JAVA 基本数据结构--数组、链表、ArrayList、Linkedlist、hashmap、hashtab等
概要
线性表是一种线性结构,它是具有相同类型的n(n≥0)个数据元素组成的有限序列。本章先介绍线性表的几个基本组成部分:数组、单向链表、双向链表;随后给出双向链表的C、C++和Java三种语言的实现。内容包括:
出处:http://www.cnblogs.com/skywang12345/p/3561803.html
数组
数组有上界和下界,数组的元素在上下界内是连续的。
存储10,20,30,40,50的数组的示意图如下: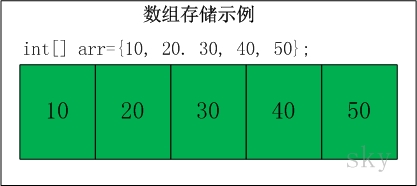
数组的特点是:数据是连续的;随机访问速度快。
数组中稍微复杂一点的是多维数组和动态数组。对于C语言而言,多维数组本质上也是通过一维数组实现的。至于动态数组,是指数组的容量能动态增长的数组;对于C语言而言,若要提供动态数组,需要手动实现;而对于C++而言,STL提供了Vector;对于Java而言,Collection集合中提供了ArrayList和Vector。
单向链表
单向链表(单链表)是链表的一种,它由节点组成,每个节点都包含下一个节点的指针。
单链表的示意图如下: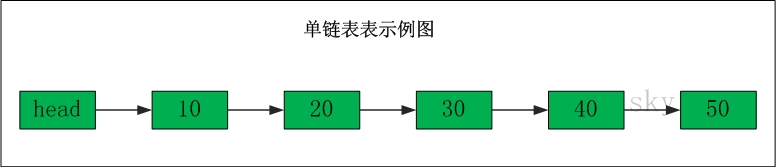
表头为空,表头的后继节点是"节点10"(数据为10的节点),"节点10"的后继节点是"节点20"(数据为10的节点),...
单链表删除节点
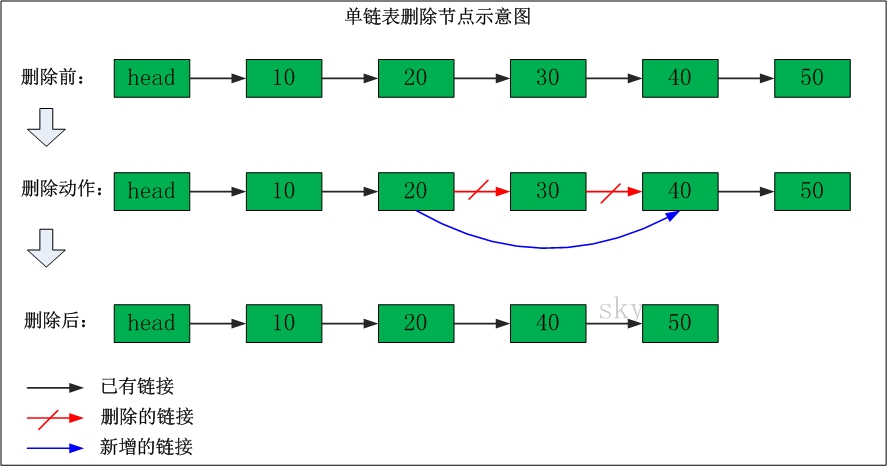
删除"节点30"
删除之前:"节点20" 的后继节点为"节点30",而"节点30" 的后继节点为"节点40"。
删除之后:"节点20" 的后继节点为"节点40"。
单链表添加节点
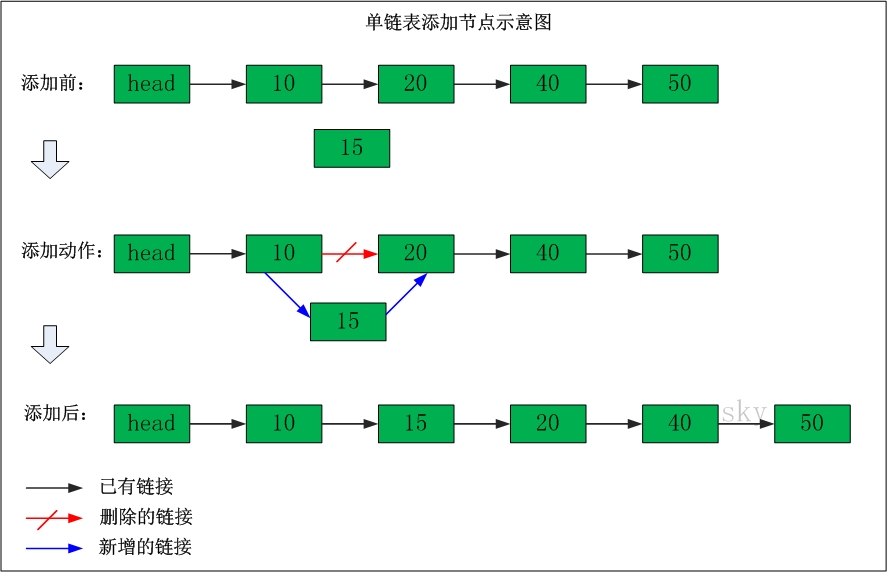
在"节点10"与"节点20"之间添加"节点15"
添加之前:"节点10" 的后继节点为"节点20"。
添加之后:"节点10" 的后继节点为"节点15",而"节点15" 的后继节点为"节点20"。
单链表的特点是:节点的链接方向是单向的;相对于数组来说,单链表的的随机访问速度较慢,但是单链表删除/添加数据的效率很高。
双向链表
双向链表(双链表)是链表的一种。和单链表一样,双链表也是由节点组成,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。一般我们都构造双向循环链表。
双链表的示意图如下:
表头为空,表头的后继节点为"节点10"(数据为10的节点);"节点10"的后继节点是"节点20"(数据为10的节点),"节点20"的前继节点是"节点10";"节点20"的后继节点是"节点30","节点30"的前继节点是"节点20";...;末尾节点的后继节点是表头。
双链表删除节点
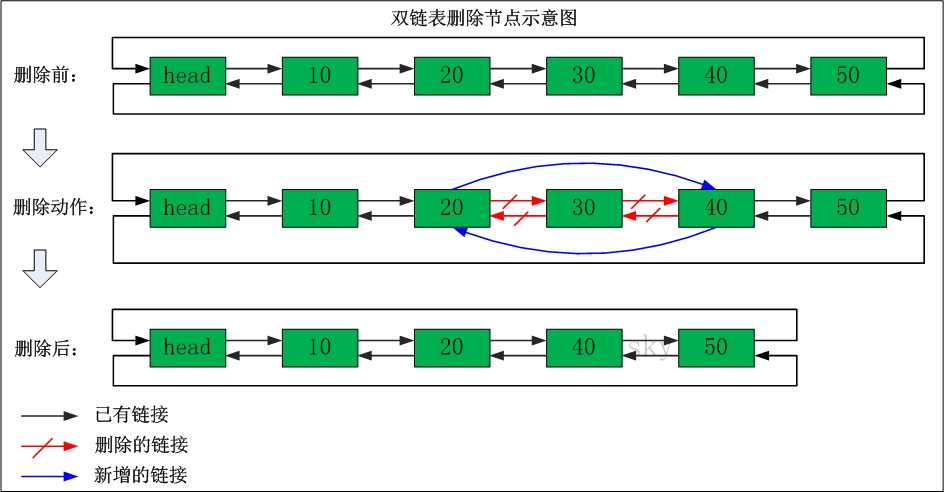
删除"节点30"
删除之前:"节点20"的后继节点为"节点30","节点30" 的前继节点为"节点20"。"节点30"的后继节点为"节点40","节点40" 的前继节点为"节点30"。
删除之后:"节点20"的后继节点为"节点40","节点40" 的前继节点为"节点20"。
双链表添加节点
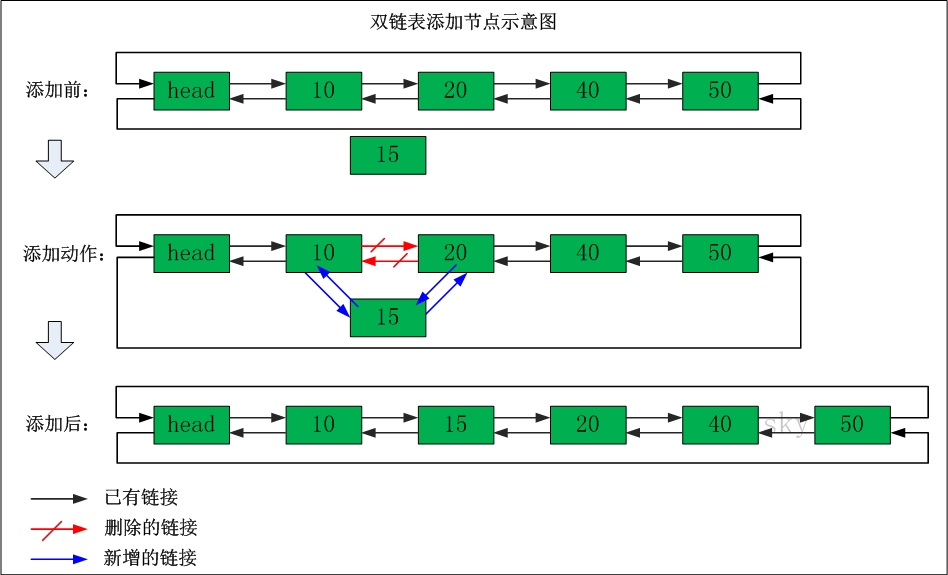
在"节点10"与"节点20"之间添加"节点15"
添加之前:"节点10"的后继节点为"节点20","节点20" 的前继节点为"节点10"。
添加之后:"节点10"的后继节点为"节点15","节点15" 的前继节点为"节点10"。"节点15"的后继节点为"节点20","节点20" 的前继节点为"节点15"。
下面介绍双链表的实现,介绍Java实现
双链表类(DoubleLink.java)
/**
* Java 实现的双向链表。
* 注:java自带的集合包中有实现双向链表,路径是:java.util.LinkedList
*
* @author skywang
* @date 2013/11/07
*/
public class DoubleLink<T> { // 表头
private DNode<T> mHead;
// 节点个数
private int mCount; // 双向链表“节点”对应的结构体
private class DNode<T> {
public DNode prev;
public DNode next;
public T value; public DNode(T value, DNode prev, DNode next) {
this.value = value;
this.prev = prev;
this.next = next;
}
} // 构造函数
public DoubleLink() {
// 创建“表头”。注意:表头没有存储数据!
mHead = new DNode<T>(null, null, null);
mHead.prev = mHead.next = mHead;
// 初始化“节点个数”为0
mCount = 0;
} // 返回节点数目
public int size() {
return mCount;
} // 返回链表是否为空
public boolean isEmpty() {
return mCount==0;
} // 获取第index位置的节点
private DNode<T> getNode(int index) {
if (index<0 || index>=mCount)
throw new IndexOutOfBoundsException(); // 正向查找
if (index <= mCount/2) {
DNode<T> node = mHead.next;
for (int i=0; i<index; i++)
node = node.next; return node;
} // 反向查找
DNode<T> rnode = mHead.prev;
int rindex = mCount - index -1;
for (int j=0; j<rindex; j++)
rnode = rnode.prev; return rnode;
} // 获取第index位置的节点的值
public T get(int index) {
return getNode(index).value;
} // 获取第1个节点的值
public T getFirst() {
return getNode(0).value;
} // 获取最后一个节点的值
public T getLast() {
return getNode(mCount-1).value;
} // 将节点插入到第index位置之前
public void insert(int index, T t) {
if (index==0) {
DNode<T> node = new DNode<T>(t, mHead, mHead.next);
mHead.next.prev = node;
mHead.next = node;
mCount++;
return ;
} DNode<T> inode = getNode(index);
DNode<T> tnode = new DNode<T>(t, inode.prev, inode);
inode.prev.next = tnode;
inode.next = tnode;
mCount++;
return ;
} // 将节点插入第一个节点处。
public void insertFirst(T t) {
insert(0, t);
} // 将节点追加到链表的末尾
public void appendLast(T t) {
DNode<T> node = new DNode<T>(t, mHead.prev, mHead);
mHead.prev.next = node;
mHead.prev = node;
mCount++;
} // 删除index位置的节点
public void del(int index) {
DNode<T> inode = getNode(index);
inode.prev.next = inode.next;
inode.next.prev = inode.prev;
inode = null;
mCount--;
} // 删除第一个节点
public void deleteFirst() {
del(0);
} // 删除最后一个节点
public void deleteLast() {
del(mCount-1);
}
}
ArrayList、Vector、LinkedList 区别与联系:
看图:
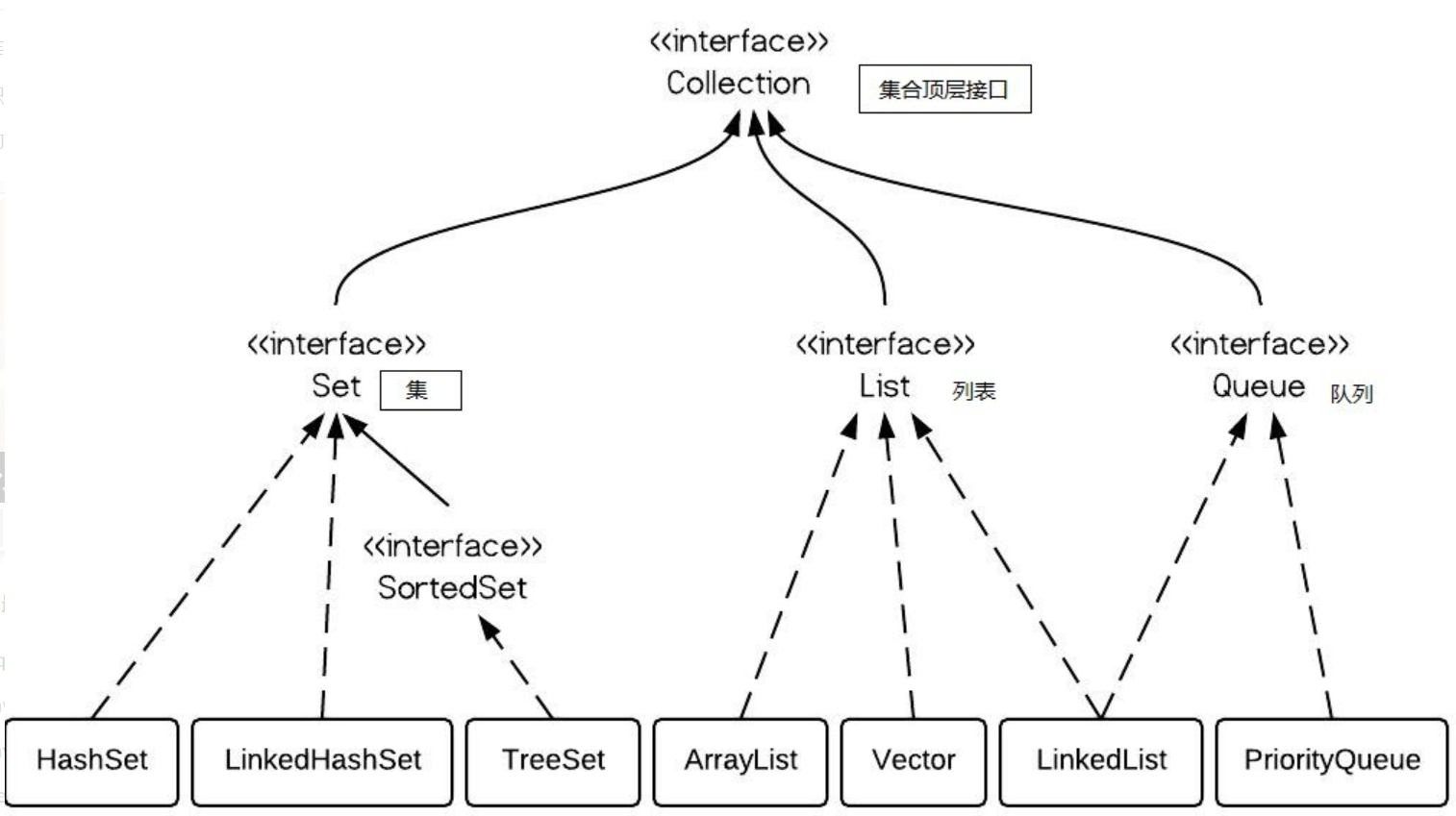
如上图所示:
ArrayList是实现了基于动态数组的数据结构,LinkedList基于双线链表的数据结构。
ArrayList可以随机定位对于新增和删除操作add和remove,LinedList比较占优势
具有Collection接口必备的iterator()方法外,List还提供一个listIterator()方法ListIterator多了一些add()之类的方法,允许添加,删除,设定元素,还能向前或向后遍历。
Vector与ArrayList唯一的区别是,Vector是线程安全的,即它的大部分方法都包含有关键字synchronized,因此,若对于单一线程的应用来说,最好使用ArrayList代替Vector,因为这样效率会快很多(类似的情况有StringBuffer线程安全的与StringBuilder线程不安全的);而在多线程程序中,为了保证数据的同步和一致性,可以使用Vector代替ArrayList实现同样的功能。
主要区别:
1、ArrayList、Vector、LinkedList类都是java.util包中,均为可伸缩数组。
2、ArrayList和Vector底层都是数组实现的,所以,索引/查询数据快,删除、插入数据慢。
ArrayList采用异步的方式,性能好,属于非线程安全的操作类。(JDK1.2)
Vector采用同步的方式,性能较低,属于线程安全的操作类。(JDK1.0)
3、LinkedList底层是链表实现,所以,索引慢,删除、插入快,属于非线程安全的操作类。
java定义数组需要声明长度,然后arraylist基于数组,等同于一个动态数组的实现,但是查询比较慢,所以可以自己编写一个动态数组来实现,代码如下:
package com.newer.tw.com; /**
* 自定义长度可变数组
*
* @author Administrator
*
*/
public class MyList {
// 定义一个初始长度为0的数组,用来缓存数据
private String[] src = new String[0];
// 增加
public void add(String s) {
//定义新数组,长度是原数组长度+1
String[] dest = new String[src.length+1];
//将原数组的数据拷贝到新数组
System.arraycopy(src, 0, dest, 0, src.length);
//将新元素放到dest数组的末尾
dest[src.length]=s;
//将src指向dest
src=dest;
}
// 修改指定位置的元素
public void modify(int index, String s) {
src[index]=s;
}
// 删除指定位置的元素
public void delete(int index) {
String[] dest = new String[src.length-1];
//将原数组的数据拷贝到新数组
System.arraycopy(src, 0, dest, 0, index);
System.arraycopy(src, index+1, dest, index, src.length-1-index);
src=dest;
}
// 获得指定位置的元素
public String get(int index) {
return src[index];
}
// 在指定位置插入指定元素
public void insert(int index, String s) {
//定义新数组,长度是原数组长度+1
String[] dest = new String[src.length+1];
//将原数组的数据拷贝到新数组
System.arraycopy(src, 0, dest, 0, index);
dest[index]=s;
System.arraycopy(src, index, dest, index+1, src.length-index);
src=dest; }
// 获得元素个数
public int size() {
return src.length;
} public void print()
{
for(int i=0;i<size();i++)
System.out.println(src[i]);
} public static void main(String[] args)
{
MyList m=new MyList();
m.add("15");
m.add("16");
m.add("17");
m.add("18");
m.add("19");
System.out.println("插入之前:");
m.print();
m.insert(2,"22");
System.out.println("插入之后:");
m.print();
} }
Hashmap 原理
参考: https://blog.csdn.net/qa962839575/article/details/44889553
在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,hashmap也不例外。Hashmap实际上是一个数组和链表的结合体(在数据结构中,一般称之为“链表散列“),请看下图
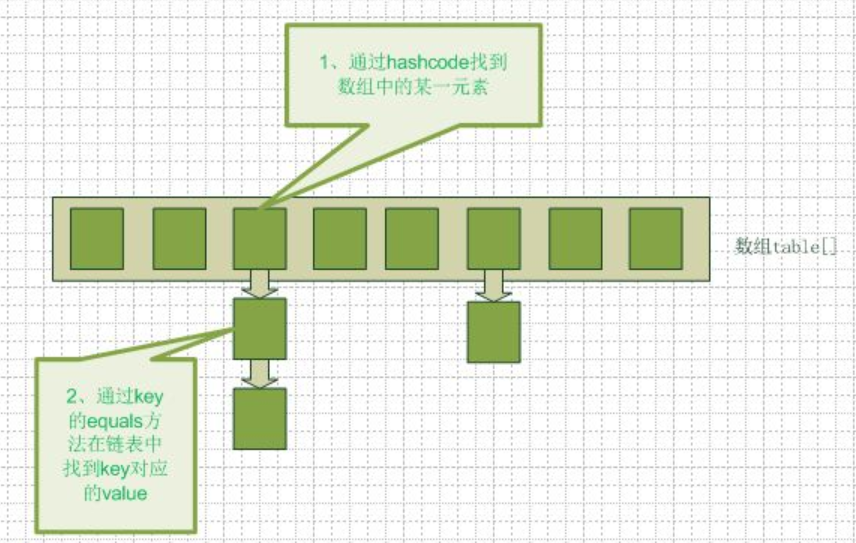
从图中我们可以看到一个hashmap就是一个数组结构,当新建一个hashmap的时候,就会初始化一个数组。
/**
* The table, resized as necessary. Length MUST Always be a power of two.
* FIXME 这里需要注意这句话,至于原因后面会讲到
*/
transient Entry[] table;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
final int hash;
Entry<K,V> next;
..........
}
Entry就是数组中的元素,它持有一个指向下一个元素的引用,这就构成了链表。
当我们往hashmap中put元素的时候,先根据key的hash值得到这个元素在数组中的位置(即下标),然后就可以把这个元素放到对应的位置中了。如果这个元素所在的位子上已经存放有其他元素了,那么在同一个位子上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。从hashmap中get元素时,首先计算key的hashcode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。从这里我们可以想象得到,如果每个位置上的链表只有一个元素,那么hashmap的get效率将是最高的,
static int indexFor(int h, int length) {
return h & (length-1);
}
首先算得key得hashcode值,然后跟数组的长度-1做一次“与”运算(&)。看上去很简单,其实比较有玄机。比如数组的长度是2的4次方,那么hashcode就会和2的4次方-1做“与”运算。很多人都有这个疑问,为什么hashmap的数组初始化大小都是2的次方大小时,hashmap的效率最高
当数组长度为2的n次幂的时候,不同的key算得得index相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,相对的,查询的时候就不用遍历某个位置上的链表,这样查询效率也就较高了。
说到这里,我们再回头看一下hashmap中默认的数组大小是多少,查看源代码可以得知是16,为什么是16,而不是15,也不是20呢,看到上面annegu的解释之后我们就清楚了吧,显然是因为16是2的整数次幂的原因,在小数据量的情况下16比15和20更能减少key之间的碰撞,而加快查询的效率。
初始容量为16,初始负载因子loadFactor为0.75 ,当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍;所以它带有动态的意义
初始容量与负载因子
参考: https://www.cnblogs.com/haifeng1990/p/6262417.html
HashMap有两个参数影响性能,初始容量和负载因子
JAVA 基本数据结构--数组、链表、ArrayList、Linkedlist、hashmap、hashtab等的更多相关文章
- java实现 数据结构:链表、 栈、 队列、优先级队列、哈希表
java实现 数据结构:链表. 栈. 队列.优先级队列.哈希表 数据结构javavector工作importlist 最近在准备找工作的事情,就复习了一下java.翻了一下书和网上的教材,发现虽然 ...
- Java描述数据结构之链表的增删改查
链表是一种常见的基础数据结构,它是一种线性表,但在内存中它并不是顺序存储的,它是以链式进行存储的,每一个节点里存放的是下一个节点的"指针".在Java中的数据分为引用数据类型和基础 ...
- (转载)Java里新建数组及ArrayList java不允许泛型数组
java中新建数组: String[] s;//定义的时候不需要设置大小 s = new String[5];//为数组分配空间时就要设置大小 对于ArrayList, ArrayList< ...
- java数据结构之列表——ArrayList,LinkedList,比较
刚看完<数据结构与算法分析java语言描述>的第3章中的表,下面回忆下主要知识点,主要说明各列表之间的关系,以及各自的优缺点.其中牵涉到内部类和嵌套类. 1 Collection APIp ...
- arrayList LinkedList HashMap HashTable的区别
ArrayList 采用的是数组形式来保存对象的,这种方式将对象放在连续的位置中,所以最大的缺点就是插入删除时非常麻烦 LinkedList 采用的将对象存放在独立的空间中,而且在每个空间中还保存下一 ...
- Java总结 - List实现类ArrayList&LinkedList
本文是根据源码进行学习的,如果我有什么理解不对的地方请多指正,谢谢您 上面基本就是List集合类的类图关系了,图中省略掉了比如Cloneable等标记接口,那么List分别具体的主要实现类有:Arra ...
- Java 集合的简单实现 (ArrayList & LinkedList & Queue & Stack)
ArrayList 就是数组实现的啦,没什么好说的,如果数组不够了就扩容到原来的1.5倍 实现了迭代器 package com.wenr.collection; import java.io.Seri ...
- JDK1.7源码阅读tools包之------ArrayList,LinkedList,HashMap,TreeMap
1.HashMap 特点:基于哈希表的 Map 接口的实现.此实现提供所有可选的映射操作,并允许使用 null 值和 null 键.(除了非同步和允许使用 null 之外,HashMap 类与 Has ...
- java之数据结构之链表及包装类、包
链表是java中的一种常见的基础数据结构,是一种线性表,但是不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针.与线性对应的一种算法是递归算法:递归算法是一种直接或间接的调用自身算法的过 ...
随机推荐
- 异常+远程控制Linux-14
什么是异常 a=8950/0 ZeroDivisioonError: division by zero print (a) ************** b = [1,2] ...
- 机器学习进阶-图像形态学操作-梯度运算 cv2.GRADIENT(梯度运算-膨胀图像-腐蚀后的图像)
1.op = cv2.GRADIENT 用于梯度运算-膨胀图像-腐蚀后的图像 梯度运算:表示的是将膨胀以后的图像 - 腐蚀后的图像,获得了最终的边缘轮廓 代码: 第一步:读取pie图片 第二步:进行腐 ...
- Java——如何创建文件夹及文件,删除文件,文件夹
package com.zz; import java.io.File; import java.io.IOException; /** * Java创建文件夹 */ public class Cre ...
- OC代码编译成c++代码 编译器命令
xcrun -sdk iphoneos clang -arch x86_64 -rewrite-objc Person+Test.m clang -rewrite-objc -fobjc-arc -s ...
- vue:绑定数据的vue页面加载会闪烁问题
1:在挂在数据的容器加上属性 v-cloak 2:在css中添加如下代码 但有时候还是会不起作用,可能原因有两个 2.1:display属性被更高权限的display属性覆盖了,我们增加权限就好了 2 ...
- 尚硅谷redis学习9-发布订阅
是什么? 图示说明 命令 例子
- Win7下npm命令Error: ENOENT问题解决
Win7下在执行npm命令,比如npm list时出现下面错误:
- Linux下查看与修改mtu值
MTU:通信术语 最大传输单元(Maximum Transmission Unit)是指一种通信协议的某一层上面所能通过的最大数据包大小(以字节为单位). 我们在使用互联网时进行的各种网络操作,都是通 ...
- img标签插入图片返回403,浏览器可以直接打开
参考:https://segmentfault.com/q/1010000011752614/a-1020000011764026 博客园引入外部图片出现,出现403问题,应该是加了防盗链,会检测访问 ...
- Structs复习 OGNL
Dominmodel只有传 User.age 类似的这种Structs才能帮创建对象 Dominmodel User里必须有空的构造方法 OGNL:OBJECT GRAPHIC NAVAGATION ...