kafka的简单理解
经典组合:
Flume+Kafka+Storm+HDFS/HBase
Flume:分布式采集
Kafka:分布式缓存
Kafka简介:
一种分布式的、基于发布/订阅的消息系统(Scala编写的)
Kafka特点:
1.消息持久化:通过O(1)的磁盘数据结构提供数据的持久化
Kafka严重依赖磁盘,但是不是说磁盘一定比内存慢
操作系统:预读,后写
特点:对磁盘的顺序访问要比对内存随机访问还要快
2.高吞吐量:每秒百万级的消息读写(每秒可以处理上百兆的数据)
3.分布式:扩展能力强(集群的方式)
4.多客户端支持:java、php、python、c++ ....
5.实时性:生产者生产的message立即被消费者可见
Kafka的数据单位:message
Kafka的目标:成为一个队列平台,不仅支持离线,还要支持在线
Kafka基本组件:
1.Broker:每一台机器叫一个Broker
2.Producer:日志消息生产者,用来写数据(日志并不是我们理解的log(消息追踪,提示性的错误,系统运转的标记),虽然也叫log(kafka控制的数据)但是相当于message)
3.Consumer:消息的消费者,用来读数据
4.Topic:不同消费者去指定的Topic中读,不同的生产者往不同的Topic中写(话题:逻辑概念)
5.Partition:在Topic基础上做了进一步区分分层(物理实现(以文件夹的形式存在),一个Topic是由一个或多个Partition实现的)
1.2.3并不是在一个节点上的(Producer--->Broker--->Consumer)
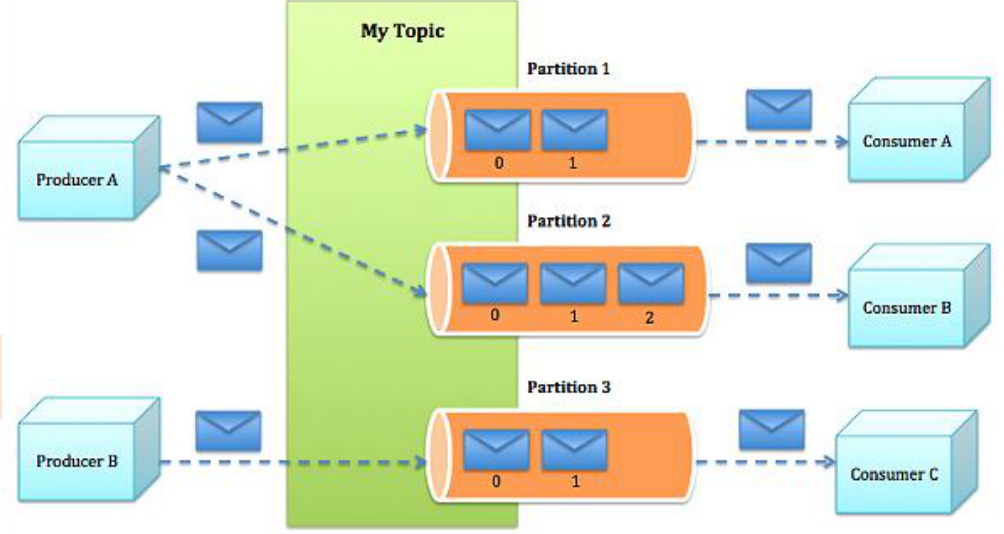
·Kafka内部是分布式的、一个Kafka集群通常包括多个Broker
·负载均衡:将Topic分成多个分区(partition),每个Broker存储一个或多个Partition
·多个Producer和Consumer同时生产和消费消息
例如: 有5个partition,3个broker,怎么分?
0 —> 0%3=0
1 —> 1%3=1
2 —> 2%3=2
3 —> 3%3=0
4 —> 4%3=1
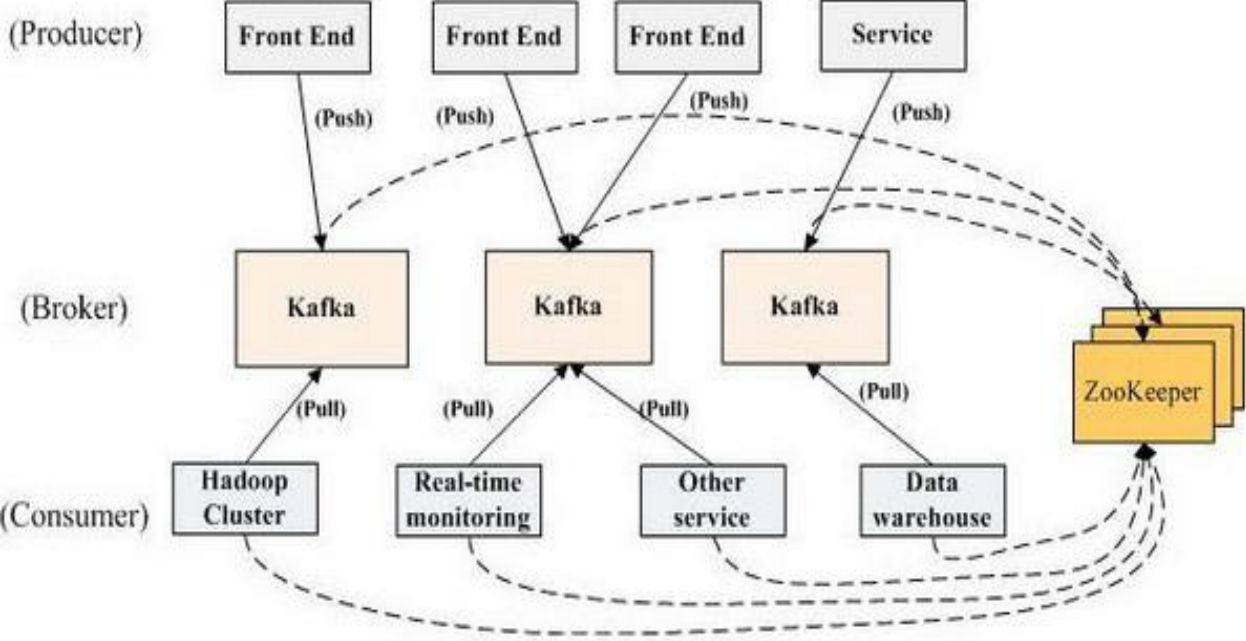
Producer和Broker不存在负载均衡(push模式(推)),因为Producer可以自己指定往哪个Broker写数据。
Broker和Consume存在负载均衡(pull模式(拉))——>依赖ZooKeeper完成。
负载均衡:
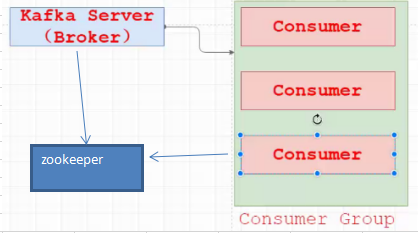
把consumer变成一个组,里面的是实际存在的,组是虚拟的概念。
分库思想,每个consumer存一部分数据,把consumer并发起来,就是完整数据,并没有丢失
负载均衡的思想:出现了个别节点不稳定,会体现rebalance机制。
一般来说Broker数量越多,集群吞吐量越高
一个topic由多个partition组成,每个partition分配了一个叫offset(偏移量)的id序列来识别分区中的消息(保证顺序性)
Kafka把更多的指导权交给了消费者(client来保存各自的offset)
Topic:
1.无论发布的消息是否被消费,kafka都会持久化一定时间(可配置,默认是7天)。
2.在每个消费者都持久化这个offset在日志中。通常消费者读消息时会使offset值线性的增长,但实际上其位置是由消费者控制,它可以按任意顺序来消费消息。比如复位到老的offset来重新处理。
3.每个分区代表一个并行单元。
Message:
message(消息)是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息,如果consumer订阅了这个主题,那么新发布的消息就会广播给这些consumer。
消息格式:
message format:
– message length : 4 bytes (value: 1+4+n)
– "magic" value : byte
– crc : bytes
– payload : n bytes
Producer:
1.生产者可以发布数据到它指定的topic中,并可以指定在topic里哪些消息分配到哪些分区(比如简单的轮流分发各个分区或通过指定分区语义分配key到对应分区)
2.生产者直接把消息发送给对应分区的broker,而不需要任何路由层。
3.批处理发送,当message积累到一定数量或等待一定时间后进行发送。
Producer有两种模式(producer.type=sync(同步),async(异步)):
1.同步模式:实时
2.异步模式:打到一定的条件(时间,数据量)
Consumer:
一种更抽象的消费方式:消费组(consumer group)
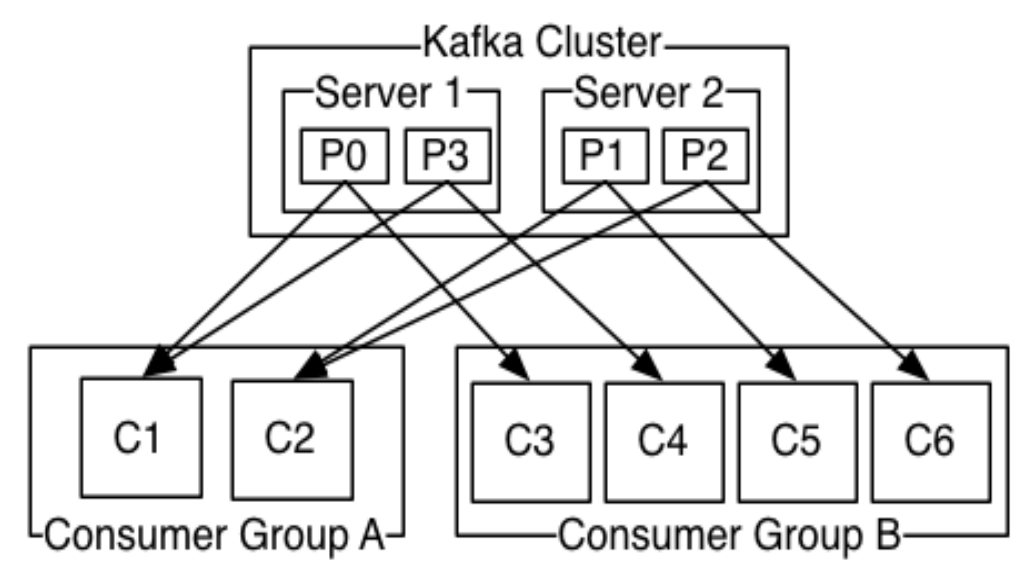
partition存储查找:
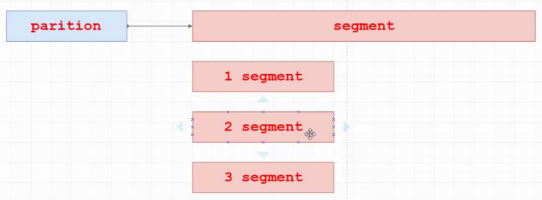
partition内部分成文件segment,真正落地的数据,往partition永远是往segment尾部追加,所以写数据是O(1),随着数据积累,segment拆分,变成多个,随着数据增长,segment不断增多,越早的数据,存在角标越小的(1,2,3)中,查历史数据,可以知道数据的offset,但不知道offset在哪一段,用二分法,定位到其中一个segment,再顺序查找。
持久化:
1.Kafka存储布局简单:topic的每个partition对应一个逻辑日志,逻辑日志由多个segment file组成,每个segment file大小一致。
2.每次生产者发布消息到一个分区,代理就将消息追加到最后一个段文件中。
3.与传统的消息系统不同,Kafka系统中存储的消息没有明确的消息Id。
4.消息通过日志中的逻辑偏移量(offset)来公开。
传输效率:
1.生产者提交一批消息作为一个请求。消费者虽然利用api遍历消息是一个一个的,但背后也是一次请求获取一批数据,从而减少网络请求数量。
2.Kafka层采用无缓存设计,而是依赖于底层的文件系统页缓存。这有助于避免双重缓存,即消息只缓存了一份在页缓存中。同时这在kafka重启后保持缓存warm也有额外的优势。因kafka根本不缓存消息在进程中,故gc开销也就很小。
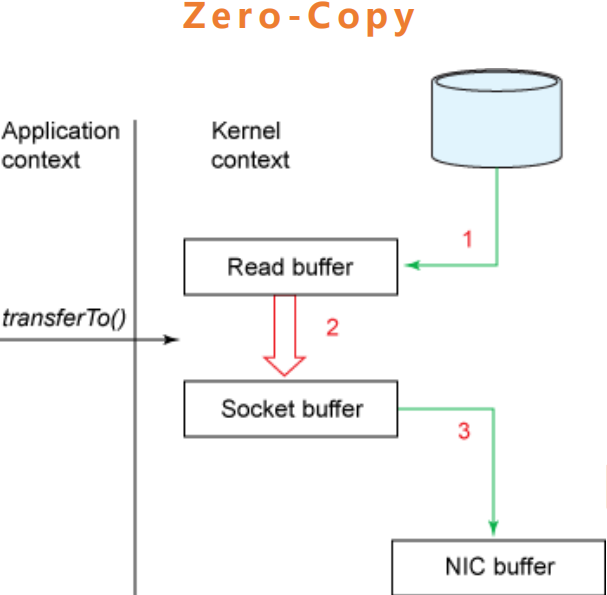
3.zero-copy:kafka为了减少字节拷贝,采用了大多数系统都会提供的sendfile系统调用。

无状态的Broker:
Kafka代理是无状态的:意味着消费者必须维护已消费的状态信息。这些信息由消费者自己维护,代理完全不管。这种设计非常微妙,它本身包含了创新。
– 从代理删除消息变得很棘手,因为代理并不知道消费者是否已经使用了该消息。Kafka创新性地解决了这个问题,它将一个简单的基于时间的SLA应用于保留策略。当消息在代理中超过一定时间后,将会被自动删除。
SLA:time-based消息保留策略(默认是7天)
– 这种创新设计有很大的好处,消费者可以故意倒回到老的偏移量再次消费数据。这违反了队列的常见约定,但被证明是许多消费者的基本特征。
交付保证:
Kafka默认采用at least once的消息投递策略。即在消费者端的处理顺序是获得消息->处理消息->保存位置。这可能导致一旦客户端挂掉,新的客户端接管时处理前面客户端已处理过的消息。
at least once:消息至少发送一次,如果消息未能接收成功,会出现重发的可能,保证消息不丢失。
三种保证策略:
– At most once 消息可能会丢,但绝不会重复传输。
– At least one 消息绝不会丢,但可能会重复传输。
– Exactly once 每条消息肯定会被传输一次且仅传输一次。
副本管理:
1.kafka将日志复制到指定多个服务器(broker)上。
针对partition副本管理,如果一共有f+1个broker,允许挂掉f个。
2.复本的单元是partition。在正常情况下,每个分区有一个leader和0到多个follower。
3.leader处理对应分区上所有的读写请求。分区可以多于broker数,leader也是分布式的。
4.follower的日志和leader的日志是相同的, follower被动的复制leader。如果leader挂了,其中一个follower会自动变成新的leader。
ISR:kafka在zookeeper中动态维护了一个set(里面表示的所有的副本,都是跟上了leader的节奏)
ISR里面副本需要删除的两个情况:
1.消息延迟
2.数据落后太多了
kfka数据提交成功:向leader里写数据,leader的segment同步数据到follower的内存,follower给leader返回信息,全部成功后leader返回ack机制,数据提交成功,之后follower在落地磁盘。
follower主动向leader去pull。
kafka失败的定义:“活着”
1.节点在zookeeper注册的session还在且可维护(基于zookeeper心跳机制)。
2.如果slave则能够紧随leader的更新不至于落后太远。
replica.lag.max.messages如果设为4,表明follower不能落后于leader超过3个消息,否则从ISR中删除。
kafka的简单理解的更多相关文章
- git的简单理解及基础操作命令
前端小白一枚,最近开始使用git,于是花了2天看了廖雪峰的git教程(偏实践,对于学习git的基础操作很有帮助哦),也在看<git版本控制管理>这本书(偏理论,内容完善,很不错),针对所学 ...
- 简单理解Struts2中拦截器与过滤器的区别及执行顺序
简单理解Struts2中拦截器与过滤器的区别及执行顺序 当接收到一个httprequest , a) 当外部的httpservletrequest到来时 b) 初始到了servlet容器 传递给一个标 ...
- [转]简单理解Socket
简单理解Socket 转自 http://www.cnblogs.com/dolphinX/p/3460545.html 题外话 前几天和朋友聊天,朋友问我怎么最近不写博客了,一个是因为最近在忙着公 ...
- Js 职责链模式 简单理解
js 职责链模式 的简单理解.大叔的代码太高深了,不好理解. function Handler(s) { this.successor = s || null; this.handle = funct ...
- Deep learning:四十六(DropConnect简单理解)
和maxout(maxout简单理解)一样,DropConnect也是在ICML2013上发表的,同样也是为了提高Deep Network的泛化能力的,两者都号称是对Dropout(Dropout简单 ...
- Deep learning:四十二(Denoise Autoencoder简单理解)
前言: 当采用无监督的方法分层预训练深度网络的权值时,为了学习到较鲁棒的特征,可以在网络的可视层(即数据的输入层)引入随机噪声,这种方法称为Denoise Autoencoder(简称dAE),由Be ...
- 简单理解dropout
dropout是CNN(卷积神经网络)中的一个trick,能防止过拟合. 关于dropout的详细内容,还是看论文原文好了: Hinton, G. E., et al. (2012). "I ...
- 我们为之奋斗过的C#-----C#的一个简单理解
我们首先来简单叙述一下什么是.NET,以及C#的一个简单理解和他们俩的一个区别. 1 .NET概述 .NET是Microsoft.NET的简称,是基于Windows平台的一种技术.它包含了能在.NET ...
- 简单理解ECMAScript2015中的箭头函数新特性
箭头函数(Arrow functions),是ECMAScript2015中新加的特性,它的产生,主要有以下两个原因:一是使得函数表达式(匿名函数)有更简洁的语法,二是它拥有词法作用域的this值,也 ...
随机推荐
- Unity Mono
Unity的mscrolib.dll和.Net的mscrolib.dll 好奇于Unity的mscrolib.dll和.Net Framework提供的mscrolib是否一致. .Net的mscro ...
- django -- uwsgi+nginx部署
一. 安装nginx How To Install Nginx on CentOS 7 添加epel扩展仓 sudo yum install epel-release 安装Nginx yum inst ...
- 【Alpha go】Day 2!
[Alpha go]Day 2! Part 0 · 简要目录 Part 1 · 项目燃尽图 Part 2 · 项目进展 Part 3 · 站立式会议照片 Part 4 · Scrum 摘要 Part ...
- Ecstore 默认图片压缩质量差的问题解决方法
修改app/image/lib/clip.php文件 }elseif( function_exists('imagecopyresampled')){ $quality = 80; $image_p ...
- MySQL数据库常用操作和技巧
MySQL数据库可以说是DBA们最常见和常用的数据库之一,MySQL的广泛应用,也使更多的人加入到学习它的行列之中.下面是老MySQL DBA总结的MySQL数据库最常见和最常使用的一些经验和技巧,分 ...
- 夯实基础之--new关键字、instanceOf原理
1.instanceOf原理 检测右边构造函数的prototype是否在左边对象的原型链上,在返回true,不在返回false 例:function Persion(name,age){ this ...
- Redis系列五:redis键管理和redis数据库管理
一.redis键管理 1 键重命名 rename oldKey newkey //格式rename oldKey newKey //若oldKey之前存在则被覆盖set name james :set ...
- 随手练——DFS小练
1. 单词接龙 https://www.luogu.org/problemnew/show/P1019 题目描述 单词接龙是一个与我们经常玩的成语接龙相类似的游戏,现在我们已知一组单词,且给定一个开头 ...
- OpenCV——霍夫变换(直线检测、圆检测)
x #include <opencv2/opencv.hpp> #include <iostream> #include <math.h> using namesp ...
- day 30
今日内容: 单例模式的四种方法 网络编程的介绍 单例模式: 什么是单例模式? 单例模式就是经过多次实例化,指向的是同一实例 为何要用单例模式? 可以节省内存资源 如何用单例模式? 方式一:利用绑定方法 ...