mysql/Java服务端对emoji的支持 专题
关于utf8不支持emoji是因为emoji是用4个字节存储的字符,而mysql的utf8只能存储1-3个字节的字符。那就存不了呗
需要更改的地方:
(1)Mysql服务器client,mysql,mysqld中需要显式指定字符集为utf8mb4
(2)在(1)的服务器上创建的db,需要为utf8mb4字符集,COLLATE为utf8mb4_unicode_ci 或 utf8mb4_general_ci
(3) 在(2)的db中创建table和存放emoji字段的字符集为utf8mb4,collate为为utf8mb4_unicode_ci 或 utf8mb4_general_ci
Tips:
utf8mb4_unicode_ci 或 utf8mb4_general_ci之间的区别
Mysql 5.1中文手册中关于utf8_unicode_ci与utf8_general_ci的说明:
当前,utf8_unicode_ci校对规则仅部分支持Unicode校对规则算法。一些字符还是不能支持。并且,不能完全支持组合的记号。这主要影响越南和俄罗斯的一些少数民族语言,如:Udmurt 、Tatar、Bashkir和Mari。
utf8_unicode_ci的最主要的特色是支持扩展,即当把一个字母看作与其它字母组合相等时。例如,在德语和一些其它语言中‘ß'等于‘ss'。
utf8_general_ci是一个遗留的 校对规则,不支持扩展。它仅能够在字符之间进行逐个比较。这意味着utf8_general_ci校对规则进行的比较速度很快,但是与使用utf8_unicode_ci的 校对规则相比,比较正确性较差)。
例如,使用utf8_general_ci和utf8_unicode_ci两种 校对规则下面的比较相等:
Ä = A
Ö = O
Ü = U
两种校对规则之间的区别是,对于utf8_general_ci下面的等式成立:
ß = s
但是,对于utf8_unicode_ci下面等式成立:
ß = ss
对于一种语言仅当使用utf8_unicode_ci排序做的不好时,才执行与具体语言相关的utf8字符集 校对规则。例如,对于德语和法语,utf8_unicode_ci工作的很好,因此不再需要为这两种语言创建特殊的utf8校对规则。
utf8_general_ci也适用与德语和法语,除了‘ß'等于‘s',而不是‘ss'之外。
如果你的应用能够接受这些,那么应该使用utf8_general_ci,因为它速度快。否则,使用utf8_unicode_ci,因为它比较准确。
小结:
utf8_unicode_ci和utf8_general_ci对中、英文来说没有实质的差别。
utf8_general_ci校对速度快,但准确度稍差。
utf8_unicode_ci准确度高,但校对速度稍慢。
如果你的应用有德语、法语或者俄语,请一定使用utf8_unicode_ci。一般用utf8_general_ci就够了
CI和BIN的区别:
ci是 case insensitive, 即 "大小写不敏感", a 和 A 会在字符判断中会被当做一样的;
bin 是二进制, a 和 A 会别区别对待.
http://www.cnblogs.com/softidea/p/5668782.html
具体操作如下:
CREATE DATABASE `test` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci ;
mysql> create database daily default character set utf8mb4 collate utf8mb4_unicode_ci;
原文:http://blog.csdn.net/woslx/article/details/49685111
utf-8编码可能2个字节、3个字节、4个字节的字符,但是MySQL的utf8编码只支持3字节的数据,而移动端的表情数据是4个字节的字符。如果直接往采用utf-8编码的数据库中插入表情数据,Java程序中将报SQL异常:
java.sql.SQLException: Incorrect string value: ‘\xF0\x9F\x92\x94’ for column ‘name’ at row 1
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1073)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3593)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3525)
at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:1986)
at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2140)
at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2620)
at com.mysql.jdbc.StatementImpl.executeUpdate(StatementImpl.java:1662)
at com.mysql.jdbc.StatementImpl.executeUpdate(StatementImpl.java:1581)
可以对4字节的字符进行编码存储,然后取出来的时候,再进行解码。但是这样做会使得任何使用该字符的地方都要进行编码与解码。
utf8mb4编码是utf8编码的超集,兼容utf8,并且能存储4字节的表情字符。
采用utf8mb4编码的好处是:存储与获取数据的时候,不用再考虑表情字符的编码与解码问题。
更改数据库的编码为utf8mb4:
1. MySQL的版本
utf8mb4的最低mysql版本支持版本为5.5.3+,若不是,请升级到较新版本。
MySQL在 5.5.3 之后增加了 utf8mb4 字符编码,mb4即 most bytes 4。简单说 utf8mb4 是 utf8 的超集并完全兼容utf8,能够用四个字节存储更多的字符。
但抛开数据库,标准的 UTF-8 字符集编码是可以用 1~4 个字节去编码21位字符,这几乎包含了是世界上所有能看见的语言了。
然而在MySQL里实现的utf8最长使用3个字节,也就是只支持到了 Unicode 中的 基本多文本平面 (U+0000至U+FFFF),包含了控制符、拉丁文,中、日、韩等绝大多数国际字符,
但并不是所有,最常见的就算现在手机端常用的表情字符 emoji和一些不常用的汉字,如 “墅” ,这些需要四个字节才能编码出来。
http://www.zuimoban.com/jiaocheng/mysql/11256.html
2. MySQL驱动
5.1.34可用,最低不能低于5.1.13
3.修改MySQL配置文件
修改mysql配置文件my.cnf(windows为my.ini)
【
how to know mysql my.cnf location
/etc/my.cnf
/etc/mysql/my.cnf
$MYSQL_HOME/my.cnf
[datadir]/my.cnf
~/.my.cnf
You can actually ask MySQL to show you the list of all locations where it searches for my.cnf (or my.ini on Windows). It is not an SQL command though. Rather, execute: $ mysqld --help --verbose
In the very first lines you will find a message with a list of all my.cnf locations it looks for. On my machine it is: Default options are read from the following files in the given order:
/etc/my.cnf
/etc/mysql/my.cnf
/usr/etc/my.cnf
~/.my.cnf
Or, on Windows: Default options are read from the following files in the given order:
C:\Windows\my.ini
C:\Windows\my.cnf
C:\my.ini
C:\my.cnf
C:\Program Files\MySQL\MySQL Server 5.5\my.ini
C:\Program Files\MySQL\MySQL Server 5.5\my.cnf
https://stackoverflow.com/questions/2482234/how-to-know-mysql-my-cnf-location
】
my.cnf一般在etc/mysql/my.cnf位置。找到后请在以下三部分里添加如下内容:
[client]
default-character-set = utf8mb4
[mysql]
default-character-set = utf8mb4
[mysqld]
character-set-client-handshake = FALSE
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
init_connect='SET NAMES utf8mb4'
4. 重启数据库,检查变量
SHOW VARIABLES WHERE Variable_name LIKE 'character_set_%' OR Variable_name LIKE 'collation%';
| Variable_name | Value |
|---|---|
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8mb4 |
| character_set_server | utf8mb4 |
| character_set_system | utf8 |
| collation_connection | utf8mb4_unicode_ci |
| collation_database | utf8mb4_unicode_ci |
| collation_server | utf8mb4_unicode_ci |
collation_connection 、collation_database 、collation_server是什么没关系。
但必须保证
| 系统变量 | 描述 |
|---|---|
| character_set_client | (客户端来源数据使用的字符集) |
| character_set_connection | (连接层字符集) |
| character_set_database | (当前选中数据库的默认字符集) |
| character_set_results | (查询结果字符集) |
| character_set_server | (默认的内部操作字符集) |
这几个变量必须是utf8mb4。
可以保存utf8-mb4的一个截图:

mysql> SHOW VARIABLES WHERE Variable_name LIKE 'character_set_%' OR Variable_name LIKE 'collation%';
+--------------------------+-----------------------------+
| Variable_name | Value |
+--------------------------+-----------------------------+
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8mb4 |
| character_set_server | utf8mb4 |
| character_set_system | utf8 |
| character_sets_dir | /data/mysql/share/charsets/ |
| collation_connection | utf8mb4_general_ci |
| collation_database | utf8mb4_unicode_ci |
| collation_server | utf8mb4_unicode_ci |
+--------------------------+-----------------------------+
11 rows in set (0.20 sec)
5. 数据库连接的配置
数据库连接参数中:
characterEncoding=utf8会被自动识别为utf8mb4,也可以不加这个参数,会自动检测。
而autoReconnect=true是必须加上的。
6. 将数据库和已经建好的表也转换成utf8mb4
更改数据库编码:ALTER DATABASE caitu99 CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
更改表编码:ALTER TABLE TABLE_NAME CONVERT TO CHARACTER SET utf8mb4 COLLATEutf8mb4_general_ci;
如有必要,还可以更改列的编码
http://www.cnblogs.com/softidea/p/6135237.html
更改好后的字符集(status命令查看):

通过上面配置更改和设置。emoji字符串已经可以存储到mysql中的字段了。但使用navicat查看时,却是这个样子: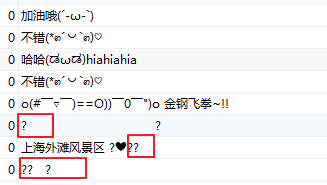
上面 的"?"在前端展示时是正常的
为什么看到emoji这种4字节字符,是这个样子呢?
因此:
最近遇到了一个很让人纠结的问题:emoji表情在使用的过程中,会莫名其妙的消失,或者变成乱码,同时数据库用utf8mb4来存储,但是也出现了问题,冷备过后,导入进库的时候,变成了不可见字符,神奇的消失了!查阅了网上的解决办法,没有找到相应的解决方案,于是决定自己研究unicode,并且处理,发现了几个主要知识点:unicode被逻辑分为了17个Plane,每个Plane存65536个代码点。而java的 char最多只有2字节(16 bit),也就是说,他最多只能存储65536个字符,而那么问题来了,大于0x10000的这些字符怎么处理? 很好这个办法,java也用了一个比较委婉的办法来解决,那么就是Character.codePoint()用int来存储。直接看代码吧,代码中有注释解释:
import org.eclipse.jetty.util.StringUtil;
import com.google.common.base.Strings;
import com.google.common.hash.Hashing; /**
* <pre>
* 本类的主要功能是将带有emoji的字符串,格式化成unicode字符串,并且提供可见unicode字符反解成emoji字符
*
*
* 相关识知点:
* <b>
* Unicode平面,
* BMP的字符可以使用charAt(index)来处理,计数可以使用length()
* 其它平面字符,需要用codePointAt(index),计数可以使用codePointCount(0,str.lenght())</b>
*
* Unicode可以逻辑分为17平面(Plane),每个平面拥有65536( = 216)个代码点,虽然目前只有少数平面被使
* 用。
* 平面0 (0000–FFFF): 基本多文种平面(Basic Multilingual Plane, BMP).
* 平面1 (10000–1FFFF): 多文种补充平面(Supplementary Multilingual Plane, SMP).
* 平面2 (20000–2FFFF): 表意文字补充平面(Supplementary Ideographic Plane, SIP).
* 平面3 (30000–3FFFF): 表意文字第三平面(Tertiary Ideographic Plane, TIP).
* 平面4 to 13 (40000–DFFFF)尚未使用
* 平面14 (E0000–EFFFF): 特别用途补充平面(Supplementary Special-purpose Plane, SSP)
* 平面15 (F0000–FFFFF)保留作为私人使用区(Private Use Area, PUA)
* 平面16 (100000–10FFFF),保留作为私人使用区(Private Use Area, PUA)
*
* 参考:
* 维基百科: http://en.wikipedia.org/wiki/Emoji
* GITHUB: http://punchdrunker.github.io/iOSEmoji/
* 杂项象形符号:1F300-1F5FF
* 表情符号:1F600-1F64F
* 交通和地图符号:1F680-1F6FF
* 杂项符号:2600-26FF
* 符号字体:2700-27BF
* 国旗:1F100-1F1FF
* 箭头:2B00-2BFF 2900-297F
* 各种技术符号:2300-23FF
* 字母符号: 2100–214F
* 中文符号: 303D 3200–32FF 2049 203C
* Private Use Area:E000-F8FF;
* High Surrogates D800..DB7F;
* High Private Use Surrogates DB80..DBFF
* Low Surrogates DC00..DFFF D800-DFFF E000-F8FF
* 标点符号:2000-200F 2028-202F 205F 2065-206F
* 变异选择器:IOS独有 FE00-FE0F
* </pre>
*/
public class EmojiCharacterUtil { // 转义时标识
private static final char unicode_separator = '&';
private static final char unicode_prefix = 'u';
private static final char separator = ':'; private static boolean isEmojiCharacter(int codePoint) {
return (codePoint >= 0x2600 && codePoint <= 0x27BF) // 杂项符号与符号字体
|| codePoint == 0x303D
|| codePoint == 0x2049
|| codePoint == 0x203C
|| (codePoint >= 0x2000 && codePoint <= 0x200F)//
|| (codePoint >= 0x2028 && codePoint <= 0x202F)//
|| codePoint == 0x205F //
|| (codePoint >= 0x2065 && codePoint <= 0x206F)//
/* 标点符号占用区域 */
|| (codePoint >= 0x2100 && codePoint <= 0x214F)// 字母符号
|| (codePoint >= 0x2300 && codePoint <= 0x23FF)// 各种技术符号
|| (codePoint >= 0x2B00 && codePoint <= 0x2BFF)// 箭头A
|| (codePoint >= 0x2900 && codePoint <= 0x297F)// 箭头B
|| (codePoint >= 0x3200 && codePoint <= 0x32FF)// 中文符号
|| (codePoint >= 0xD800 && codePoint <= 0xDFFF)// 高低位替代符保留区域
|| (codePoint >= 0xE000 && codePoint <= 0xF8FF)// 私有保留区域
|| (codePoint >= 0xFE00 && codePoint <= 0xFE0F)// 变异选择器
|| codePoint >= 0x10000; // Plane在第二平面以上的,char都不可以存,全部都转
} /**
* 将带有emoji字符的字符串转换成可见字符标识
*/
public static String escape(String src) {
if (src == null) {
return null;
}
int cpCount = src.codePointCount(0, src.length());
int firCodeIndex = src.offsetByCodePoints(0, 0);
int lstCodeIndex = src.offsetByCodePoints(0, cpCount - 1);
StringBuilder sb = new StringBuilder(src.length());
for (int index = firCodeIndex; index <= lstCodeIndex;) {
int codepoint = src.codePointAt(index);
if (isEmojiCharacter(codepoint)) {
String hash = Integer.toHexString(codepoint);
sb.append(unicode_separator).append(hash.length()).append(unicode_prefix).append(separator).append(hash);
} else {
sb.append((char) codepoint);
}
}
return sb.toString();
} /** 解析可见字符标识字符串 */
public static String reverse(String src) {
// 查找对应编码的标识位
if (src == null) {
return null;
}
StringBuilder sb = new StringBuilder(src.length());
char[] sourceChar = src.toCharArray();
int index = 0;
while (index < sourceChar.length) {
if (sourceChar[index] == unicode_separator) {
if (index + 6 >= sourceChar.length) {
sb.append(sourceChar[index]);
index++;
continue;
}
// 自已的格式,与通用unicode格式不能互转
if (sourceChar[index + 1] >= '4' && sourceChar[index + 1] <= '6' && sourceChar[index + 2] == unicode_prefix && sourceChar[index + 3] == separator) {
int length = Integer.parseInt(String.valueOf(sourceChar[index + 1]));
char[] hexchars = new char[length]; // 创建一个4至六位的数组,来存储uncode码的HEX值
for (int j = 0; j < length; j++) {
char ch = sourceChar[index + 4 + j];// 4位识别码
if ((ch >= '0' && ch <= '9') || (ch >= 'a' && ch <= 'f')) {
hexchars[j] = ch; } else { // 字符范围不对
sb.append(sourceChar[index]);
index++;
break;
}
}
sb.append(Character.toChars(Integer.parseInt(new String(hexchars), 16)));
index += (4 + length);// 4位前缀+4-6位字符码
} else if (sourceChar[index + 1] == unicode_prefix) { // 通用字符的反转
// 因为第二平面之上的,已经采用了我们自己转码格式,所以这里是固定的长度4
char[] hexchars = new char[4];
for (int j = 0; j < 4; j++) {
char ch = sourceChar[index + 2 + j]; // 两位识别码要去掉
if ((ch >= '0' && ch <= '9') || (ch >= 'a' && ch <= 'f')) {
hexchars[j] = ch; // 4位识别码
} else { // 字符范围不对
sb.append(sourceChar[index]);
index++;
break;
}
sb.append(Character.toChars(Integer.parseInt(String.valueOf(hexchars), 16)));
index += (2 + 4);// 2位前缀+4位字符码
}
} else {
sb.append(sourceChar[index]);
index++;
continue;
}
} else {
sb.append(sourceChar[index]);
index++;
continue;
}
} return sb.toString();
} public static String filter(String src) {
if (src == null) {
return null;
}
int cpCount = src.codePointCount(0, src.length());
int firCodeIndex = src.offsetByCodePoints(0, 0);
int lstCodeIndex = src.offsetByCodePoints(0, cpCount - 1);
StringBuilder sb = new StringBuilder(src.length());
for (int index = firCodeIndex; index <= lstCodeIndex;) {
int codepoint = src.codePointAt(index);
if (!isEmojiCharacter(codepoint)) {
System.err.println("codepoint:" + Integer.toHexString(codepoint));
sb.append((char) codepoint);
}
index += ((Character.isSupplementaryCodePoint(codepoint)) ? 2 : 1); }
return sb.toString();
}
}
http://www.cnblogs.com/hahahjx/p/4522913.html
其中UTF-8编码规则阅读自《十分钟搞清字符集和字符编码》,字节与十六进制的转换参考自《Java中byte与16进制字符串的互相转换》。
另外一个解决策略,把emoji字符替换掉:
【Java】如何检测、替换4个字节的utf-8编码(此范围编码包含emoji表情)
http://www.cnblogs.com/nick-huang/p/5507262.html
https://github.com/vdurmont/emoji-java 【百度输入法上面的好多图标,并没有被EmojiParser.parseToUnicode替换掉】
乱码
推荐大家看 深入MySQL字符集设置 ,区分检查client端、server端的编码;最简单暴力的方式,是在所有的环节都显式明确的指定相同的编码。
比如使用python的MySQLdb连接MySQL时默认的charset是latin1,需要自己指定charset=’utf8′,即使是在服务器端的init-connect=’SET NAMES utf8′,MySQLdb也会使用latin1覆盖该选项;可以参照这篇文章;
emoji表情与utf8mb4
关于emoji表情的话mysql的utf8是不支持,需要修改设置为utf8mb4,才能支持, 详细emoji表情与utf8mb4的关系 。
MYSQL 5.5 之前, UTF8 编码只支持1-3个字节,只支持BMP这部分的unicode编码区, BMP是从哪到哪,到 http://en.wikipedia.org/wiki/Mapping_of_Unicode_characters 这里看,基本就是0000~FFFF这一区。 从MYSQL5.5开始,可支持4个字节UTF编码utf8mb4,一个字符最多能有4字节,所以能支持更多的字符集。
utf8mb4 is a superset of utf8
utf8mb4兼容utf8,且比utf8能表示更多的字符。
修改方法
服务器端
修改数据库配置文件/etc/my.cnf
character-set-server=utf8mb4
collation_server=utf8mb4_unicode_ci
重启MySQL(按照官方文档,这两个选项都是可以动态设置的,但是实际的经验是Server必须重启一下)
已有的表修改编码为utf8mb4
ALTER TABLEtbl_nameCONVERT TO CHARACTER SETcharset_name;
使用下面这个语句只是修改了表的default编码
ALTER TABLE etape_prospection CHARSET=utf8;
客户端
jdbc的连接字符串不支持utf8mb4,这个 这种方式 来解决的,如果服务器端设置了character_set_server=utf8mb4,则客户端会自动将传过去的utf-8视作utf8mb4。
- Connector/J did not support
utf8mb4for servers 5.5.2 and newer.Connector/J now auto-detects servers configured with
character_set_server=utf8mb4or treats the Java encodingutf-8passed usingcharacterEncoding=...asutf8mb4in theSET NAMES=calls it makes when establishing the connection. (Bug #54175)
其他的client端,比如php、python需要看下client是否支持,如果不能在连接字符串中指定的话,可以在获取连接之后,执行”set names utf8mb4″来解决这个问题;
因为utf8mb4是utf8的超集,理论上即使client修改字符集为utf8mb4,也会不会对已有的utf8编码读取产生任何问题。
http://www.tuicool.com/articles/zAnEV3?spm=5176.100239.blogcont6791.9.f4a57Y
摘要: 问题描述: 对于IOS开发来说,iOS项目因为需要用户文本的存储,自然就遇到了emoji等表情符号如何被mysql DB支持的问题 如果UTF8字符集且是Java服务器的话,当存储含有emoji表情时,会抛出类似如下异常: java.sql.SQLException: Incorrect str...
问题描述:
对于IOS开发来说,iOS项目因为需要用户文本的存储,自然就遇到了emoji等表情符号如何被mysql DB支持的问题
如果UTF8字符集且是Java服务器的话,当存储含有emoji表情时,会抛出类似如下异常:
java.sql.SQLException: Incorrect string value: '\xF0\x9F\x92\x94' for column 'name' at row 1
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1073)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3593)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3525)
at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:1986)
at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2140)
at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2620)
at com.mysql.jdbc.StatementImpl.executeUpdate(StatementImpl.java:1662)
at com.mysql.jdbc.StatementImpl.executeUpdate(StatementImpl.java:1581)
这就是字符集不支持的异常。因为UTF-8编码有可能是两个、三个、四个字节,其中Emoji表情是4个字节,而Mysql的utf8编码最多3个字节,所以导致了数据插不进去。
升级前需要考虑的问题:
如果你的项目要进行移动产品的用户文本的存储,将你的DB字符集从UTF8/GBK等传统字符集升级到utf8mb4将是势在必行。你可以通过应用层面转换emoji等特殊字符,以达到原DB的兼容,我认为可行,但是你可能走了弯路。
utf8mb4作为utf8的super set,完全向下兼容,所以不用担心字符的兼容性问题。切换中需要顾虑的主要影响是mysql需要重新启动(虽然mysql官方文档说可以动态修改配置,但是经过数次测试,还是需要重启才可生效),对于业务可用率的影响是需要考虑的大问题,这里就暂时不展开讨论了。
升级步骤:
1.utf8mb4的最低mysql版本支持版本为5.5.3+,若不是,请升级到较新版本。
mysql版本查看命令请看:查看mysql版本的四种方法;mysql安装步骤请看:Linux中升级Mysql到Mysql最新版本的方法
2.修改database、table和column字符集。参考以下语句:
ALTER DATABASE database_name CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
ALTER TABLE table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
ALTER TABLE table_name CHANGE column_name VARCHAR(191) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
3.修改mysql配置文件my.cnf(windows为my.ini)
my.cnf一般在etc/mysql/my.cnf位置。找到后请在以下三部分里添加如下内容:
[client]
default-character-set = utf8mb4
[mysql]
default-character-set = utf8mb4
[mysqld]
character-set-client-handshake = FALSE
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
init_connect='SET NAMES utf8mb4'
4.重启 MySQL Server、检查字符集
1.)重启命令参考:/etc/init.d/mysql restart
2.)输入命令:mysql,进入mysql命令行(如果提示没权限,可以尝试输入mysql -uroot -p你的密码)
3.)在mysql命令行中输入:SHOW VARIABLES WHERE Variable_name LIKE 'character_set_%' OR Variable_name LIKE 'collation%';
检查是否如下:
+--------------------------+--------------------+
| Variable_name | Value |
+--------------------------+--------------------+
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8mb4 |
| character_set_server | utf8mb4 |
| character_set_system | utf8 |
| collation_connection | utf8mb4_unicode_ci |
| collation_database | utf8mb4_unicode_ci |
| collation_server | utf8mb4_unicode_ci |
+--------------------------+--------------------+
rows in set (0.00 sec)
特别说明下:collation_connection/collation_database/collation_server如果是utf8mb4_general_ci,没有关系。但必须保证character_set_client/character_set_connection/character_set_database/character_set_results/character_set_server为utf8mb4。关于这些字符集配置是干什么用的,有什么区别,请参考:深入Mysql字符集设置
5.如果你用的是java服务器,升级或确保你的mysql connector版本高于5.1.13,否则仍然无法使用utf8mb4
这是mysql官方release note,大家可以查看说明,并下载最新的mysql connector for java的jar包。
这里为大家提供一个:mysql-connector-java-5.1.31-bin.jar
同时记得修改pom配置哦~
6.检查你服务端的db配置文件:
jdbc.driverClassName=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/database?useUnicode=true&characterEncoding=utf8&autoReconnect=true&rewriteBatchedStatements=TRUE
jdbc.username=root
jdbc.password=password
特别说明其中的jdbc.url配置:如果你已经升级好了mysql-connector,其中的characterEncoding=utf8可以被自动被识别为utf8mb4(当然也兼容原来的utf8),而autoReconnect配置我强烈建议配上,我之前就是忽略了这个属性,导致因为缓存缘故,没有读取到DB最新配置,导致一直无法使用utf8mb4字符集。
更多如下
转自:http://segmentfault.com/blog/ilikewhite/1190000000616820
https://yq.aliyun.com/articles/6791
RDS MySQL使用utf8mb4字符集存储emoji表情
1. 基本原则
如果要实现存储 emoji 表情到 RDS MySQL 实例,需要客户端、到 RDS MySQL 实例的连接、RDS 实例内部 3 个方面统一使用或者支持 utf8mb4 字符集。
注:关于 utf8mb4 字符集,请参考 MySQL 官方文档
2. 三个条件的说明
2.1 应用客户端
客户端需要保证输出的字符串的字符集为 utf8mb4。
2.2 应用到 RDS MySQL 实例的连接
以常见的 JDBC 连接为例:
对于 JDBC 连接,需要使用 MySQL Connector/J 5.1.13(含)以上的版本。
JDBC 的连接串中,建议不配置 characterEncoding 选项。
注:关于 MySQL Connector/J 5.1.13,请参考 MySQL 官方 Release Notes
2.3 RDS 实例配置
Step 1. 在控制台  参数配置 中修改 character_set_server 参数为 utf8mb4。
参数配置 中修改 character_set_server 参数为 utf8mb4。


对于已有的实例,需要重启数据实例,OK,完美解决………………
Step 2. 设置库的字符集为 utf8mb4
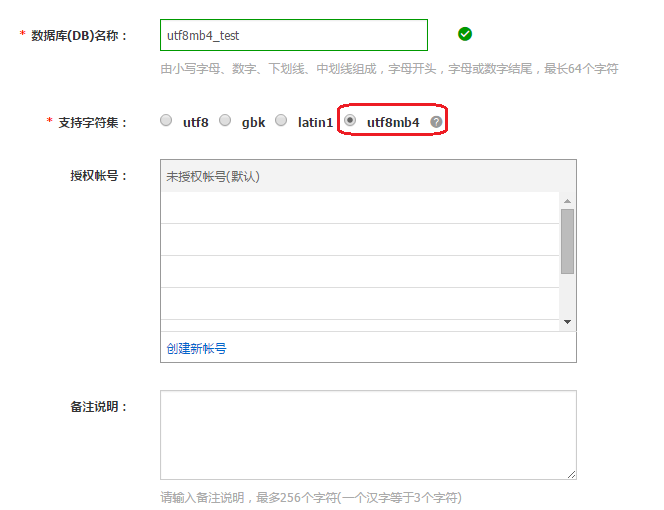
Step 3. 设置表的字符集为 utf8mb4

3. 通过 set names 命令设置会话字符集
对于 JDBC 连接串设置了 characterEncoding 为 utf8 或者做了上述配置仍旧无法正常插入emoji数据的情况,建议在代码中指定连接的字符集为 utf8mb4,样例代码如下:
String query = “set names utf8mb4”;
stat.execute(query);
https://help.aliyun.com/knowledge_detail/41702.html
Changes in MySQL Connector/J 5.1.13 (2010-06-24)
Fixes bugs found since release 5.1.12.
Functionality Added or Changed
Connector/J did not support
utf8mb4for servers 5.5.2 and newer.Connector/J now auto-detects servers configured with
character_set_server=utf8mb4or treats the Java encodingutf-8passed usingcharacterEncoding=...asutf8mb4in theSET NAMES=calls it makes when establishing the connection. (Bug #54175)
http://dev.mysql.com/doc/relnotes/connector-j/5.1/en/news-5-1-13.html
最近,将一个部署在阿里云上的 Rails 项目,连接的 MySQL 数据库的编码,由 utf8 调整为 utf8mb4。
实施过程不是非常顺利,目前,已经部署完成,观察了一段时间,比较稳定。
写了本篇总结,希望可以帮到有需要的朋友。
环境说明
- 服务器系统 Centos,版本为 6.5;
- 数据库使用的是阿里云 RDS MySQL,版本为 5.5.18;
- Rails 版本为 4.1.2;
- mysql2 Gem, 版本为 0.3.16。
为什么要使用 utf8mb4 编码
根本的原因在于,采用 utf8 编码的 MySQL 无法保存占位是4个字节的 Emoji 表情。
为了使后端的项目,全面支持客户端输入的 Emoji 表情,升级编码为 utf8mb4 是最佳解决方案。
之前一篇博文有讲到,不调整 MySQL 编码,使用 rumoji 替换 Emoji 表情为字母编号。
博客原文链接:Ruby on Rails Use MySQL DB Support iPhone emoji
http://manageyp.github.com/ruby-on-rails/2014/12/10/ruby-on-rails-use-mysql-db-support-iphone-emoji.html
但是,这样处理至少有两个问题:
1. Emoji 表情会持续的更新,rumoji 库如果没有及时更新,输入新的表情,则会报错。
2. 使用 rumoji 对用户输入的字符,做正则匹配解析,增加了系统的开销,降低了性能。
另外,看到很多网友建议,迁移 MySQL 至 PostgreSQL、MongoDB 等,迁移成本不小,暂时不考虑。
备注:MySQL 5.5.3 版本之后,引入了 utf8mb4 字符集。
在 mysql client 端,输入以下命令,确认 mysql server 是否支持 utf8mb4 编码。
mysql> SHOW CHAR SET WHERE Charset LIKE "%utf8%";
+---------+---------------+--------------------+--------+
| Charset | Description | Default collation | Maxlen |
+---------+---------------+--------------------+--------+
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 |
+---------+---------------+--------------------+--------+
至于排序规则(collation) 选择默认的 utf8mb4_general_ci,还是 utf8mb4_unicode_ci。
请参考下面文章的介绍,Character Set & Collation In MySQL:
http://infopotato.com/blog/index/mysql_character_set_and_collation
作者从排序的准确性,以及性能方面,告诉我们应该选用 utf8mb4_unicode_ci 。
实施的步骤
- (1) 在阿里云 RDS 控制台,新建一个数据库
名称为:production_new
字符集选择:utf8mb4
- (2) 修改 database.yml 编码
# config/database.yml
encoding: utf8mb4
- (3) Ruby 程序接收和返回 JSON 数据时,强制使用 UTF-8 编码
"string".force_encoding("UTF-8")
(4) 停止 Ruby 进程,停止队列等服务
(5) 部署项目报错
正式版部署之前,有在本地和 Staging 做过测试。
信心满满的在正式版部署,执行的过程中,遇到下面的错误:
Character set 'utf8mb4' is not a compiled character set and is not specified in the '/path/mysql/charsets/Index.xml' file
rake aborted!
Mysql2::Error: Can't initialize character set utf8mb4 (path: /path/mysql/charsets/)
/path/.rvm/gems/ruby-2.0.0-p598/gems/mysql2-0.3.16/lib/mysql2/client.rb:70:in `connect'
/path/.rvm/gems/ruby-2.0.0-p598/gems/mysql2-0.3.16/lib/mysql2/client.rb:70:in `initialize'
经过一番检查后发现,错误是由于当前系统上的 MySQL 客户端版本过低导致。
# 列出所有被安装的 mysql 包
rpm -qa | grep mysql
mysql-devel-5.1.73-3.el6_5.x86_64
mysql-5.1.73-3.el6_5.x86_64
mysql-libs-5.1.73-3.el6_5.x86_64
- (6) 移除现有的旧版本,重新安装 5.5 版本的客户端
# 清理现有 mysql
yum list installed | grep -i mysql
yum remove mysql mysql-* # 修改安装源,不修改源,重新安装的仍然是 5.1 的版本
rpm -Uvh http://repo.webtatic.com/yum/el6/latest.rpm # 安装 5.5 版本的 mysql client
yum install libmysqlclient16 --enablerepo=webtatic
yum install mysql55w mysql55w-libs mysql55w-devel --enablerepo=webtatic # 如果你需要安装 mysql server,请执行
yum install mysql55w-server --enablerepo=webtatic
https://ruby-china.org/topics/24693
CREATE TABLE `ios_emoji` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`unicode` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT 'Unicode编码',
`utf8` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT 'UTF8编码',
`utf16` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT 'UTF16编码',
`sbunicode` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT 'SBUnicode编码',
`filename` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '文件名',
`filebyte` longblob COMMENT '文件内容字节',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT COMMENT='ios表情编码表';
数据存储(MySQL varchar 数据类型对UTF8 支持问题)
MYSQL 5.5 之前, UTF8 编码只支持1-3个字节, 从MYSQL5.5开始,可支持4个字节UTF编码,但要特殊标记。例如我们的帖子内容项,我们加上了这个支持。服务端mysql统一存储为ios5.x也就是Unicode编码。
对应alter语句:
ALTER TABLE topic MODIFY COLUMN content varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '内容';
http://blog.csdn.net/qdkfriend/article/details/7576524?spm=5176.100239.blogcont6791.10.f4a57Y
RDS MySQL 建索引时 Specified key was too long; max key length is 767 bytes 错误的处理
在大字段上创建索引时,有时会碰到下面的错误
ERROR 1709 (HY000): Index column size too large. The maximum column size is 767 bytes.
1. 错误原因
由于 MySQL Innodb 引擎表索引字段长度的限制为 767 字节,因此对于多字节字符集的大字段(或者多字段组合索引),创建索引会出现上面的错误。
以 utf8mb4 字符集 字符串类型字段为例:utf8mb4 是 4 字节字符集,则默认支持的索引字段最大长度是: 767 字节 / 4 字节每字符 = 191 字符,因此在 varchar(255) 或 char(255) 类型字段上创建索引会失败。
注:MySQL官网关于 utf8mb4 字符集的参考文档
2. 解决步骤
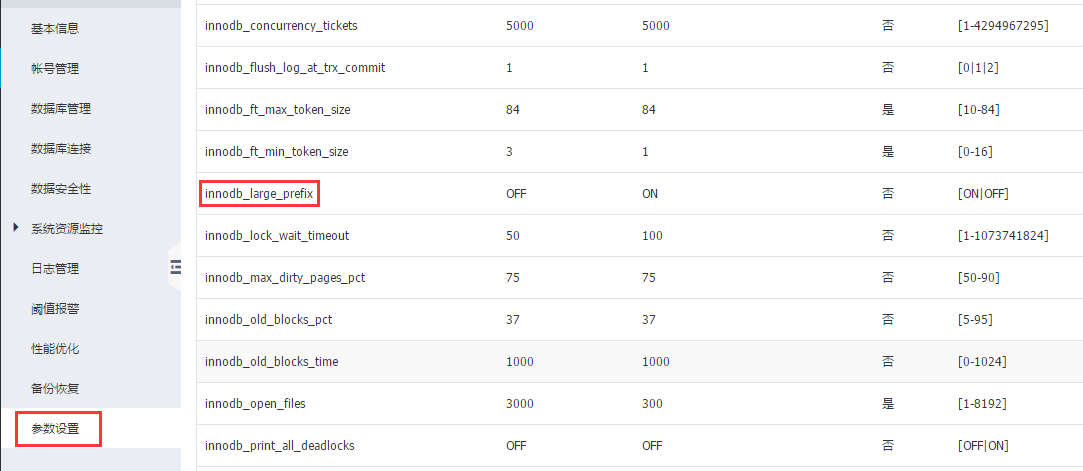
Step 1. RDS 控制台 参数设置,调整参数 innodb_large_prefix 为 ON
将 Innodb_large_prefix 修改为 on 后,对于 Dynamic 和 Compressed 格式的InnoDB 引擎表,其最大的索引字段长度支持到 3072 字节。
Step 2. 创建表的时候指定表的 row format 格式为 Dynamic 或者 Compressed,如下示例:
create table idx_length_test_02
(
id int auto_increment primary key,
name varchar(255)
)
ROW_FORMAT=DYNAMIC default charset utf8mb4;
insert into idx_length_test_02 values (null,'xxxxxxxxxx');
create index idx_name on idx_length_test_02 (name);
show warnings;
show create table idx_length_test_02 \G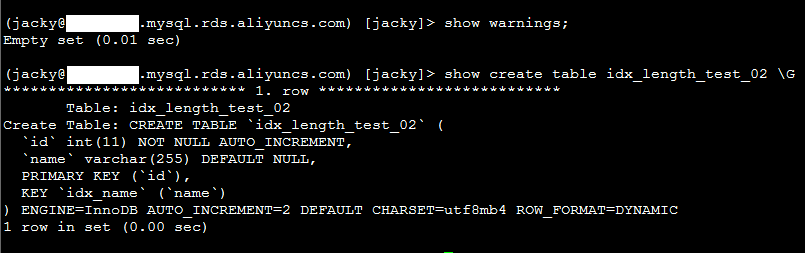
Step 3. 修改现有表
对已经创建的表,通过下面的语句修改下表的 row_format 格式
alter table <table_name> row_format=dynamic;
alter table <table_name> row_format=compressed;https://help.aliyun.com/knowledge_detail/41707.html
emoji是iso和Mac OS系统特有的一系列“表情符号”在微博+ios设备泛滥的今天,很多人的微博中都会嵌入类似的表情符号。
不同于传统上UTF8字符的3个字节(中文地区的传统),emoji采用了4个字节的编码方式。
这一个不算大的改变会导致系统出现类似的报错。
Incorrect string value: ‘xF0x9Fx8Cx9FVi…’ for column ‘nick_name’ at row 1
既然是字符不能识别的报错,只要简单的修改字符集就可以,我的方法是使用了uft8mb4字符集。utf8mb4字符集可以平滑替换原有的utf8,
不过需要注意的是只有MySQL5.1.14版本以上才会支持utf8mb4,而且是server 和client都要在此版本之上方可。对于较旧版本的用户支持emoji,
我的建议是先升级版本吧。
首先修改my.ini
[mysql]
default-character-set=utf8mb4
[mysqld]
character-set-server=utf8mb4
重启MySQL使配置生效,其实可以完全通过set names的方式实现这个调整,我这样做的目的是为了不改变代码,平滑过渡。
修改对应字段的编码格式
ALTER TABLE `表名` CHANGE COLUMN `字段名` `字段名` 类型(长度) CHARACTER SET utf8mb4
http://blog.sina.com.cn/s/blog_600e56a60102uzp9.html
JAVA 连接 RDS for MySQL 测试程序
在使用 Java 开发 RDS 管理和连接时,您可以参考以下方式,建议安装JDK1.7 版本以上,通过 maven 的安装【点此查看】。
RDS mysql 的Java 连接方式您可以考虑用mysql-connector 官方有对应下载,您可以引入对应jar包到build path,下载参考:【点此查看】 。
对应连接RDS MySQL 的实例参考:
import java.sql.*; public class mysqlconnection { public static void main(String[] args) { Connection conn = null;
String sql;
String url = "jdbc:mysql://rdssoxxxxxxxxx.mysql.rds.aliyuncs.com:3306?zeroDateTimeBehavior=convertToNull"
+ "user=michael&password=password&useUnicode=true&characterEncoding=UTF8";
try { Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection(url);
Statement stmt = conn.createStatement();
String sqlusedb = "use test_5"; int result1 = stmt.executeUpdate(sqlusedb); sql = "create table teacher(NO char(20),name varchar(20),primary key(NO))";
int result = stmt.executeUpdate(sql);
if (result != -1) { sql = "insert into teacher(NO,name) values('2016001','wangsan')";
result = stmt.executeUpdate(sql);
sql = "insert into teacher(NO,name) values('2016002','zhaosi')";
result = stmt.executeUpdate(sql);
sql = "select * from teacher";
ResultSet rs = stmt.executeQuery(sql);
ResultSetMetaData metaData = rs.getMetaData();
int columnCount = metaData.getColumnCount();
String separator = " ";
for (int i = 1; i <= columnCount; i++) {
System.out.print(metaData.getColumnLabel(i) + separator);
}
while (rs.next()) {
System.out.println("");
for (int i = 1; i <= columnCount; i++) {
System.out.print(rs.getString(i) + separator);
}
} }
} catch (SQLException e) {
System.out.println("MySQL操作错误");
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
} } }https://help.aliyun.com/knowledge_detail/41741.html
java.sql.SQLException: Incorrect string value: '\xF0\x9F\x92\x94' for colum n 'name' at row 1
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1073)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3593)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3525)
at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:1986)
at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2140)
at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2620)
at com.mysql.jdbc.StatementImpl.executeUpdate(StatementImpl.java:1662)
at com.mysql.jdbc.StatementImpl.executeUpdate(StatementImpl.java:1581)

当报以上错误的时候,可能是java代码中的字段与数据库中的字段类型或者编码不匹配,这种情况只要统一格式或者编码就就可以了。
这里主要介绍emoji的图像插入数据库的错误以及解决方法
使用mysql数据库的时候,如果字符集是UTF-8并且在java服务器上,当存储emoji表情的时候,会抛出以上异常(比如微信开发获取用户昵称,有的用户的昵称用的是emoji的图像)
这是由于字符集不支持的异常,因为utf-8编码有可能是两个,三个,四个字节,其中Emoji表情是四个字节,而mysql的utf-8编码最多三个字节,所以导致数据插不进去。
解决方式:
一.从数据库层面进行解决(mysql支持utf8mb4的版本是5.5.3+,必须升级到较新版本)
注意:
(1.修改database,table,column字符集
ALTER DATABASE database_name CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
ALTER TABLE table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
ALTER TABLE table_name CHANGE column_name VARCHAR(191) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
(2.修改mysql配置文件my.cnf(window为my.ini)
[client]
default-character-set = utf8mb4
[mysql]
default-character-set = utf8mb4
[mysqld]
character-set-client-handshake = FALSE
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
init_connect='SET NAMES utf8mb4'
(3.用的是java服务器,升级或者确保mysql connection版本高于5.1.13否则仍然不能试用utf8mb4
(4.服务器端的db配置文件
jdbc.driverClassName=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/database?useUnicode=true&characterEncoding=utf8&autoReconnect=true&rewriteBatchedStatements=TRUE
jdbc.username=root
jdbc.password=password
如果升级了mysql-connector,其中的characterEncoding=utf8可以自动被识别为utf8mb4(兼容原来的utf8),而
autoReconnection(当数据库连接异常中断时,是否自动重新连接?默认为false)强烈建议配上,忽略这个属性,可能导致缓存缘故 ,
没有读取到DB最新的配置,导致一直无法试用utf8mb4字符集;
详细可见 :
http://segmentfault.com/a/1190000000616820
二.从应用层的方面进行解决
在获得数据之后往数据库存之前先进行编码:
URLEncoder.encode(nickName, "utf-8");
当从数据库中取出准备显示的时候进行解码,
URLDecoder.decode(nickname, "utf-8");
从应用层进行解决的时候建议不要在对象getter,setter方法中直接编码,因为放入对象的时候setter方法将nickname进行编码,当插入数据库的时候相当于从对象中调用getter方法将你参考取出这就将之前setter编码过的nickname又重新解码了,等于未对Nickname进行任何操作。依然会出现以上问题。
http://www.cnblogs.com/dashuai01/p/4601204.html
app端遇到表情图标提交后台MySQL数据库报错的最简单的解决方式
后台服务器错误日志常见为:Caused by: java.sql.SQLException: Incorrect string value: '\xF0\x9F\x98\x97\xF0\x9F...' for column 'CONTENT' at row 1。。。。。
遇到这种情况说明数据库字段存贮上出了问题,为什么呢,这种输入Incorrect string value: '\xF0\x9F\x98\x97\xF0\x9F...'的问题,多数都是字符集的,以前从latain改成gbk,从gbk改成utf8,比utf8更多的就只有utf8mb4了。因为普通的字符串或者表情都是占位3个字节,所以utf8足够用了,但是移动端的表情符号占位是4个字节,普通的utf8就不够用了,为了应对无线互联网的机遇和挑战、避免 emoji 表情符号带来的问题、涉及无线相关的 MySQL 数据库建议都提前采用 utf8mb4 字符集,这必须要作为移动互联网行业的一个技术选型的要点。
注意: 需要 >= MySQL 5.5.3版本、从库也必须是5.5的了、低版本不支持这个字符集、复制报错。
如果系统设计时没注意到此问题,后期开发中才发现,就不需要整体修改数据库编码,只需找到相应表的相关可以提交表情符号的字段,修改字段的编码为 utf8mb4. 同时数据库链接处修改一下编码即可。
例如:如果使用阿里数据源,spring框架下面的配置只需增加一行设置即可。
<!-- 阿里 druid数据库连接池 -->
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" destroy-method="close">
<property name="url" value="${url}" />
<property name="username" value="${username}" />
......
<property name="connectionInitSqls" value="set names utf8mb4;"/>
在dataSource 内增加这一行 配置即可解决问题。
随便说一下,关于linux服务器 如果使用的是比较新的 CentOS7系统的话,mysql本身可能安装会遇到一些问题了,
因为默认的是 Mariadb而不是mysql! Mariadb是mysql的一个分支,具体就不详细介绍,可以自己查本为什么改名字,
使用系统自带的repos安装很简单:yum install mariadb mariadb-server
systemctl start mariadb ==> 启动mariadb
systemctl enable mariadb ==> 开机自启动
mysql_secure_installation ==> 设置 root密码等相关
mysql -uroot -p123456 ==> 测试登录!
结束!
http://sanwen8.cn/p/251jbXQ.html
mysql/Java服务端对emoji的支持 专题的更多相关文章
- mysql/Java服务端对emoji的支持
更改好后的字符集: 乱码 推荐大家看 深入MySQL字符集设置 ,区分检查client端.server端的编码:最简单暴力的方式,是在所有的环节都显式明确的指定相同的编码. 比如使用python的My ...
- php过滤文字中的表情字符和mysql服务端对emoji的支持
1.过滤emoji表情的原因 在我们的项目开发中,emoji表情是个麻烦的东西,即使我们可以能存储,也不一定能完美显示,因为它的更新速度很快:在iOS以外的平台上,例如PC或者android.如果你需 ...
- “快的打车”创始人陈伟星的新项目招人啦,高薪急招Java服务端/Android/Ios 客户端研发工程师/ mysql DBA/ app市场推广专家,欢迎大家加入我们的团队! - V2EX
"快的打车"创始人陈伟星的新项目招人啦,高薪急招Java服务端/Android/Ios 客户端研发工程师/ mysql DBA/ app市场推广专家,欢迎大家加入我们的团队! - ...
- 那些年,我们见过的 Java 服务端“问题”
导读 明代著名的心学集大成者王阳明先生在<传习录>中有云: 道无精粗,人之所见有精粗.如这一间房,人初进来,只见一个大规模如此.处久,便柱壁之类,一一看得明白.再久,如柱上有些文藻,细细都 ...
- 俯瞰 Java 服务端开发
原文首发于 github ,欢迎 star . Java 服务端开发是一个非常宽广的领域,要概括其全貌,即使是几本书也讲不完,该文将会提到许多的技术及工具,但不会深入去讲解,旨在以一个俯瞰的视角去探寻 ...
- Flex通信-Java服务端通信实例
转自:http://blessht.iteye.com/blog/1132934Flex与Java通信的方式有很多种,比较常用的有以下方式: WebService:一种跨语言的在线服务,只要用特定语言 ...
- thrift例子:python客户端/java服务端
java服务端的代码请看上文. 1.说明: 这两篇文章其实解决的问题是,当使用python去访问大数据线上集群的时候,遇到两个问题: 1)python-hadoop和python-hive相关包链接不 ...
- Java 服务端监控方案(四. Java 篇)
http://jerrypeng.me/2014/08/08/server-side-java-monitoring-java/ 这个漫长的系列文章今天要迎来最后一篇了,也是真正与 Java 有关的部 ...
- Java 服务端入门和进阶指南
作者:谢龙 链接:https://www.zhihu.com/question/29581524/answer/44872235 来源:知乎 著作权归作者所有,转载请联系作者获得授权. 现在互联网上资 ...
随机推荐
- [疯狂Java]JDBC:事务管理、中间点、批量更新
1. 数据库事务的概念: 1) 事务的目的就是为了保证数据库中数据的完整性. 2) 设想一个银行转账的过程,假设分两步,第一步是A的账户-1000,第二步是B的账户+1000.这两个动 ...
- [AngularFire2] Auth with Firebase auth -- email
First, you need to enable the email auth in Firebase console. Then implement the auth service: login ...
- php压缩
php压缩的一个demo,随便测试了一下,可以用 <?php class PHPZip { private $ctrl_dir = array(); private $datasec = arr ...
- ConcurrentLinkedQueue使用方法
它是一个基于链接节点的无界线程安全队列.该队列的元素遵循先进先出的原则.头是最先加入的,尾是最近加入的. 插入元素是追加到尾上.提取一个元素是从头提取.当多个线程共享访问一个公共 collection ...
- php实现 统计输入中各种字符的个数
php实现 统计输入中各种字符的个数 一.总结 一句话总结:谋而后动,想清楚,会非常节约编写代码的时间. 1.对结果可能是0的变量,记得初始化? 4 $len=0; 5 $len=strlen($st ...
- php实现二叉树的镜像(二叉树就是递归)
php实现二叉树的镜像(二叉树就是递归) 一.总结 二叉树就是递归 二.php实现二叉树的镜像 题目描述 操作给定的二叉树,将其变换为源二叉树的镜像. 输入描述: 二叉树的镜像定义:源二叉树 8 / ...
- 360随身WIFI作USB无线网卡的做法
作者:朱金灿 来源:http://blog.csdn.net/clever101 1. 到控制面板上把360wifi卸载. 2. 到雷凌的官网下载网卡驱动,注意选择USB(RT2870***),操作系 ...
- Tools:downloading and Building EDK II工具篇:安装/使用EDKII源代码获取/编译工具[2.3]
Tools:Installing and using the Required Tools for downloading and Building EDK II工具篇:安装/使用EDKII源代码获取 ...
- CSS盒子模型中距离的通俗解释
设一个有两个div,一大一小,小的div在大的div里面,而小的div和大div直接的距离就叫外边距,用margin.margin-left.margin-right.margin-top.margi ...
- 每天一个JavaScript实例-检測表单数据
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content ...