elasticsearch index之Translog
跟大多数分布式系统一样,es也通过临时写入写操作来保证数据安全。因为lucene索引过程中,数据会首先据缓存在内存中直到达到一个量(文档数或是占用空间大小)才会写入到磁盘。这就会带来一个风险,如果在写入磁盘前系统崩溃,那么这些缓存数据就会丢失。es通过translog解决了这个问题,每次写操作都会写入一个临时文件translog中,这样如果系统需要恢复数据可以从translog中读取。本篇就主要分析translog的结构及写入方式。
这一部分主要包括两部分translog和tanslogFile,前者对外提供了对translogFile操作的相关接口,后者则是具体的translogFile,它是具体的文件。首先看一下translogFile的继承关系,如下图所示:
实现了两种translogFile,它们的最大区别如名字所示就是写入时是否缓存。FsTranslogFile的接口如下所示:
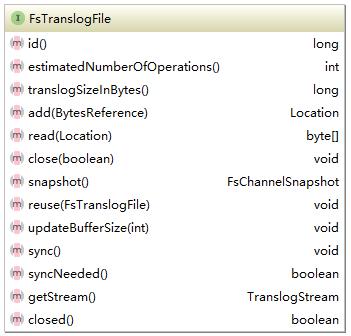
每一个translogFile都会有一个唯一Id,两个非常重要的方法add和write。add是添加对应的操作,这些操作都是在translog中定义,这里写入的只是byte类型的文件,不关注是何种操作。所有的操作都是顺序写入,因此读取的时候需要一个位置信息。add方法代码如下所示:
public Translog.Location add(BytesReference data) throws IOException {
rwl.writeLock().lock();//获取读写锁,每个文件的写入都是顺序的。
try {
operationCounter++;
long position = lastPosition;
if (data.length() >= buffer.length) {
flushBuffer();
// we use the channel to write, since on windows, writing to the RAF might not be reflected
// when reading through the channel
data.writeTo(raf.channel());//写入数据
lastWrittenPosition += data.length();
lastPosition += data.length();//记录位置
return new Translog.Location(id, position, data.length());//返回由id,位置及长度确定的操作位置信息。
}
if (data.length() > buffer.length - bufferCount) {
flushBuffer();
}
data.writeTo(bufferOs);
lastPosition += data.length();
return new Translog.Location(id, position, data.length());
} finally {
rwl.writeLock().unlock();
}
}
这是SimpleTranslogFile写入操作,BufferedTransLogFile写入逻辑基本相同,只是它不会立刻写入到硬盘,先进行缓存。另外TranslogFile还提供了一个快照的方法,该方法返回一个FileChannelSnapshot,可以通过它next方法将translogFile中所有的操作都读出来,写入到一个shapshot文件中。代码如下:
public FsChannelSnapshot snapshot() throws TranslogException {
if (raf.increaseRefCount()) {
boolean success = false;
try {
rwl.writeLock().lock();
try {
FsChannelSnapshot snapshot = new FsChannelSnapshot(this.id, raf, lastWrittenPosition, operationCounter);
snapshot.seekTo(this.headsuccess = true;
returnerSize);
snapshot;
} finally {
rwl.writeLock().unlock();
}
} catch (FileNotFoundException e) {
throw new TranslogException(shardId, "failed to create snapshot", e);
} finally {
if (!success) {
raf.decreaseRefCount(false);
}
}
}
return null;
}
TransLogFile是具体文件的抽象,它只是负责写入和读取,并不关心读取和写入的操作类型。各种操作的定义及对TransLogFile的定义到在Translog中。它的接口如下所示:

这里的写入(add)就是一个具体的操作,这是一个外部调用接口,索引、删除等修改索引的操作都会构造一个对应的Operation在对索引进行相关操作的同时调用该方法。这里还要着重说明一下makeTransientCurrent方法。操作的写入时刻进行,但是根据配置TransLogFile超过限度时需要删除重新开始一个新的文件。因此在transLog中存在两个TransLogFile,current和transient。当需要更换时需要通过读写锁确保单线程操作,将current切换到transient上来,然后删除之前的current。代码如下所示:
public void revertTransient() {
FsTranslogFile tmpTransient;
rwl.writeLock().lock();
try {
tmpTransient = trans;//交换
this.trans = null;
} finally {
rwl.writeLock().unlock();
}
logger.trace("revert transient {}", tmpTransient);
// previous transient might be null because it was failed on its creation
// for example
if (tmpTransient != null) {
tmpTransient.close(true);
}
}
translog中定义了index,create,delete及deletebyquery四种操作它们都继承自Operation。这四种操作也是四种能够改变索引数据的操作。operation代码如下所示:
static interface Operation extends Streamable {
static enum Type {
CREATE((byte) 1),
SAVE((byte) 2),
DELETE((byte) 3),
DELETE_BY_QUERY((byte) 4);
private final byte id;
private Type(byte id) {
this.id = id;
}
public byte id() {
return this.id;
}
public static Type fromId(byte id) {
switch (id) {
case 1:
return CREATE;
case 2:
return SAVE;
case 3:
return DELETE;
case 4:
return DELETE_BY_QUERY;
default:
throw new ElasticsearchIllegalArgumentException("No type mapped for [" + id + "]");
}
}
}
Type opType();
long estimateSize();
Source getSource();
}
tanslog部分就是实时记录所有的修改索引操作确保数据不丢失,因此它的实现上不上非常复杂。
总结:TransLog主要作用是实时记录对于索引的修改操作,确保在索引写入磁盘前出现系统故障不丢失数据。tanslog的主要作用就是索引恢复,正常情况下需要恢复索引的时候非常少,它以stream的形式顺序写入,不会消耗太多资源,不会成为性能瓶颈。它的实现上,translog提供了对外的接口,translogFile是具体的文件抽象,提供了对于文件的具体操作。
elasticsearch index之Translog的更多相关文章
- elasticsearch index 之 engine
elasticsearch对于索引中的数据操作如读写get等接口都封装在engine中,同时engine还封装了索引的读写控制,如流量.错误处理等.engine是离lucene最近的一部分. engi ...
- ElasticSearch Index操作源码分析
ElasticSearch Index操作源码分析 本文记录ElasticSearch创建索引执行源码流程.从执行流程角度看一下创建索引会涉及到哪些服务(比如AllocationService.Mas ...
- elasticsearch index 之 put mapping
elasticsearch index 之 put mapping mapping机制使得elasticsearch索引数据变的更加灵活,近乎于no schema.mapping可以在建立索引时设 ...
- Elasticsearch Index模块
1. Index Setting(索引设置) 每个索引都可以设置索引级别.可选值有: static :只能在索引创建的时候,或者在一个关闭的索引上设置 dynamic:可以动态设置 1.1. S ...
- elasticsearch index tuning
一.扩容 tag_server当前使用ElasticSearch版本为5.6,此版本单个index的分片是固定的,一旦创建后不能更改. 1.扩容方法1,不适 ES6.1支持split index功能, ...
- Add mappings to an Elasticsearch index in realtime
Changing mapping on existing index is not an easy task. You may find the reason and possible solutio ...
- ElasticSearch Index API && Mapping
ElasticSearch NEST Client 操作Index var indexName="twitter"; var deleteIndexResponse = clie ...
- Elasticsearch index fields 重命名
reindex数据复制,重索引 POST _reindex { "source": { "index": "twitter" }, &quo ...
- elasticsearch index 之 create index(-)
从本篇开始,就进入了Index的核心代码部分.这里首先分析一下索引的创建过程.elasticsearch中的索引是多个分片的集合,它只是逻辑上的索引,并不具备实际的索引功能,所有对数据的操作最终还是由 ...
随机推荐
- String build-in function - len
len is a build-in function that returns the numbers of characters in a string: Since we started coun ...
- 升级JDK9后eclipse无法启动的解决方法
解决方法-打开: D:\Program Files\eclipse\eclipse.ini 在文件末尾添加一行: --add-modules=ALL-SYSTEM 再次启动eclipse即可 感谢ht ...
- CUDA学习笔记(五)
终于实质分析线程的内容了:按照SIMD的方式,每32个线程称为一个线程束,这些线程都执行同一指令,且每个线程都使用私有寄存器进行这一操作请求. 忽然觉得,做CUDA的程序就像是去北京上班:写MPI之后 ...
- 14个优秀 JS 前端框架、库、工具及其使用时机
这篇文章主要描述现今流行的一些 Javascript web 前端框架,库以及它们的适用场景. 新的 Javascript 库层出不穷,从而Web 社区愈发活跃.多样.在多方面快速发展.详细去描述每一 ...
- 为什么越来越少的开源项目使用 GPL 协议
原文出处: opensource 译文出处:oschina/王练 前段时间,我在 RedMonk 上看到了一篇来自 Stephen O’Grady 的有趣推文,介绍了开源许可证目前的状态,以 ...
- center os 7最小化安装后按table无法补全命令的问题
闲来无趣,这两天huskiesir又重新安装了下center os 7操作系统,结果呢,发现一个问题:按table键无法补全命令啊. 咦,奇怪了,这次怎么回事,完全没遇到过啊.哦,回想了一下,和以往的 ...
- C语言调试小技巧
经常看到有人介绍一些IDE或者像gdb这样的调试器的很高级的调试功能,也听人说过有些牛人做工程的时候就用printf来调试,不用特殊的调试器.特别是在代码经过编译器一些比较复杂的优化后,会变得“难以辨 ...
- CMSIS-RTOS 简介
CMSIS-RTOS API是基于Arm®Cortex®-M处理器的设备的通用RTOS接口.CMSIS-RTOS为需要RTOS功能的软件组件提供标准化API,从而为用户和软件行业带来了巨大的好处. C ...
- Spring Cloud学习笔记【九】配置中心Spring Cloud Config
Spring Cloud Config 是 Spring Cloud 团队创建的一个全新项目,用来为分布式系统中的基础设施和微服务应用提供集中化的外部配置支持,它分为服务端与客户端两个部分.其中服务端 ...
- 通过视频展示如何通过Samba配置PDC
通过视频展示如何通过Samba配置PDC(Linux企业应用案例精解补充视频内容) 本文通过视频,真实地再现了在Linux平台下如何通过配置smb.conf文件而实现Samba Server模拟win ...