大数据系列之并行计算引擎Spark部署及应用
相关博文:
之前介绍过关于Spark的程序运行模式有三种:
1.Local模式;
2.standalone(独立模式)
3.Yarn/mesos模式
本文将介绍Spark安装及运行模式的第1、3两种模式。
安装包:
spark-2.1.0-bin-hadoop2.7.tgz size:195MB
下载链接: https://pan.baidu.com/s/1bphB3Q3 密码: 9v5h
安装步骤:
1.本地模式:
1.直接将tgz包放置在任一目录:LZ放在了 /home/mfz/resources 下
2.解压:
tar -xzvf spark-2.1.-bin-hadoop2..tgz
3.进入spark-2.1.0-bin-hadoop2.7目录下,启动spark:
bin/spark-shell --master local

4.下面就可以在spark命令行上编程scala啦;
在启动spark时,spark提供了一个RDD,属性名叫sc。下面我们来操作一下计算wordcount:
新建文本/home/mfz/scalaWordCount.txt

scala命令如下:
val wordtxt = sc.textFile("file:///home/mfz/scalaWordCount.txt") //加载文本scalaWordCount.txt
//将文本按照空格切分成Map(word,1),再进行reduceByKey将map的value进行累加,将计算结果落入磁盘(file表示本地磁盘)wordResult.txt目录中
wordtxt.flatMap(_.split(" ")).map(x => (x,)).reduceByKey(_+_).saveAsTextFile("file:///home/mfz/wordResult.txt");

查看结果

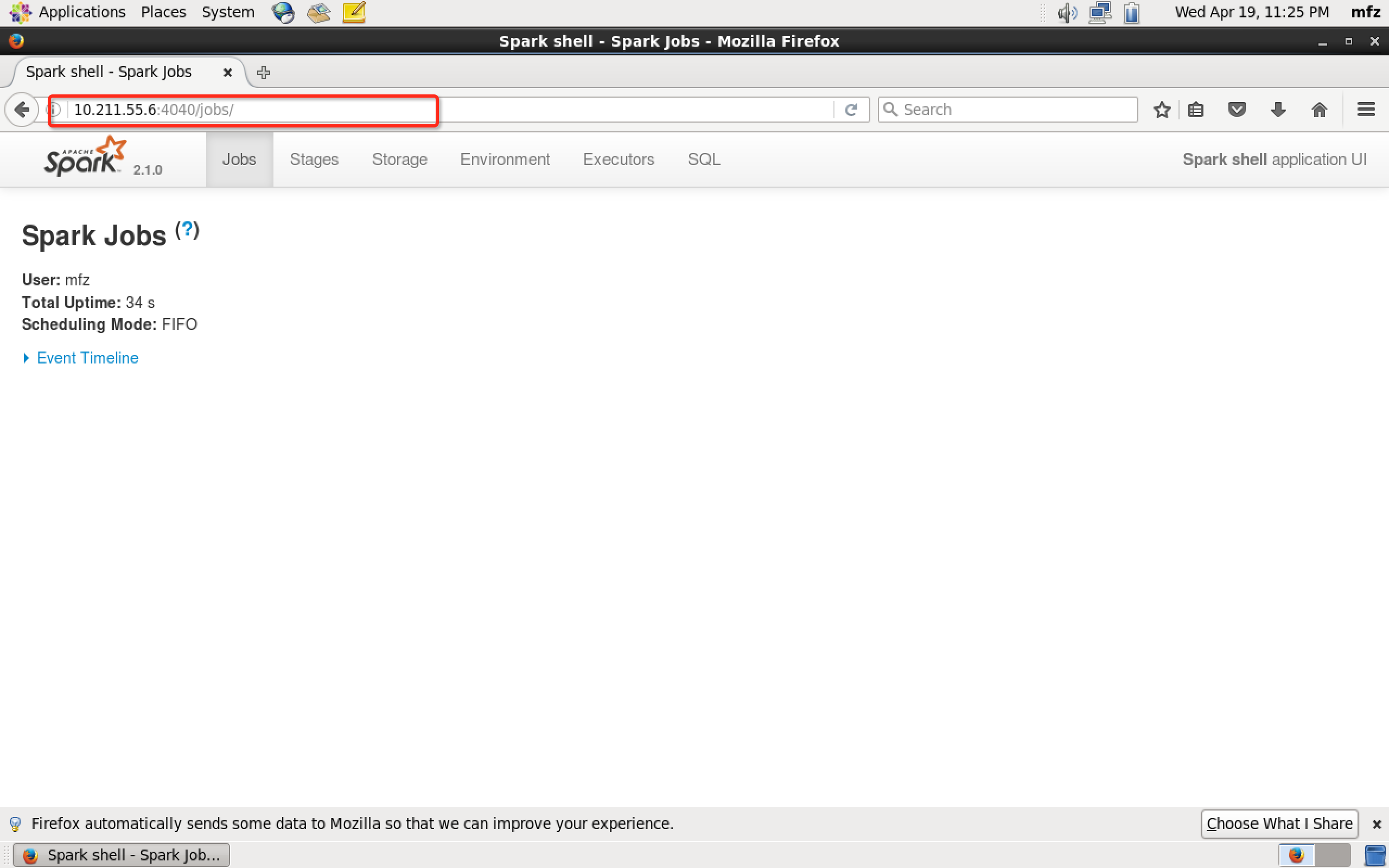
再看WebUI

scala语法详见:https://yq.aliyun.com/topic/69
2.Yarn上运行
在Yarn上运行我们就需要启动HDFS与Yarn服务了。关于Hadoop安装步骤详见博文:大数据系列之Hadoop分布式集群部署
1.修改spark配置文件:
vim /home/mfz/spark-2.1.0-bin-hadoop2.7/conf/spark-env.sh
#添加Hadoop配置文件环境变量
export HADOOP_CONF_DIR=/home/mfz/hadoop-2.7./etc/hadoop
2.
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf 添加如下 spark.master=local
# 配置historyServer
spark.yarn.historyServer.address=master: //master是hadoop服务器hostname
spark.history.ui.port=
spark.eventLog.enabled=true
spark.eventLog.dir=hdfs:///tmp/spark/events
spark.history.fs.logDirectory=hdfs:///tmp/spark/events
3.修改$Hadoop_HOME/etc/hadoop下yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs</value>
</property>
</configuration>
4.启动HDFS,Yarn服务
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
$HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver
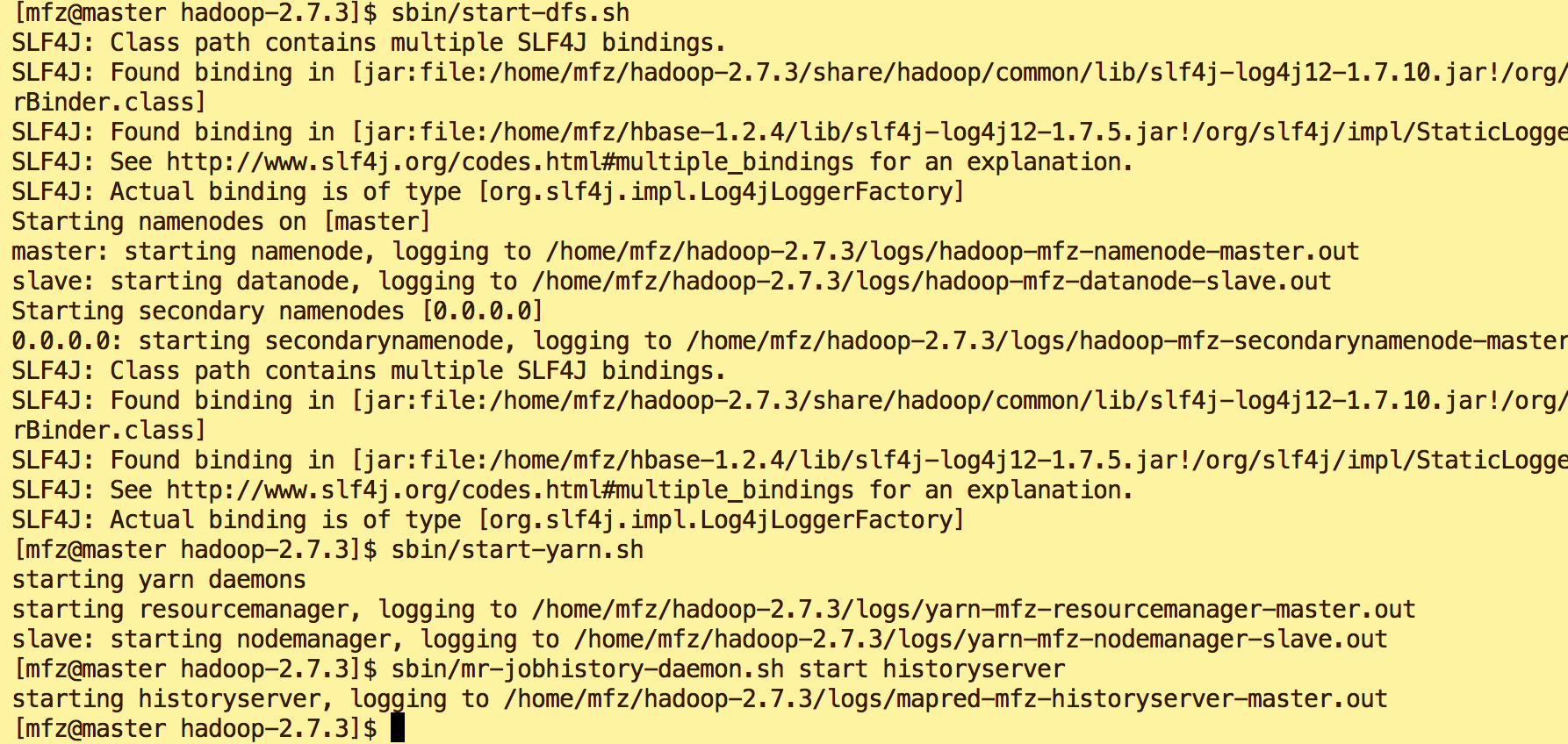
5.验证启动是否成功:


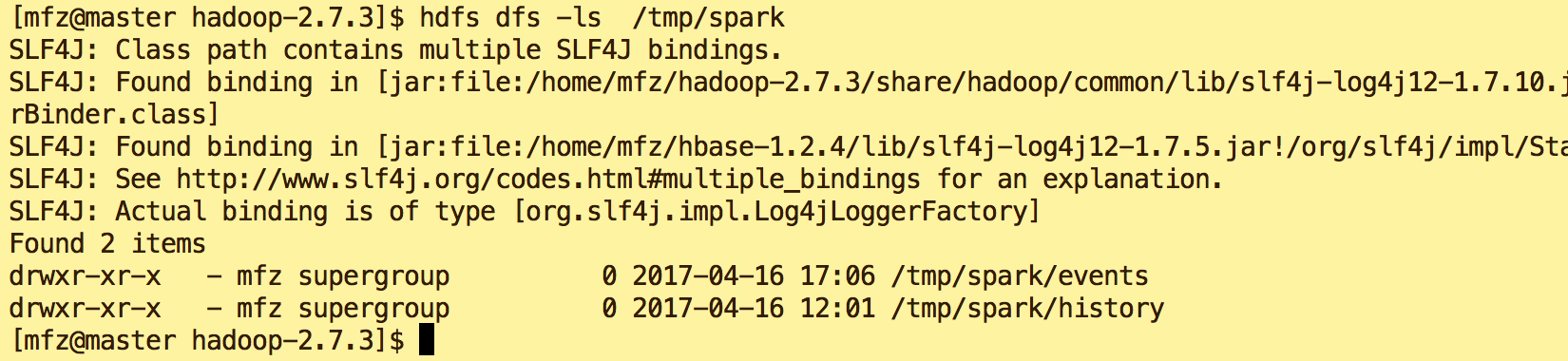
6.新建dfs目录
hdfs dfs -mkdir -p /tmp/spark/events hdfs dfs -mkdir -p /tmp/spark/history
#查看目录
hdfs dfs -ls /tmp/spark
7. 启动Spark on Yarn
cd spark-2.1.-bin-hadoop2.
bin/spark-shell --master yarn-client

8.下面我们再来执行一次WordCount命令,区别于Local我们将落盘地址改为HDFS上。
val wordtxt = sc.textFile("file:///home/mfz/scalaWordCount.txt") //加载文本scalaWordCount.txt
wordtxt.flatMap(_.split(" ")).map(x => (x,)).reduceByKey(_+_).saveAsTextFile("/tmp/wordResult");

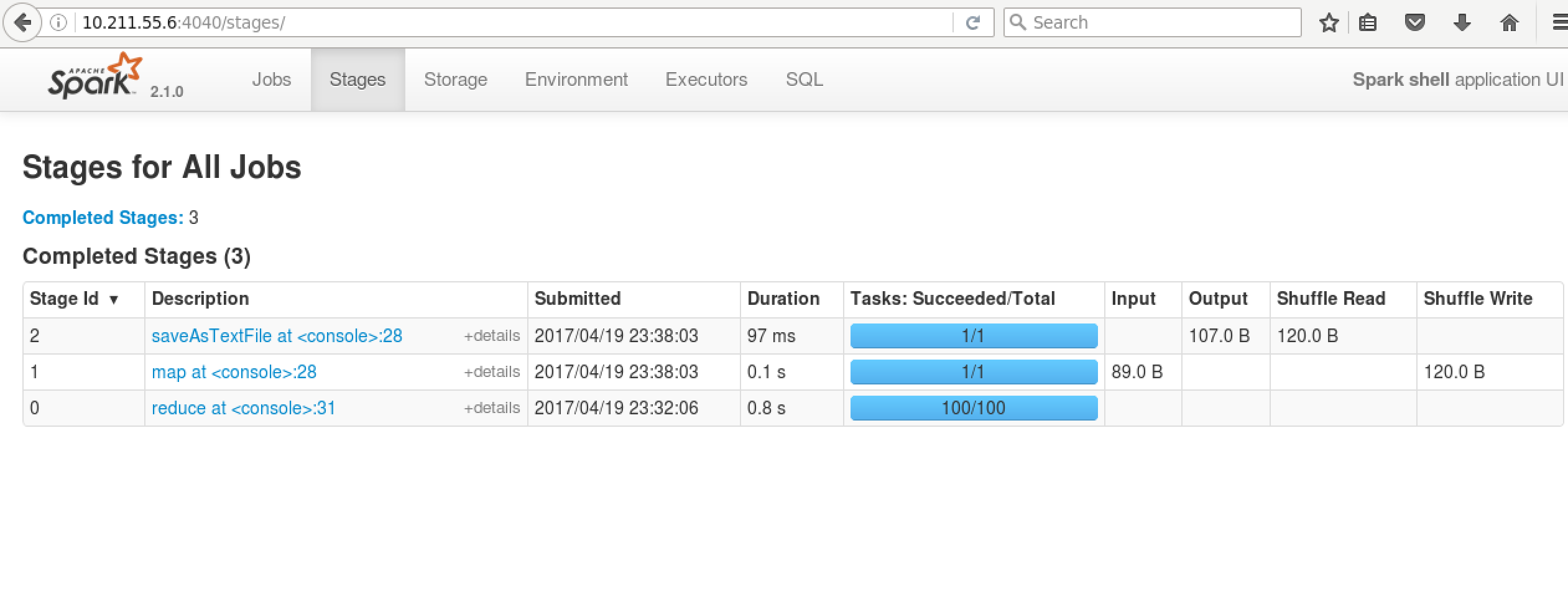
9.结果如下:
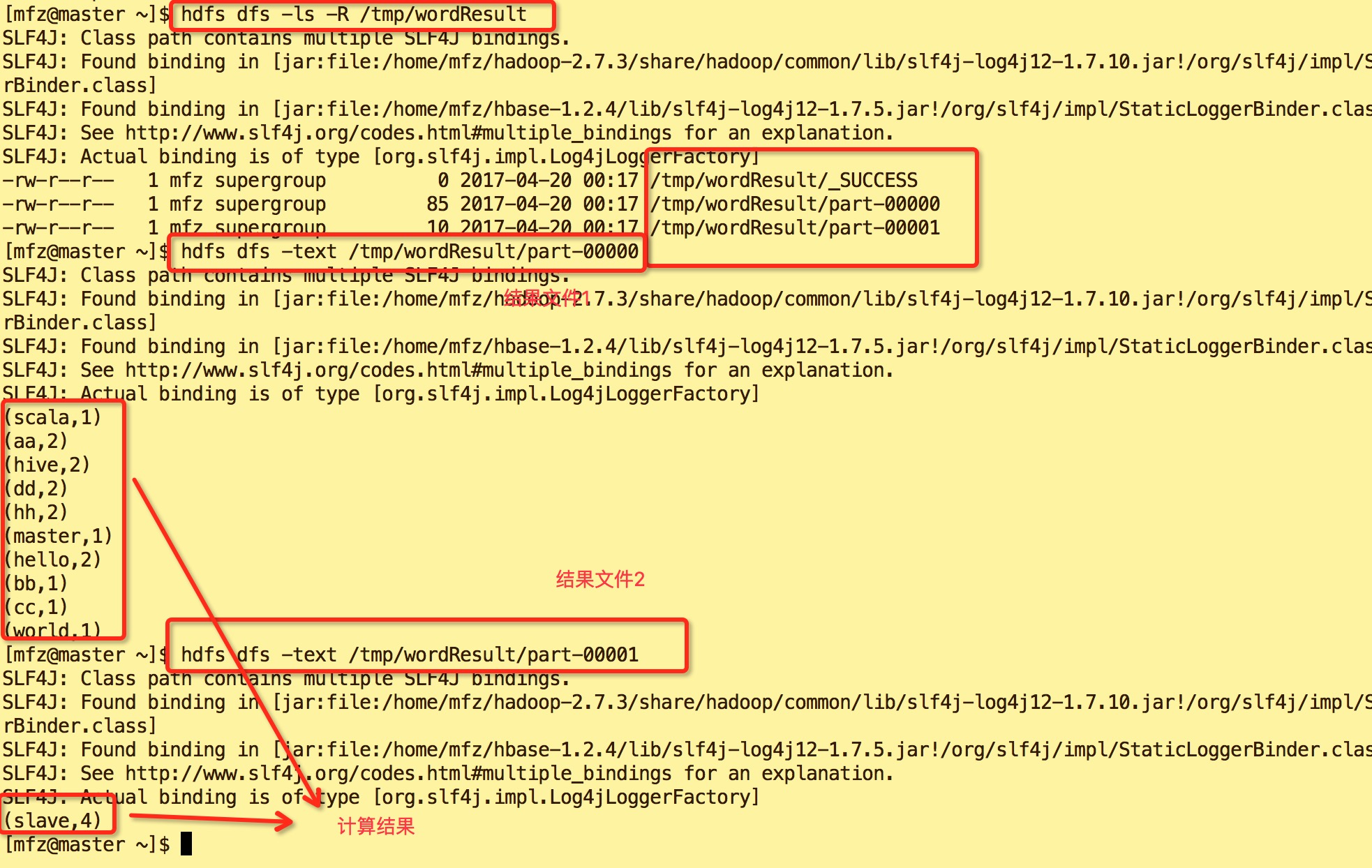
10.查看Yarn WebUi :master:18088。可以看到在红色框中的ID是 application_1492617622120_0001,正是我们上图spart on Yarn启动的app id 号,点击yarn web ui的spark id
可进入spark web ui查看我们刚才执行所有操作.

完~~
大数据系列之并行计算引擎Spark部署及应用的更多相关文章
- 大数据系列之并行计算引擎Spark介绍
相关博文:大数据系列之并行计算引擎Spark部署及应用 Spark: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. Spark是UC Berkeley AMP lab ( ...
- 大数据系列之分布式计算批处理引擎MapReduce实践
关于MR的工作原理不做过多叙述,本文将对MapReduce的实例WordCount(单词计数程序)做实践,从而理解MapReduce的工作机制. WordCount: 1.应用场景,在大量文件中存储了 ...
- 大数据系列之分布式计算批处理引擎MapReduce实践-排序
清明刚过,该来学习点新的知识点了. 上次说到关于MapReduce对于文本中词频的统计使用WordCount.如果还有同学不熟悉的可以参考博文大数据系列之分布式计算批处理引擎MapReduce实践. ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 大数据系列之数据仓库Hive原理
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列4:Yarn以及MapReduce 2
系列文章: 大数据系列:一文初识Hdfs 大数据系列2:Hdfs的读写操作 大数据谢列3:Hdfs的HA实现 通过前文,我们对Hdfs的已经有了一定的了解,本文将继续之前的内容,介绍Yarn与Yarn ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
随机推荐
- 侧边导航栏css示例
效果展示: html: <div class="sidebar"> <ul> <li>优先级 <ul> <li>< ...
- [转帖] k8s kubectl 命令行技巧
https://jimmysong.io/posts/kubectl-cheatsheet/ Kubectl Cheatsheet kubectl命令技巧大全Posted on November 3, ...
- poi中如何自定义日期格式
1. poi的“Quick Guide”中提供了 “How to create date cells ”例子来说明如何创建日期单元格,代码如下: HSSFCellStyle cellStyle = w ...
- mybatis之接口方法多参数的三种实现方式
关键代码举例: DaoMapper.xml <!-- 传入多个参数时,自动转换为map形式 --> <insert id="insertByColumns" us ...
- 普通的jdbc事务在插入数据后 下面的代码报错时 数据不会回滚 但是 spring的事务会回滚
普通的jdbc事务在插入数据后 下面的代码报错时 数据不会回滚 但是 spring的事务会回滚
- Python:目录和文件的操作模块os.path和OS常用方法
1.目录和文件的操作模块os.path,在使用之前要先导入:import os.path.它主要有以下几个重要的功能函数: #!/user/bin/python #coding= utf-8 impo ...
- UVa 10305 - Ordering Tasks (拓扑排序裸题)
John has n tasks to do. Unfortunately, the tasks are not independent and the execution of one task i ...
- wps相关问题
1 总汇 1.1 关闭wps中“我的wps”选项卡 我记得之前的WPS都是可以设置的不启动"我的WPS"的,但是最新版本中好象没有发现这个设置,反正小编是没找到,但是这并不影响我们 ...
- AngularJS学习笔记3——AngularJS的工作原理
个人觉得,要很好的理解AngularJS的运行机制,才能尽可能避免掉到坑里面去.在这篇文章中,我将根据网上的资料和自己的理解对AngularJS的在启动后,每一步都做了些什么,做一个比较清楚详细的解析 ...
- P2513 [HAOI2009]逆序对数列
P2513 [HAOI2009]逆序对数列 题目描述 对于一个数列{ai},如果有iaj,那么我们称ai与aj为一对逆序对数.若对于任意一个由1~n自然数组成的数列,可以很容易求出有多少个逆序对数.那 ...