Hadoop集群配置搭建
环境:Centos 6.9,Hadoop 2.7.1,JDK 1.8.0_161,Maven 3.3.9
前言:
1、配置一台master服务器,两台或多台slave服务器。
2、master可以无密码ssh登陆slave
3、解压安装Hadoop,配置hadoop的core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml文件,配置好之后启动hadoope服务,用jps命令查看状态;
4、运行hadoop自带的wordcount程序做一个Hello World实例
开始配置
第一步 配置hosts
获得它们的IP地址,并设置主机名,(根据实际IP地址和主机名)修改/etc/hosts文件内容为:
192.168.110.66 master.hadoop
192.168.110.67 slave1.hadoop
192.168.110.68 slave2.hadoop

重启后。host生效。
第二步 ssh免密登陆
全程用的都是root用户,没有另外创建用户。每台服务器都生成公钥,再合并到authorized_keys。
1) CentOS默认没有启动ssh无密登录,去掉/etc/ssh/sshd_config其中2行的注释,每台服务器都要设置。
查找
#RSAAuthentication yes
#PubkeyAuthentication yes
删除前面的井号注释。
2) 输入命令,ssh-keygen -t rsa,生成key,都不输入密码,一直回车,/root就会生成.ssh文件夹,每台服务器都要设置
3) 合并公钥到authorized_keys文件,在master服务器,进入/root/.ssh目录,通过SSH命令合并,(~/.ssh/id_rsa.pub 是省略的写法,要根据实际路径来确定)
cat id_rsa.pub>> authorized_keys
ssh root@192.168.110.67 cat ~/.ssh/id_rsa.pub >> authorized_keys
ssh root@192.168.110.68 cat ~/.ssh/id_rsa.pub >> authorized_keys
如果出现 ssh command not found
就yum装一个ssh


4) 把master服务器的authorized_keys、known_hosts复制到slave服务器的/root/.ssh目录
scp -r /root/.ssh/authorized_keys root@192.168.110.67:/root/.ssh/
scp -r /root/.ssh/known_hosts root@192.168.110.67:/root/.ssh/ scp -r /root/.ssh/authorized_keys root@192.168.110.68:/root/.ssh/
scp -r /root/.ssh/known_hosts root@192.168.110.68:/root/.ssh/
5) 完成后,ssh root@192.168.110.67、ssh root@192.168.110.68或者(ssh root@slave1.hadoop、ssh root@slave2.hadoop ) 就不需要输入密码直接登录到其他节点上。

第三步安装JDK

tar包安装方式
1) 在/home目录下创建java目录,然后使用rz命令,上传“jdk-7u79-linux-x64.gz”到/home/java目录下,
2) 解压,输入命令,tar -zxvf jdk-7u79-linux-x64.gz
3) 编辑 /etc/profile,在其末尾添加以下内容:
export JAVA_HOME=/home/java/jdk1..0_79
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
4) 使配置生效,输入命令,source /etc/profile
5) 输入命令,java -version,完成
第四步安装Hadoop
将主从节点上传好的hadoop解压。,输入命令,tar -xzvf hadoop-2.7.3.tar.gz
在/home/hadoop目录下创建数据存放的文件夹,tmp、dfs、dfs/data、dfs/name(hdfs-site.xml文件中会用到)
修改配置文件
1./root/hadoop/etc/hadoop目录下的core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master.hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value></value>
</property>
</configuration>
2.配置/root/hadoop/etc/hadoop目录下的hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///root/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///root/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master.hadoop:</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
3.配置/root/hadoop/etc/hadoop目录下的mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>master.hadoop:</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master.hadoop:</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master.hadoop:</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://master.hadoop:9001</value>
</property>
</configuration>
4.配置/home/hadoop/hadoop-2.7.0/etc/hadoop目录下的yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property> <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master.hadoop:</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master.hadoop:</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master.hadoop:</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master.hadoop:</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master.hadoop:</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master.hadoop</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value></value>
</property>
</configuration>
提示:yarn.nodemanager.resource.memory-mbr的值一定要注意,在最后的hello world程序运行时,会提示内存太小,(hadoop运行到mapreduce.job: Running job后停止运行 )我把它从1024改成了2048
最后执行wordcount遇到内存不足的问题,解决方案就是把yarn-site.xml文件中的yarn.nodemanager.resource.memory-mb的值改成2048
5.配置/home/hadoop/hadoop-2.7.3/etc/hadoop目录下hadoop-env.sh、yarn-env.sh的JAVA_HOME
取消注释,设置为export JAVA_HOME=你java的安装路径
通过yum安装的java 路径在 /etc/alternatives/java_sdk_1.8.0
slave1.hadoop
slave2.hadoop
6.配置/home/hadoop/hadoop-2.7.3/etc/hadoop目录下的slaves,删除默认的localhost,增加2个slave节点:
7.将master服务器上配置好的Hadoop复制到各个节点对应位置上,通过scp传送
scp -r /root/hadoop 192.168.110.67:/root/
scp -r /root/hadoop 192.168.110.68:/root/
第四步安装Hadoop
提示:在master服务器启动hadoop,各从节点会自动启动,进入/root/hadoop目录,hadoop的启动和停止都在master服务器上执行。
1) 初始化,在hadoop目录下输入命令,bin/hdfs namenode -format (注意这个 横杆不能是中文横杆,否则namenode会格式化失败,在日志里报java.io.IOException: NameNode is not formatted.)
2) 启动命令
sbin/start-dfs.sh
sbin/start-yarn.sh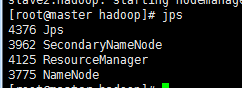
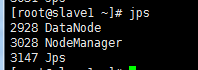
3) 停止命令,依次执行:sbin/stop-dfs.sh、sbin/stop-yarn.sh
至此hadoop已经搭建完成。
四、Hadoop入门之HelloWorld程序
摘要:初步接触Hadoop,必不可少的就是运行属于Hadoop的Helloworld程序——wordcount,统计文件中各单词的数目。安装好的Hadoop集群上已有相应的程序。我们来验证一下。
准备数据
在/root/hadoopdemo/下创建file文件夹,里面生成file1.txt,file2.txt,file3.txt,file4.txt四个文件
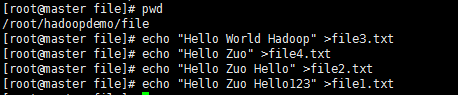
然后把数据put到HDFS里
[root@master hadoop]# bin/hadoop fs -mkdir -p /input
[root@master hadoop]# bin/hadoop fs -put /root/hadoopdemo/file/file1.txt /input
[root@master hadoop]# bin/hadoop fs -put /root/hadoopdemo/file/file2.txt /input
[root@master hadoop]# bin/hadoop fs -put /root/hadoopdemo/file/file3.txt /input
[root@master hadoop]# bin/hadoop fs -put /root/hadoopdemo/file/file4.txt /input

长传成功,但是发现每执行异常hadoop命令都会报一个OpenJDK的警告。
先执行wordcount
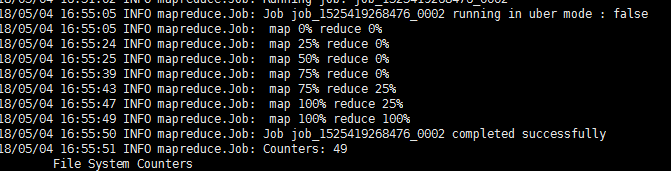
执行命令查看结果
bin/hadoop fs -text /output/wordcount/part-r-00000

问题
要关闭主从各个节点的防火墙,否则容易出现各种莫名的问题。
Ubuntu(ubuntu-12.04-desktop-amd64)
查看防火墙状态:ufw status
关闭防火墙:ufw disable
---------------------------------------------------------------
centos6.0
查看防火墙状态:service iptables status
关闭防火墙:chkconfig iptables off #开机不启动防火墙服务
--------------------------------------------------------------
centos7.0(默认是使用firewall作为防火墙,如若未改为iptables防火墙,使用以下命令查看和关闭防火墙)
查看防火墙状态:firewall-cmd --state
关闭防火墙:systemctl stop firewalld.service
Hadoop集群配置搭建的更多相关文章
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群的搭建与配置(2)
对解压过后的文件进行从命名 把"/usr/hadoop"读权限分配给hadoop用户(非常重要) 配置完之后我们要创建一个tmp文件供以后的使用 然后对我们的hadoop进行配置文 ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- Hadoop集群配置(最全面总结)
Hadoop集群配置(最全面总结) 通常,集群里的一台机器被指定为 NameNode,另一台不同的机器被指定为JobTracker.这些机器是masters.余下的机器即作为DataNode也作为Ta ...
- hadoop集群的搭建
hadoop集群的搭建 1.ubuntu 14.04更换成阿里云源 刚刚开始我选择了nat模式,所有可以连通网络,但是不能ping通,我就是想安装一下mysql,因为安装手动安装mysql太麻烦了,然 ...
- Hadoop集群配置(最全面总结 )(转)
Hadoop集群配置(最全面总结) huangguisu 通常,集群里的一台机器被指定为 NameNode,另一台不同的机器被指定为JobTracker.这些机器是masters.余下的机器即作为Da ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- hadoop集群的搭建(分布式安装)
集群 计算机集群是一种计算机系统,他通过一组松散集成的计算机软件和硬件连接起来高度紧密地协同完成计算工作. 集群系统中的单个计算机通常称为节点,通常通过局域网连接. 集群技术的特点: 1.通过多台计算 ...
随机推荐
- 修改host文件浏览国外网站
公司电脑网络没法进github没办法工作需要只能FQ了. 方法1:用VPN 但是地要钱呐,没钱只能放弃了,不过每天试用还是可以的 方法2:改电脑host,文件中每条数据前面的#代表注释.把要访问的地址 ...
- VisualStudio UnitTest FrameWork
当创建单元测试时,Microsoft.VisualStudio.TestTools.UnitTesting的名字控件会添加到测试项目中,该名字控件中包含很多有用的类: 断言类:在单元测试中验证条件 初 ...
- ZOJ 2883 Shopaholic【贪心】
解题思路:给出n件物品,每买三件,折扣为这三件里面最便宜的那一件即将n件物品的价值按降序排序,依次选择a[3],a[6],a[9]----a[3*k] Shopaholic Time Limit: 2 ...
- Mojo C++ Bindings API
This document is a subset of the Mojo documentation. Contents Overview Getting Started Interfaces Ba ...
- div控制最小高度又自适高度
div控制最小高度又自适高度我们在用div布局的时候经常会遇到这样的一种情况:我们需要设置一个div的高度,当里面的东西超过这个高度时,让这个容器自动被撑开,也就是自适应高度.当里面的信息很少时候,我 ...
- [arc082e]ConvexScore
题意: 给出直角坐标系中的$N$个点$(X_i,Y_i)$,定义由其中部分点构成的点集为“凸点集”当且仅当这些点恰好能构成一个凸多边形(内部没有其他点). 如图,点集$\{A,C,E\}$和$\{B, ...
- sudo不用在输入密码
在任意的路径之下执行:sudo visudo 的命令对文件进行修改: 其中的: sudo ALL=(ALL) %admin ALL=(ALL) 这两个语句为: sudo ALL=(ALL) NOPAS ...
- [APIO2014]回文串(回文自动机)
题意 给你一个由小写拉丁字母组成的字符串 s.我们定义 s 的一个子串的存在值为这个子串在 s 中出现的次数乘以这个子串的长度. 对于给你的这个字符串 s,求所有回文子串中的最大存在值. |S|< ...
- CF451E Devu and Flowers (组合数学+容斥)
题目大意:给你$n$个箱子,每个箱子里有$a_{i}$个花,你最多取$s$个花,求所有取花的方案,$n<=20$,$s<=1e14$,$a_{i}<=1e12$ 容斥入门题目 把取花 ...
- 洛谷 P4932 浏览器 (思维题)
题目大意:给你一个序列,求满足$x_{i}\: xor\; x_{j}$在二进制下1的数量为奇数的数对数量 打月赛的时候真没想出来,还是我太弱.. xor意义下,对于两个数,假设它们两个每一位都是2个 ...