[机器学习]Generalized Linear Model
最近一直在回顾linear regression model和logistic regression model,但对其中的一些问题都很疑惑不解,知道我看到广义线性模型即Generalized Linear Model后才恍然大悟原来这些模型是这样推导的,在这里与诸位分享一下,具体更多细节可以参考Andrew Ng的课程。
一、指数分布
广义线性模型都是由指数分布出发来推导的,所以在介绍GLM之前先讲讲什么是指数分布。指数分布的形式如下:

η是参数,T(y)是y的充分统计量,即T(y)可以完全表达y,通常T(y)=y。当参数T,b,a都固定的时候,就定义了一个以η为参数的参数簇。实际上,很多的概率分布都是属于指数分布,比如:
(1)伯努利分布
(2)正态分布
(3)泊松分布
(4)伽马分布
等等等。。。。
或许从原本的形式上看不出来他们是指数分布,但是经过一系列的变换之后,就会发现他们都是指数分布。举两个例子,顺便我自己也推导一下。
伯努利分布:
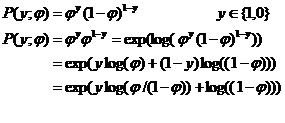
那么b(y)=1,T(y)=y,η=log(φ/(1-φ)),a(η)=log((1-φ)),则φ=1/(1+e-y),这个就是sigmoid函数的由来。
同样我们对正态分布做变换,不过在这里我们要假设方差为1,以为方差并不影响我们的回归。
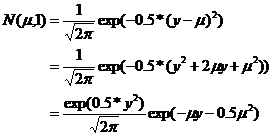
我们可以看到η=µ。
二、广义线性模型
介绍完指数分布后我们可以来看看广义线性模型是怎样的。
首先广义线性模型有三个假设,这三个假设即是前提条件也是帮助我们构造模型的关键。
(1)P(y|x;θ)~ExpFamliy(η);
(2)对于一个给定x,我们的目标函数为h(x)=E[T(y)|x];
(3)η=ΘTx
根据以上三个假设我们就能推导出logistic model 和 最小二乘模型。Logistic model 推导如下:
h(x)=E[T(y)|x]=E[y|x]=φ=1/(1+e-η)=1/(1+e-ΘTx)
对于最小二乘模型推导如下:
h(x)=E[T(y)|x]=E[y|x]=η=µ=ΘTx
从中我们将把η和原模型参数联系起来的函数称之为正则响应函数。所以对于广义线性模型,我们需要y是怎样的分布,就能推导出相应的模型。有兴趣的可以从多项式分布试试推导出SoftMax回归。
[机器学习]Generalized Linear Model的更多相关文章
- Bayesian generalized linear model (GLM) | 贝叶斯广义线性回归实例
一些问题: 1. 什么时候我的问题可以用GLM,什么时候我的问题不能用GLM? 2. GLM到底能给我们带来什么好处? 3. 如何评价GLM模型的好坏? 广义线性回归啊,虐了我快几个月了,还是没有彻底 ...
- 广义线性模型(Generalized Linear Model)
广义线性模型(Generalized Linear Model) http://www.cnblogs.com/sumai 1.指数分布族 我们在建模的时候,关心的目标变量Y可能服从很多种分布.像线性 ...
- 广义线性模型(GLM, Generalized Linear Model)
引言:通过高斯模型得到最小二乘法(线性回归),即: 通过伯努利模型得到逻辑回归,即: 这些模型都可以通过广义线性模型得到.广义线性模型是把自变量的线性预测函数当作因变量的估计值.在 ...
- 从线性模型(linear model)衍生出的机器学习分类器(classifier)
1. 线性模型简介 0x1:线性模型的现实意义 在一个理想的连续世界中,任何非线性的东西都可以被线性的东西来拟合(参考Taylor Expansion公式),所以理论上线性模型可以模拟物理世界中的绝大 ...
- Andrew Ng机器学习公开课笔记 -- Generalized Linear Models
网易公开课,第4课 notes,http://cs229.stanford.edu/notes/cs229-notes1.pdf 前面介绍一个线性回归问题,符合高斯分布 一个分类问题,logstic回 ...
- [Scikit-learn] 1.5 Generalized Linear Models - SGD for Classification
NB: 因为softmax,NN看上去是分类,其实是拟合(回归),拟合最大似然. 多分类参见:[Scikit-learn] 1.1 Generalized Linear Models - Logist ...
- [Scikit-learn] 1.1 Generalized Linear Models - Logistic regression & Softmax
二分类:Logistic regression 多分类:Softmax分类函数 对于损失函数,我们求其最小值, 对于似然函数,我们求其最大值. Logistic是loss function,即: 在逻 ...
- Regression:Generalized Linear Models
作者:桂. 时间:2017-05-22 15:28:43 链接:http://www.cnblogs.com/xingshansi/p/6890048.html 前言 本文主要是线性回归模型,包括: ...
- Generalized Linear Models
作者:桂. 时间:2017-05-22 15:28:43 链接:http://www.cnblogs.com/xingshansi/p/6890048.html 前言 主要记录python工具包:s ...
随机推荐
- ACCESS通过一个连接写入的数据,还有一个连接却读取不出来
近期在用c#实现一个数据导入的功能,将一个ACCESS数据库中的数据导入到还有一个ACCESS的数据库中,然后显示出来,可是导入成功了.却显示不出来. 经过研究认为应该是缓存的原因,因为我写入数据和读 ...
- UIlabel文字大小自适应label宽度变大变小
label.adjustsFontSizeToFitWidth = YES; //默认no
- 51nod1673 树有几多愁 - 贪心策略 + 虚树 + 状压dp
传送门 题目大意: 给一颗重新编号,叶子节点的值定义为他到根节点编号的最小值,求所有叶子节点值的乘积的最大值. 题目分析: 为什么我觉得这道题最难的是贪心啊..首先要想到 在一条链上,深度大的编号要小 ...
- 亲测有效,解决Can 't connect to local MySQL server through socket '/tmp/mysql.sock '(2) ";
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/hjf161105/article/details/78850658 最近租了一个阿里云云翼服务器,趁 ...
- Codeforces 385 D Bear and Floodlight
主题链接~~> 做题情绪:时候最后有点蛋疼了,处理点的坐标处理晕了.so~比赛完清醒了一下就AC了. 解题思路: 状态压缩DP ,仅仅有 20 个点.假设安排灯的时候仅仅有顺序不同的问题.全然能 ...
- Qt常用函数 记录(update erase repaint 的区别)
一界面重载函数使用方法:1在头文件里定义函数protected: void paintEvent(QPaintEvent *event); 2 在CPP内直接重载void ----------::pa ...
- 学习 NLP(一)—— TF-IDF
TF-IDF(Term Frequency & Inverse Document Frequency),是一种用于信息检索与数据挖掘的常用加权技术.它的主要思想是:如果某个词或短语在一篇文章中 ...
- 学习Hadoop和Spark的好的资源
1. 官网http://spark.apache.org 有各种资源链接: 2. 总结得很好的个人博客[从零开始学Hadoop系列]1)初识http://blog.csdn.net/u01016816 ...
- Dijkstra含权图最短路径;审判,不要错过枚举退款保证不会重复;国际象棋八皇后问题
求两节点的最短通路.对于无权图,能够通过图的广度优先遍历求解.含权图一般通过Dijkstra算法求解. import java.util.ArrayList; import java.util.Has ...
- window下nodejs爬取gb2312网页出现乱码的解决方案
发布于 2012-8-22 18:15 5230 次浏览 最后一次编辑是 2013-2-18 22:31 linux环境下,我们可以通过 iconv 这个C++模块来处理Node.JS不支持的字 ...