.net 大数据量,查找Where优化(List的Contains与Dictionary的ContainsKey的比较)
最近优化一个where查询条件,查询时间很慢,改为用Dictionary就很快了。
一、样例
假设:listPicsTemp 有100w条数据,pictures有1000w条数据。
使用第1段代码执行超过2分钟。
var listPicsTemp = new List<string>(); pictures = pictures.AsParallel().Where(d => listPicsTemp.Contains(d.Pic)).ToList();
使用第2段代码执行十几毫秒。
var listPicsTemp = new List<string>(); var dicPicsTemp = listPicsTemp.Where(d => d != null).Distinct().ToDictionary(d => d);//使用Dictionary类型,速度快很多 pictures = pictures.AsParallel().Where(d => dicPicsTemp.ContainsKey(d.Pic)).ToList();
二、为什么Dictionary这么快呢?查看了一下微软官方文档。
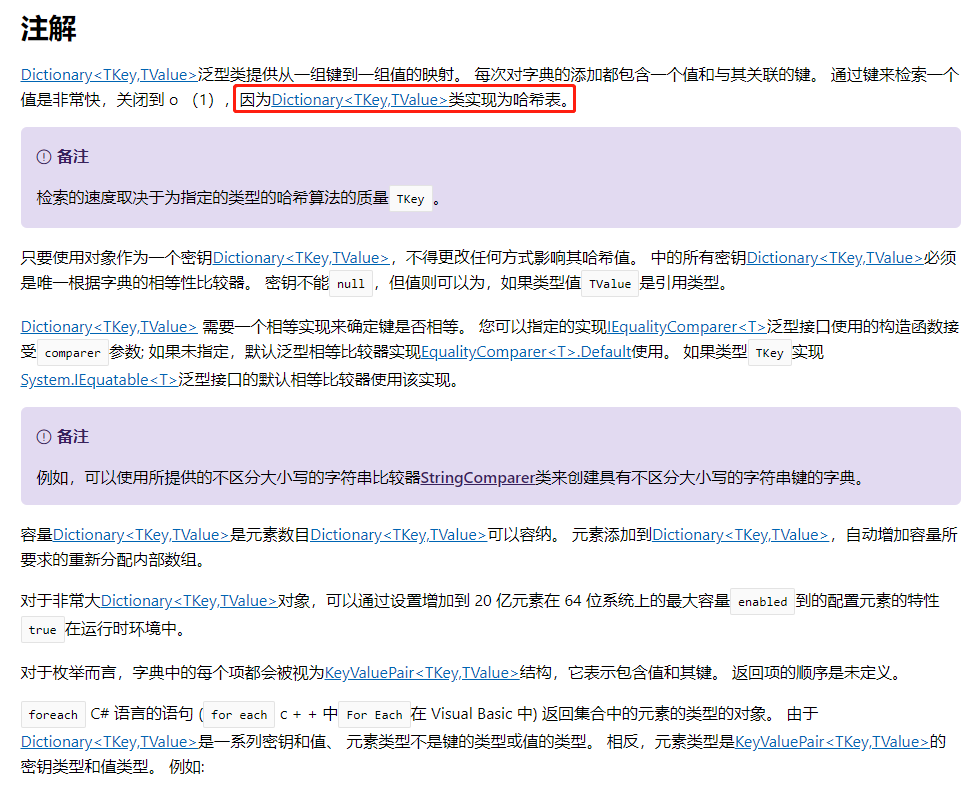

三、查看源码
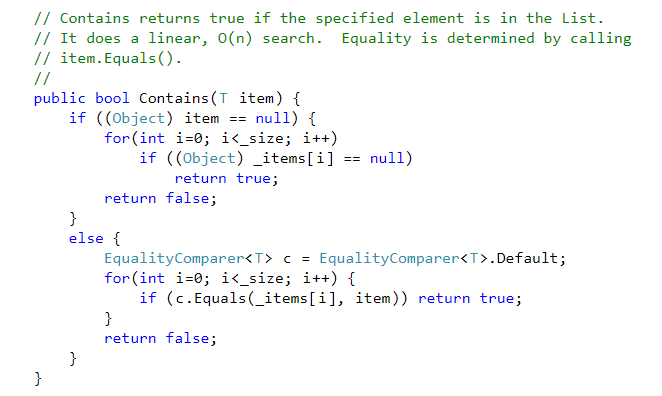
List的源码:https://referencesource.microsoft.com/#mscorlib/system/collections/generic/list.cs,cf7f4095e4de7646
List的Contains,是循环for查找的。
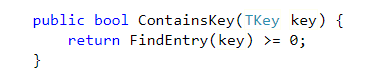
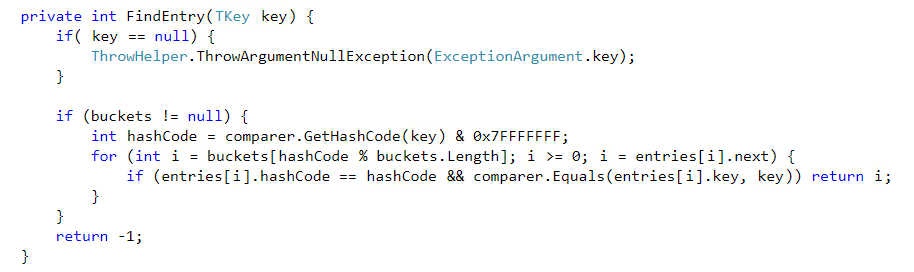
Dictionary的源码: https://referencesource.microsoft.com/#mscorlib/system/collections/generic/dictionary.cs,bcd13bb775d408f1
Dictionary的ContainsKey,是通过hash查找的。
四、小结:
1、Dictionary<TKey,TValue>类实现为哈希表。ContainsKey() 内部是通过Hash查找实现的,查询的时间复杂度是O(1)。所以,查询很快。(List的Contains是通过for查找的)
2、Dictionary不是线程安全的。(查看微软官方文档,确实能学到很多知识盲区。)
.net 大数据量,查找Where优化(List的Contains与Dictionary的ContainsKey的比较)的更多相关文章
- sql大数据量查询的优化技巧
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- MySQL大数据量分页性能优化
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- 任何抛开业务谈大数据量的sql优化都是瞎扯
周三去某在线旅游公司面试.被问到了一个关于数据量大的优化问题.问题是:一个主外键关联表,主表有一百万数据,外键关联表有一千万的数据,要求做一个连接. 本人接触过单表数据量最大的就是将近两亿行历史数据( ...
- Android, BaseAdapter 处理大数据量时的优化
Android优化 最常见的就是ListView, Gallery, GridView, ViewPager 的大数据优化 图片优化 访问网络的优化优化的原则: 数据延迟加载 分批加载 本地缓 ...
- mysql大数据量之limit优化
背景:当数据库里面的数据达到几百万条上千万条的时候,如果要分页的时候(不过一般分页不会有这么多),如果业务要求这么做那我们需要如何解决呢?我用的本地一个自己生产的一张表有五百多万的表,来进行测试,表名 ...
- 【MYSQL】mysql大数据量分页性能优化
转载地址: http://www.cnblogs.com/lpfuture/p/5772055.html https://www.cnblogs.com/shiwenhu/p/5757250.html ...
- 0113针对大数据量SUM的优化-思路
转自博客:http://bbs.csdn.net/topics/390426801?page=1 优化思路:无论如何你的结果都是要扫描全有表记录,而在456010记录中,的UserName的分布导致这 ...
- DB开发之大数据量高并发的数据库优化
一.数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实施之前,完备的数据库模型的设计是必须的. ...
- 大数据量高并发的数据库优化详解(MSSQL)
转载自:http://www.jb51.net/article/71041.htm 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能. ...
- 大数据量高并发访问SQL优化方法
保证在实现功能的基础上,尽量减少对数据库的访问次数:通过搜索参数,尽量减少对表的访问行数,最小化结果集,从而减轻网络负担:能够分开的操作尽量分开处理,提高每次的响应速度:在数据窗口使用SQL时,尽量把 ...
随机推荐
- [bzoj2055]80人环游世界[网络流,上下界网络流]
手动画了整张图,,算是搞懂了吧,, #include <bits/stdc++.h> #define INF 0x3f3f3f3f using namespace std; templat ...
- Hihocoder 1337 (splay)
Problem 平衡树 SBT 题目大意 维护一个序列,支持两种操作. 操作一:插入一个数. 操作二:询问第k小的数. 解题分析 ~~刷刷水题,再熟悉一下splay的基本操作. ps:哇咔咔,有连续四 ...
- 27、Java并发性和多线程-CAS(比较和替换)
以下内容转自http://ifeve.com/compare-and-swap/: CAS(Compare and swap)比较和替换是设计并发算法时用到的一种技术.简单来说,比较和替换是使用一个期 ...
- 【分享】迅为iTOP4412开发板-Android系统屏幕旋转设置
1.1概述 Android4.0,Androd4.4源代码能够编译成手机模式和平板模式,讯为iTop4412 开发平台 的Android系统默认编译为平板模式.客户须要依据自己的产品设计及应用环境,切 ...
- 利用scons构建project
scons有非常多相对于make构建系统的优秀特性,可是因为发展时间比較短如今的应用范围还是不太多,可以找到的资料也不是非常多. scons如今一大问题就是初始上手还是有点难度的,对于有python的 ...
- VFL演示样例
上篇文章向大家介绍了VFL的基本的语法点,假设对下面演示样例不熟的童鞋,能够前去參考.废话不多说.我们直接来看演示样例. 演示样例一 将五个大小同样.颜色不同的view排成一行,view间的间隔为15 ...
- IOS - 设置与帮助界面
设置与帮助 改动头像, 改动password, 移动客服, 帮助, 声明, 关于我们. 代码 // // IndexSetting600ViewController.h // SymptomCheck ...
- 从头认识java-13.7 什么时候使用泛型?
这一章节我们来讨论一下什么时候使用泛型? 答案:当你希望代码能够跨多个类型(不同的类型,不包括继承关系)工作的时候. 1.当没有确切类型的时候 以下是错误的代码: package com.ray.ch ...
- intellij idea 写 Helloworld
http://www.jetbrains.com/idea/webhelp/creating-and-running-your-first-java-application.html Creating ...
- Dynamics CRM Microsoft SQL Server 指定的数据库具有更高的版本号
在做NLB部署时遇到这么个问题,CRMAPP1安装的CRM版本号是6.1已经打了SP1补丁,而在CRMAPP2上的CRM安装包是6.0版本号.在选择连接现有部署后,最后一步检測就出了问题,例如以下图所 ...