利用scrapy获取抽屉新热榜的标题和内容以及新闻地址保存到本地
1、安装scrapy
pip3 install scrapy
2、打开terminal,cd 到想要创建程序的目录下
3、创建一个scrapy项目
在终端输入:scrapy startproject my_first_scrapy(项目名)
4、在终端输入:cd my_first_scrapy 进入到项目目录下
5、新建爬虫:
输入: scrapy genspider chouti chouti.com (chouti: 爬虫名称, chouti.com : 要爬取的网站的起始网址)
6、在pycharm中打开my_first_scrapy,就可以看到刚才创建的项目:

7、打开settings.py可以对项目相关参数进行设置,如设置userAgent:
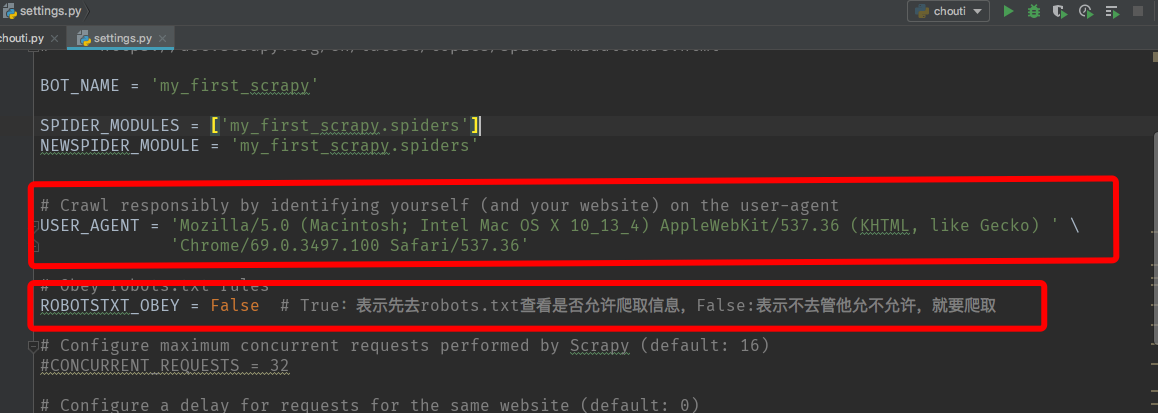
8、打开chouti.py编写代码:
- # -*- coding: utf-8 -*-
- """
- 获取抽屉新热榜的标题和内容以及新闻地址保存到本地
- """
- import scrapy
- from scrapy.http import Request
- from scrapy.http.response.html import HtmlResponse
- from ..items import MyFirstScrapyItem
- class ChoutiSpider(scrapy.Spider):
- name = 'chouti'
- allowed_domains = ['chouti.com']
- start_urls = ['http://chouti.com/']
- def parse(self, response):
- # print(response, type(response)) # <class 'scrapy.http.response.html.HtmlResponse'>
- # print(response.text)
- # 解析文本内容, 提取标题和简介,地址
- # 去页面中找id=content-list的div标签,再去这个div下找class=item的div
- items = response.xpath("//div[@id='content-list']/div[@class='item']")
- # "//"表示从html文件的根部开始找。"/"表示从儿子里面找。".//"表示相对的,及当前目录下的儿子里面找
- for item in items:
- # 当前目录下找class=part1的div标签,再找div标签下的a标签的文本信息text(),并且只取第一个
- # a标签后面可以加索引,表示取第几个a标签,如第一个:a[0]
- title = item.xpath(".//div[@class='part1']/a/text()").extract_first().strip() # 去掉标题两端的空格
- href = item.xpath(".//div[@class='part1']/a/@href").extract_first().strip() # 取href属性
- summary = item.xpath(".//div[@class='area-summary']/span/text()").extract_first()
- # print(1, title)
- # print(2, href)
- # print(3, summary)
- item_obj = MyFirstScrapyItem(title=title, href=href, summary=summary) # 实例化
- yield item_obj # 将数据交给pipelines
- # 获取页码
- page_list = response.xpath("//div[@id='dig_lcpage']//a/@href").extract()
- for url in page_list:
- url = "https://dig.chouti.com%s" % url
- yield Request(url=url, callback=self.parse) # 下载页面内容
9、打开items.py写代码:
- # -*- coding: utf-8 -*-
- # Define here the models for your scraped items
- #
- # See documentation in:
- # https://doc.scrapy.org/en/latest/topics/items.html
- import scrapy
- class MyFirstScrapyItem(scrapy.Item):
- # define the fields for your item here like:
- # name = scrapy.Field()
- # 规则化:将要持久化的数据转化为某种格式
- title = scrapy.Field()
- href = scrapy.Field()
- summary = scrapy.Field()
10、打开pipelines.py写代码:
- """
- 1、先去类中找from_crawler
- 有:执行且必须返回一个当前类的对象
- 没有:不执行,则去执行构造方法__init__(self)并返回一个对象
- 2、再去执行"对象.其他方法"
- """
- class MyFirstScrapyPipeline(object):
- def __init__(self, file_path):
- self.f = None
- self.file_path = file_path
- @classmethod
- def from_crawler(cls, crawler):
- """
- 初始化时,用于创建pipelines对象
- :param crawler:
- :return:
- """
- file_path = crawler.settings.get("CHOUTI_NEWS_PATH") # 存储文件的路径
- return cls(file_path)
- def open_spider(self, spider):
- """
- 打开文件
- :param spider:提交数据过来的爬虫对象
- :return:
- """
- self.f = open(self.file_path, "a+", encoding="utf-8")
- def process_item(self, item, spider):
- """
- :param item: 爬虫中yield过来的item对象
- :param spider:提交数据过来的爬虫对象
- :return:
- """
- self.f.write(item["href"] + "\n")
- self.f.flush() # 将内容强刷到硬盘进行保存
- return item
- def close_spider(self, spider):
- """
- 关闭文件
- :param spider:提交数据过来的爬虫对象
- :return:
- """
- self.f.close()
11、在settings.py中找到 ITEM_PIPELINES进行设置,并设置存储下载的新闻存储的文件路径:


12、运行爬虫项目,在终端输入:
scrapy crawl chouti(会打印日志) 或者 scrapy crawl chouti --nolog (不打印日志)
利用scrapy获取抽屉新热榜的标题和内容以及新闻地址保存到本地的更多相关文章
- 【IOS】模仿"抽屉新热榜"动态启动页YFSplashScreen
IOS最好要设置系统默认启动页面,不然进入应用就会突然闪现黑色画面 下图是我们要实现的效果: 总体思路:设置一个系统默认启动页面,在进入didFinishLaunchingWithOptions时, ...
- Python之路【第二十篇】:python项目之旧版抽屉新热榜
旧版抽屉新热榜 代码如下: <!DOCTYPE html> <html lang="en"> <head> <meta charset=& ...
- 【Python之路】特别篇--抽屉新热榜
登陆与注册 注册功能: 流程: 填写用户名,邮箱,获取邮箱验证码,填入密码 单击<下一步>按钮,完成注册! 1.获取邮箱验证码(具体步骤分析): 1.利用ajax 往后台传入邮箱, 2.后 ...
- 利用scrapy爬取腾讯的招聘信息
利用scrapy框架抓取腾讯的招聘信息,爬取地址为:https://hr.tencent.com/position.php 抓取字段包括:招聘岗位,人数,工作地点,发布时间,及具体的工作要求和工作任务 ...
- 用python实现的百度新歌榜、热歌榜下载器
首先声明,本工具仅仅为学习之用,不涉及版权问题,因为百度音乐里面的歌曲本身是可以下载的,而且现在百度也提供了”百度音乐播放器”,可以通过这个工具进行批量下载. 我当时做这个工具的时候,百度还没有提供” ...
- 了不起的 Deno:带你极速获取各大平台今日热榜
摘要:Deno 是一个 JavaScript/TypeScript 的运行时,默认使用安全环境执行代码,有着卓越的开发体验. 有人的地方就有江湖,有江湖的地方就有争论.前些天,继<[译]为什么如 ...
- (转)利用libcurl获取新浪股票接口, ubuntu和openwrt实验成功(三)
1. 利用 CURLOPT_WRITEFUNCTION 设置回调函数, 利用 CURLOPT_WRITEDATA 获取数据指针 官网文档如下 CALLBACK OPTIONS CURLOPT_WRI ...
- 全网趣味网站分享:今日热榜/Pixiv高级搜索/win10激活工具/songtaste复活/sharesome汤不热替代者
1.回形针手册 由科普类视频节目“回形针PaperClip”近期提出的一个实用百科工具计划,计划名称是回形针手册. 包含了当下科技,农业等等各行各业的各种相关信息,计划刚刚开始! 关于回形针手册的详细 ...
- 利用scrapy和MongoDB来开发一个爬虫
今天我们利用scrapy框架来抓取Stack Overflow里面最新的问题(),并且将这些问题保存到MongoDb当中,直接提供给客户进行查询. 安装 在进行今天的任务之前我们需要安装二个框架,分别 ...
随机推荐
- AtCoder Grand Contest 012 B
B - Splatter Painting Time limit : 2sec / Memory limit : 256MB Score : 700 points Problem Statement ...
- Query on a tree IV SPOJ - QTREE4
https://vjudge.net/problem/SPOJ-QTREE4 点分就没有一道不卡常的? 卡常记录: 1.把multiset换成手写的带删除堆(套用pq)(作用很大) 2.把带删除堆里面 ...
- 记一次有关spark动态资源分配和消息总线的爬坑经历
问题: 线上的spark thriftserver运行一段时间以后,ui的executor页面上显示大量的active task,但是从job页面看,并没有任务在跑.此外,由于在yarn mode下, ...
- Unity中所有特殊的文件夹
1. 隐藏文件夹以.开头的文件夹会被Unity忽略.在这种文件夹中的资源不会被导入,脚本不会被编译.也不会出现在Project视图中.2. Standard Assets在这个文件夹中的脚本最先被编译 ...
- AJPFX关于Class类和Class类实例
Java程序中的各个Java类属于同一类事物,描述这类事物的Java类就是Class类.对比提问:众多的人用一个什么类表示?众多的Java类用一个什么类表示?人 PersonJava类 Cla ...
- Git之master ->! [rejected] master (non-fast-forward)
出现这个情况可能是在克隆项目的时候强制关闭或者是在pull的时候强制关闭 运行命令:git pull --rebase origin master 然后就可以 git push origin mast ...
- 【学习笔记】深入理解js原型和闭包(3)——prototype原型
既typeof之后的另一位老朋友! prototype也是我们的老朋友,即使不了解的人,也应该都听过它的大名.如果它还是您的新朋友,我估计您也是javascript的新朋友. 在咱们的第一节(深入理解 ...
- 生产线上的Nginx如何添加未编译安装模块
正在生产线上跑着web前端是nginx+tomcat,现在有这样一个需求,需要对网站的单品页面和列表页设置缓存,不同的页面设置不同的缓存,但是由于开始没有安装ngx_cache_purge这个模块,现 ...
- 实现流水灯以间隔500ms的时间闪烁(系统定时器SysTick实现的精确延时)
/** ****************************************************************************** * @file main.c * ...
- 原创:PHP编译安装配置参数说明
--prefix=/application/php-5.5.32 \ #指定PHP的安装路径 --with-mysql=/application/mysql/ \ ...