day12 字符编码
计算机基础
启动应用程序
- 双击QQ
- 操作系统接受指令然后把该操作转化成0和1发送给CPU
- CPU接受指令然后把指令发送给内存
- 内存接受指令把指令发送给硬盘读取数据
- QQ在内存中运行
写文本的流程
- 在记事本中按下键盘按键j的时候
- 记事本和操作系统交互,把这个按下的指令j转化成0和1
- 操作系统发送这个指令给CPU
- CPU把这个0和1的指令,转化为j
- 然后再由显示器显示
只是一种不错的理解方式,是为了更好的理解下面的主要内容,并不是就是这样的
期间发送的转化过程我们称之为字符编码
j --> 0和1 # 存储
0和1 --> j # 取
统称为字符编码
Python解释器的原理
- 启动Python解释器. # 010001
- 打开文件,读出文件的内容,这时候Python解释器相当于一个文本编辑器. # 发生了字符编码, name = 'nick'
- Python解释器解释
name='nick',然后才有语法的概念 # 发生了字符编码 010001
0000010101001001001(硬盘中) --> name='nick'(内存) -- > 开辟一块内存空间 --> 000010101010
Python解释器和文本编辑器的区别
- 相同点
- 都把硬盘中的数据读到内存中,并显示出来
- 不同点:
- Python解释器多执行了一个解释的步骤
字符编码发生在哪三个阶段
- 存: 从内存到硬盘
- 取: 从硬盘到内存
- 解释: Python3解释器解释
字符编码发展史和分类
计算机是由美国人发明,最早的字符编码为ASCII码, 只规定了英文字母和一些特殊字符与数字的对应关系.最多只能用8位二进制位(一个字节)来表示,即: 2**8 = 256, 所以ASCII码最多只能表示256个字符.
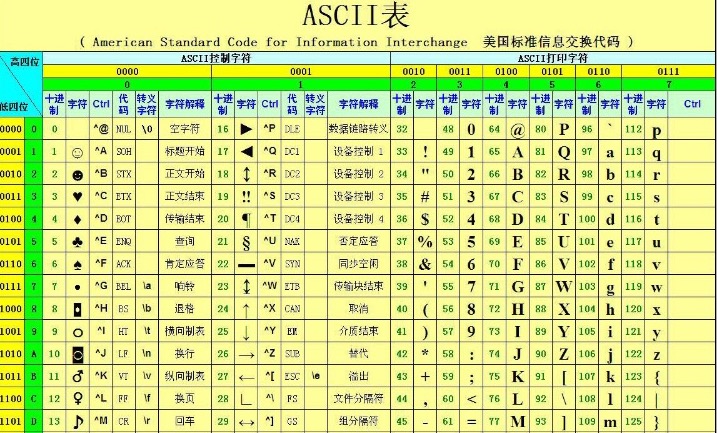
当然我们编程语言都用英文没问题,ASCII也够用,但是在处理数据时,不同的国家有不同的语言,中国人会加入中文,日本人会加入日文,韩国人会加入韩文.
如果要表示中文,单拿一个字节来表示汉字,256个还不够小学生用,解决的办法就是用多个字节来表示.
所以中国人规定了自己的标准GBK编码,规定了包含中文以及数字在内的对应关系,一共用到了2个字节.

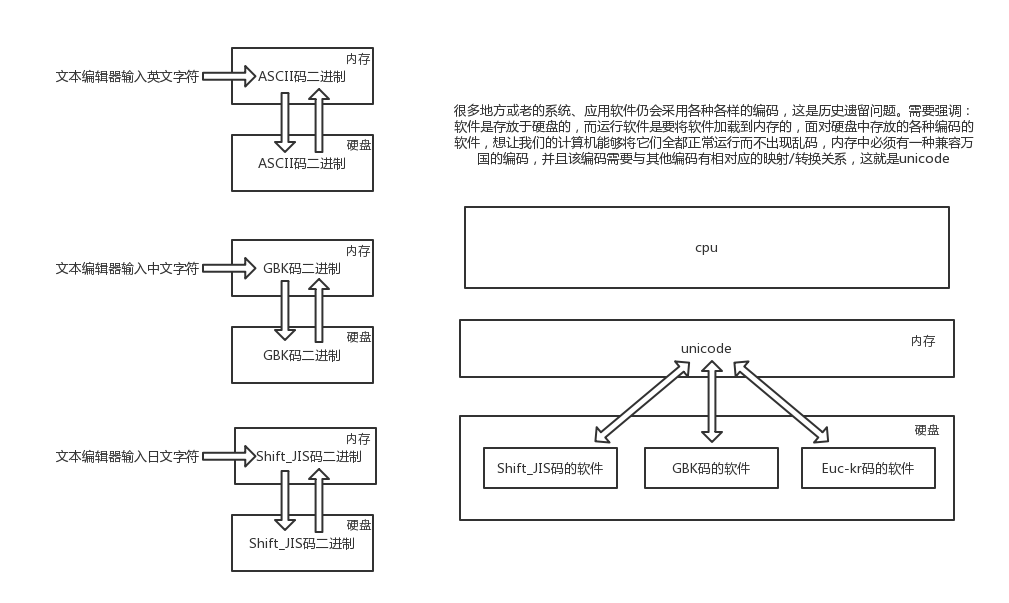
当然,日本人也规定了自己的Shift_JIS编码;韩国人规定了自己的Euc-kr编码(另外,韩国人说,计算机是他们发明的,要求世界统一用韩国编码,但世界人民没有搭理他们)。
这时候问题出现了,因为此刻的各种标准都只是规定了自己国家的文字在内的字符跟数字的对应关系,如果单纯采用一种国家的编码格式,那么其余国家语言的文字在解析时就会出现乱。所以迫切需要一个世界的标准(能包含全世界的语言)于是Unicode应运而生(韩国人表示不服,然后没有什么卵用)。
ascii用1个字节(8位二进制)代表一个字符;Unicode常用2(16个二进制位,原有的英文编码从单字节变成双字节,只需要把高字节全部填为0就可以。) - 4(32个二进制位)来表示.
这时候乱码问题消失了,所有的文档我们都使用但是新问题出现了,如果我们的文档通篇都是英文,你用Unicode会比ascii耗费多一倍的空间,在存储和传输上十分的低效。
本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8(Unicode Transformation Format-8)编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节(8个二进制位,也就是ASCII),汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
所以UTF-8就类似于升级版的Unicode,但是由于历史遗留问题,(之前编写的用世界各国编码程序).而UTF-8只能和unicode间进行转换,所以内存中使用的依旧是Unicode,但是保存的时候大部分市面上的电脑都是使用UTF-8的格式了.
编码
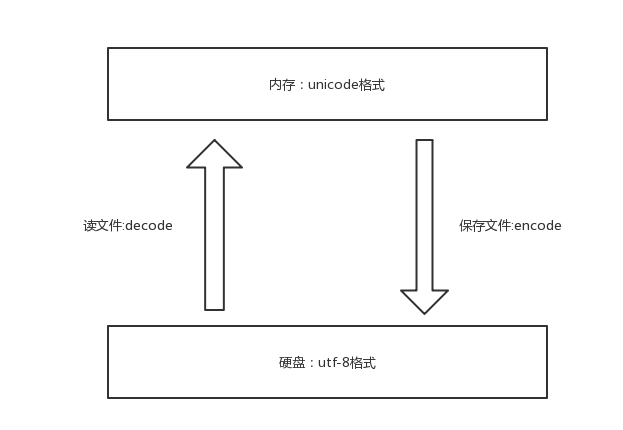
- 从内存到硬盘的过程,即unicode --> gbk 称为编码 encode
解码
- 从硬盘到内存的过程,即gbk --> unicode 称为解码 decode
乱码
- 存的时候和取得时候用的编码不同所致
总结
- 存的时候用什么编码,取的时候用什么编码
Python2与Python3字符串类型的区别
Python2
- 在Python2中有两种字符串类型,str和Unicode
- str:编码成gbk的形式
- unicode:编码成unicode的形式,需要在字符串前加'u'
Python3
- 只有一种字符串类型,也就是unicode
# _*_ coding:utf-8 _*_声明编码格式,控制Python3解释器作为文本编辑器的时候以上面编码格式读取文本内容,Python2中默认使用ascii,Python3中默认使用utf-8。
pycharm 右下角控制的是你写入的代码字符以什么编码格式保存
python解释器解释语法
解释定义变量的语法,会新开辟一块内存空间放入这个变量,然后假设这个变量在python3中以utf-8的形式存储,如字符x = '中',被python3解释后再内存中会变成x=000001101010.理论上print(x)相当于输出000001101010,但是这个000001101010对于程序员来讲看不懂,所以python3创始人龟叔做了这个操作-把000001101010编码按终端的编码格式输出编码后的结果,如上.如果终端的编码为gbk,终端无法识别000001101010.所以新开辟空间放入变量的时候,就用unicode转换,则终端无论是什么形式的编码格式,都能够识别并打印.
自己的理解
书写Python程序的时候,编辑器用的是一种编码格式,如果用Pycharm或者Python3写,则默认是utf-8保存,用文本文件写,则是gbk保存
写的时候可以声明Python打开时用的字符编码,Python2打开是ascii,Python3打开是utf-8.
如果你用文本文件,也就是gbk格式写的程序,又没有声明用gbk打开,那么用Python3打开时,如果里面有中文,则会编译错误,因为对应关系不一样,用英文可能可以正常编译,因为都是用ASCII.
这前面的内容都是Python作为文本编辑器时的应用场景
当程序被打开执行后,变量会被定义到内存中,这是Python2中可以定义gbk或unicode,而Python则只能被定义成unicode放入内存中
当输入变量时,print('中')会被编译成0000101010之类的二进制码,但是这个东西直接输入看不懂,所以Python做了一个操作,把0000101010按照终端的编码格式输出编码后的结果.而定义的时候如果用的是unicode形式,则无论终端采用什么编码格式,都可以正常编码,如果采用的是gbk格式,则必须终端也使用jbk格式进行解码,否则则会乱码.
这段的内容是Python作为解释器时的应用场景
day12 字符编码的更多相关文章
- Python遇到字符编码出问题的一个相对万能的办法
在使用Python做爬虫的过程中,经常遇到字符编码出问题的情况. UnicodeEncodeError: 'ascii' codec can't encode character u'\u6211' ...
- python学习笔记(基础一:'hello world'、变量、字符编码)
第一个python程序: Hello World程序 windows命令行中输入:python,进入python交互器,也可以称为解释器. print("Hello World!" ...
- Python学习Day2笔记(字符编码和函数)
1.字符编码 #ASCII码里只能存英文和特殊字符 不能存中文 存英文占1个字节 8位#中文编码为GBK 操作系统编码也为GBK#为了统一存储中文和英文和其他语言文字出现了万国码Unicode 所有一 ...
- mysql 5.5 修改字符编码
修改/etc/mysql/my.cnf 配置文件: 最后重启mysql 服务,再查看: 编码已经改好了,可以支持中文字符编码了.
- mysql命令行修改字符编码
1.修改数据库字符编码 mysql> alter database mydb character set utf8 ; 2.创建数据库时,指定数据库的字符编码 mysql> create ...
- 关于Unicode,字符集,字符编码,每个程序员都应该知道的事
关于Unicode,字符集,字符编码,每个程序员都应该知道的事 作者:Jack47 李笑来的文章如何判断一个人是否聪明?中提到: 必要.清晰.且准确的概念,是一切思考的基石.所谓思考,很大程度上,就是 ...
- java中文乱码解决之道(二)-----字符编码详解:基础知识 + ASCII + GB**
在上篇博文(java中文乱码解决之道(一)-----认识字符集)中,LZ简单介绍了主流的字符编码,对各种编码都是点到为止,以下LZ将详细阐述字符集.字符编码等基础知识和ASCII.GB的详情. 一.基 ...
- ASP.NET 字符编码的那些事
ASP.NET 中的字符编码问题,一般会有两个场景: HTML 编码:一般是动态显示 HTML 字符或标签,写法是:HttpUtility.HtmlDecode(htmlString) 或 Html. ...
- 【字符编码】Java字符编码详细解答及问题探讨
一.前言 继上一篇写完字节编码内容后,现在分析在Java中各字符编码的问题,并且由这个问题,也引出了一个更有意思的问题,笔者也还没有找到这个问题的答案.也希望各位园友指点指点. 二.Java字符编码 ...
随机推荐
- Java常用工具类---XML工具类、数据验证工具类
package com.jarvis.base.util; import java.io.File;import java.io.FileWriter;import java.io.IOExcepti ...
- HTTPie:一个不错的 HTTP 命令行客户端
转自:http://top.jobbole.com/9682/ HTTPie:一个不错的 HTTP 命令行客户端 HTTPie (读aych-tee-tee-pie)是一个 HTTP 的命令行客户端. ...
- css中的流,元素,基本尺寸
流 元素 基本尺寸 流之所以影响整个css世界,是因为它影响了css世界的基石 --HTML HTML 常见的标签有虽然标签种类繁多,但通常我们就把它们分为两类: 块级元素(block-level e ...
- HDU2147 - kiki's game 【巴什博弈】
Recently kiki has nothing to do. While she is bored, an idea appears in his mind, she just playes th ...
- UVA 12633 Super Rooks on Chessboard (生成函数+FFT)
题面传送门 题目大意:给你一张网格,上面有很多骑士,每个骑士能横着竖着斜着攻击一条直线上的格子,求没被攻击的格子的数量总和 好神奇的卷积 假设骑士不能斜着攻击 那么答案就是没被攻击的 行数*列数 接下 ...
- 实现路由器自动登录校园网(edu)
准备工作: (1)一个可以刷openwrt固件的路由器,如大多人使用的crazybox版本的路由. (2)一个可用的edu账号. (3)一个浏览器(firfox,chrome) 下面开始: 一:刷op ...
- 理解 Javascript 执行上下文和执行栈
如果你是一名 JavaScript 开发者,或者想要成为一名 JavaScript 开发者,那么你必须知道 JavaScript 程序内部的执行机制.理解执行上下文和执行栈同样有助于理解其他的 Jav ...
- Java中发邮件的6种方法
1.官方标准JavaMail Sun(Oracle)官方标准,功能强大,用起来比较繁琐. 官方资料:http://www.oracle.com/technetwork/java/javamail/in ...
- EL表达式取整问题
一般来说我们是无法实现EL表达式取整的.对于EL表达式的除法而言,他的结果是浮点型. 如:${6/7},他的结果是:0.8571428571428571.对于这个我们是无法直接来实现取整的. 这时就可 ...
- 使用SeaJS,require加载Jquery的时候总是为null
这个问题困扰了我两天,使用别人的例子.官网down下来的example都没有问题.但是放到自己项目里就 var $=require("jquery") 为null. 后来发现,jq ...