Beautifulsoup提取特定丁香园帖子回复
DataWhale-Task3(Beautifulsoup爬取丁香园)
简要分析
任务3:爬取丁香园论坛特定帖子,包括帖子主题,帖子介绍,回贴内容(用户名,用户头像,用户所在城市,用户回贴内容)
此次爬取的url:http://i.dxy.cn/topic/admerahealthcollege
其加载帖子内容的接口:http://i.dxy.cn/topic/admerahealthcollege/feeds/list

其数据接口仅在于路径不同,host是相同的,在帖子url补上/feeds/list
数据接口共有三个GET参数:JUTE_TOKEN,type,page,size
| 参数 | 说明 |
|---|---|
| JSTE_TOKE | 是第一次请求服务器响应的 cookies 之一 |
| type | 默认为 0 |
| page | 评论的页码 |
| size | 每次请求多少条评论 |
代码函数功能
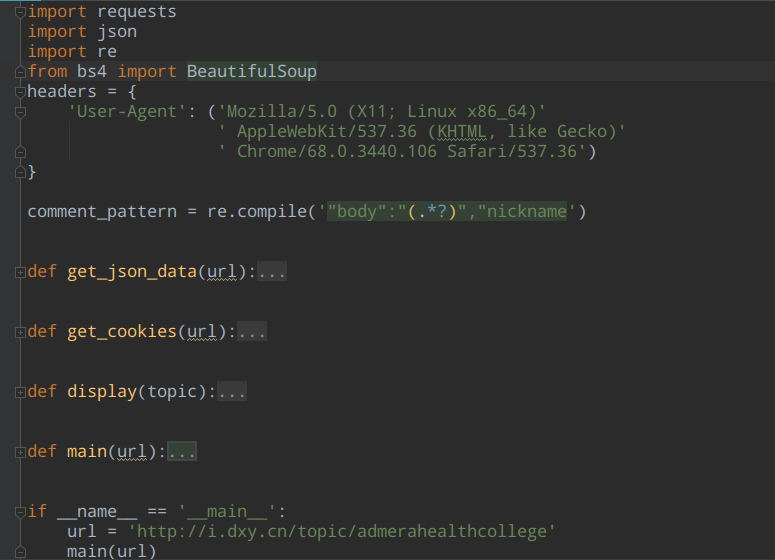
get_json_data:获取评论的数据(用户名,用户头像地址,用户所在城市,评论内容)get_cookies:获取cookies,以备设置JUTE_TOKEN参数值display: 显示提取的最终数据main:主模块,负责调用以上三个函数
完整代码
import requests
import json
import re
from bs4 import BeautifulSoup
"""
爬取: http://i.dxy.cn/topic/admerahealthcollege
爬取丁香园:丁香园是用 js 接口加载信息的,即直接请求上面的网址
得到的只是一个模板文件
通过浏览器开发者工具可以看到其加载信息的接口为
http://i.dxy.cn/topic/admerahealthcollege/feeds/list?JUTE_TOKEN=f79d77be-f161-4b2a-bc87-b20271b018ba&type=0&page=1&size=20
可以发现的是有三个请求参数 JSTE_TOKEN type page size
url: http://i.dxy.cn/topic/admerahealthcollege/feeds/list
JSTE_TOKE 是第一次请求服务器响应的 cookies 之一
type 默认为 0
page 评论的页码
size 每次请求多少条评论
"""
headers = {
'User-Agent': ('Mozilla/5.0 (X11; Linux x86_64)'
' AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/68.0.3440.106 Safari/537.36')
}
comment_pattern = re.compile('"body":"(.*?)","nickname')
def get_json_data(url):
"""
:param url: api
:return: comment dict
comment
nickname 作键值
avator 头像 url 地址
body 评论内容
city 用户省份
"""
comment = []
tarage_index = 1
while True:
target_url = url.format(tarage_index)
resp = requests.get(target_url, headers=headers)
resp_dict = json.loads(resp.content.decode("utf-8"))
if len(resp_dict['items']) == 0:
break
for item in resp_dict['items']:
body = re.search(comment_pattern, item['content']).group(1)
comment.append({item['nickname']: {'avator': item['infoAvatar'], 'body': body, 'city': item['city']}})
tarage_index += 1
return comment
def get_cookies(url):
# 获取 cookies
resp = requests.get(url, headers=headers)
for k, v in resp.cookies.items():
headers[k] = v
resp.encoding = 'utf-8'
return resp.text
def display(topic):
"""
topic: 字典,键值有 topic info comment
topic key 主题名
info key 主题介绍
comment key 相关评论
"""
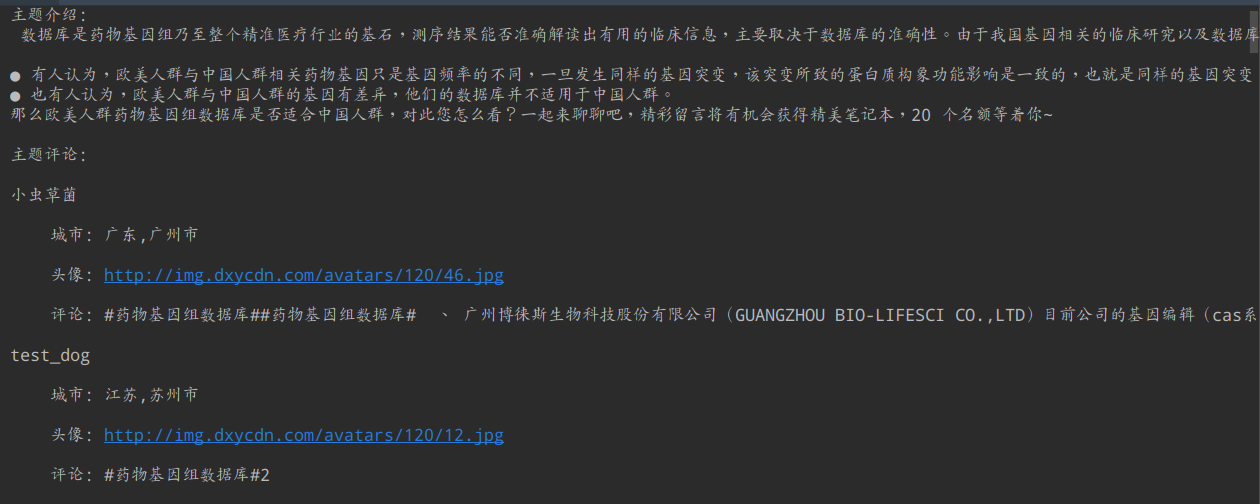
print("主题:\n", topic['topic'])
print("主题介绍:\n", topic['info'])
print("主题评论:\n")
for item in topic['comment']:
for k, v in item.items():
print(k, '\n')
print("\t城市:", v['city'], '\n')
print('\t头像:', v['avator'], '\n')
print('\t评论:', v['body'], '\n')
def main(url):
html = get_cookies(url)
soup = BeautifulSoup(html, 'lxml')
topic = {}
# 设置 json 接口的 host, JUTE_TOKEN, page 先设为占位符
topic['topic'] = soup.select('#topic-con > div.brief > h2 > a')[0].text
topic['info'] = soup.select('#topic-con > div.brief > p')[0].text
js_url = '{}/feeds/list?JUTE_TOKEN={}&type=0&page={}&size=20'.format(url, headers['JUTE_TOKEN'], '{}')
topic['comment'] = get_json_data(js_url)
display(topic)
if __name__ == '__main__':
url = 'http://i.dxy.cn/topic/admerahealthcollege'
main(url)
结果图
参考资料
Beautifulsoup提取特定丁香园帖子回复的更多相关文章
- DDD实践问题之 - 关于论坛的帖子回复统计信息的更新的思考
之前,在用ENode开发forum案例时,遇到了关于如何实现论坛帖子的回复的统计信息如何更新的问题.后来找到了自己认为比较合理的解决方案,分享给大家.也希望能和大家交流,擦出更多的火花. 论坛核心领域 ...
- 论文系统Step1:从日志记录中提取特定信息
论文系统Step1:从日志记录中提取特定信息 前言 论文数据需要,需要实现从服务器日志中提取出用户的特定交互行为信息.日志内容如下: 自己需要获取"请求数据包一行的信息"及&quo ...
- 一个通用的php正则表达式匹配或检测或提取特定字符类
在php开发时,日常不可或缺地会用到正则表达式,可每次都要重新写,有时忘记了某一函数还要翻查手册,所以,抽空写了一个关于日常所用到的正则表达式区配类,便于随便移置调用.(^_^有点偷懒). /*/ ...
- 使用Beautifulsoup去除特定标签
使用Beautifulsoup去除特定标签 试用了Beautifulsoup,的确是个神器. 在抓取到网页时,会出现很多不想要的内容,例如<script>标签,利用beautifulsou ...
- python beautifulsoup获取特定html源码
beautifulsoup 获取特定html源码(无需登录页面) import refrom bs4 import BeautifulSoupimport urllib2 url = 'http:// ...
- Java用来进行批量文件重命名,批量提取特定类型文件
原因: 因为在网上下载视频教程,有的名字特别长,一般都是机构或者网站的宣传,不方便直接看到视频的简介,所以做了下面的第一个功能. 因为老师发的课件中,文件夹太多,想把docx都放在同一个文件夹下面,一 ...
- jmeter正则表达式提取器提取特定字符串后的全部内容
jmeter进行JDBC请求时,请求后的响应结果在传递给下一个请求使用时,需要用到关联,也在jmeter中,关联通过正则表达式提取器实现. 但是,在JDBC请求后的响应结果中,往往需要关联的内容是只有 ...
- python 利用正则表达的式提取特定数据如手机号
import re file=open('1.txt','r') listfile=file.readlines() listfile=','.join(listfile)#合并文本 listfile ...
- js 提取特定的时间区间段
项目中遇到问题,需要根据用户的选择提取出一个时间的区间段,然后对后台进行请求. 基本思路,先根据new Date()对象求出start_time和end_time时间戳,然后把时间戳转化成new Da ...
随机推荐
- UIRecorder环境搭建及录制实现
前天看TesterHome提到UI录制做UI自动化,很感兴趣,前来学习学习. 参考:https://github.com/alibaba/uirecorder/blob/master/doc/zh-c ...
- luogu1063 能量项链
题目大意 有一串项链,项链上的每个珠子有首尾两个数字,首尾相连的两个珠子的尾数字和头数字相同.每次选择相连的一对珠子,得到第一个项链的首数字*第一个项链的尾数字(第二个项链的首数字)*第二个项链的尾数 ...
- E20170911-hm
specification n. 规格; 说明书; 详述;
- OOM三种类型
OOM的三种类型: 堆OOM /** * -Xmx1g -XX:+PrintGCDetails -XX:MaxDirectMemorySize=100m * * @param args */ publ ...
- 从flink-example分析flink组件(1)WordCount batch实战及源码分析
上一章<windows下flink示例程序的执行> 简单介绍了一下flink在windows下如何通过flink-webui运行已经打包完成的示例程序(jar),那么我们为什么要使用fli ...
- Nightmare --- 炸弹时间复位
题目大意: 该题为走迷宫,其条件有如下6个: 1, 迷宫用二维数组来表示: 2, 人走动时不能越界,不能在墙上走: 3, 当走到出口时,若剩余时间恰好为0,则失败: 4, 找到炸弹复位装置,若剩余时间 ...
- android 可拖动控件 ontouchevent
首先附上文章的转载内容的链接: 学习android 可拖动事件首先需要对android的屏幕和touchevent参数建立一个详细的知识结构. 1.android坐标系统 一.首先明确一下 andro ...
- Spring Boot (21) 使用Swagger2构建restful API
使用swagger可以与spring mvc程序配合组织出强大的restful api文档.它既可以减少我们创建文档的工作量,同时说明内容又整合入现实代码中,让维护文档和修改代码整合为一体,可以让我们 ...
- jQuery学习笔记之概念(1)
jQuery学习笔记之概念(1) ----------------------学习目录-------------------- 1.概念 2.特点 3.选择器 4.DOM操作 5.事件 6.jQuer ...
- android中复制图片
activity_main.xml中的配置 <LinearLayout xmlns:android="http://schemas.android.com/apk/res/androi ...