聚类算法学习-kmeans,kmedoids,GMM
GMM参考这篇文章:Link
简单地说,k-means 的结果是每个数据点被 assign 到其中某一个 cluster 了,而 GMM 则给出这些数据点被 assign 到每个 cluster 的概率,又称作 soft assignment 。
通常单个点的概率都很小,许多很小的数字相乘起来在计算机里很容易造成浮点数下溢,因此我们通常会对其取对数,把乘积变成加和  ,得到 log-likelihood function 。
,得到 log-likelihood function 。
因此也有和 K-means 同样的问题──并不能保证总是能取到全局最优,如果运气比较差,取到不好的初始值,就有可能得到很差的结果。
对于 K-means 的情况,我们通常是重复一定次数然后取最好的结果,不过 GMM 每一次迭代的计算量比 K-means 要大许多,一个更流行的做法是先用 K-means (已经重复并取最优值了)得到一个粗略的结果,然后将其作为初值(只要将 K-means 所得的 centroids 传入 gmm 函数即可),再用 GMM 进行细致迭代。
K-medoids参考这篇文章:Link
k-means 和 k-medoids 之间的差异就类似于一个数据样本的均值 (mean) 和中位数 (median) 之间的差异:前者的取值范围可以是连续空间中的任意值,而后者只能在给样本给定的那些点里面选。
一个最直接的理由就是 k-means 对数据的要求太高了,它使用欧氏距离描述数据点之间的差异 (dissimilarity) ,从而可以直接通过求均值来计算中心点。这要求数据点处在一个欧氏空间之中。
然而并不是所有的数据都能满足这样的要求,对于数值类型的特征,比如身高,可以很自然地用这样的方式来处理,但是类别 (categorical) 类型的特征就不行了。举一个简单的例子,如果我现在要对犬进行聚类,并且希望直接在所有犬组成的空间中进行,k-means 就无能为力了,因为欧氏距离  在这里不能用了:一只 Samoyed 减去一只 Rough Collie 然后在平方一下?天知道那是什么!再加上一只 German Shepherd Dog 然后求一下平均值?根本没法算,k-means 在这里寸步难行!
在这里不能用了:一只 Samoyed 减去一只 Rough Collie 然后在平方一下?天知道那是什么!再加上一只 German Shepherd Dog 然后求一下平均值?根本没法算,k-means 在这里寸步难行!
最常见的方式是构造一个 dissimilarity matrix  来代表
来代表  ,其中的元素
,其中的元素  表示第
表示第  只狗和第
只狗和第  只狗之间的差异程度,例如,两只 Samoyed 之间的差异可以设为 0 ,一只 German Shepherd Dog 和一只 Rough Collie 之间的差异是 0.7,和一只 Miniature Schnauzer 之间的差异是 1 ,等等。
只狗之间的差异程度,例如,两只 Samoyed 之间的差异可以设为 0 ,一只 German Shepherd Dog 和一只 Rough Collie 之间的差异是 0.7,和一只 Miniature Schnauzer 之间的差异是 1 ,等等。
除此之外,由于中心点是在已有的数据点里面选取的,因此相对于 k-means 来说,不容易受到那些由于误差之类的原因产生的 Outlier 的影响,更加 robust 一些。
就会发现,从 k-means 变到 k-medoids ,时间复杂度陡然增加了许多:在 k-means 中只要求一个平均值  即可,而在 k-medoids 中则需要枚举每个点,并求出它到所有其他点的距离之和,复杂度为
即可,而在 k-medoids 中则需要枚举每个点,并求出它到所有其他点的距离之和,复杂度为  。
。
同样也可能陷入局部最优:
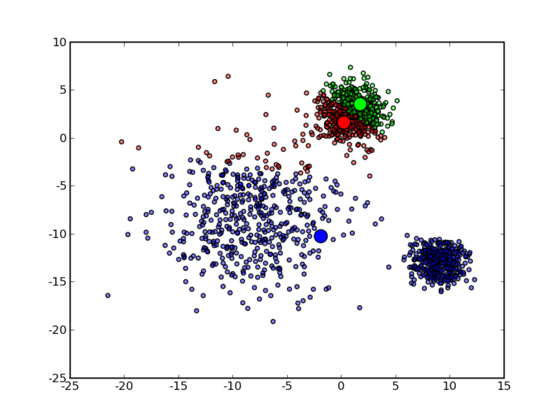
然后作者用了一个文本分类来结束文章。里面还提到了一个 N-Gram:
在 N-gram-based text categorization 这篇 paper 中描述了一种计算由不同语言写成的文档的相似度的方法。一个(以字符为单位的) N-gram 就相当于长度为 N 的一系列连续子串。例如,由 hello 产生的 3-gram 为:hel、ell 和 llo ,有时候还会在划分 N-gram 之前在开头和末尾加上空格(这里用下划线表示):_he、hel、ell、llo、lo_ 和 o__ 。按照 Zipf’s law :
The nth most common word in a human language text occurs with a frequency inversely proportional to n.
这里我们用 N-gram 来代替 word 。这样,我们从一个文档中可以得到一个 N-gram 的频率分布,按照频率排序一下,只保留频率最高的前 k 个(比如,300)N-gram,我们把叫做一个“Profile”。正常情况下,某一种语言(至少是西方国家的那些类英语的语言)写成的文档,不论主题或长短,通常得出来的 Profile 都差不多,亦即按照出现的频率排序所得到的各个 N-gram 的序号不会变化太大。这是非常好的一个性质:通常我们只要各个语言选取一篇(比较正常的,也不需要很长)文档构建出一个 Profile ,在拿到一篇未知文档的时候,只要和各个 Profile 比较一下,差异最小的那个 Profile 所对应的语言就可以认定是这篇未知文档的语言了——准确率很高,更可贵的是,所需要的训练数据非常少而且容易获得,训练出来的模型也是非常小的。
聚类算法学习-kmeans,kmedoids,GMM的更多相关文章
- 聚类算法K-Means, K-Medoids, GMM, Spectral clustering,Ncut
原文请戳:http://blog.csdn.net/abcjennifer/article/details/8170687 聚类算法是ML中一个重要分支,一般采用unsupervised learni ...
- 聚类算法K-Means, K-Medoids, GMM, Spectral clustering,Ncut
聚类算法是ML中一个重要分支,一般采用unsupervised learning进行学习,本文根据常见聚类算法分类讲解K-Means, K-Medoids, GMM, Spectral cluster ...
- 机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记
机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记 关键字:k-均值.kMeans.聚类.非监督学习作者:米仓山下时间: ...
- 聚类算法与K-means实现
聚类算法与K-means实现 一.聚类算法的数学描述: 区别于监督学习的算法(回归,分类,预测等),无监督学习就是指训练样本的 label 未知,只能通过对无标记的训练样本的学习来揭示数据的内在规律和 ...
- 浅谈聚类算法(K-means)
聚类算法(K-means)目的是将n个对象根据它们各自属性分成k个不同的簇,使得簇内各个对象的相似度尽可能高,而各簇之间的相似度尽量小. 而如何评测相似度呢,采用的准则函数是误差平方和(因此也叫K-均 ...
- 聚类算法:K-means
2013-12-13 20:00:58 Yanjun K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离 ...
- 聚类算法之K-means
想想常见的分类算法有决策树.Logistic回归.SVM.贝叶斯等.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应.但是很多时候上述条件得不到满 ...
- [数据挖掘] - 聚类算法:K-means算法理解及SparkCore实现
聚类算法是机器学习中的一大重要算法,也是我们掌握机器学习的必须算法,下面对聚类算法中的K-means算法做一个简单的描述: 一.概述 K-means算法属于聚类算法中的直接聚类算法.给定一个对象(或记 ...
- 机器学习算法总结(五)——聚类算法(K-means,密度聚类,层次聚类)
本文介绍无监督学习算法,无监督学习是在样本的标签未知的情况下,根据样本的内在规律对样本进行分类,常见的无监督学习就是聚类算法. 在监督学习中我们常根据模型的误差来衡量模型的好坏,通过优化损失函数来改善 ...
随机推荐
- Java - 经常使用函数Random函数
http://blog.csdn.net/pipisorry/article/details/44411541 Random()函数生成随机数 java.util.Random 在Java的API帮助 ...
- Unity3D - 图形性能优化:优化着色器载入时间
Unity官方文档之"图形性能优化-优化着色器载入时间"的翻译,E文链接. Optimizing Shader Load Time 优化着色器载入时间 Shaders are sm ...
- hdu2688 Rotate(树状数组)
题目链接:pid=2688">点击打开链接 题意描写叙述:对一个长度为2<=n<=3000000的数组,求数组中有序对(i<j而且F[i]<F[j])的数量?其 ...
- CSS初步理解
近期在学习牛腩的时候遇到了网页的制作.挺新奇的.其中涉及到了有关CSS的知识,于是乎自己也就花费两个小时的时间.找了本浅显易懂的书来看了一遍,从宏观上来了解CSS的相关内容.有关CSS的基础知识详见下 ...
- MySQL具体解释(8)----------MySQL线程池总结(二)
这篇文章是对上篇文章的一个补充,主要环绕下面两点展开.one-connection-per-thread的实现方式以及线程池中epoll的使用. one-connection-per-thread 依 ...
- Nginx系列(三)--管理进程、多工作进程设计
Nginx由一个master进程和多个worker进程组成,但master进程或者worker进程中并不会再创建线程. 一.master进程和worker进程的作用 master进程 不须要处理网络事 ...
- dnscapy使用——本质上是建立ssh的代理(通过dns tunnel)
git clone https://github.com/cr0hn/dnscapy.git easy_install Scapy 服务端: python dnscapy_server.py a.fr ...
- BZOJ 1818 线段树+扫描线
思路: 可以把题目转化成 给你一些沿坐标轴方向的线段 让你求交点个数 然后就线段树+扫描线 搞一搞 (线段不包含断点 最后+n 这种方式 比线段包含断点+各种特判要好写得多) //By SiriusR ...
- POJ 2771 最大独立集 匈牙利算法
(为什么最大独立集的背景都是严打搞对象的( _ _)ノ|壁) 思路:匈牙利算法 没什么可说的-- // by SiriusRen #include <cstdio> #include &l ...
- java8 Lambad表达式自己的例子
service层方法 public <E> E outer(Function<Session, E> function) { return dao.outer(function ...