javaee 第八周作业
先来试想一个场景,如果你想查找一个集合中是否包含某个对象,那么程序应该怎么写呢?通常的做法是逐一取出每个元素与要查找的对象一一比较,当发现两者进行equals比较结果相等时,则停止查找并返回true,否则,返回false。但是这个做法的一个缺点是当集合中的元素很多时,譬如有一万个元素,那么逐一的比较效率势必下降很快。于是有人发明了一种哈希算法来提高从该集合中查找元素的效率,这种方式将集合分成若干个存储区域(可以看成一个个桶),每个对象可以计算出一个哈希码,可以根据哈希码分组,每组分别对应某个存储区域,这样一个对象根据它的哈希码就可以分到不同的存储区域(不同的桶中)。如下图所示:
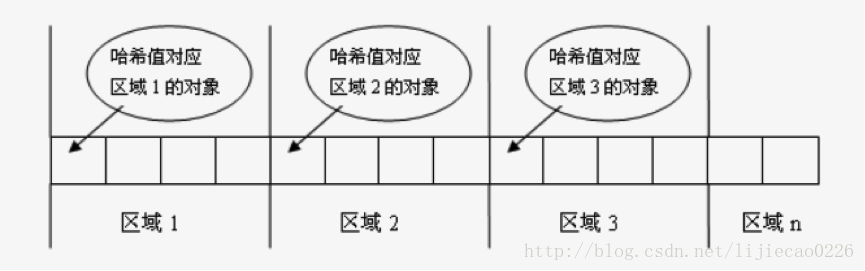
实际的使用中,一个对象一般有key和value,可以根据key来计算它的hashCode。假设现在全部的对象都已经根据自己的hashCode值存储在不同的存储区域中了,那么现在查找某个对象(根据对象的key来查找),不需要遍历整个集合了,现在只需要计算要查找对象的key的hashCode,然后找到该hashCode对应的存储区域,在该存储区域中来查找就可以了,这样效率也就提升了很多。说了这么多相信你对hashCode的作用有了一定的了解,下面就来看看hashCode和equals的区别和联系。
在研究这个问题之前,首先说明一下JDK对equals(Object obj)和hashCode()这两个方法的定义和规范:在Java中任何一个对象都具备equals(Object
obj)和hashCode()这两个方法,因为他们是在Object类中定义的。 equals(Object obj)方法用来判断两个对象是否“相同”,如果“相同”则返回true,否则返回false。 hashCode()方法返回一个int数,在Object类中的默认实现是“将该对象的内部地址转换成一个整数返回”。
下面是官方文档给出的一些说明:
- <span style="font-size:18px;">hashCode 的常规协定是:
- 在 Java 应用程序执行期间,在同一对象上多次调用 hashCode 方法时,必须一致地返回相同的整数,前提是对象上 equals 比较中所用的信息没有被修改。从某一应用程序的一次执行到同一应用程序的另一次执行,该整数无需保持一致。
- 如果根据 equals(Object) 方法,两个对象是相等的,那么在两个对象中的每个对象上调用 hashCode 方法都必须生成相同的整数结果。
- 以下情况不 是必需的:如果根据 equals(java.lang.Object) 方法,两个对象不相等,那么在两个对象中的任一对象上调用 hashCode 方法必定会生成不同的整数结果。但是,程序员应该知道,为不相等的对象生成不同整数结果可以提高哈希表的性能。
- 实际上,由 Object 类定义的 hashCode 方法确实会针对不同的对象返回不同的整数。(这一般是通过将该对象的内部地址转换成一个整数来实现的,但是 JavaTM 编程语言不需要这种实现技巧。)
- 当equals方法被重写时,通常有必要重写 hashCode 方法,以维护 hashCode 方法的常规协定,该协定声明相等对象必须具有相等的哈希码。</span>
下面是我查阅了相关资料之后对以上的说明做的归纳总结:
1.若重写了equals(Object obj)方法,则有必要重写hashCode()方法。
2.若两个对象equals(Object obj)返回true,则hashCode()有必要也返回相同的int数。
3.若两个对象equals(Object obj)返回false,则hashCode()不一定返回不同的int数。
4.若两个对象hashCode()返回相同int数,则equals(Object obj)不一定返回true。
5.若两个对象hashCode()返回不同int数,则equals(Object
obj)一定返回false。
6.同一对象在执行期间若已经存储在集合中,则不能修改影响hashCode值的相关信息,否则会导致内存泄露问题。
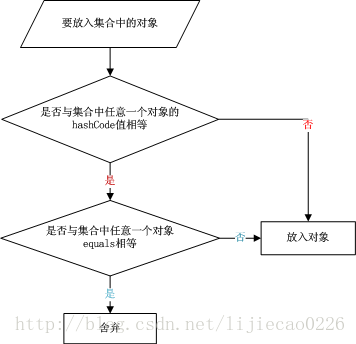
从上面的图中可以清晰地看到在存储一个对象时,先进行hashCode值的比较,然后进行equals的比较。可能现在你已经对上面的6点归纳有了一些认识。我们还可以通过JDK中得源码来认识一下具体hashCode和equals在代码中是如何调用的。
HashSet.java
- <span style="font-size:18px;"> public boolean add(E e) {
- return map.put(e, PRESENT)==null;
- }</span>
HashMap.java
- <span style="font-size:18px;"> public V put(K key, V value) {
- if (key == null)
- return putForNullKey(value);
- int hash = hash(key.hashCode());
- int i = indexFor(hash, table.length);
- for (Entry<K,V> e = table[i]; e != null; e = e.next) {
- Object k;
- if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- return oldValue;
- }
- }
- modCount++;
- addEntry(hash, key, value, i);
- return null;
- }</span>
最后再来看几个测试的例子吧:
测试一:覆盖equals(Object obj)但不覆盖hashCode(),导致数据不唯一性
- <span style="font-size:18px;">public class HashCodeTest {
- public static void main(String[] args) {
- Collection set = new HashSet();
- Point p1 = new Point(1, 1);
- Point p2 = new Point(1, 1);
- System.out.println(p1.equals(p2));
- set.add(p1); //(1)
- set.add(p2); //(2)
- set.add(p1); //(3)
- Iterator iterator = set.iterator();
- while (iterator.hasNext()) {
- Object object = iterator.next();
- System.out.println(object);
- }
- }
- }
- class Point {
- private int x;
- private int y;
- public Point(int x, int y) {
- super();
- this.x = x;
- this.y = y;
- }
- @Override
- public boolean equals(Object obj) {
- if (this == obj)
- return true;
- if (obj == null)
- return false;
- if (getClass() != obj.getClass())
- return false;
- Point other = (Point) obj;
- if (x != other.x)
- return false;
- if (y != other.y)
- return false;
- return true;
- }
- @Override
- public String toString() {
- return "x:" + x + ",y:" + y;
- }
- }
- </span>
输出结果:
- <span style="font-size:18px;">true
- x:1,y:1
- x:1,y:1
- </span>
原因分析:
(1)当执行set.add(p1)时(1),集合为空,直接存入集合;
(2)当执行set.add(p2)时(2),首先判断该对象(p2)的hashCode值所在的存储区域是否有相同的hashCode,因为没有覆盖hashCode方法,所以jdk使用默认Object的hashCode方法,返回内存地址转换后的整数,因为不同对象的地址值不同,所以这里不存在与p2相同hashCode值的对象,因此jdk默认不同hashCode值,equals一定返回false,所以直接存入集合。
(3)当执行set.add(p1)时(3),时,因为p1已经存入集合,同一对象返回的hashCode值是一样的,继续判断equals是否返回true,因为是同一对象所以返回true。此时jdk认为该对象已经存在于集合中,所以舍弃。
测试二:覆盖hashCode方法,但不覆盖equals方法,仍然会导致数据的不唯一性
修改Point类:
- <span style="font-size:18px;">class Point {
- private int x;
- private int y;
- public Point(int x, int y) {
- super();
- this.x = x;
- this.y = y;
- }
- @Override
- public int hashCode() {
- final int prime = 31;
- int result = 1;
- result = prime * result + x;
- result = prime * result + y;
- return result;
- }
- @Override
- public String toString() {
- return "x:" + x + ",y:" + y;
- }
- }
- </span>
输出结果:
- <span style="font-size:18px;">false
- x:1,y:1
- x:1,y:1</span>
原因分析:
(1)当执行set.add(p1)时(1),集合为空,直接存入集合;
(2)当执行set.add(p2)时(2),首先判断该对象(p2)的hashCode值所在的存储区域是否有相同的hashCode,这里覆盖了hashCode方法,p1和p2的hashCode相等,所以继续判断equals是否相等,因为这里没有覆盖equals,默认使用'=='来判断,所以这里equals返回false,jdk认为是不同的对象,所以将p2存入集合。
(3)当执行set.add(p1)时(3),时,因为p1已经存入集合,同一对象返回的hashCode值是一样的,并且equals返回true。此时jdk认为该对象已经存在于集合中,所以舍弃。
- <span style="font-size:18px;">public class HashCodeTest {
- public static void main(String[] args) {
- Collection set = new HashSet();
- Point p1 = new Point(1, 1);
- Point p2 = new Point(1, 2);
- set.add(p1);
- set.add(p2);
- p2.setX(10);
- p2.setY(10);
- set.remove(p2);
- Iterator iterator = set.iterator();
- while (iterator.hasNext()) {
- Object object = iterator.next();
- System.out.println(object);
- }
- }
- }
- class Point {
- private int x;
- private int y;
- public Point(int x, int y) {
- super();
- this.x = x;
- this.y = y;
- }
- public int getX() {
- return x;
- }
- public void setX(int x) {
- this.x = x;
- }
- public int getY() {
- return y;
- }
- public void setY(int y) {
- this.y = y;
- }
- @Override
- public int hashCode() {
- final int prime = 31;
- int result = 1;
- result = prime * result + x;
- result = prime * result + y;
- return result;
- }
- @Override
- public boolean equals(Object obj) {
- if (this == obj)
- return true;
- if (obj == null)
- return false;
- if (getClass() != obj.getClass())
- return false;
- Point other = (Point) obj;
- if (x != other.x)
- return false;
- if (y != other.y)
- return false;
- return true;
- }
- @Override
- public String toString() {
- return "x:" + x + ",y:" + y;
- }
- }
- </span>
运行结果:
- <span style="font-size:18px;">x:1,y:1
- x:10,y:10</span>
原因分析:
假设p1的hashCode为1,p2的hashCode为2,在存储时p1被分配在1号桶中,p2被分配在2号筒中。这时修改了p2中与计算hashCode有关的信息(x和y),当调用remove(Object
obj)时,首先会查找该hashCode值得对象是否在集合中。假设修改后的hashCode值为10(仍存在2号桶中),这时查找结果空,jdk认为该对象不在集合中,所以不会进行删除操作。然而用户以为该对象已经被删除,导致该对象长时间不能被释放,造成内存泄露。解决该问题的办法是不要在执行期间修改与hashCode值有关的对象信息,如果非要修改,则必须先从集合中删除,更新信息后再加入集合中。
4.若两个对象equals返回false,则hashCode不一定返回不同的int数,但为不相等的对象生成不同hashCode值可以提高
哈希表的性能。
5.若两个对象hashCode返回相同int数,则equals不一定返回true。
6.若两个对象hashCode返回不同int数,则equals一定返回false。
7.同一对象在执行期间若已经存储在集合中,则不能修改影响hashCode值的相关信息,否则会导致内存泄露问题。
来自:https://blog.csdn.net/lijiecao0226/article/details/24609559 键随心动
javaee 第八周作业的更多相关文章
- 2017-2018-2 1723《程序设计与数据结构》第八周作业 & 实验二 & 第一周结对编程 总结
作业地址 第八周作业:https://edu.cnblogs.com/campus/besti/CS-IMIS-1723/homework/1847 (作业界面已评分,可随时查看,如果对自己的评分有意 ...
- 2018-2019-1 20189221 《Linux内核原理与分析》第八周作业
2018-2019-1 20189221 <Linux内核原理与分析>第八周作业 实验七 编译链接过程 gcc –e –o hello.cpp hello.c / gcc -x cpp-o ...
- 2017-2018-1 JAVA实验站 第八周作业
2017-2018-1 JAVA实验站 第八周作业 详情请见团队博客
- 2017-2018-1 JaWorld 第八周作业
2017-2018-1 JaWorld 第八周作业 团队分工 成员 分工 陈是奇 统计成员工具选择 马平川 类图 王译潇 编码规范 李昱兴 用例图 林臻 状态图 张师瑜 推进工作进展.写博客 UML ...
- 2017-2018-1 20179205《Linux内核原理与设计》第八周作业
<Linux内核原理与设计>第八周作业 视频学习及操作分析 预处理.编译.链接和目标文件的格式 可执行程序是怎么来的? 以C语言为例,经过编译器预处理.编译成汇编代码.汇编器编译成目标代码 ...
- 2019-2020-1 20199329《Linux内核原理与分析》第八周作业
<Linux内核原理与分析>第八周作业 一.本周内容概述: 理解编译链接的过程和ELF可执行文件格式 编程练习动态链接库的两种使用方式 使用gdb跟踪分析一个execve系统调用内核处理函 ...
- 2020-2021-1 20209307 《Linux内核原理与分析》第八周作业
这个作业属于哪个课程 <2020-2021-1Linux内核原理与分析)> 这个作业要求在哪里 <2020-2021-1Linux内核原理与分析第八周作业> 这个作业的目标 & ...
- 2017-2018-1 我爱学Java 第八周 作业
团队六七周作业 团队分工 UML图 工具选择 小编(金立清)有话说 参考资料 团队分工 返回目录 UML图 用例图 类图 活动图 状态图 返回目录 工具选择 ProcessOn - 免费在线作图,实时 ...
- 第八周作业总结&第六次实验报告
实验六 Java异常 实验目的 理解异常的基本概念: 掌握异常处理方法及熟悉常见异常的捕获方法. 实验要求 练习捕获异常.声明异常.抛出异常的方法.熟悉try和catch子句的使用. 掌握自定义异常类 ...
随机推荐
- UVA-11078(水题)
题意: 给一个序列,找两个整数a[i],a[j]使得a[i]-a[j]最大; 思路: 从前往后扫一遍;水题; AC代码: #include <bits/stdc++.h> /* #incl ...
- Brackets(区间dp)
Brackets Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 8017 Accepted: 4257 Descript ...
- Codeforces702A - Maximum Increase【尺取】
题意: 求一个连续的最长子序列长度: 思路: 没看仔细还wa1了-以为LIS- 然后写了尺取吧...= =太不仔细了.不过收获是LIS特么写挫了然后看了学长的blog<-点我- 题目的挫code ...
- lightoj 1025【区间DP】
题意: 给出一个word,求有多少种方法你从这个word清除一些字符而达到一个回文串. 思路: 区间问题,还是区间DP: 我判断小的区间有多少,然后往外扩大一点. dp[i,j]就代表从i到j的方案数 ...
- python 模块和包的使用方法
一.模块 1.import导入模块 import module1,mudule2... 2.from...import...导入模块 导入指定内容 from modname import name1[ ...
- 超完整的Chrome浏览器客户端调试大全
引言 “工欲善其事,必先利其器” 没错,这句话个人觉得说的特别有道理,举个例子来说吧,厉害的化妆师都有一套非常专业的刷子,散粉刷负责定妆,眼影刷负责打眼影,各司其职,有了专业的工具才能干专业的事,这个 ...
- 如何在VS2010的VC++ 基于对话框的MFC程序中添加菜单
方法1:亲测 成功 转载自https://social.msdn.microsoft.com/Forums/vstudio/zh-CN/48338f6b-e5d9-4c0c-8b17-05ca3ef ...
- js 切割逗号
使用string对象的split()方法可以处理.例如:var yourString=“12,25,24,234,234,”;var result=yourString.split(",&q ...
- CSS3向上移动的效果
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- ie下,php HTTP_REFERER获取失败的整理
HTTP_REFERER有效的情况1.以iframe 形式调用地址2.以window.open调用,打开新页面window.open(url);3.使用window.location.replace在 ...