MYSQL 二次筛选,统计,最大值,最小值,分组,靠拢
HAVING 筛选后再 筛选
SELECT CLASS,SUM(TOTAL_SCORES) FROM student_score GROUP BY CLASS HAVING SUM(TOTAL_SCORES)>;
这里用where SUM(TOTAL_SCORES)>505的话,将会出错,因为表中根本没有总成绩分数这项,这是分组之后才有的
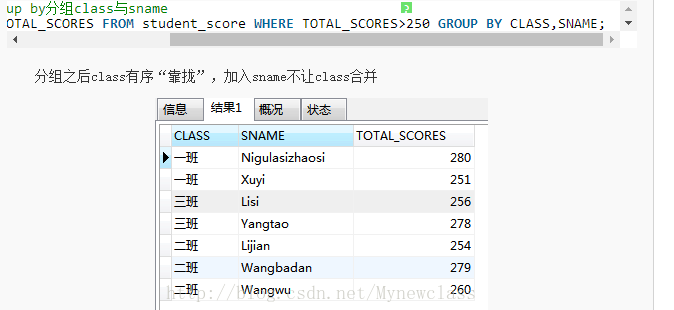
ELECT CLASS,SNAME,TOTAL_SCORES FROM student_score WHERE TOTAL_SCORES>250 GROUP BY CLASS,SNAME;
意思是 分班 不靠拢 成绩 降序
统计命令 对时间 筛选时段 并且 统计
select sum(zong) from table where unix_timestamp(date) between unix_timestamp('2013-05-05') and unix_timestamp('2013-09-01')
参考
https://www.2cto.com/database/201712/706595.html
https://www.cnblogs.com/zuochuang/p/8006289.html
我们经常会面临要从数据库里判断时间,取出特定日期的查询。但是数据库里储存的都是unix时间戳,处理起来并不是特别友好。幸而MYSQL提供了几个处理时间戳的函数,可以帮助我们在查询的时候,就将时间戳格式化。用法举例如下:
1.FROM_UNIXTIME()函数
FROM_UNIXTIME(unix_timestamp,format)
参数unix_timestamp 时间戳 可以用数据库里的存储时间数据的字段
参数format 要转化的格式 比如“”%Y-%m-%d“” 这样格式化之后的时间就是 2017-11-30
可以有的形式:
%M 月名字(January~December)
%W 星期名字(Sunday~Saturday)
%D 有英语前缀的月份的日期(1st, 2nd, 3rd, 等等。)
%Y 年, 数字, 4 位
%y 年, 数字, 2 位
%a 缩写的星期名字(Sun~Sat)
%d 月份中的天数, 数字(00~31)
%e 月份中的天数, 数字(0~31)
%m 月, 数字(01~12)
%c 月, 数字(1~12)
%b 缩写的月份名字(Jan~Dec)
%j 一年中的天数(001~366)
%H 小时(00~23)
%k 小时(0~23)
%h 小时(01~12)
%I 小时(01~12)
%l 小时(1~12)
%i 分钟, 数字(00~59)
%r 时间,12 小时(hh:mm:ss [AP]M)
%T 时间,24 小时(hh:mm:ss)
%S 秒(00~59)
%s 秒(00~59)
%p AM或PM
%w 一个星期中的天数(0=Sunday ~6=Saturday )
%U 星期(0~52), 这里星期天是星期的第一天
%u 星期(0~52), 这里星期一是星期的第一天
%% 一个文字%
使用举例:
SELECT
username,
FROM_UNIXTIME(create_time, "%Y-%m-%d") AS dat
FROM
`wp_user`
GROUP BY
dat
这样就能查出每天有哪些用户注册了。按天分组,你可以将数据导出后进行其他操作。
2.UNIX_TIMESTAMP()
UNIX_TIMESTAMP(date)
其中date可以是一个DATE字符串,一个DATETIME字符串,一个TIMESTAMP或者一个当地时间的YYMMDD或YYYMMDD格式的数字
用这个函数可以帮助我们在时间戳中筛选出某些天的数据。
比如说:
SELECT
username,
FROM_UNIXTIME(create_time, "%Y-%m-%d") AS dat
FROM
`wp_user`
WHERE
create_time >=UNIX_TIMESTAMP(''2017-11-29')
AND
create_time <UNIX_TIMESTAMP(''2017-11-30')
GROUP BY
dat
这个查询可以让我们查出29号那一天的用户注册记录。
善用这两个MYSQL函数可以帮助我们提高处理数据的效率。
为了测试GROUP BY 语句,我们创建两张表,并往表中添加数据
id TINYINT UNSIGNED AUTO_INCREMENT KEY,
depName VARCHAR(20) NOT NULL UNIQUE
);
INSERT department(depName) VALUES('开发部');
INSERT department(depName) VALUES('视频部');
INSERT department(depName) VALUES('教学部');
INSERT department(depName) VALUES('运营部');
CREATE TABLE IF NOT EXISTS employee(
id Int UNSIGNED AUTO_INCREMENT KEY,
username VARCHAR(20) NOT NULL,
age TINYINT UNSIGNED DEFAULT 18,
addr VARCHAR(50) NOT NULL DEFAULT '北京',
salary FLOAT(6,2) NOT NULL DEFAULT 0,
sex ENUM('男','女','保密'),
depId TINYINT UNSIGNED
);
INSERT employee(username,age,addr,salary,sex,depId) VALUES('张三','21','山东','5432.12','男',1);
INSERT employee(username,age,addr,salary,sex,depId) VALUES('李四','32','河北','6432.00','男',2);
INSERT employee(username,age,addr,salary,sex,depId) VALUES('王五','26','北京','5932.92','女',3);
INSERT employee(username,age,addr,salary,sex,depId) VALUES('赵六','32','上海','6232.14','男',4);
INSERT employee(username,age,addr,salary,sex,depId) VALUES('Mr Adword','55','美国','9432.99','男',4);
INSERT employee(username,age,addr,salary,sex,depId) VALUES('田七','19','北京','4932.92','保密',1);
INSERT employee(username,age,addr,salary,sex,depId) VALUES('孙八','62','上海','9932.14','男',2);
INSERT employee(username,age,addr,salary,sex,depId) VALUES('Mr lili','45','美国','9132.99','女',1);
CREATE TABLE IF NOT EXISTS provinces(
-> id TINYINT UNSIGNED AUTO_INCREMENT KEY,
-> pName VARCHAR(10) NOT NULL UNIQUE
-> );
INSERT provinces(pName) VALUES('山东'),('河北'),('北京'),('上海'),('美国');
mysql> SELECT * FROM department;+----+---------+| id | depName |+----+---------+| 1 | 开发部 || 3 | 教学部 || 2 | 视频部 || 4 | 运营部 |+----+---------+4 rows in set (0.06 sec)mysql> SELECT * FROM employee;+----+-----------+------+------+---------+------+-------+| id | username | age | addr | salary | sex | depId |+----+-----------+------+------+---------+------+-------+| 1 | 张三 | 21 | 山东 | 5432.12 | 男 | 1 || 2 | 李四 | 32 | 河北 | 6432.00 | 男 | 2 || 3 | 王五 | 26 | 北京 | 5932.92 | 女 | 3 || 4 | 赵六 | 32 | 上海 | 6232.14 | 男 | 4 || 5 | 田七 | 19 | 北京 | 4932.92 | 保密 | 1 || 6 | Mr Adword | 55 | 美国 | 9432.99 | 男 | 4 || 7 | 田七 | 19 | 北京 | 4932.92 | 保密 | 1 || 8 | 孙八 | 62 | 上海 | 9932.14 | 男 | 2 || 9 | Mr lili | 45 | 美国 | 9132.99 | 女 | 1 |+----+-----------+------+------+---------+------+-------+
mysql> SELECT * FROM provinces;+----+-------+| id | pName |+----+-------+| 4 | 上海 || 3 | 北京 || 1 | 山东 || 2 | 河北 || 5 | 美国 |+----+-------+
mysql> -- 按照性别分组mysql> SELECT * FROM employee GROUP BY sex;+----+----------+------+------+---------+------+-------+| id | username | age | addr | salary | sex | depId |+----+----------+------+------+---------+------+-------+| 1 | 张三 | 21 | 山东 | 5432.12 | 男 | 1 || 3 | 王五 | 26 | 北京 | 5932.92 | 女 | 3 || 5 | 田七 | 19 | 北京 | 4932.92 | 保密 | 1 |+----+----------+------+------+---------+------+-------+3 rows in set (0.05 sec)mysql> -- 按照部门编号分组mysql> SELECT * FROM employee GROUP BY depId;+----+----------+------+------+---------+------+-------+| id | username | age | addr | salary | sex | depId |+----+----------+------+------+---------+------+-------+| 1 | 张三 | 21 | 山东 | 5432.12 | 男 | 1 || 2 | 李四 | 32 | 河北 | 6432.00 | 男 | 2 || 3 | 王五 | 26 | 北京 | 5932.92 | 女 | 3 || 4 | 赵六 | 32 | 上海 | 6232.14 | 男 | 4 |+----+----------+------+------+---------+------+-------+4 rows in set (0.00 sec)mysql> -- 根据多个字段分组mysql> SELECT * FROM employee GROUP BY sex,depId;+----+----------+------+------+---------+------+-------+| id | username | age | addr | salary | sex | depId |+----+----------+------+------+---------+------+-------+| 1 | 张三 | 21 | 山东 | 5432.12 | 男 | 1 || 2 | 李四 | 32 | 河北 | 6432.00 | 男 | 2 || 4 | 赵六 | 32 | 上海 | 6232.14 | 男 | 4 || 9 | Mr lili | 45 | 美国 | 9132.99 | 女 | 1 || 3 | 王五 | 26 | 北京 | 5932.92 | 女 | 3 || 5 | 田七 | 19 | 北京 | 4932.92 | 保密 | 1 |+----+----------+------+------+---------+------+-------+
mysql> -- 按照性别分组,得到每组中人员的名称mysql> SELECT *,GROUP_CONCAT(username) FROM employee GROUP BY sex;+----+----------+------+------+---------+------+-------+-------------------------------+| id | username | age | addr | salary | sex | depId | GROUP_CONCAT(username) |+----+----------+------+------+---------+------+-------+-------------------------------+| 1 | 张三 | 21 | 山东 | 5432.12 | 男 | 1 | 张三,李四,赵六,Mr Adword,孙八 || 3 | 王五 | 26 | 北京 | 5932.92 | 女 | 3 | 王五,Mr lili || 5 | 田七 | 19 | 北京 | 4932.92 | 保密 | 1 | 田七,田七 |+----+----------+------+------+---------+------+-------+-------------------------------+
- COUNT():统计记录的数目
- SUM():求字段的和
- AVG():求字段的平均值
- MAX():求字段的最大值
- MIN():求字段的最小值
mysql> -- 统计员工表中员工数目,以及薪水的总和、最大值、最小值、平均值mysql> SELECT id AS '编号',username AS '用户名',COUNT(*) AS '员工总数',SUM(salary) AS '总薪水',MAX(salary) AS '最高薪水',MIN(salary) AS '最低薪水',AVG(salary) AS '平均薪水' FROM employee;*************************** 1. row ***************************编号: 1用户名: 张三员工总数: 9总薪水: 62393.14最高薪水: 9932.14最低薪水: 4932.92平均薪水: 6932.5711261 row in set (0.00 sec)
mysql> -- 按照性别分组,统计出每个组中年龄最大值、最小值,薪水最大值,每个组中的人数,人名,以及平均薪水。mysql> SELECT id,sex,MAX(age) AS max_age,MIN(age) AS min_age,MAX(salary) AS max_salary,COUNT(*) AS total_peo,AVG(salary)
AS avg_salary ,GROUP_CONCAT(username)FROM employee GROUP BY sex;
+----+------+---------+---------+------------+-----------+-------------+-------------------------------+
| id | sex | max_age | min_age | max_salary | total_peo | avg_salary | GROUP_CONCAT(username) |
+----+------+---------+---------+------------+-----------+-------------+-------------------------------+
| 1 | 男 | 62 | 21 | 9932.14 | 5 | 7492.278027 | 张三,李四,赵六,Mr Adword,孙八 |
| 3 | 女 | 45 | 26 | 9132.99 | 2 | 7532.955078 | 王五,Mr lili |
| 5 | 保密 | 19 | 19 | 4932.92 | 2 | 4932.919922 | 田七,田七 |
+----+------+---------+---------+------------+-----------+-------------+-------------------------------+
mysql> -- 按照性别分组,并找到分组后组中人数大于3的组
mysql> SELECT id,sex,COUNT(*) AS total_peo FROM employee GROUP BY sex HAVING COUNT(*)>3;+----+------+-----------+| id | sex | total_peo |+----+------+-----------+| 1 | 男 | 5 |+----+------+-----------+
MYSQL 二次筛选,统计,最大值,最小值,分组,靠拢的更多相关文章
- js求最大值最小值
比较数组中数值的大小是比较常见的操作,比较大小的方法有多种,比如可以使用自带的sort()函数,代码如下: <html> <head> <meta charset=&qu ...
- MySQL-分组查询(GROUP BY)及二次筛选(HAVING)
为了测试GROUP BY 语句,我们创建两张表,并往表中添加数据 -- 创建部门表 CREATE TABLE IF NOT EXISTS department( id TINYINT UNSIGNED ...
- Java8 Stream:2万字20个实例,玩转集合的筛选、归约、分组、聚合
点波关注不迷路,一键三连好运连连! 先贴上几个案例,水平高超的同学可以挑战一下: 从员工集合中筛选出salary大于8000的员工,并放置到新的集合里. 统计员工的最高薪资.平均薪资.薪资之和. 将员 ...
- MySQL单表查询 条件查询,分组
目录 1 where 条件查询 between like not in 2 group by 分组 聚合函数:max min sum avg count 3 having 过滤 4 distinct ...
- 第十二章——SQLServer统计信息(1)——创建和更新统计信息
原文:第十二章--SQLServer统计信息(1)--创建和更新统计信息 简介: 查询的统计信息: 目前为止,已经介绍了选择索引.维护索引.如果有合适的索引并实时更新统计信息,那么优化器会选择有用的索 ...
- mysql count group by统计条数方法
mysql count group by统计条数方法 mysql 分组之后如何统计记录条数? gourp by 之后的 count,把group by查询结果当成一个表再count一次select c ...
- java8 stream取出 最大值/最小值
注:转载请注明出处!!! 这里直接用取出多个对象中某个值 最大/最小 来进行举例 直接看代码 /** * 时间测试类 */ class TimeTest { private Date time; pu ...
- 转载:Centos7 从零编译Nginx+PHP+MySql 二
序言 这次玩次狠得.除了编译器使用yum安装,其他全部手动编译.哼~ 看似就Nginx.PHP.MySql三个东东,但是它们太尼玛依赖别人了. 没办法,想用它们就得老老实实给它们提供想要的东西. 首先 ...
- 第十二章——SQLServer统计信息(4)——在过滤索引上的统计信息
原文:第十二章--SQLServer统计信息(4)--在过滤索引上的统计信息 前言: 从2008开始,引入了一个增强非聚集索引的新功能--过滤索引(filter index),可以使用带有where条 ...
随机推荐
- c#-关于自动属性的思考
参考:c#-关于自动属性的思考 我的理解:自动属性跟 公有字段 一模一样,编程习惯而已.目前是这么认为的. 自动属性:public string Name{ get; set } 公有字段:pub ...
- 「NOIP2014」「LuoguP2296」 寻找道路
Description 在有向图 G 中,每条边的长度均为 1 ,现给定起点和终点,请你在图中找一条从起点到终点的路径,该路径满足以下条件: 路径上的所有点的出边所指向的点都直接或间接与终点连通. 在 ...
- 怎么解决Failed to load the JNI shared library
怎么解决Failed to load the JNIshared library 解决Failed to load the JNIshared library唯一的方法就是重新安装eclipse, ...
- 《Eye In-Painting with Exemplar Generative Adversarial Networks》论文阅读笔记
Abstract 基于conditional GAN使用隐藏在reference image中的exemplar information生成high-quality,personalized in-p ...
- ASP.NET Core MVC 2.x 全面教程_ASP.NET Core MVC 17. 基于Claim和Policy的授权 上
首先补一下昨天没有讲的东西 只有管理员才能访问UserController RoleController都加上这个角色 Cliam 不是管理员角色的用户访问 cliam是name个Value值的键值对 ...
- 【华为2016上机试题C++】最高分是多少
[编程题] 最高分是多少 时间限制:1秒 空间限制:65536K 老师想知道从某某同学当中,分数最高的是多少,现在请你编程模拟老师的询问.当然,老师有时候需要更新某位同学的成绩. 输入描述: 输入包括 ...
- Linux2.6 内核中结构体初始化(转载)
转自:http://hnniyan123.blog.chinaunix.net/uid-29917301-id-4989879.html 在Linux2.6版本的内核中,我们经常可以看到下面的结构体的 ...
- Python基础:一起来面向对象 (二) 之搜索引擎
实例 搜索引擎 一个搜索引擎由搜索器.索引器.检索器和用户接口四个部分组成 搜索器就是爬虫(scrawler),爬出的内容送给索引器生成索引(Index)存储在内部数据库.用户通过用户接口发出询问(q ...
- 知乎模拟登录 requests session
Python 3.5 # -*- coding: utf-8 -*- """ Created on Wed May 3 16:26:55 2017 @author: x- ...
- 轻松搞定JSONP跨域请求【转】,文章非常好!
http://blog.csdn.net/u014607184/article/details/52027879