Java实验--统计字母出现频率及其单词个数
本周的实验要求在之前实现统计单词的基础之上(可以见之前博客的统计单词的那个实验),对其进行修改成所需要的格式,统计字母出现频率的功能,并按照一定的格式把最终结果的用特定的格式在文本中显示出来
统计过程的实现并不太麻烦,在原来的基础上导入导出函数的基础上修改成通用的类型,统计单词的那一部分的单个字符读取那一段加上统计字母的情况,并加上判断把大小写字母统一起来。
同时,在统计单词的那里加上一个无用字母的表格。这样就可以统计有用意义的前n个最常用的单词了。
实验的代码如下所示:
package pipei;
//洪鼎淇 20173627 信1705-3
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.text.DecimalFormat;
import java.util.HashMap;
import java.util.Map;
//哈利波特单词统计 public class Pipei {
public static Map<String,Integer> map1=new HashMap<String,Integer>();
static int g_Wordcount[]=new int[27];
static int g_Num[]=new int[27]; static String []unUse=new String[] {
"it",
"in",
"to",
"of",
"the",
"and",
"that",
"for"
}; public static void main(String arg[]) {
daoruFiles("piao.txt","tongji");
traverseFolder2("C:\\Users\\Halo\\javatest\\pipei\\piao"); }
public static void daoruFiles(String a,String dc)
{
map1.clear();
try {
daoru(a);
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace(); }
String sz[];
Integer num[];
final int MAXNUM=10; //统计的单词出现最多的前n个的个数 for(int i=0;i<g_Wordcount.length;i++)
{
g_Wordcount[i]=0;
g_Num[i]=i;
} sz=new String[MAXNUM+1];
num=new Integer[MAXNUM+1];
Pipei pipei=new Pipei();
int account =1;
//Vector<String> ve1=new Vector<String>();
try {
daoru(a);
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
System.out.println("英文单词的出现情况如下:");
int g_run=0; for(g_run=0;g_run<MAXNUM+1;g_run++)
{
account=1;
for(Map.Entry<String,Integer> it : Pipei.map1.entrySet())
{
if(account==1)
{
sz[g_run]=it.getKey();
num[g_run]=it.getValue();
account=2;
}
if(account==0)
{
account=1;
continue;
}
if(num[g_run]<it.getValue())
{
sz[g_run]=it.getKey();
num[g_run]=it.getValue();
}
//System.out.println("英文单词: "+it.getKey()+" 该英文单词出现次数: "+it.getValue());
}
Pipei.map1.remove(sz[g_run]);
}
int g_count=1;
String tx1=new String();
String tx2=new String();
for(int i=0;i<g_run;i++)
{
if(sz[i]==null)
continue;
if(sz[i].equals(""))
continue;
tx1+="出现次数第"+(g_count)+"多的单词为:"+sz[i]+"\t\t\t出现次数: "+num[i]+"\r\n";
System.out.println("出现次数第"+(g_count)+"多的单词为:"+sz[i]+"\t\t\t出现次数: "+num[i]);
g_count++;
}
try {
daochu(tx1,dc+"2.txt");
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} //------------------------------
int temp=g_Wordcount[0];
int numtemp=0;
for(int i=0;i<26;i++)
{
for(int j=i;j<26;j++)
{
if(g_Wordcount[j]>g_Wordcount[i])
{
temp=g_Wordcount[i];
g_Wordcount[i]=g_Wordcount[j];
g_Wordcount[j]=temp;
numtemp=g_Num[i];
g_Num[i]=g_Num[j];
g_Num[j]=numtemp; }
}
}
int sum=0;
for(int i=0;i<26;i++)
{
sum+=g_Wordcount[i];
}
for(int i=0;i<26;i++)
{
char c=(char) ('a'+g_Num[i]);
tx2+=c+":"+String.format("%.2f%% \r\n", (double)g_Wordcount[i]/sum*100);
}
try {
daochu(tx2,dc+"1.txt");
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} //------------------------------ }
public static void daoru(String s) throws IOException
{ File a=new File(s);
FileInputStream b = new FileInputStream(a);
InputStreamReader c=new InputStreamReader(b,"UTF-8");
String string2=new String("");
while(c.ready())
{
char string1=(char) c.read();
if(WordNum(string1)>=0)
{
g_Wordcount[WordNum(string1)]+=1;
} //------------------------
if(!isWord(string1))
{
if(!isBaseWord(string2))
{
if(map1.containsKey(string2.toLowerCase()))
{
Integer num1=map1.get(string2.toLowerCase())+1;
map1.put(string2.toLowerCase(),num1);
}
else
{
Integer num1=1;
map1.put(string2.toLowerCase(),num1);
}
}
string2="";
}
else
{
if(isInitWord(string1))
{
string2+=string1;
}
}
}
if(!string2.isEmpty())
{
if(!isBaseWord(string2))
{
if(map1.containsKey(string2.toLowerCase()))
{
Integer num1=map1.get(string2.toLowerCase())+1;
map1.put(string2.toLowerCase(),num1);
}
else
{
Integer num1=1;
map1.put(string2.toLowerCase(),num1);
}
} string2="";
}
c.close();
b.close();
}
public static void daochu(String txt,String outfile) throws IOException
{
File fi=new File(outfile);
FileOutputStream fop=new FileOutputStream(fi);
OutputStreamWriter ops=new OutputStreamWriter(fop,"UTF-8");
ops.append(txt);
ops.close();
fop.close();
}
public static boolean isWord(char a)
{
if(a<='z'&&a>='a'||a<='Z'&&a>='A'||a=='\'')
return true;
return false;
}
public static boolean isInitWord(char a)
{
if(a<='z'&&a>='a'||a<='Z'&&a>='A'||a>'0'&&a<'9'||a=='\'')
return true;
return false;
}
public static boolean isBaseWord(String word)
{
for(int i=0;i<unUse.length;i++)
{
if(unUse[i].equals(word)||word.length()==1)
return true;
}
return false;
}
public static int WordNum(char a)
{
if(a<='z'&&a>='a')
return a-'a';
else if(a<='Z'&&a>='A')
return a-'A';
return -1;
}
//----递归文件夹
public static void traverseFolder2(String path) { File file = new File(path);
if (file.exists()) {
File[] files = file.listFiles();
if (null == files || files.length == 0) {
System.out.println("文件夹是空的!");
return;
} else {
for (File file2 : files) {
if (file2.isDirectory()) {
System.out.println("文件夹:" + file2.getAbsolutePath());
traverseFolder2(file2.getAbsolutePath());
} else {
System.out.println("文件:" + file2.getAbsolutePath());
String name=file2.getName();
daoruFiles(file2.getAbsolutePath(), file2.getParentFile()+"\\"+name.replace(".txt", "")+"tongji"); }
}
}
} else {
System.out.println("文件不存在!");
}
} }
将飘的整本小说及其分章节放在一个文件夹中,最终的实验结果如下:
tongji1位后缀的是文章字母构成比例(以整本飘的英文小说为例子):

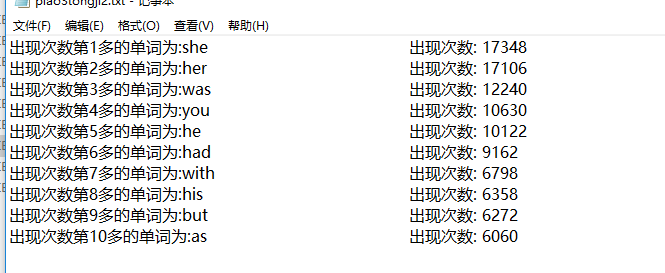
tongji2的实验结果是有意义单词的出现次数前10的排名:
对整本飘小说处理的时间级别在1秒以内,处理大文件及其多文件的过程在测试过程中没有出现问题。
Java实验--统计字母出现频率及其单词个数的更多相关文章
- JAVA实验--统计文章中单词的个数并排序
分析: 1)要统计单词的个数,就自己的对文章中单词出现的判断的理解来说是:当出现一个非字母的字符的时候,对前面的一部分字符串归结为单词 2)对于最后要判断字母出现的个数这个问题,我认为应该是要用到ma ...
- Java版统计文件中的每个单词出现次数
正则表达式之Pattern和Matcher,请参见转载博客 http://www.cnblogs.com/haodawang/p/5967219.html 代码实现: import java.i ...
- [Java]对字符串中的每一个单词个数进行统计
这是来自一道电面的题. 单词统计非常easy想到用Map来统计,于是想到了用HashMap. 可是我却没有想到用split来切割单词,想着用遍历字符的方式来推断空格.人家面试官就说了,假设单词之间不止 ...
- 初学Java 数组统计字母
public class CountLetterInArray { public static void main(String[] args) { char[] chars = createArra ...
- Java查找统计文中字母,单词
package io; import java.io.BufferedReader; import java.io.File; import java.io.FileOutputStream; imp ...
- 统计英文文章中各单词的频率,打印频率最高的十个单词(C语言实现)
一.程序思路及相关代码 首先打开文件,代码如下 FILE *fp; char fname[10]; printf("请输入要分析的文件名:\n"); scanf("%s ...
- 用java 集合和映射实现文章的单词数目统计
package 一_统计字母出现; import java.io.File; import java.io.FileNotFoundException; import java.util.HashMa ...
- Java实现 蓝桥杯VIP 算法训练 统计单词个数
题目描述 给出一个长度不超过200的由小写英文字母组 成的字母串(约定;该字串以每行20个字母的方式输入,且保证每行一定为20个).要求将此字母串分成k份 (1< k< =40),且每份中 ...
- C++读取文件统计单词个数及频率
1.Github链接 GitHub链接地址https://github.com/Zzwenm/PersonProject-C2 2.PSP表格 PSP2.1 Personal Software Pro ...
随机推荐
- codevs 2905 足球晋级
时间限制: 1 s 空间限制: 64000 KB 题目等级 : 黄金 Gold 题目描述 Description A市举行了一场足球比赛 一共有4n支队伍参加,分成n个小组(每小组4支队伍)进 ...
- Kali 2017.3开启VNC远程桌面登录
通过启用屏幕共享来开启远程桌面登录,开启后需要关闭encryption,否则会出现无法连接的情况.关闭encryption可以使用系统配置工具dconf来完成.所以先安装dconf-editor. 更 ...
- 微信小程序开发系列六:微信框架API的调用
微信小程序开发系列教程 微信小程序开发系列一:微信小程序的申请和开发环境的搭建 微信小程序开发系列二:微信小程序的视图设计 微信小程序开发系列三:微信小程序的调试方法 微信小程序开发系列四:微信小程序 ...
- QT+模态对话框与非模态对话框
#include "mainwindow.h" #include <QMenuBar> #include <QMenu> #include <QAct ...
- js实现复制input的value到剪切板
<button class="button-code button-copy">复制链接</button><script> $(".b ...
- In line copy and paste to system clipboard
On the Wiki Wiki Activity Random page Videos Photos Chat Community portal To do Contribute Watch ...
- 448. Find All Numbers Disappeared in an Array@python
Given an array of integers where 1 ≤ a[i] ≤ n (n = size of array), some elements appear twice and ot ...
- [LUOGU] P2886 [USACO07NOV]牛继电器Cow Relays
https://www.luogu.org/problemnew/show/P2886 给定无向连通图,求经过k条边,s到t的最短路 Floyd形式的矩阵乘法,同样满足结合律,所以可以进行快速幂. 离 ...
- django扩展User模型(model),profile
from django.contrib.auth.models import User # Create your models here. class Profile(models.Model): ...
- iPhone模拟定位(非越狱修改手机定位)
剩下的事情就是build一下到手机,那么,就可以看到神奇的效果! 本次带来一个简单又好玩的实用功能,比如定位装逼(共享定位非分享可选那种),又或者定位打卡之类,由于改变的是设备级别的定位,本设备所 ...