python——线程相关
使用python的threading中的Thread
下面是两种基本的实现线程的方式:
第一种方式————
#coding=utf-8 """
thread的第一种声明及调用方式
""" from threading import Thread
import time def func():
while True:
print time.ctime()
time.sleep(1) def func1():
while True:
print "func1", time.ctime()
time.sleep(2) #将要执行的方法作为参数传给Thread的构造方法 t = Thread(target=func)
t.start() t1 = Thread(target=func1)
t1.start()
第二种方式————
#coding=utf-8 """
thread的第二种声明及调用方法
""" import time
from threading import Thread
from time import sleep #从Thread继承,并重写run()
class myThread(Thread):
def __init__(self, threadname):
Thread.__init__(self, name=threadname) def run(self):
while True:
print self.getName() + " " + time.ctime()
time.sleep(1) t = myThread("thread_1")
t.start() t1 = myThread("thread_2")
t1.start()
接下来是:join和setDaemon的方法调用及具体区别:
join的方法调用:
#coding=utf-8 """
join方法的含义是:存在A主线程,B子线程,在A主线程中生成了一个子线程B,
如果子线程B调用了join方法,则主线程需要等待子线程操作结束,才能够继续往下执行,主线程会被阻塞
"""
import time
from threading import Thread class myThread(Thread):
def __init__(self, threadname):
Thread.__init__(self, name = threadname) def run(self):
time.sleep(10)
print self.getName() + " " + time.ctime() def mainfunc():
for i in range(5):
print i if __name__ == "__main__":
t = myThread("childthread")
t.start()
#增加join方法的调用,则程序运行时的表现是:先子线程(会先sleep 10s,之后打印子线程的内容),再运行主线程中的打印从0到4的逻辑
#不增加join方法的调用,则程序运行时的表现是:会先走主线程的打印从0到4的逻辑,之后子线程(sleep 10s,再打印子线程中的内容),但其实这里就是没有等待子线程
# t.join()
mainfunc()
setDaemon方法的调用:
#coding=utf-8 """
daemon方法的含义是:存在主线程A,和子线程B,子线程B是从主线程A中生成的
如果设置子线程B为daemon即守护进程,则主线程A不存在的话,子线程B就退出
如果没有设置子线程B为daemon,则主线程A结束运行退出之后,子线程B也不退出
""" import time
from threading import Thread class myThread(Thread):
def __init__(self, threadname):
Thread.__init__(self, name=threadname) def run(self):
time.sleep(10)
print self.getName() + " " + time.ctime() def mainfunc():
for i in range(5):
print i if __name__ == "__main__":
t = myThread("zixiancheng")
#不设置子线程为守护进程,则主线程退出,子线程继续运行
#设置子线程为守护进程,则主线程退出,子线程直接退出
#并且,需要在start之前调用setDaemon
# t.setDaemon(True)
t.start()
mainfunc()
接下来是线程同步相关的内容:
首先是没有线程同步机制的情况下,多个线程同时操作一个公共数据:
代码如下:
#coding=utf-8 """
@function: test Thread的Lock
@author: LiXia
@date: 2017-0303
""" """
所有的锁都是为了在线程之间进行通信
例如对一个公共变量进行操作,此例子为没有使用线程同步机制对公共变量进行操作
""" from threading import Thread
import time data = 0 class myThread(Thread):
def __init__(self):
Thread.__init__(self) def run(self):
global data
time.sleep(1)
data += 1
print self.getName() + " data: " + str(data) if __name__ == "__main__":
for i in range(5):
t = myThread()
t.start()
运行结果见下方:

为了能够对公共操作的数据,在特定逻辑内保持一致,需要保证在该逻辑内,只有单个线程可以操作,其他线程需要等待该线程处理结束才可以。
所以下面是关于python线程同步机制提供的指令:
1、Lock:
但是将以上代码中增加上lock处理,注意一定要增加在对公共数据的逻辑判断和处理的前面和后面,所以这里必须添加到while判断之前,释放锁需要在输出操作结束之后添加
即:
#coding=utf-8 """
所有的锁都是为了在线程之间进行通信
例如对一个公共变量进行操作
""" from threading import Thread
import threading
import time data = 0
lock = threading.Lock() class myThread(Thread):
def __init__(self):
Thread.__init__(self) def run(self):
global data
if lock.acquire():
time.sleep(1)
data += 1
print self.getName() + " data: " + str(data)
lock.release() if __name__ == "__main__":
for i in range(5):
t = myThread()
t.start()
运行结果见下方:

2、RLock
代码如下:
#coding=utf-8 """
通过RLock(可重入锁)进行线程间的安全通信,RLock为可重入锁,即线程在拥有RLock之后可以继续acquire(),只要保证acquire()次数与
release()次数一致即可;
继续对公共变量进行操作
""" from threading import Thread
import threading
import time rlock = threading.RLock()
data = 0 class myThread(Thread):
def __init__(self):
Thread.__init__(self) def run(self):
global data
if rlock.acquire():
time.sleep(1)
data += 1
print self.getName() + " data:" + str(data) if rlock.acquire():
time.sleep(1)
data -= 1
print self.getName() + " data:" + str(data)
rlock.release()
rlock.release() if __name__ == "__main__":
for i in range(5):
t = myThread()
t.start()
运行结果:
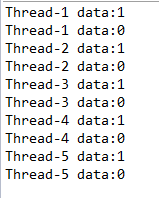
3、Condition
Condition就是条件变量,condition通常与一个锁关联。
acquire([timeout])/release(): 调用关联的锁的相应方法。
wait([timeout]): 调用这个方法将使线程进入Condition的等待池等待通知,并释放锁。使用前线程必须已获得锁定,否则将抛出异常。
notify(): 调用这个方法将从等待池挑选一个线程并通知,收到通知的线程将自动调用acquire()尝试获得锁定(进入锁定池);其他线程仍然在等待池中。调用这个方法不会释放锁定。使用前线程必须已获得锁定,否则将抛出异常。
notifyAll(): 调用这个方法将通知等待池中所有的线程,这些线程都将进入锁定池尝试获得锁定。调用这个方法不会释放锁定。使用前线程必须已获得锁定,否则将抛出异常。
#coding=utf-8 """
以最经典的生产者和消费者的问题为例,两者需要针对一个公共的数据区域做操作,并且两端需要进行通信
生产者在生产之前,需要先占领地盘,然后开始生产,生产结束通知消费者来取;
消费者在消费的时候,也需要先占领地盘,然后开始消费,消费结束通知生产者继续生产;
当然还有多个生产者和消费者的情况,会更加复杂,可以用python的Queue来实现
""" from threading import Thread
import threading
import time
import random product = []
con = threading.Condition() #得到一个Condition的对象 #生产者线程
class producerThread(Thread):
def __init__(self, threadname):
Thread.__init__(self, name=threadname) def run(self):
global product
if con.acquire():
while True:
r = random.randint(0, 20)
product.append(r)
print "product len and product: ", self.getName(), product
con.notify()
con.wait()
# time.sleep(2) #消费者线程
class consumerThread(Thread):
def __init__(self, threadname):
Thread.__init__(self, name=threadname) def run(self):
global product
if con.acquire():
while True:
if product != []:
product.pop()
print "consumer len and product: ", self.getName(), product
con.notify()
con.wait()
time.sleep(2) if __name__ == "__main__":
t1 = producerThread("producer")
t2 = consumerThread("consumer") t1.start()
t2.start()
运行结果如下:

4、对多个生产者消费者支持的很好的Queue
Queue是什么?Queue实现了多生产者-多消费者的队列形式,分别包含先入先出(默认)FIFO、后进先出LIFO、以及优先级队列PriorityQueue(优先级低的先出)
Queue模块的class及exception:
#coding=utf-8 """
Queue的类和异常
""" import Queue q = Queue.Queue(maxsize = 0) #FIFO的Queue,maxsize即Queue的size值,maxsize≤0表示无size限制 lq = Queue.LifoQueue(maxsize = 0) #LIFO的Queue,先进后出,maxsiz的含义同上 pq = Queue.PriorityQueue(maxsize = 0) #优先级Queue,优先级低的先出,maxsize的含义同上 Queue.Empty() #当Queue的对象为空时,使用非阻塞get时会抛出异常 Queue.Full() #当Queue的对象已满时,使用非阻塞put时会抛出异常
Queue的对象:
Queue(Queue、LifoQueue、PriorityQueue)的对象提供的公共方法如下:
#coding=utf-8 """
Queue(Queue、LifoQueue、PriorityQueue)的对象的公共方法
""" import Queue q = Queue.Queue() q.qsize() #获取Queue的大小
q.empty() #是否为空,是则返回True,否则返回False
q.full() #是否已满,是则返回True,否则返回False
q.put(item[, block[, timeout]]) #put元素到Queue中,可选参数block默认值为True,timeout默认值为None,即为阻塞方法,
#接上,若timeout为正值,则代表会阻塞timeout的时长之后引发一个full的异常(如果已满)
q.put_nowait(item) #相当于q.put(item, False)
q.get([block[, timeout]]) #get元素到Queue中,可选参数block默认值为True,timeout默认值为None,即为阻塞方法,
#接上,若timeout为正数,则代表会则色timeouu的时长之后会引发一个empty的异常(如果为空)
q.get_nowait() #相当于q.get(False)
q.task_done() #用在Queue的消费者模式下,即用在Queue.get()方法之后,通过Queue.task_done()告诉Queue当前任务完成
#如果当前join正在阻塞,则它将在所有item都被处理之后恢复
q.join() #会保持阻塞直到队列中的所有item都会处理
#接上,未完成的task数目会增加当一个item被add到Queue中,未完成的task数目会降低,每当消费者线程调用task_done来表示所有的
#接上,work都完成了,当未完成的数目降低到0时,join就自动取消阻塞了
Queue的主要用法是什么?
看一下Queue的源码实现,然后在另一篇博客中更新一下。
#coding=utf-8 """
理解Queue的用法,理解Queue衍生出来的不同的class
""" from Queue import Queue
from threading import Thread
import time
import random q = Queue() class producerQueue(Thread):
def __init__(self, queue):
Thread.__init__(self)
self.queue = queue def run(self):
while True:
r = random.randint(0, 99)
self.queue.put(r)
print self.getName() + "produce " + str(r)
time.sleep(1) class consumerQueue(Thread):
def __init__(self, queue):
Thread.__init__(self)
self.queue = queue def run(self):
while True:
r = self.queue.get()
print self.getName() + "consume " + str(r)
time.sleep(3)
self.queue.task_done() if __name__ == "__main__":
threads = []
for i in range(5):
t = producerQueue(q)
t.start()
# threads.append(t) for i in range(3):
t = consumerQueue(q)
t.start()
# threads.append(t) q.join()
之后得到的结果如下:

python——线程相关的更多相关文章
- python线程池ThreadPoolExecutor(上)(38)
在前面的文章中我们已经介绍了很多关于python线程相关的知识点,比如 线程互斥锁Lock / 线程事件Event / 线程条件变量Condition 等等,而今天给大家讲解的是 线程池ThreadP ...
- Python之路(第四十二篇)线程相关的其他方法、join()、Thread类的start()和run()方法的区别、守护线程
一.线程相关的其他方法 Thread实例对象的方法 # isAlive(): 返回线程是否活动的. # getName(): 返回线程名. # setName(): 设置线程名. threadin ...
- python——线程与多线程进阶
之前我们已经学会如何在代码块中创建新的线程去执行我们要同步执行的多个任务,但是线程的世界远不止如此.接下来,我们要介绍的是整个threading模块.threading基于Java的线程模型设计.锁( ...
- Python 线程、进程和协程
python提供了两个模块来实现多线程thread 和threading ,thread 有一些缺点,在threading 得到了弥补,为了不浪费时间,所以我们直接学习threading 就可以了. ...
- [python] 线程简介
参考:http://www.cnblogs.com/aylin/p/5601969.html 我是搬运工,特别感谢张岩林老师! python 线程与进程简介 进程与线程的历史 我们都知道计算机是由硬件 ...
- Python线程指南
本文介绍了Python对于线程的支持,包括“学会”多线程编程需要掌握的基础以及Python两个线程标准库的完整介绍及使用示例. 注意:本文基于Python2.4完成,:如果看到不明白的词汇请记得百度谷 ...
- 进程 & 线程相关知识
不管Java,C++都有进程.线程相关的内容.在这里统一整理吧. Python的线程,其实是伪线程,不能真正的并发.下面也有讲. 线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序 ...
- Python线程
原文出处: AstralWind 1. 线程基础 1.1. 线程状态 线程有5种状态,状态转换的过程如下图所示: 1.2. 线程同步(锁) 多线程的优势在于可以同时运行多个任务(至少感觉起来是这样). ...
- Python 线程,进程
Threading用于提供线程相关的操作,线程是应用程序中工作的最小单元 线程不能实现多并发 只能实现伪并发 每次工作 只能是一个线程完成 由于python解释器 原生是c 原生线程 底层都会有一把 ...
随机推荐
- math模块
序号 方法 功能 示例 1 matd.ceil 取大于等于x的最小的整数值,如果x是一个整数,则返回x print(matd.ceil(10.1))# 11print(matd.ceil(-3.1)) ...
- 1047A_Little C Loves 3 I(构造)
A. Little C Loves 3 I time limit per test 1 second memory limit per test 256 megabytes input standar ...
- ReactiveX 学习笔记(8)错误处理和 To 操作符
Error Handling Operators Operators to Convert Observables 本文的主题为对 Observable 进行错误处理的操作符以及转换 Observab ...
- ReactiveX 学习笔记(5)合并数据流
Combining Observables 本文的主题为合并 Observable 的操作符. 这里的 Observable 实质上是可观察的数据流. RxJava操作符(四)Combining An ...
- 【374】Adobe Acrobat 操作技巧
1. 文件内容增减 参考:如何在PDF文件中删除页面 参考:如何旋转.移动.删除和重新编号 PDF 页面 双击PDF文档,并在预览程序中打开它. 如果在其他程序(如Adobe Reader)中打开文档 ...
- JavaScript 从定义到执行,你应该知道的那些事
JavaScript从定义到执行,JS引擎在实现层做了很多初始化工作,因此在学习JS引擎工作机制之前,我们需要引入几个相关的概念:执行环境栈.执行环境.全局对象.变量对象.活动对象.作用域和作用域链等 ...
- 何谓domReady
我的博客已经写过好几篇如何实现domReady的文章,最近做培训,面向新手们,需要彻彻底底向他们说明这个东西,于是就有了这篇文章. 我们经常看人们用 document.getElementById(& ...
- Zookeeper与HBse安装过程纪录
1 zookeeper安装 1.1 环境变量 1.2 配置zoo.cfg 初次使用 ZooKeeper 时, 需要将 $ZOOKEEPER_HOME/conf 目录下的 zoo_sample.cfg ...
- SQL Server--存在则更新问题
在博客园看到一篇讨论特别多的文章“探讨SQL Server并发处理存在就更新七种解决方案”,这种业务需求很常见:如果记录存在就更新,不存在就插入. 最常见的做法: BEGIN TRANSACTION ...
- 设置DNS 代理
最近烦心事好多啊,坑爹的中介... 公司之前因为断电,导致DNS基础服务故障,很多系统好半天在能使用,所以这次吸取教训,设置备份的DNS server以及使得DNS能够动态迁移,在这种时候就显得格外的 ...