Pyspider抓取静态页面
近期,我想爬一批新闻资讯的内容。新闻类型的网址很多,我想看看有没有一个网页上能包罗尽可能多的新闻网站呢,于是就发现了下面这个网页
http://news.hao123.com/wangzhi
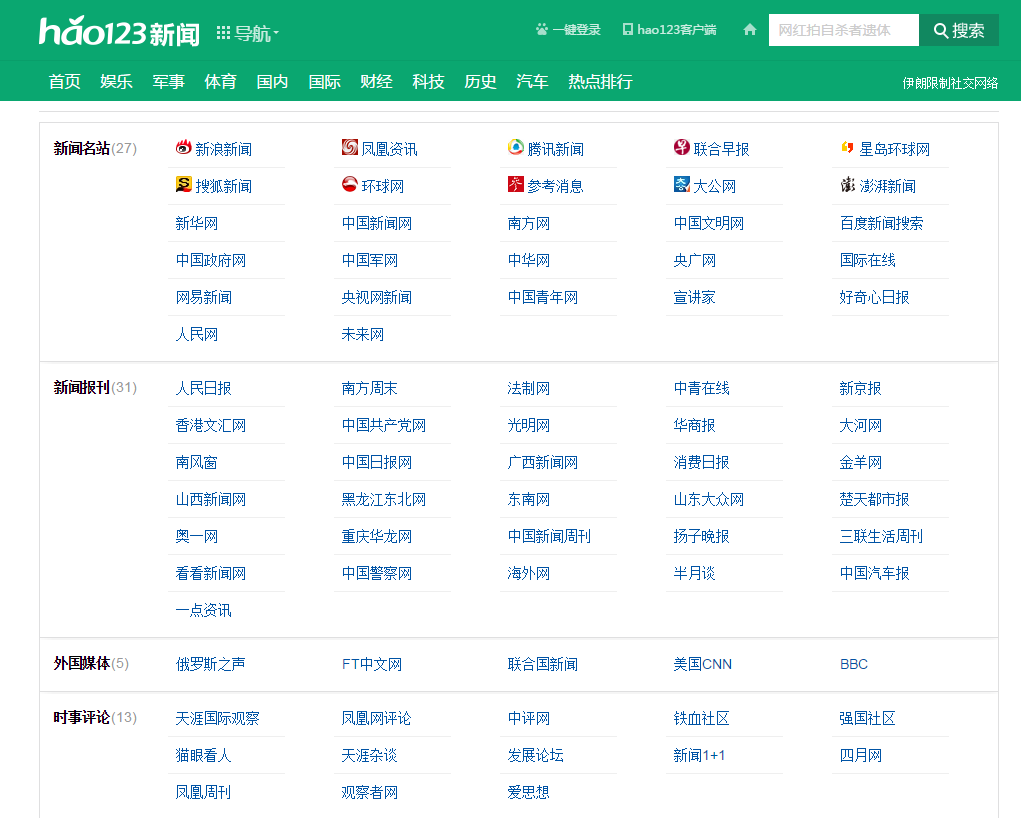
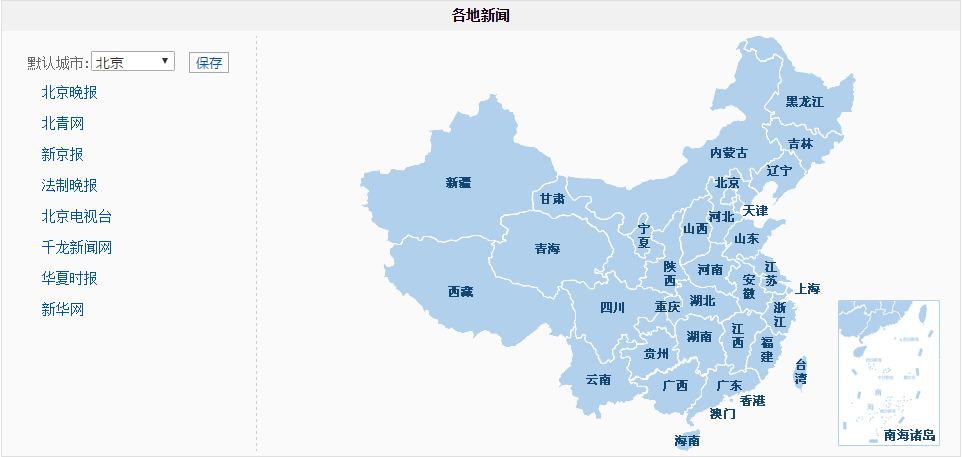
这个页面的下边还有地方新闻的分类
1、爬取目标
按类型分的网址列表
按地方分的网址列表
2、按类型
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-01-02 15:44:54
# Project: financeNews from pyspider.libs.base_handler import * class Handler(BaseHandler):
crawl_config = {
} def __init__(self):
self.url = 'http://news.hao123.com/wangzhi' @every(minutes=24 * 60)
def on_start(self):
self.crawl(self.url,callback=self.index_page) @config(age=10 * 24 * 60 * 60)
def index_page(self, response): return [{
"group" : x('.content-title').text(),
"websites" : [a.text() for a in x('li a').items()]
} for x in response.doc('.mod-content').items()]
运行结果

3、按地方
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-01-02 15:44:54
# Project: financeNews from pyspider.libs.base_handler import * class Handler(BaseHandler):
crawl_config = {
} def __init__(self):
self.url = 'http://news.hao123.com/wangzhi' @every(minutes=24 * 60)
def on_start(self):
self.crawl(self.url,callback=self.index_page) @config(age=10 * 24 * 60 * 60)
def index_page(self, response): return [{
"city" : x.attr('id')[5:],
"websites" : [a.text() for a in x('li a').items()]
} for x in response.doc('.page').items()]
运行结果

4、知识点小结
4.1 __init__()方法为对象创建完成后的初始化方法,自动执行,可以自定义一些全局属性
4.2 "city" : x.attr('id')[5:]
取属性id的值,并从第6个字符截取
4.3 可以在return中多级遍历,数组套数组
4.4 pyspider提供了元素选择帮助功能,可以快捷选取元素,但不是非常精确
Pyspider抓取静态页面的更多相关文章
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息PySpider:一个国人编写的强大的网络爬虫系统并带有强大的WebUI,采用Python语言编写 ...
- Python爬虫之一 PySpider 抓取淘宝MM的个人信息和图片
ySpider 是一个非常方便并且功能强大的爬虫框架,支持多线程爬取.JS动态解析,提供了可操作界面.出错重试.定时爬取等等的功能,使用非常人性化. 本篇通过做一个PySpider 项目,来理解 Py ...
- 利用curl抓取远程页面内容
最基本的操作如下 $curlPost = 'a=1&b=2';//模拟POST数据$cookie_file = tempnam('./temp','kie');//可选,保存ses ...
- php curl抓取远程页面内容的代码
使用php curl抓取远程页面内容的例子. 代码如下: <?php /** * php curl抓取远程网页内容 * edit by www.jbxue.com */ $curlPost = ...
- php抓取ajax页面返回图片。
要抓取的页面:http://pic.hao123.com/ 当我们往下滚动的时候,图片是用ajax来动态获取的.这就需要我们仔细分析页面了. 可以看到,异步加载的ajax文件为: http://pic ...
- C#抓取AJAX页面的内容
原文 C#抓取AJAX页面的内容 现在的网页有相当一部分是采用了AJAX技术,所谓的AJAX技术简单一点讲就是事件驱动吧(当然这种说法可能很不全面),在你提交了URL后,服务器发给你的并不是所有是页面 ...
- Scrapy爬取静态页面
Scrapy爬取静态页面 安装Scrapy框架: Scrapy是python下一个非常有用的一个爬虫框架 Pycharm下: 搜索Scrapy库添加进项目即可 终端下: #python2 sudo p ...
- 简易数据分析 13 | Web Scraper 抓取二级页面
这是简易数据分析系列的第 13 篇文章. 不知不觉,web scraper 系列教程我已经写了 10 篇了,这 10 篇内容,基本上覆盖了 Web Scraper 大部分功能.今天的内容算这个系列的最 ...
- 用C#抓取AJAX页面的内容
现在的网页有相当一部分是采用了AJAX技术,不管是采用C#中的WebClient还是HttpRequest都得不到正确的结果,因为这些脚本是在服务器发送完毕后才执行的! 但我们用IE浏览页面时是正常的 ...
随机推荐
- IDEA Tomcat Web项目修改了代码,重新部署页面没改变
今天被IDEA坑的不浅直接说一下问题: 这是html页面不管我怎么修改重启服务器在浏览器中还是一点都不变化,甚至把一些内容都删了都没有变化,target可执行文件是最新的没问题,找了点资料发现是浏览器 ...
- 关于电脑重装win10系统导致编译环境失效(jdk)
年前换了固态,于是重装了系统发现之前装在非系统盘的jdk1.8配置过系统环境后仍然不能正常使用的问题,在犹豫一会后选择了重装jdk, 由于之前用的是win7在环境配置上是 变量值内加;即可自行分行,但 ...
- Java虚拟机 - 类加载机制
[深入Java虚拟机]之四:类加载机制 类加载过程 类从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期包括:加载.验证.准备.解析.初始化.使用和卸载七个阶段.它们开始的顺序如下 ...
- POJ3268(KB4-D spfa)
Silver Cow Party Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 23426 Accepted: 1069 ...
- python学习之老男孩python全栈第九期_day007作业
一.关系运算 有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合pythons={'alex','egon','yuanhao','wu ...
- 【java】开发中常用字符串方法
java字符串的功能可以说非常强大, 它的每一种方法也都很有用. java字符串中常用的有两种字符串类, 分别是String类和StringBuffer类. Sting类 String类的对象是不可变 ...
- CentOS7下安装caffe(包括ffmpeg\boost\opencv)
因为有项目想采用深度学习,而caffe是深度学习框架中比较理想的一款,并且跨平台,以及可以采用python/matlab的方式进行调用等优势,所以想在服务器上安装,下面就开始了血泪史... 服务器是阿 ...
- Maven学习(六)maven使用中遇到的坑
坑1:使用eclipse构建web项目时,pom.xml中 <packaging>war</packaging> 报错 eclipse给出的报错信息提示是:web.xml is ...
- 原生JSON解析
原生JSON解析 JSONObject:JSON数据封装对象JSONArray:JSON数据封装数组 布局: <?xml version="1.0" encoding=&qu ...
- WiFi 统一管理以及设备自动化测试实践
ATX 安卓设备 WiFi 统一管理以及设备自动化测试实践 (零散知识梳理总结) 此文为转载,感谢作者 目录 众所周知,安卓单台设备的UI自动化测试已经比较完善了,有数不清的自动化框架或者工具.但 ...