K-means聚类算法的三种改进(K-means++,ISODATA,Kernel K-means)介绍与对比
一、概述
在本篇文章中将对四种聚类算法(K-means,K-means++,ISODATA和Kernel K-means)进行详细介绍,并利用数据集来真实地反映这四种算法之间的区别。
首先需要明确的是上述四种算法都属于"硬聚类”算法,即数据集中每一个样本都是被100%确定得分到某一个类别中。与之相对的"软聚类”可以理解为每个样本是以一定的概率被分到某一个类别中。
先简要阐述下上述四种算法之间的关系,已经了解过经典K-means算法的读者应该会有所体会。没有了解过K-means的读者可以先看下面的经典K-means算法介绍再回来看这部分。
(1) K-means与K-means++:原始K-means算法最开始随机选取数据集中K个点作为聚类中心,而K-means++按照如下的思想选取K个聚类中心:假设已经选取了n个初始聚类中心(0<n<K),则在选取第n+1个聚类中心时:距离当前n个聚类中心越远的点会有更高的概率被选为第n+1个聚类中心。在选取第一个聚类中心(n=1)时同样通过随机的方法。可以说这也符合我们的直觉:聚类中心当然是互相离得越远越好。这个改进虽然直观简单,但是却非常得有效。
(2) K-means与ISODATA:ISODATA的全称是迭代自组织数据分析法。在K-means中,K的值需要预先人为地确定,并且在整个算法过程中无法更改。而当遇到高维度、海量的数据集时,人们往往很难准确地估计出K的大小。ISODATA就是针对这个问题进行了改进,它的思想也很直观:当属于某个类别的样本数过少时把这个类别去除,当属于某个类别的样本数过多、分散程度较大时把这个类别分为两个子类别。
(3) K-means与Kernel K-means:传统K-means采用欧式距离进行样本间的相似度度量,显然并不是所有的数据集都适用于这种度量方式。参照支持向量机中核函数的思想,将所有样本映射到另外一个特征空间中再进行聚类,就有可能改善聚类效果。本文不对Kernel K-means进行详细介绍。
可以看到,上述三种针对K-means的改进分别是从不同的角度出发的,因此都非常具有代表意义。目前应用广泛的应该还是K-means++算法(例如2016年底的NIPS上也有针对K-means++的改进,感兴趣的读者可以进一步学习)。
二、经典K-means算法
算法描述如下,非常清晰易懂。经典K-means算法应该是每个无监督学习教程开头都会讲的内容,故不再多费口舌说一遍了。
 图1. 经典K-means算法
图1. 经典K-means算法
值得一提的是关于聚类中心数目(K值)的选取,的确存在一种可行的方法,叫做Elbow Method:通过绘制K-means代价函数与聚类数目K的关系图,选取直线拐点处的K值作为最佳的聚类中心数目。但在这边不做过多的介绍,因为上述方法中的拐点在实际情况中是很少出现的。比较提倡的做法还是从实际问题出发,人工指定比较合理的K值,通过多次随机初始化聚类中心选取比较满意的结果。
三、K-means++算法
2007年由D. Arthur等人提出的K-means++针对图1中的第一步做了改进。可以直观地将这改进理解成这K个初始聚类中心相互之间应该分得越开越好。整个算法的描述如下图所示:

图2. K-means++算法
下面结合一个简单的例子说明K-means++是如何选取初始聚类中心的。数据集中共有8个样本,分布以及对应序号如下图所示:
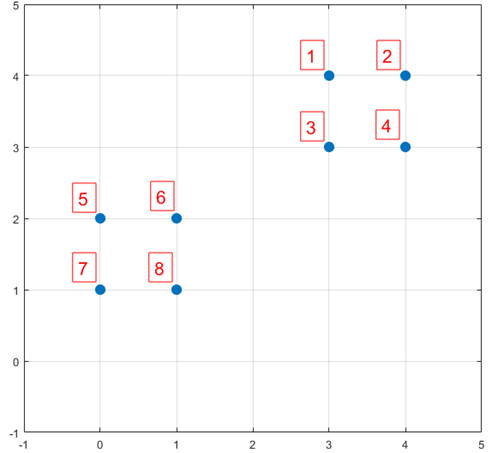 图3. K-means++示例
图3. K-means++示例
假设经过图2的步骤一后6号点被选择为第一个初始聚类中心,那在进行步骤二时每个样本的D(x)和被选择为第二个聚类中心的概率如下表所示:
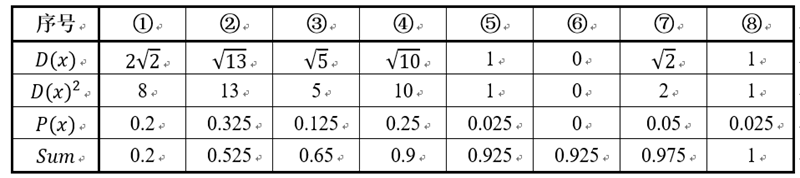
其中的P(x)就是每个样本被选为下一个聚类中心的概率。最后一行的Sum是概率P(x)的累加和,用于轮盘法选择出第二个聚类中心。方法是随机产生出一个0~1之间的随机数,判断它属于哪个区间,那么该区间对应的序号就是被选择出来的第二个聚类中心了。例如1号点的区间为[0,0.2),2号点的区间为[0.2, 0.525)。
从上表可以直观的看到第二个初始聚类中心是1号,2号,3号,4号中的一个的概率为0.9。而这4个点正好是离第一个初始聚类中心6号点较远的四个点。这也验证了K-means的改进思想:即离当前已有聚类中心较远的点有更大的概率被选为下一个聚类中心。可以看到,该例的K值取2是比较合适的。当K值大于2时,每个样本会有多个距离,需要取最小的那个距离作为D(x)。
四、ISODATA算法
放在最后也是最复杂的就是ISODATA算法。正如之前所述,K-means和K-means++的聚类中心数K是固定不变的。而ISODATA算法在运行过程中能够根据各个类别的实际情况进行两种操作来调整聚类中心数K:(1)分裂操作,对应着增加聚类中心数;(2)合并操作,对应着减少聚类中心数。
下面首先给出ISODATA算法的输入(输入的数据和迭代次数不再单独介绍):
[1] 预期的聚类中心数目Ko:虽然在ISODATA运行过程中聚类中心数目是可变的,但还是需要由用户指定一个参考标准。事实上,该算法的聚类中心数目变动范围也由Ko决定。具体地,最终输出的聚类中心数目范围是 [Ko/2, 2Ko]。
[2] 每个类所要求的最少样本数目Nmin:用于判断当某个类别所包含样本分散程度较大时是否可以进行分裂操作。如果分裂后会导致某个子类别所包含样本数目小于Nmin,就不会对该类别进行分裂操作。
[3] 最大方差Sigma:用于衡量某个类别中样本的分散程度。当样本的分散程度超过这个值时,则有可能进行分裂操作(注意同时需要满足[2]中所述的条件)。
[4] 两个类别对应聚类中心之间所允许最小距离dmin:如果两个类别靠得非常近(即这两个类别对应聚类中心之间的距离非常小),则需要对这两个类别进行合并操作。是否进行合并的阈值就是由dmin决定。
相信很多人看完上述输入的介绍后对ISODATA算法的流程已经有所猜测了。的确,ISODATA算法的原理非常直观,不过由于它和其他两个方法相比需要额外指定较多的参数,并且某些参数同样很难准确指定出一个较合理的值,因此ISODATA算法在实际过程中并没有K-means++受欢迎。
首先给出ISODATA算法主体部分的描述,如下图所示:

图4. ISODATA算法的主体部分
上面描述中没有说明清楚的是第5步中的分裂操作和第6步中的合并操作。下面首先介绍合并操作:

图5. ISODATA算法的合并操作
最后是ISODATA算法中的分裂操作。

图6. ISODATA算法的分裂操作
最后,针对ISODATA算法总结一下:该算法能够在聚类过程中根据各个类所包含样本的实际情况动态调整聚类中心的数目。如果某个类中样本分散程度较大(通过方差进行衡量)并且样本数量较大,则对其进行分裂操作;如果某两个类别靠得比较近(通过聚类中心的距离衡量),则对它们进行合并操作。
可能没有表述清楚的地方是ISODATA-分裂操作的第1步和第2步。同样地以图三所示数据集为例,假设最初1,2,3,4,5,6,8号被分到了同一个类中,执行第1步和第2步结果如下所示:
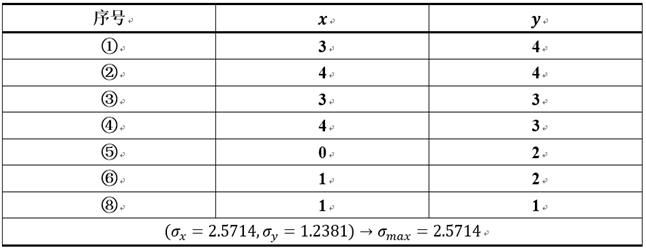
而在正确分类情况下(即1,2,3,4为一类;5,6,7,8为一类),方差为0.33。因此,目前的方差远大于理想的方差,ISODATA算法就很有可能对其进行分裂操作。
五、聚类算法源代码
我已经将上述三种算法整合成一个Matlab函数Clustering.m。读者可以直接使用该函数对数据集进行聚类。由于代码比较长,而且代码插件还不怎么会用,就不在文中介绍了。需要使用的读者可以点击下面的链接下载使用(欢迎Star和Fork,之后会不定期补充新的算法和优化的):
https://github.com/AaronX121/Unsupervised-Learning-Clustering
使用方式非常简单,目前支持三种形式的输入,分别对应着上面的三种算法:
[centroid, result] = Clustering(data, ‘kmeans’, k , iteration);
[centroid, result] = Clustering(data, ‘kmeans++’, k , iteration);
[centroid, result] =
Clustering(data, ‘isodata’, desired_k , iteration, minimum_n, maximum_variance, minimum_d);
其中的输入data是一个矩阵,每一行代表数据集中的一个样本。其他输入的意义与上面的算法描述中一一对应。输出的centroid是聚类中心的位置,result是每个样本所对应的类别索引。
六、数据集测试
最后以一个简单的满足二维高斯分布的数据集为例,展示上述三种算法的聚类结果,如下图所示。
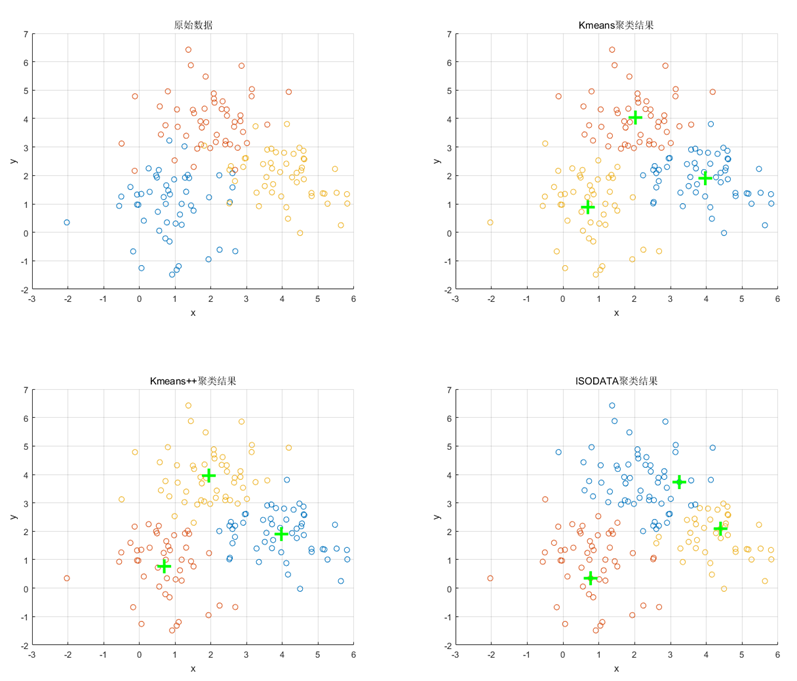
图7. 一个简单数据集上三种算法的聚类效果(绿色加号代表聚类中心位置)
K-means聚类算法的三种改进(K-means++,ISODATA,Kernel K-means)介绍与对比的更多相关文章
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
- Top k问题的讨论(三种方法的java实现及适用范围)
在很多的笔试和面试中,喜欢考察Top K.下面从自身的经验给出三种实现方式及实用范围. 合并法 这种方法适用于几个数组有序的情况,来求Top k.时间复杂度为O(k*m).(m:为数组的个数).具体实 ...
- 编程算法 - 背包问题(三种动态规划) 代码(C)
背包问题(三种动态规划) 代码(C) 本文地址: http://blog.csdn.net/caroline_wendy 题目參考: http://blog.csdn.net/caroline_wen ...
- Win10计算器在哪里?三种可以打开Win10计算器的方法图文介绍
全新的windows10系统带来了不少新的特性和改变,其中win10的计算器位置就发生了很多的变化,导致很多网友们都以为win10计算器不见了,那么,win10计算器在哪里?如何打开?针对此问题,本文 ...
- VPS采用的几种常见技术(OVZ、Xen、KVM)介绍与对比
很多人看到同样配置的VPS价格相差很大,甚是不理解,其实VPS使用的虚拟技术种类有很多,如OpenVZ.Xen.KVM.Xen和HVM与PV. 在+XEN中pv是半虚拟化,hvm是全虚拟化,pv只能用 ...
随机推荐
- Windows 7 上面 redis 启动报错的处理
Windows 7或者是 win10 上面 安装redis 的windows 3.2.100 的版本 启动报错: Creating Server TCP listening socket *:: li ...
- ThreadLocal变量
什么是ThreadLocal变量?ThreadLocal,很多地方叫做线程本地变量,也有些地方叫做线程本地存储,其实意思差不多.可能很多朋友都知道ThreadLocal为变量在每个线程中都创建了一个副 ...
- Gym - 101522H Hit!
H. Hit! time limit per test 1.0 s memory limit per test 256 MB input standard input output standard ...
- HGOI20181030 模拟题解
problem:给定一个序列,问你能不能通过一次交换把他弄成有序 sol: 对于0%的数据,满足数列是一个排列,然后我就打了这档分(自己瞎造的!) 对于100%的数据,显然我们先对数列进行排序然后上下 ...
- Access与SQL Server 语法差异
序号 简述 Access语法 SqlServer语法 Oracle语法 解决方案 01 系统时间 Now(),Date() GETDATE() SYSDATE GetSysTimeStr 02 连接字 ...
- LVS NAT/DR
LVS介绍:http://www.linuxvirtualserver.org/zh/lvs3.html DR 工作流: HOST发送服务请求报文(源IP为HOST IP,目的IP为VSIP) Gen ...
- <meta http-equiv="X-UA-Compatible" content="IE=7" />意思是将IE8用IE7进行渲染,使网页在IE8下正常
X-UA-Compatible是针对ie8新加的一个设置,对于ie8之外的浏览器是不识别的,这个区别与content="IE=7"在无论页面是否包含<!DOCTYPE> ...
- 什么是spu和sku
电商概念SPU与SKU SPU = Standard Product Unit (标准产品单位)SPU是商品信息聚合的最小单位,是一组可复用.易检索的标准化信息的集合,该集合描述了一个产品的特性.通俗 ...
- 设置 Linux 服务器中 MySQL 允许远程访问
开启 MySQL 远程访问权限: 在linux系统上登陆mysql服务. -- root 是用户名 [root@localhost ~]# mysql -u root -p Enter passwor ...
- spring中set注入的一些小细节错误
这是小白偶尔一直null指针的错误,调试了好久,原来是自己对spring注入的不够了解 我相信有很多跟我差不多的初学者会遇上,所以特地写出来,防止有人跟我一样.哈哈,也写上去,以防自己下次还犯这样的错 ...