Python爬虫之『urlopen』
本文以爬取百度首页为示例来学习,python版本为python3.6.7,完整代码会在文章末附上
本次学习所用到的python框架:
urllib.request 本次学习所用到的函数:
urllib.request.urlopen():发送http的get请求
.read():读取抓到的内容
.decode("utf-8"):将获取的betys格式数据转换为string格式数据
1.发送http的get请求使用的函数urllib.request.urlopen() ,其返回内容是所请求的url的网页源代码 可以将返回的内容赋给另外一个key
例如 response = urllib.request.urlopen(url)
代码执行结果:

好像是存在内存里,这应该展示的是一个内存地址。
data = response.read() `将response的内容读出来赋值给data
代码执行结果:获取的数据类型为bytes,没有可读性哈

3.需要进行转换将data转换成字符串类型,用到函数.decode("utf-8")
str_data = data.decode("utf-8")
代码执行结果:【ps:将上面的https改为http】不截图了这里就能打印出url所对应的网页源代码了

代码运行会生成一个baidu.html保存的是上面搜抓取的内容。
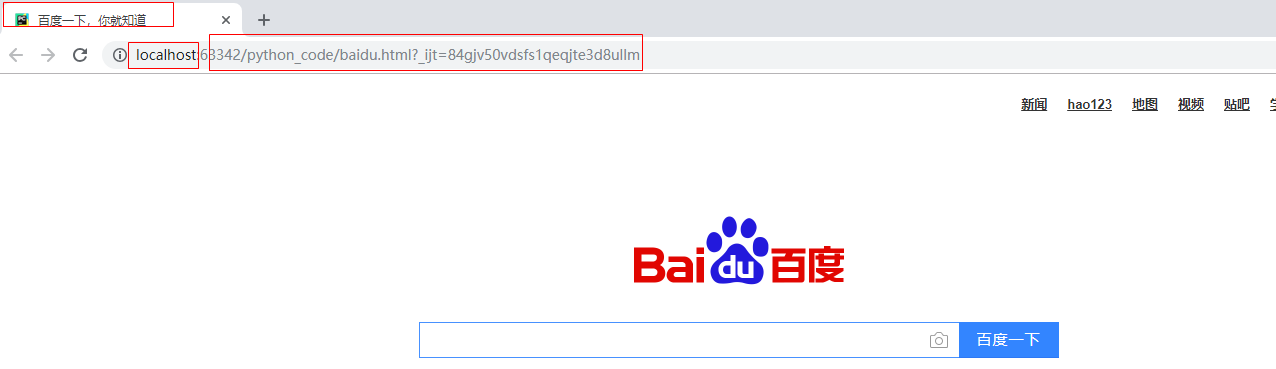

代码运行结果:

# -*- coding:utf-8 -*-
import urllib.request def load_data():
url = "http://www.baidu.com/" #发送http的get请求的函数 urllib.request.urlopen() 其返回内容是所请求url的网页源代码
#将返回的内容赋值给response
response = urllib.request.urlopen(url)
#print(response)
#读取内容 运行之后发现返回数据类型为bytes类型[做运维的小年轻]
data = response.read()
#print(data)
# 将获取的数据类型为bytes的数据data 转换成字符串类型
str_data = data.decode("utf-8")
#print(str_data)
#数据持久化,即写入文件
with open("baidu.html","w",encoding="utf-8")as f:
f.write(str_data)
load_data()
Python爬虫之『urlopen』的更多相关文章
- python爬虫之『入门基础』
HTTP请求 1.首先需要了解一下http请求,当用户在地址栏中输入网址,发送网络请求的过程是什么? 可以参考我之前学习的时候转载的一篇文章一次完整的HTTP事务过程–超详细 2.还需要了解一下htt ...
- 一个简单的开源PHP爬虫框架『Phpfetcher』
这篇文章首发在吹水小镇:http://blog.reetsee.com/archives/366 要在手机或者电脑看到更好的图片或代码欢迎到博文原地址.也欢迎到博文原地址批评指正. 转载请注明: 吹水 ...
- Python爬虫1-使用urlopen
GitHub代码练习地址:https://github.com/Neo-ML/PythonPractice/blob/master/SpiderPrac01_urlopen.py 爬虫简介- 爬虫定义 ...
- Python爬虫教程-02-使用urlopen
Spider-02-使用urlopen 做一个最简单的python爬虫,使用爬虫爬取:智联招聘某招聘信息的DOM urllib 包含模块 - urllib.request:打开和读取urls - ur ...
- 『Python题库 - 填空题』151道Python笔试填空题
『Python题库 - 填空题』Python笔试填空题 part 1. Python语言概述和Python开发环境配置 part 2. Python语言基本语法元素(变量,基本数据类型, 基础运算) ...
- 『Python题库 - 简答题』 Python中的基本概念 (121道)
## 『Python题库 - 简答题』 Python中的基本概念 1. Python和Java.PHP.C.C#.C++等其他语言的对比? 2. 简述解释型和编译型编程语言? 3. 代码中要修改不可变 ...
- 『009』Python
『004』索引-Language Python 准备更新中
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
随机推荐
- NodeJS学习笔记 (19)进阶调试-debugger(ok)
写在前面 谈到node断点调试,目前主要有三种方式,通过node内置调试工具.通过IDE(如vscode).通过node-inspector,三者本质上差不多.本文着重点在于介绍 如何在本地通过nod ...
- C语言操作数截断
//测试截断 #include <stdio.h> int main() { int a = 0x80000001; unsigned int b = 0x80000001; printf ...
- Java基础学习总结(9)——this关键字
一.this关键字 this是一个引用,它指向自身的这个对象. 看内存分析图: 假设我们在堆内存new了一个对象,在这个对象里面你想象着他有一个引用this,this指向这个对象自己,所以这就是thi ...
- ArcGIS api for javascript——合并切片和动态图层
描述 这个示例加入一个通过ArcGISTiledMapServiceLayer表示的cachedArcGIS Server地图服务,和一个通过ArcGISDynamicMapServiceLayer表 ...
- Cocos2d-x学习笔记(十四)CCAutoreleasePool具体解释
原创文章,转载请注明出处:http://blog.csdn.net/sfh366958228/article/details/38964637 前言 之前学了那么多的内容.差点儿全部的控件都要涉及内存 ...
- 八款常用的 Python GUI 开发框架推荐
作为Python开发者,你迟早都会用到图形用户界面来开发应用.本文将推荐一些 Python GUI 框架,希望对你有所帮助,如果你有其他更好的选择,欢迎在评论区留言. Python 的 UI 开发工具 ...
- springMVC的一些配置解析
<mvc:annotation-driven /> <!-- 启动注解驱动的Spring MVC功能,注册请求url和注解POJO类方法的映射--> 是一种简写形式,完全可以手 ...
- nginx大量TIME_WAIT的解决办法--转
原文地址:http://liuyieyer.iteye.com/blog/2214722?utm_source=tuicool&utm_medium=referral 由于网站使用nginx做 ...
- [ Java ][ Eclipse ] 停止讓 Eclipse 跳出 Password Required
stackoverflow 上,問題的解決方式: http://stackoverflow.com/questions/4713890/how-to-disable-programmatically- ...
- swing导出html到excel
swing导出html到excel 1 ShowCopDetal package com.product; import java.awt.BorderLayout; import java.awt ...