local300699497_0001_r_000000_0' done.
-- ::, INFO [org.apache.hadoop.mapreduce.Job] - map % reduce %
-- ::, INFO [org.apache.hadoop.mapreduce.Job] - Job job_local300699497_0001 completed successfully
-- ::, INFO [org.apache.hadoop.mapreduce.Job] - Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input split bytes=
Combine input records=
Combine output records=
Reduce input groups=
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
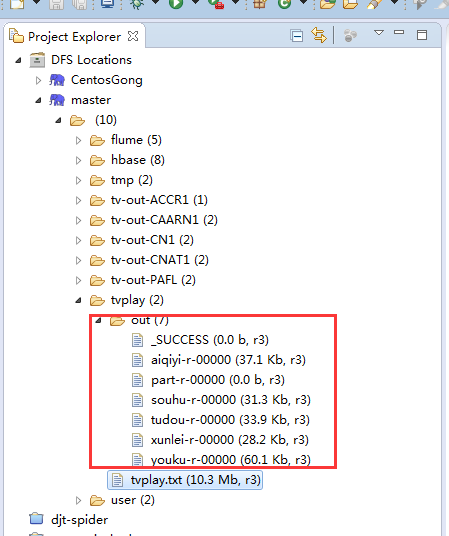
查看hdfs上的输出结果

mapreduce深入剖析5大视频的更多相关文章
- 如何使用油猴脚本不要vip就能观看各大视频网站如腾讯,爱奇艺等的vip视频
如何使用油猴脚本不要vip就能观看各大视频网站如腾讯,爱奇艺等的vip视频 首先打开谷歌商店(这里需要fq,如不能fq的小伙伴请看上面写的Chrome怎么访问外网) 搜索Tampermonkey,点击 ...
- 关于大视频video播放的问题以及解决方案(m3u8的播放)
在HTML5里,提供了<video>标签,可以直接播放视频,video的使用很简单: <video width="320" height="240&qu ...
- 详细剖析pyecharts大屏的Page函数配置文件:chart_config.json
目录 一.问题背景 二.揭开json文件神秘面纱 三.巧用json文件 四.关于Table图表 五.同步讲解视频 5.1 讲解json的视频 5.2 讲解全流程大屏的视频 5.3 讲解全流程大屏的文章 ...
- 百度编辑器上传大视频报http请求错误怎么办
百度编辑器UEditor是由百度web前端研发部开发所见即所得富文本web编辑器,具有轻量,可定制,注重用户体验等特点,开源基于MIT协议,允许自由使用和修改代码,所以受到很多开放人员的青睐.但是有时 ...
- 深度剖析 | 基于大数据架构的BI应用
说起互联网.电商的数据分析,更多的是谈应用案例,如何去实践数据化管理运营.而这里,我们要从技术角度分享关于数据的技术架构干货,如何应用BI. 原文是云猴网BI总经理王卫东在帆软大数据上的演讲,以下是整 ...
- 简单获取各大视频网站的flash地址
最近做网站的时候遇到一个需求:给定一个视频地址,获取它的swf地址.例如,给一个优酷的视频地址:http://v.youku.com /v_show/id_XNDg4MzY5ODU2.html,想获取 ...
- webUploader上传大视频文件相关web.config配置
在webuploader上传大文件时必须配置一下,不然请求后台处理程序时,会请求超时.出现404! <system.web> <httpRuntime maxRequestLengt ...
- java大视频上传实现
理清思路: 引入了两个概念:块(block)和片(chunk).每个块由一到多个片组成,而一个资源则由一到多个块组成 块是服务端的永久数据存储单位,片则只在分片上传过程中作为临时存储的单位.服务端会以 ...
- php+大视频文件上传+进度条
该项目核心就是文件分块上传.前后端要高度配合,需要双方约定好一些数据,才能完成大文件分块,我们在项目中要重点解决的以下问题. * 如何分片: * 如何合成一个文件: * 中断了从哪个分片开始. 如何分 ...
随机推荐
- Windows2008R2系统运行时间超过497天的bug
早上接到客户电话,说一台测试服务器tomcat服务无法访问,登录服务器查看tomcat连接数据库故障. 使用plsql develop工具登录,提示 ora-12560 TNS:protocol ad ...
- JS 从HTML页面获取自定义属性值
<select id="nextType" data-parameter="@Model.NextType"> <option value=& ...
- Oracle 增加、修改、删除字段
分别对T_USER表 进行增加name字段, 修改name字段,删除name字段 /*增加列表*/ ALTER TABLE T_USERS ADD name varchar2(512) ; /*删除列 ...
- HanLP二元核心词典详细解析
本文分析:HanLP版本1.5.3中二元核心词典的存储与查找.当词典文件没有被缓存时,会从文本文件CoreNatureDictionary.ngram.txt中解析出来存储到TreeMap中,然后构造 ...
- chgrp命令详解
Linux chgrp命令 Linux chgrp命令用于变更文件或目录的所属群组. 在UNIX系统家族里,文件或目录权限的掌控以拥有者及所属群组来管理.您可以使用chgrp指令去变更文件与目录的所属 ...
- jQuery 筛选器 链式编程操作
$('#i1').next() 下一个标签$('#i1').nextAll() 兄弟标签中,所有下一个标签$('#i1').nextUntil('#ii1') 兄弟标签中,从下一个标签到id为ii1的 ...
- 查找Python项目依赖的库并生成requirements.txt
使用pip freeze pip freeze > requirements.txt 这种方式配合virtualenv 才好使,否则把整个环境中的包都列出来了. 使用 pipreqs 这个工具的 ...
- C#实现设置系统时间
using System; using System.Runtime.InteropServices; using System.Windows.Forms; namespace Demo { pub ...
- 陷入了一个NGUI自适应的一个坑
自己对anchor的乱用.造成自己深陷anchor来搞自适应 耽误了太多的精力,最终也是回到正轨的途径 这期间浪费的太多精力了. 沉迷一件错误的事情过久 就 要果断的跳出 调整 . 但凡让自己觉得别扭 ...
- HTTP是什么?,GET与POST区别?
HTTP是什么? 超文本传输协议(HTTP),目的是保证客户端与服务器之间的通信. 工作方式是客户端与服务器之间的请求-应答协议. web浏览器可能是客户端,计算机上的网络应用程序也可能作为服务器端. ...