Python之路(第十六篇)xml模块、datetime模块
一、xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,
xml比较早,早期许多软件都是用xml,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
什么是XML?
XML是可扩展标记语言(Extensible Markup Language)的缩写,其中的 标记(markup)是关键部分。您可以创建内容,然后使用限定标记标记它,从而使每个单词、短语或块成为可识别、可分类的信息。XML不是为了方便阅读而设计,而是为了编码为数据。
标记语言从早期的私有公司和政府制定形式逐渐演变成标准通用标记语言(Standard Generalized Markup Language,SGML)、超文本标记语言(Hypertext Markup Language,HTML),并且最终演变成 XML。XML有以下几个特点。
XML的设计宗旨是传输数据,而非显示数据。
XML标签没有被预定义。您需要自行定义标签。
XML被设计为具有自我描述性。
XML是W3C的推荐标准。
xml常见用途
(1) 数据传送通用格式
(2)配置文件
(3) 充当小型数据库
目前,XML在Web中起到的作用不会亚于一直作为Web基石的HTML。 XML无所不在。XML是各种应用程序之间进行数据传输的最常用的工具,并且在信息存储和描述领域变得越来越流行。
因此,学会如何解析XML文件,对于Web开发来说是十分重要的。
有哪些可以解析XML的Python包?
Python的标准库中,提供了6种可以用于处理XML的包。
xml.dom 、xml.dom.minidom、xml.dom.pulldom、xml.sax、xml.parser.expat、xml.etree.ElementTree(以下简称ET)
利用ElementTree解析XML
Python标准库中,提供了ET的两种实现。一个是纯Python实现的xml.etree.ElementTree,另一个是速度更快的C语言实现xml.etree.cElementTree。请记住始终使用C语言实现,因为它的速度要快很多,而且内存消耗也要少很多。如果你所使用的Python版本中没有cElementTree所需的加速模块,你可以这样导入模块:
try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET
如果某个API存在不同的实现,上面是常见的导入方式。当然,很可能你直接导入第一个模块时,并不会出现问题。请注意,自Python 3.3之后,就不用采用上面的导入方法,因为ElemenTree模块会自动优先使用C加速器,如果不存在C实现,则会使用Python实现。
因此,使用Python 3.3+的朋友,只需要import xml.etree.ElementTree即可。
将XML文档解析为树(tree)
XML是一种结构化、层级化的数据格式,最适合体现XML的数据结构就是树。ET提供了两个对象:ElementTree将整个XML文档转化为树,Element则代表着树上的单个节点。对整个XML文档的交互(读取,写入,查找需要的元素),一般是在ElementTree层面进行的。对单个XML元素及其子元素,则是在Element层面进行的。
ElementTree表示整个XML节点树,而Element表示节点数中的一个单独的节点。
ET 模块可以归纳为三个部分:ElementTree类,Element类以及一些操作 XML 的函数。
在面向对象的编程语言中,我们需要定义几个类来表示这个树形结构的组成部分。分析这个树形结构我们发现其实每个节点(指的是上图中的每个圆形,对应XML中的每个标签对)都可以抽象为一个共同的类,比如叫Leaf(叶子)、Node(节点)、Element都可以。但是,除了表示节点的类,我们还需要定义一个类来表示这个树本身。ET(xml.etree.ElementTree)中就设计了以下几个类:
ElementTree: 表示整个XML层级结构
Element: 表示树形结构中所有的父节点
SubElement: 表示树形结构中所有的子节点
有些节点既是父节点,又是子节点
Xml语法
入门案例: 用xml来记录一个班级信息
<?xml version="1.0" encoding="utf-8"?>
<xml-body>
<class>
<stu id="001">
<name>杨过</name>
<sex>男</sex>
<age>30</age>
</stu>
<stu id="002">
<name>李莫愁</name>
<sex>女</sex>
<age>20</age>
</stu>
</class>
</xml-body>
用encoding属性说明文档的字符编码:<?xml version="1.0" encoding="GB2312" ?>
当XML文件中有中文时,必须使用encoding属性指明文档的字符编码,例如:encoding="GB2312"或者encoding="utf-8",并且在保存文件时,也要以相应的文件编码来保存,否则在使用浏览器解析XML文件时,就会出现解析错误的情况。
(1) 文档声明
<?xml version=”1.0” encoding=”编码方式” standalone=”yes|no”?>
XML声明放在XML文档的第一行
XML声明由以下几个部分组成:
version - -文档符合XML1.0规范,我们学习1.0
encoding - -文档字符编码,比如”gb2312”
standalone - -文档定义是否独立使用
standalone="yes“
standalone=“no” 默认
(2) 一个xml 文档中,有且只有一个根元素(元素标签节点)
(3) 对于XML标签中出现的所有空格和换行,XML解析程序都会当作标签内容进行处理。例如:下面两段内容的意义是不一样的:
<name>xiaoming</name>
不等价与
<name>
xiaoming
</name>
由于在XML中,空格和换行都作为原始内容被处理,所以,在编写XML文件时,要特别注意。
(4) 属性值用双引号(")或单引号(')分隔(如果属性值中有',用"分隔;有",用'分隔),一个元素可以有多个属性,它的基本格式为:<元素名 属性名="属性值">
特定的属性名称在同一个元素标记中只能出现一次,属性值不能包括<, >, &
%E3%80%90day22%E3%80%91/XML%E5%B1%9E%E6%80%A7%E5%90%8D%E6%9C%89%E5%BC%95%E5%8F%B7.png?lastModify=1526954917)

<?xml version="1.0" encoding="utf-8"?>
<xml-body>
<class>
<stu id="a"0'0'1">
<name>杨过</name>
<sex>男</sex>
<age>30</age>
</stu>
<stu id="002">
<name>李莫愁</name>
<sex>女</sex>
<age>20</age>
</stu>
</class>
</xml-body>
实际效果

%E3%80%90day22%E3%80%91/XML%E5%B1%9E%E6%80%A7%E5%90%8D%E6%9C%89%E5%BC%95%E5%8F%B7%E5%AE%9E%E9%99%85%E6%95%88%E6%9E%9C.png?lastModify=1526954917)
一个XML元素可以包含字母、数字以及其它一些可见字符,但必须遵守下面的一些规范:
区分大小写,例如,<P>和<p>是两个不同的标记。
不能以数字或"_" (下划线)开头。
不能包含空格。
名称中间不能包含冒号(:)。
(5)xml语法——元素
XML元素指XML文件中出现的标签,一个标签分为开始标签和结束标签,一个标签有如下几种书写形式,例如:
- 包含标签体:<a>www.cnblogs.com/</a>
- 不含标签体的:<a></a>, 简写为:<a/>
一个标签中也可以嵌套若干子标签。但所有标签必须合理的嵌套,绝对不允许交叉嵌套 ,例如:
错误的写法:<a>welcome to <b>www.cnblogs.com/</a></b>
格式良好的XML文档必须有且仅有一个根标签,其它标签都是这个根标签的子孙标签。
(6)XML语法——属性
一个标签可以有多个属性,每个属性都有它自己的名称和取值,例如: <input name=“text”> ,属性值一定要用双引号(")或单引号(')引起来,定义属性必须遵循与标签相同的命名规范 。
多学一招:**在XML技术中,标签属性所代表的信息,也可以被改成用子元素的形式来描述**,例如:
<input>
<name>text</name>
</input>
例子
<?xml version="1.0"?>
<data>
<country name="Liechtenstein"> #country 元素名, name =""是元素的名称
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
在python中的操作
xml文件:文件名"testxml.xml",内容如下:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
python中的操作
import xml.etree.ElementTree as ET
tree = ET.parse("testxml.xml") #.parse解析,ET的解析方法
root = tree.getroot()
print(root.tag)
ElementTree.parse(source, parser=None),将xml文件加载并返回ElementTree对象。parser是一个可选的参数,如果为空,则默认使用标准的XMLParser解析器。
ElementTree.getroot(),得到根节点。返回根节点的element对象。根元素(root)是一个Element对象。
Element.remove(tag),删除root下名称为tag的子节点 以下函数,ElementTree和Element的对象都包含。
访问Element对象的标签、属性和值
tag = element.tag #标签
attrib = element.attrib #属性
value = element.text #值、内容
例子
import xml.etree.ElementTree as ET
tree = ET.parse("testxml.xml")
root = tree.getroot()
# 遍历根节点,获取根节点的子对象
for i in root:
print(i) #这里获取的是根节点的子对象
print(i.tag) #用tag方法获取节点的标签
输出结果
<Element 'country' at 0x027A4F90>
country
<Element 'country' at 0x027AC120>
country
<Element 'country' at 0x027AC240>
country
遍历根节点
例子
import xml.etree.ElementTree as ET
tree = ET.parse("testxml.xml")
root = tree.getroot()
# 遍历根节点,获取根节点的子对象
for i in root:
print(i.attrib) #获取子对象的属性
输出结果
{'name': 'Liechtenstein'}
{'name': 'Singapore'}
{'name': 'Panama'}
例子
import xml.etree.ElementTree as ET
tree = ET.parse("testxml.xml")
root = tree.getroot()
# 遍历根节点,获取根节点的子对象
for i in root:
for j in i:
print(j.attrib) #获取SubElement对象的属性
输出结果
{'updated': 'yes'}
{}
{}
{'name': 'Austria', 'direction': 'E'}
{'name': 'Switzerland', 'direction': 'W'}
{'updated': 'yes'}
{}
{}
{'name': 'Malaysia', 'direction': 'N'}
{'updated': 'yes'}
{}
{}
{'name': 'Costa Rica', 'direction': 'W'}
{'name': 'Colombia', 'direction': 'E'}
root.iter()迭代
例子
import xml.etree.ElementTree as ET
tree = ET.parse("testxml.xml")
root = tree.getroot()
# root.iter()迭代
# Element元素迭代子元素,Element.iter("tag"),即罗列该节点下所包含的所有子节点
#罗列出所有节点的下面包含year元素的内容
for i in root.iter("year"):
print(i.tag,i.text)
输出结果
year 2008
year 2011
year 2011
element.findall()、element.find()
import xml.etree.ElementTree as ET
tree = ET.parse("testxml.xml")
root = tree.getroot()
# Element.findall("tag"):查找当前元素为“tag”的直接子元素
#findall只能用来查找直接子元素,不能用来查找rank,neighbor等element
for country in root.findall('country'): #查询当前元素的子元素
rank = country.find('rank').text #查询指定标签的第一个子元素,element.text获取元素的内容
year = country.find('year').text
neig = country.find('neighbor').attrib
name = country.get("name") #element.get()获取元素的属性值
print(rank,year,neig,name)
输出结果
2 2008 {'name': 'Austria', 'direction': 'E'} Liechtenstein
5 2011 {'name': 'Malaysia', 'direction': 'N'} Singapore
69 2011 {'name': 'Costa Rica', 'direction': 'W'} Panama
修改xml文件:
element.set()修改属性,element.remove()删除元素
ElementTree.write("xmlfile"):更新xml文件
Element.append():为当前element对象添加子元素(element)
Element.set(key,value):为当前element的key属性设置value值
Element.remove(element):删除为element的节点
例子
xml文件:文件名"testxml.xml",内容如下:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
python操作
element.set()修改属性
import xml.etree.ElementTree as ET
tree = ET.parse("testxml.xml")
root = tree.getroot()
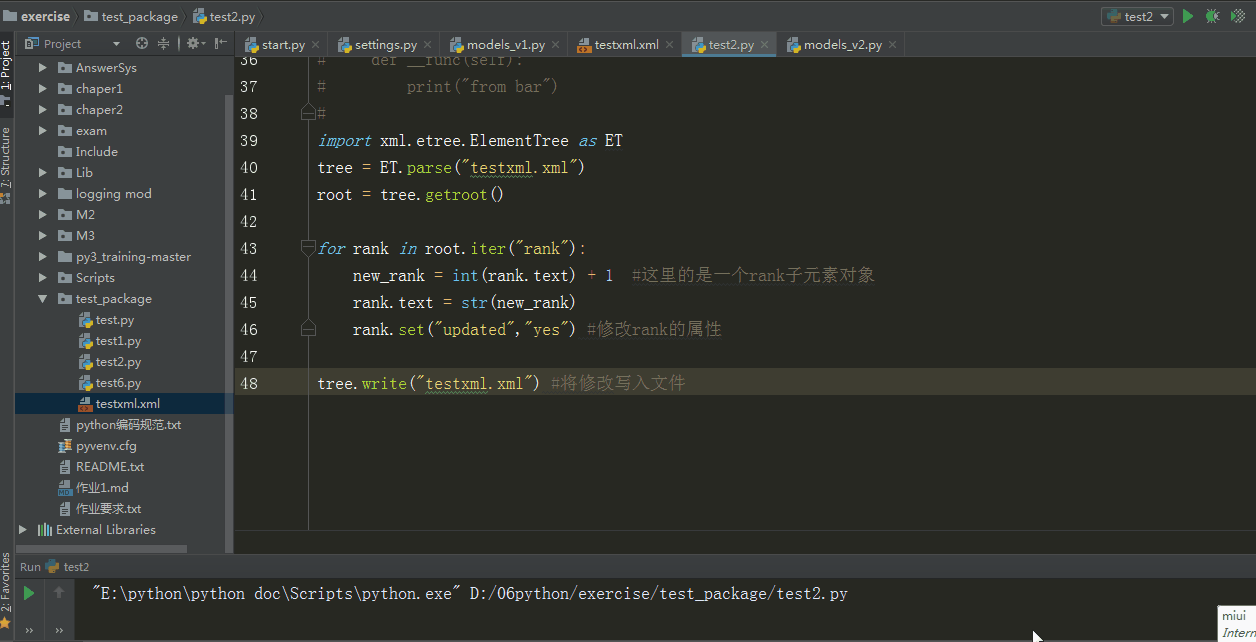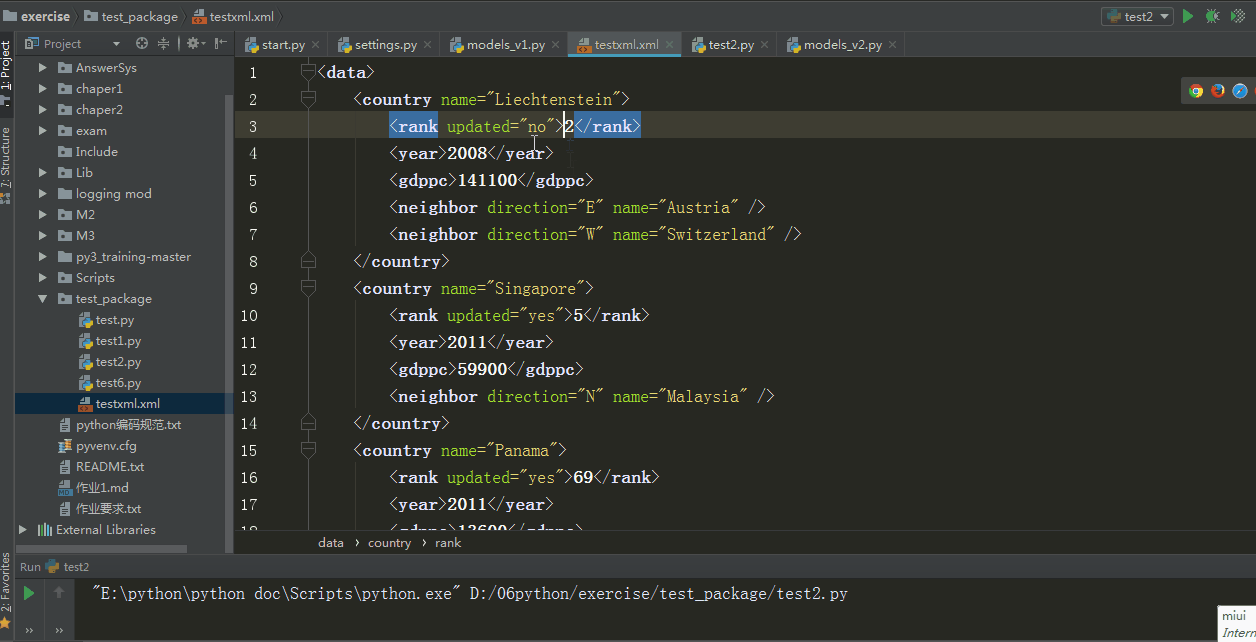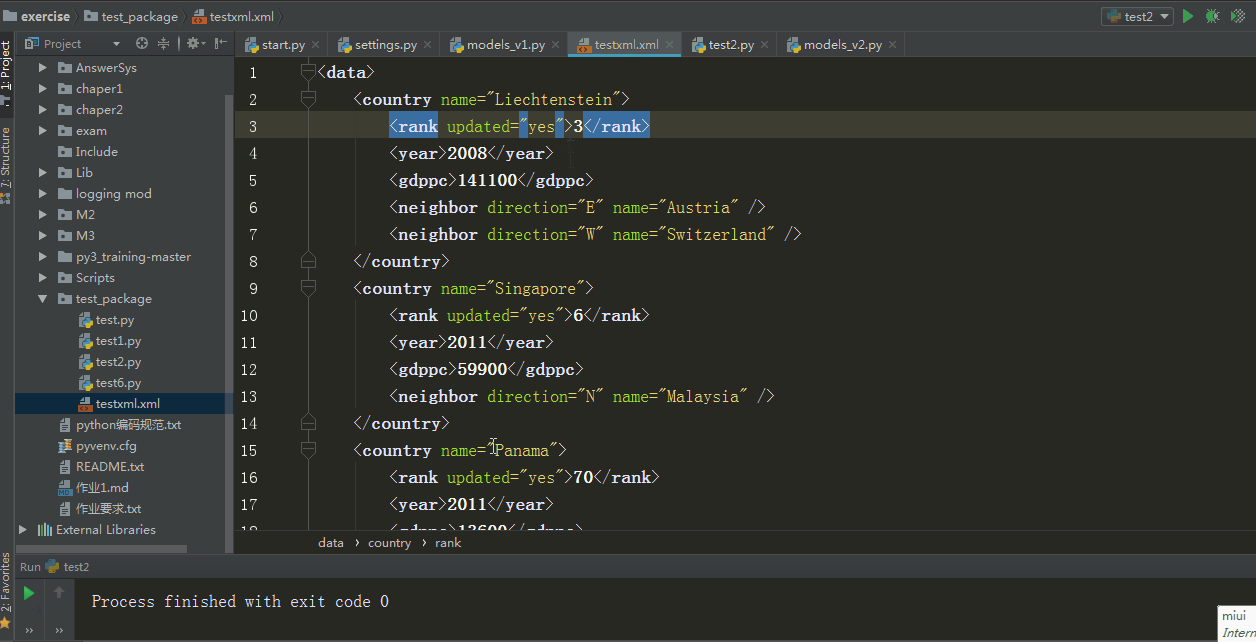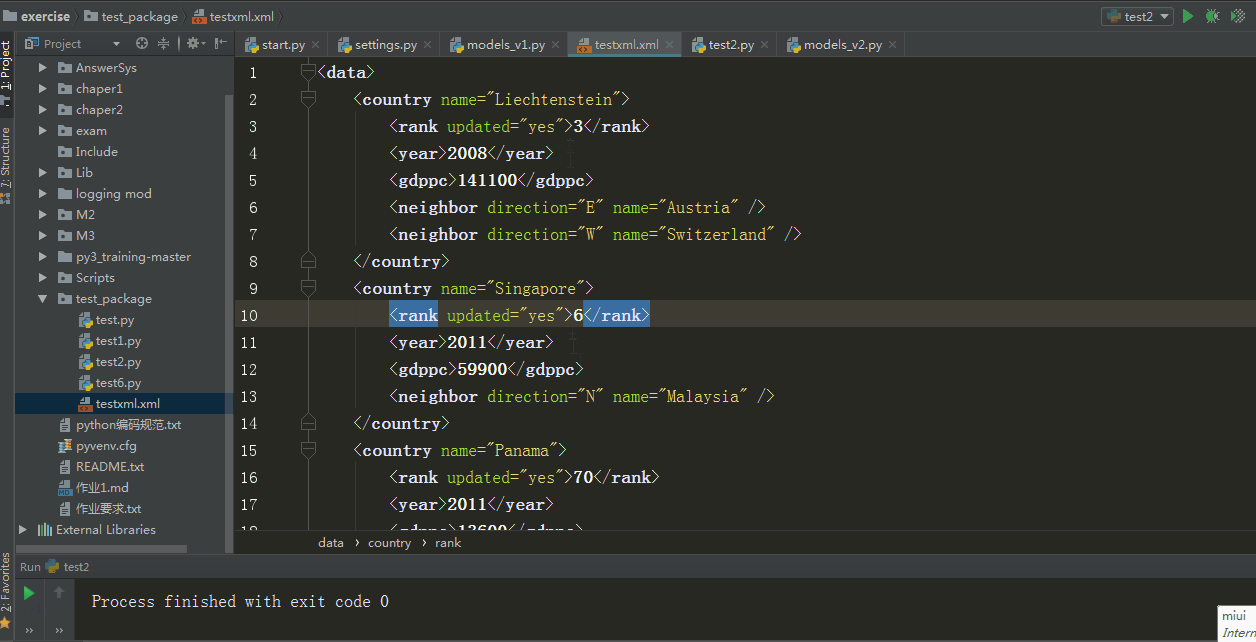
for rank in root.iter("rank"):
new_rank = int(rank.text) + 1 #这里的是一个rank子元素对象
rank.text = str(new_rank)
rank.set("updated","yes") #修改rank的属性
tree.write("testxml.xml") #将修改写入文件
输出结果
%E3%80%90day22%E3%80%91/element.set()%E4%BF%AE%E6%94%B9%E5%B1%9E%E6%80%A7.gif?lastModify=1526954917)
element.remove()删除元素
import xml.etree.ElementTree as ET
tree = ET.parse("testxml.xml")
root = tree.getroot()
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank>50:
root.remove(country)
tree.write('test.xml')
例子
test.xml 原文件内容
<root><sub1 name="name attribute" /><sub2>test</sub2></root>
python文件
import xml.etree.ElementTree as ET
#读取待修改文件
updateTree = ET.parse("test.xml")
root = updateTree.getroot()
#创建新节点并添加为root的子节点
newEle = ET.Element("NewElement")
newEle.attrib = {"name":"NewElement","age":"20"}
newEle.text = "This is a new element"
root.append(newEle)
#修改sub1的name属性
sub1 = root.find("sub1")
sub1.set("name","New Name")
#修改sub2的数据值
sub2 = root.find("sub2")
sub2.text = "New Value"
#写回原文件
updateTree.write("test.xml")
#打印生成的格式
ET.dump(updateTree)
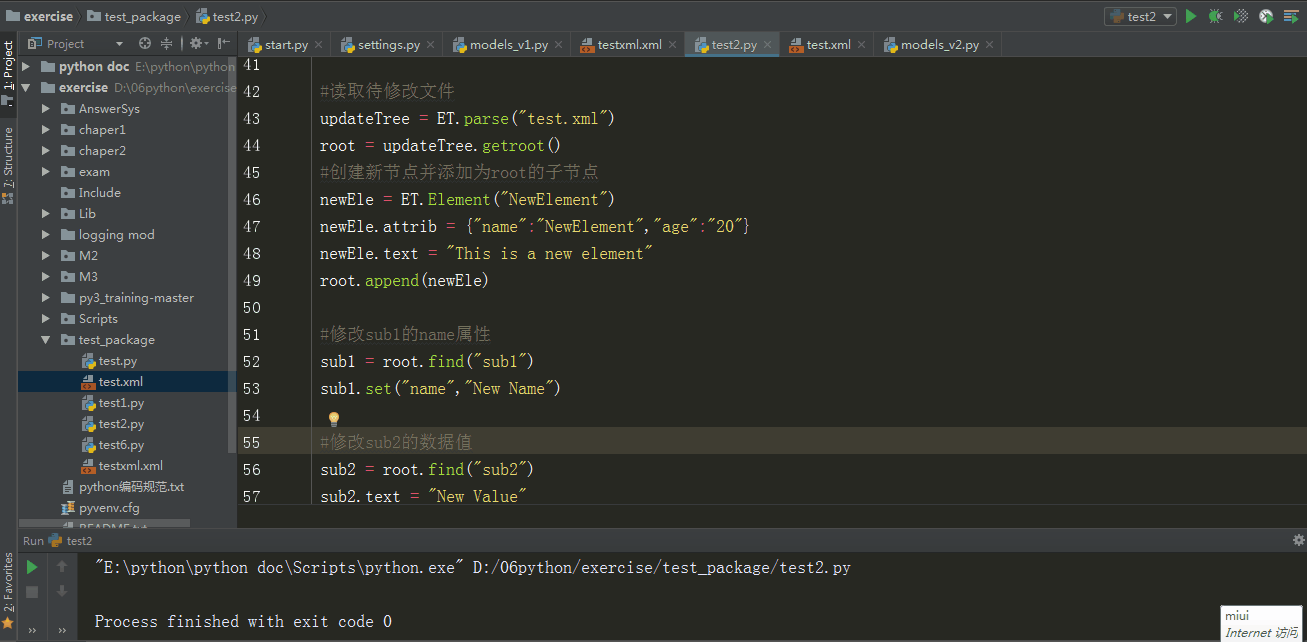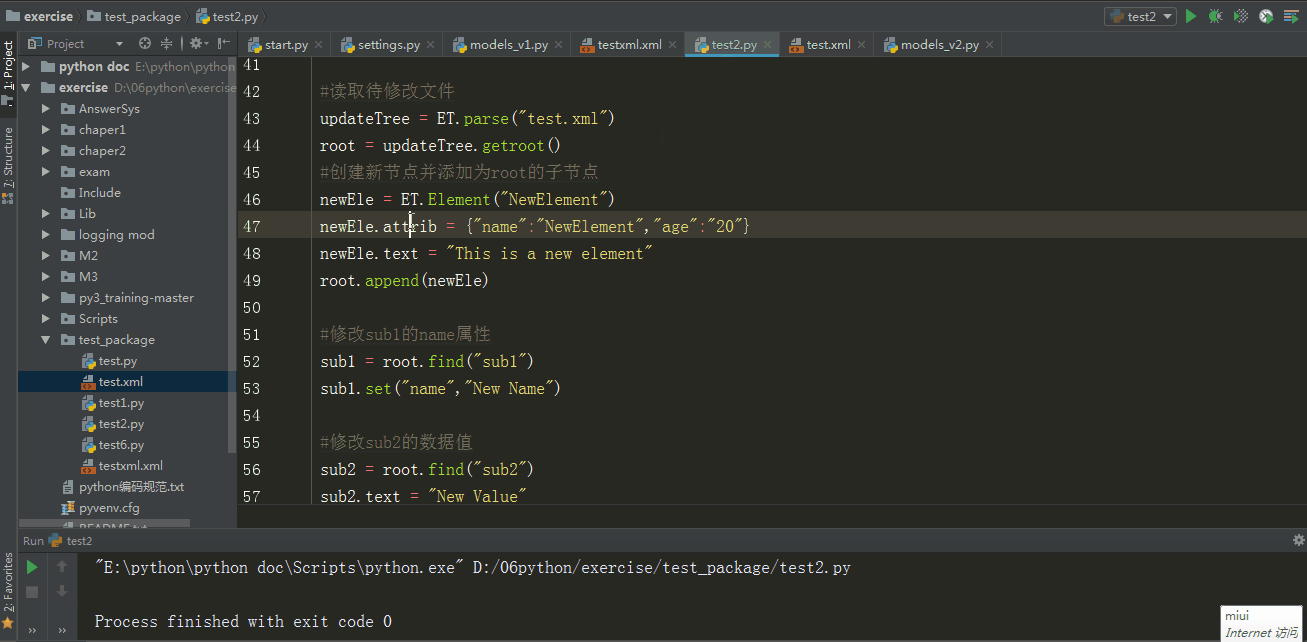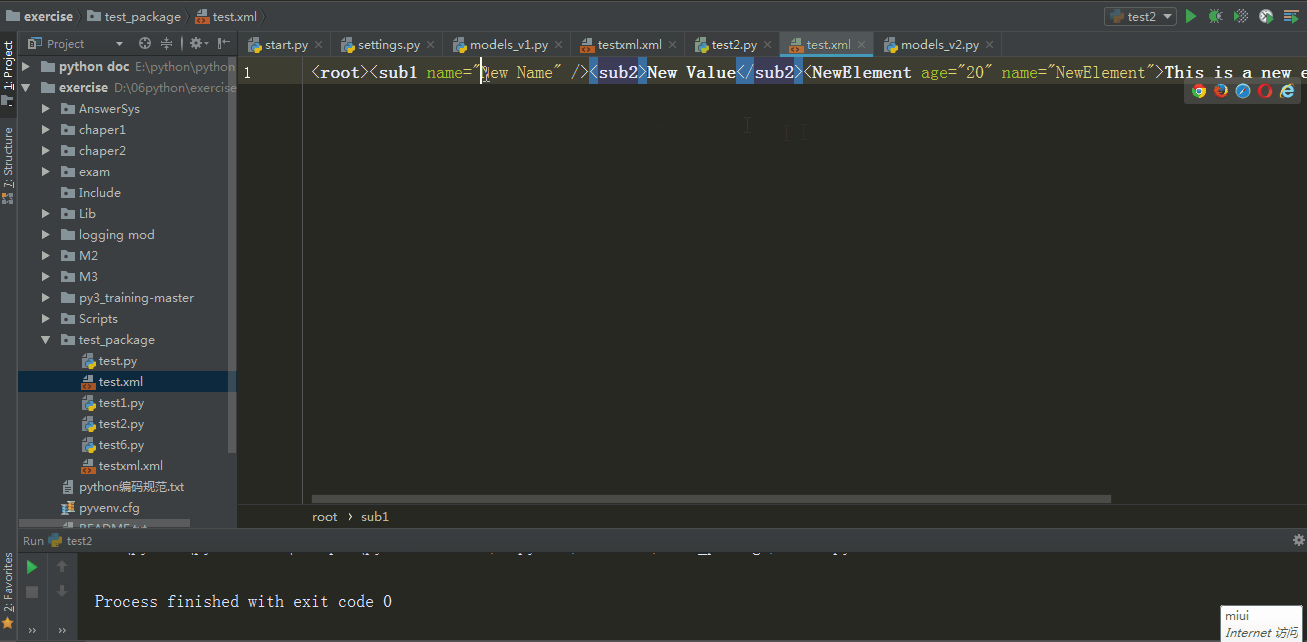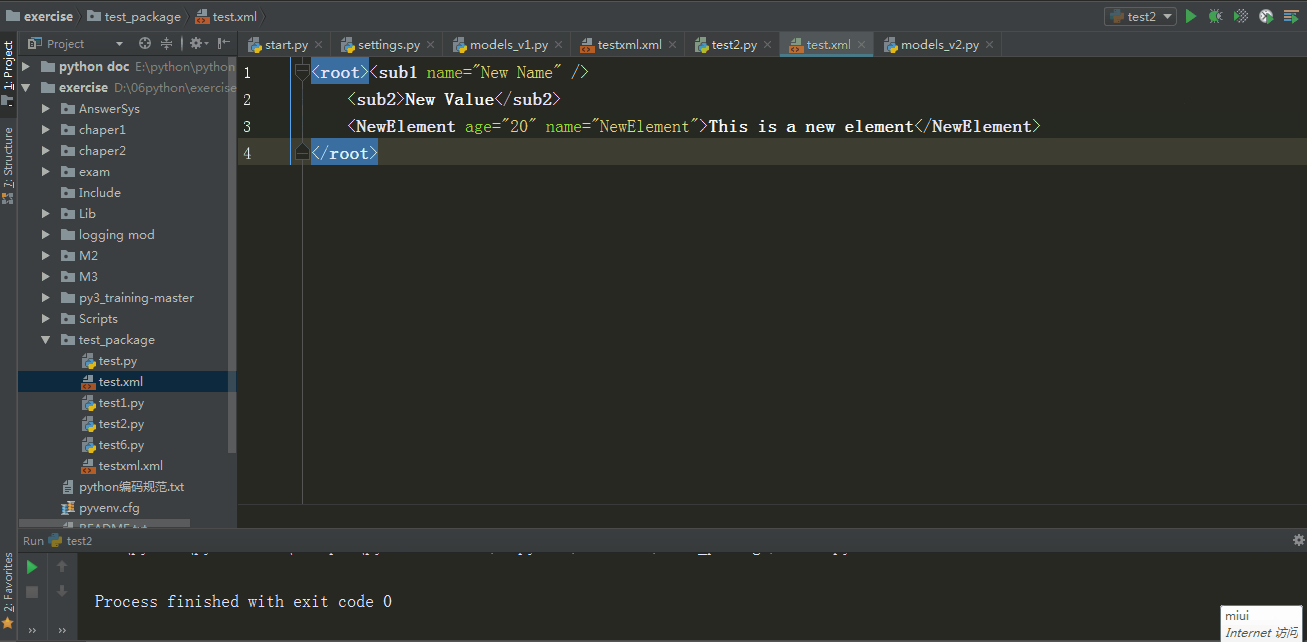
输出结果
<root><sub1 name="New Name" />
<sub2>New Value</sub2>
<NewElement age="20" name="NewElement">This is a new element</NewElement>
</root>
%E3%80%90day22%E3%80%91/%E4%BF%AE%E6%94%B9XML%E6%96%87%E4%BB%B6.gif?lastModify=1526954917)
创建xml文件
import xml.etree.ElementTree as ET
#创建根节点
a = ET.Element("root")
#创建子节点,并添加属性
b = ET.SubElement(a,"sub1")
b.attrib = {"name":"name attribute"}
#创建子节点,并添加数据
c = ET.SubElement(a,"sub2")
c.text = "test"
#创建elementtree对象,写文件
tree = ET.ElementTree(a)
tree.write("test.xml")
输出结果
<root><sub1 name="name attribute" /><sub2>test</sub2></root>

%E3%80%90day22%E3%80%91/%E5%88%9B%E5%BB%BAxml%E6%96%87%E4%BB%B6.gif?lastModify=1526954917)
二、datetime模块
datetime模块
datatime模块重新封装了time模块,提供更多接口,
相比于time模块,datetime模块的接口则更直观、更容易调用
datetime模块定义了下面这几个类:
datetime.date:表示日期的类。常用的属性有year, month, day;
datetime.time:表示时间的类。常用的属性有hour, minute, second, microsecond;
datetime.datetime:表示日期时间。
datetime.timedelta:表示时间间隔,即两个时间点之间的长度。
datetime.tzinfo:与时区有关的相关信息。(这里不详细充分讨论该类,感兴趣的童鞋可以参考python手册)
1、date类
datetime.date(year, month, day)
静态方法和字段
date.max、date.min :date对象所能表示的最大、最小日期;
date.resolution :date对象表示日期的最小单位。这里是天。
date.today() :返回一个表示当前本地日期的date对象;
date.fromtimestamp(timestamp) :根据给定的时间戮,返回一个date对象;
例子
import datetime
import time
print(datetime.date.max)
print(datetime.date.min)
print(datetime.date.resolution)
print(datetime.date.today())
print(datetime.date.fromtimestamp(time.time()))
输出结果
9999-12-31
0001-01-01
1 day, 0:00:00
2018-05-22
2018-05-22
date类方法和属性
d1.year、date.month、date.day:年、月、日;
d1.replace(year, month, day):生成一个新的日期对象,用参数指定的年,月,日代替原有对象中的属性。(原有对象仍保持不变)
d1.timetuple():返回日期对应的time.struct_time对象;
d1.weekday():返回weekday,如果是星期一,返回0;如果是星期2,返回1,以此类推;
d1.isoweekday():返回weekday,如果是星期一,返回1;如果是星期2,返回2,以此类推;
d1.isocalendar():返回格式如(year,month,day)的元组;
d1.isoformat():返回格式如'YYYY-MM-DD’的字符串;
d1.strftime(fmt):和time模块format相同。
例子
import datetime
d1 = datetime.date(year=2018,month=5,day=1) #date对象
d2 = datetime.date(2018,2,3)
print(d1.year,d1.month)
print(d1.replace(2017,3,1)) #生成一个新的日期对象,原有对象仍保持不变
print(d1.timetuple()) #返回结构化时间
print(d1.weekday()) #返回是一周星期几的数字,从周一/0开始,周一是0
print(d1.isoweekday()) #返回是一周星期几的数字,从周一/1开始,周一是1
print(d1.isocalendar()) #返回格式如(year,month,day)的元组时间;
print(d1.isoformat()) #返回格式如'YYYY-MM-DD’的字符串时间;
print(d1.strftime("%Y--%m--%d")) #设置时间格式,和time模块format相同。
print(datetime.date.fromtimestamp(128322222)) # 把一个时间戳转为datetime日期类型
输出结果
2018 5
2017-03-01
time.struct_time(tm_year=2018, tm_mon=5, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=1, tm_yday=121, tm_isdst=-1)
1
2
(2018, 18, 2)
2018-05-01
2018--05--01
1974-01-25
2、time类
datetime.time(hour[ , minute[ , second[ , microsecond[ , tzinfo] ] ] ] )
静态方法和字段
time.min、time.max:time类所能表示的最小、最大时间。其中,time.min = time(0, 0, 0, 0), time.max = time(23, 59, 59, 999999);
time.resolution:时间的最小单位,这里是1微秒;
例子
import datetime
print(datetime.time.max)
print(datetime.time.min)
print(datetime.time.resolution)
输出结果
23:59:59.999999
00:00:00
0:00:00.000001
方法和属性
例子
import datetime
t1 = datetime.time(23,12,52,90)
t2 = datetime.time(hour=23,minute=12,second=52,microsecond=90)
print(t1) #返回时间
print(t1.hour) #返回对象的小时数值
print(t1.minute) #返回对象的分钟数值
print(t1.second) #返回对象的秒数值
print(t1.microsecond) #返回对象的毫秒数值
print(t1.tzinfo) #返回对象的时区信息
print(t1.replace(20,10,7,888)) #创建一个新的时间对象,用参数指定的时、分、秒、微秒
# 代替原有对象中的属性(原有对象仍保持不变)
print(t1.isoformat()) #返回型如"HH:MM:SS"格式的字符串表示
print(t1.strftime("%H--%M--%S")) #设置显示的时间格式,同time模块中的format;
输出结果
23:12:52.000090
23
12
52
90
None
20:10:07.000888
23:12:52.000090
23--12--52
3、datetime类
datetime相当于date和time结合起来。datetime.datetime (year, month, day[ , hour[ , minute[ , second[ , microsecond[ , tzinfo] ] ] ] ] )
静态方法和字段
datetime.max 返回datetime类能表示的最大时间
datetime.min 返回datetime类能表示的最小时间
datetime.today():返回一个表示当前本地时间的datetime对象;
datetime.now([tz]):返回一个表示当前本地时间的datetime对象,如果提供了参数tz,则获取tz参数所指时区的本地时间;
datetime.utcnow():返回一个当前utc时间的datetime对象;#格林威治时间
datetime.fromtimestamp(timestamp[, tz]):根据时间戮创建一个datetime对象,参数tz指定时区信息;
datetime.utcfromtimestamp(timestamp):根据时间戮创建一个datetime对象;
datetime.combine(date, time):根据date和time,创建一个datetime对象;
datetime.strptime(date_string, format):由日期格式转化为字符串格式
例子
import datetime
import time
print(datetime.datetime.max) # 返回datetime类能表示的最大时间
print(datetime.datetime.min) # 返回datetime类能表示的最小时间
print(datetime.datetime.today()) #返回一个表示当前本地时间的datetime对象;
print(datetime.datetime.now()) #返回一个表示当前本地时间的datetime对象
print(datetime.datetime.utcnow()) #返回一个当前utc时间的datetime对象;#格林威治时间
print(datetime.datetime.fromtimestamp(time.time())) #根据时间戮创建一个datetime对象,参数tz指定时区信息;
print(datetime.datetime.utcfromtimestamp(time.time())) #根据时间戮创建一个datetime对象;
d1 = datetime.date(2018,5,1)
t1 = datetime.time(20,5,8,90)
print(datetime.datetime.combine(d1,t1)) #根据date和time,创建一个datetime对象;
dt1= datetime.datetime(2018,5,1,20,8,11)
print(datetime.datetime.strftime(dt1,"%Y-%m-%d %H:%M:%S")) #由日期格式转化为字符串格式
输出结果
9999-12-31 23:59:59.999999
0001-01-01 00:00:00
2018-05-22 18:34:21.797177
2018-05-22 18:34:21.797177
2018-05-22 10:34:21.797177
2018-05-22 18:34:21.797177
2018-05-22 10:34:21.797177
2018-05-22 10:34:21.797177
2018-05-01 20:05:08.000090
2018-05-01 20:08:11
方法和属性
import datetime
dt = datetime.datetime.now()
print(dt)
print(dt.year)
print(dt.month)
print(dt.day)
print(dt.hour)
print(dt.minute)
print(dt.second)
print(dt.microsecond)
print(dt.tzinfo)
print(dt.date()) #返回date对象
print(dt.time()) #返回time对象
print(dt.replace(2018,2,3,20,10,8,999)) #生成一个新的日期对象,原有对象仍保持不变
print(dt.timetuple()) #返回结构化时间
print(dt. utctimetuple ()) #返回格林尼治时区的的结构化时间
print(dt. weekday ()) #返回是一周星期几的数字,从周一/0开始,周一是0
print(dt. isocalendar ()) #返回格式如(year,month,day)的元组时间
print(dt. isoformat ()) #返回型如"HH:MM:SS"格式的字符串表示
print(dt. ctime ()) #返回一个日期时间的C格式字符串,等效于time.ctime(time.mktime(dt.timetuple()));
print(dt. strftime ("%Y--%m--%d %H:%M:%S")) #由日期格式转化为字符串格式
输出结果
2018-05-22 19:51:33.427091
2018
5
22
19
51
33
427091
None
2018-05-22
19:51:33.427091
2018-02-03 20:10:08.000999
time.struct_time(tm_year=2018, tm_mon=5, tm_mday=22, tm_hour=19, tm_min=51, tm_sec=33, tm_wday=1, tm_yday=142, tm_isdst=-1)
time.struct_time(tm_year=2018, tm_mon=5, tm_mday=22, tm_hour=19, tm_min=51, tm_sec=33, tm_wday=1, tm_yday=142, tm_isdst=0)
1
(2018, 21, 2)
2018-05-22T19:51:33.427091
Tue May 22 19:51:33 2018
2018--05--22 19:51:33
4、timedelta类,时间加减
使用timedelta可以很方便的在日期上做天days,小时hour,分钟,秒,毫秒,微妙的时间计算,如果要计算月份则需要另外的办法。
import datetime
dt = datetime.datetime.now()
#日期加一天
dt1 = dt + datetime.timedelta(days=1)
#日期减一天
dt2 = dt - datetime.timedelta(days=1)
print(dt1)
print(dt2)
#时间快进到5个小时后
dt3 = dt + datetime.timedelta(hours=5)
#时间返回到半小时前
dt4 = dt - datetime.timedelta(minutes=30)
print(dt3)
print(dt4)
输出结果
2018-05-23 20:04:35.337814
2018-05-21 20:04:35.337814
2018-05-23 01:04:35.337814
2018-05-22 19:34:35.337814
参考资料
[1]http://developer.51cto.com/art/201602/505662.htm
[2]https://www.cnblogs.com/yaoyinglong/p/xml.html
[3]https://www.cnblogs.com/tkqasn/p/6001134.html
Python之路(第十六篇)xml模块、datetime模块的更多相关文章
- Python之路(第二十六篇) 面向对象进阶:内置方法
一.__getattribute__ object.__getattribute__(self, name) 无条件被调用,通过实例访问属性.如果class中定义了__getattr__(),则__g ...
- Python之路(第十二篇)程序解耦、模块介绍\导入\安装、包
一.程序解耦 解耦总的一句话来说,减少依赖,抽象业务和逻辑,让各个功能实现独立. 直观理解“解耦”,就是我可以替换某个模块,对原来系统的功能不造成影响.是两个东西原来互相影响,现在让他们独立发展:核心 ...
- Python之路【第六篇】:socket
Python之路[第六篇]:socket Socket socket通常也称作"套接字",用于描述IP地址和端口,是一个通信链的句柄,应用程序通常通过"套接字&quo ...
- 【Python之路】第六篇--Python基础之模块
模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能需要多个函数才 ...
- Python之路【第六篇】python基础 之面向对象进阶
一 isinstance(obj,cls)和issubclass(sub,super) isinstance(obj,cls)检查是否obj是否是类 cls 的对象 和 issubclass(su ...
- Python自动化 【第十六篇】:JavaScript作用域和Dom收尾
本节内容: javascript作用域 DOM收尾 JavaScript作用域 JavaScript的作用域一直以来是前端开发中比较难以理解的知识点,对于JavaScript的作用域主要记住几句话,走 ...
- Python之路【第六篇】:面向对象编程相关
判断类与对象关系 isinstance(obj, cls) 判断对象obj是否是由cls类创建的 #!/usr/bin/env python #-*- coding:utf-8 -*- class ...
- Python之路(第十八篇)shutil 模块、zipfile模块、configparser模块
一.shutil 模块 1.shutil.copyfileobj(fsrc, fdst[, length]) 将文件内容拷贝到另一个文件中,需要打开文件 import shutil shutil.co ...
- Python之路【第六篇】:模块与包
目录 一 模块 3.1 import 3.2 from ... import... 3.3 把模块当做脚本执行 3.4 模块搜索路径 3.5 编译python文件 3.6 标准模块 3.7 dir ...
随机推荐
- spring boot 2 内嵌Tomcat Stopping service [Tomcat]
我在使用springboot时,当代码有问题时,发现控制台打印下面信息: Connected to the target VM, address: '127.0.0.1:42091', transpo ...
- linux安装mysql5.1
一.卸载mysql 1.检测系统是否已经安装过mysql或其依赖,若已装过要先将其删除 # yum list installed | grep mysql mysql-libs.i686 ...
- 无线LoRa远传智能水表
无线远传智能水表是一款基于瑞萨芯片的水表,该水表具有电子计数.无线远传功能.欠费关阀等功能,无线水表具有的功能如下:无线通信采用SX1278的LoRa进行点对点通信,SX1278模块在通信中启用CAD ...
- 大数据入门到精通3-SPARK RDD filter 以及 filter 函数
一.如何处理RDD的filter 1. 把第一行的行头去掉 scala> val collegesRdd= sc.textFile("/user/hdfs/CollegeNavigat ...
- Kubernetes 之上的架构应用
规划并运转一个兼顾可扩展性.可移植性和健壮性的运用是一件很有应战的事情,尤其是当体系杂乱度在不断增长时.运用或体系 本身的架构极大的影响着其运转办法.对环境的依靠性,以及与相关组件的耦合强弱.当运用在 ...
- php打印错误报告
//error handler functionfunction customError($errno, $errstr){ echo "<b>Error:</b> ...
- c++中的类(class)-----笔记(类继承)
1,派生类继承了基类的所有成员函数和数据成员(构造函数.析构函数和操作符重载函数外). 2,当不指明继承方式时,默认为私有继承. 3,基类的私有成员仅在基类中可见,在派生类中是不可见的.基类的私有成员 ...
- 全国绿色计算大赛 模拟赛第一阶段(C++)第1关:求和
挑战任务 这次“绿盟杯”大赛,小明作为参赛选手在练习的时候遇到一个问题,他要对一个范围的两个数进行数位的累加,例如有两个数 15,19 则 他们的数位和应该为:1+5+1+6+1+7+1+8+1+9, ...
- CentOS 下搭建Hudson
1.下载Hudson安装包 wget http://ftp.jaist.ac.jp/pub/eclipse/hudson/war/hudson-3.3.3.war 2.执行 java -jar hud ...
- oracle视图(转)
视图的概念 视图是基于一张表或多张表或另外一个视图的逻辑表.视图不同于表,视图本身不包含任何数据.表是实际独立存在的实体,是用于存储数据的基本结构.而视图只是一种定义,对应一个查询语句.视图的数据 ...