Yolov3代码分析与训练自己数据集
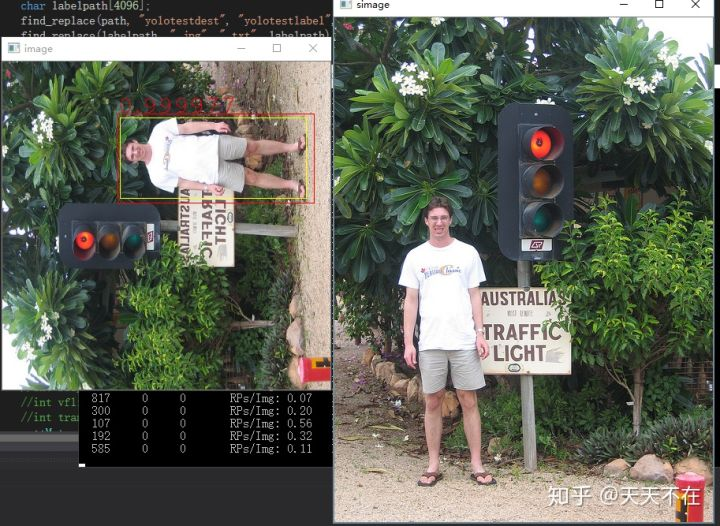
现在要针对我们需求引入检测模型,只检测人物,然后是图像能侧立,这样人物在里面占比更多,也更清晰,也不需要检测人占比小的情况,如下是针对这个需求,用的yolov3-tiny模型训练后的效果。
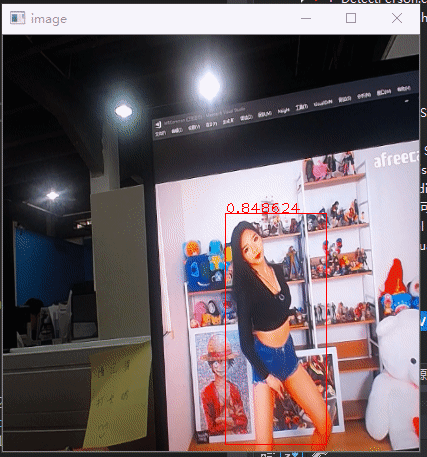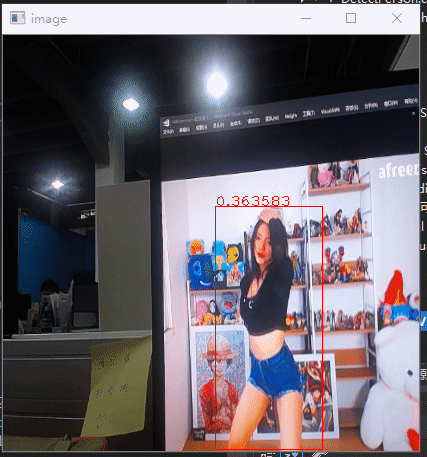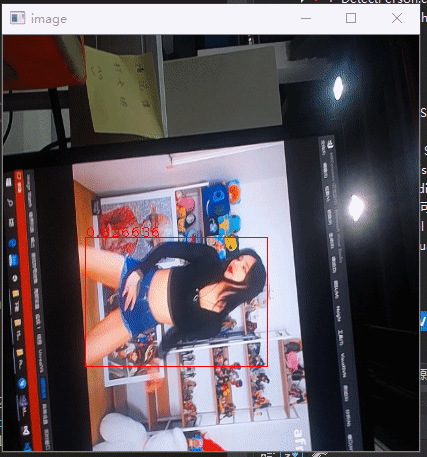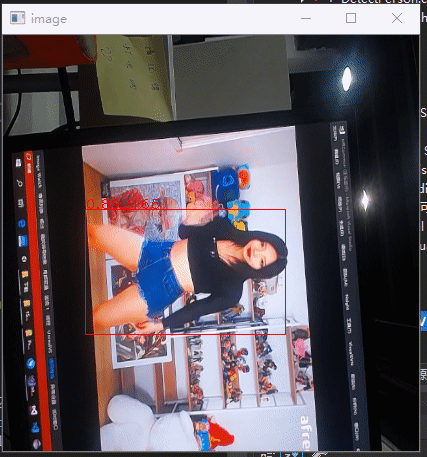
Yolov3模型网上也讲烂了,但是总感觉不看代码,不清楚具体实现看讲解总是不清晰,在这分析下darknet的实现,给自己解惑,顺便也做个笔记。
首先查看打开yolov3.cfg,我们看下网络,可以用netron查看图形界面,可以发现网络主要以卷积层构成,shortcut(残差连接),route(通道组合)三种构成,首先用步长为2的卷积缩小图像一次,然后开始用shortcut(残差连接)连接一次再用步长为2的卷积缩小图像缩小二次,后面开始不断用卷积与残差组合,到开始分支,分出二个部分,每分出一个分支就把主支图像缩小次,最后加上主支部分一共三个分支,就是一共有3个yolo层,其中主支部分缩小了五次,第一次分支缩小三次,第二次分支缩小四次。
这里也解答了以前我的一个疑惑,从ResNet网络开始,开始隔层交流,不管是相加还是整合,我疑惑的是如何在文件这种列表形式下描述分支结构,原来很简单,一次描述一个分支,然后用route/shortcut记录分支层,继续向下描述。
回到网络部分,这三次分支可以用这图表示,网络上不知谁的,确实表达了很多要说的,不过有个问题,应该是版本更新了,我手上配置拿的是长宽是608*608,所以下图需要改一些,如13*13是19*19,大家明白就行,还有主支是32(2^5)倍那个,16与8是第二分支与第一分支,其中先算主支部分,算完主支然后上层卷积层upsample再与第二分支route一起算,第一分支同这逻辑。
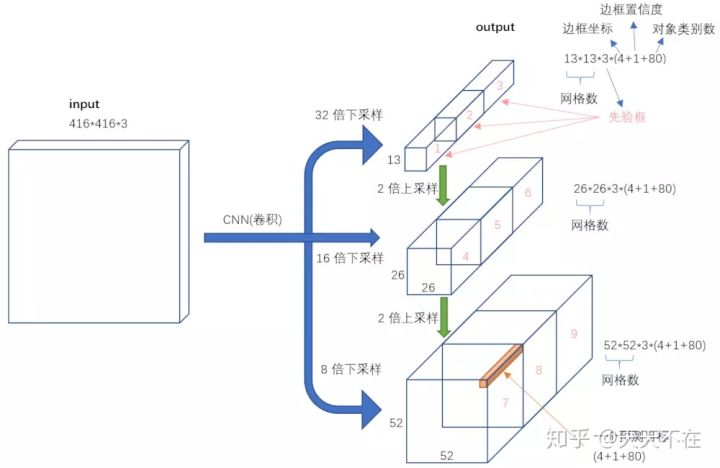

这个yolo层就是主支部分,可以看如上分析,在这层特征图长宽只有19*19,对应如上 anchors中是根据k-means算法拿到对应图集K=9的分类簇框,其中mask=6,7,8指向最后三个大框,主支部分主要检测大物体,根据前面分析可以知道中框包含了大框的特征图结果,而小框包含中大的特征图结果,这应该yolov3相比v2针对小物体的识别提高的原因,而shortcut与route则保证网络能加深到一百多层。
darknet种各层的主要有三个函数,分别是make_xxx_layer, forward_xxx_layer, backward_xxx_layer, 这三个函数make_xxx_layer是初始各种参数,根据参数自动算一些参数,如卷积层,根据传入特征图的大小与核的参数,就能算出传出特征图的大小,以及申请内存或是显存,forward_xxx_layer表示根据当前层参数计算预测,而backward_xxx_layer根据上层的delta(如上层是yolo层,delta就表示期望输出-预测输出)与输入计算梯度,并更新下层需要的delta,以及还有个update_xxx_layer用于根据backward_xxx_layer计算的梯度来更新参数。而yolo,region,detection,softmax这几种检测层相对卷积层来说,没有参数weight,主要用来计算delta(期望输出-预测输出).而反向传播就是从这个yolo的delta开始的,在yolo的反向传播中,先把这个delta给卷积层的delta,然后结合前一层的输出,求得当前层的梯度,并把delta结合当前层的weights求得新的delta,然后下一层卷积层根据这个delta梯度,循环下去更新所有参数。
下面根据代码来分析yolov层,先看下make_yolo_layer的实现。
//在yolov3中,n=3 total=9(mask在yolov3中分三组,分别是[0,1,2/3,4,5/6,7,8],n表示分组里几个数据,n*3=total)
//608*608下,第一组是19*19,第二组是38*38,第三组是76*76,每组检查对应索引里的anchors
layer make_yolo_layer(int batch, int w, int h, int n, int total, int *mask, int classes)
{
//在这假设在主支中,其中缩小5次,608/(2^5)=19,这个分支中,w=h=19
int i;
layer l = { };
l.type = YOLO;
//检测几种类型边框(这分支对应上面anchors[6,7,8]这个用来检测大边框)
l.n = n;
//如上,在yolov3中,有大中小分别有三个边框聚合,一共是3*3=9
//而在yolov3-tiny中,有大小分别三个边框聚合,一共是3*2=6
l.total = total;
//一般来说,训练为32,预测为1
l.batch = batch;
//主支,608/(2^5)=19
l.h = h;
l.w = w;
//如上在主支中,每张特征图有19*19个元素,c表示特征图个数,n表示对应的anchors[6,7,8]这三个
//4表示box坐标,1是Po(预测机率与IOU正确率)的概率,classes是预测的类别数
l.c = n * (classes + + );
l.out_w = l.w;
l.out_h = l.h;
l.out_c = l.c;
//检测一共有多少个类别
l.classes = classes;
//计算代价(数据集整体的误差描述)
l.cost = calloc(, sizeof(float));
//对应表示anchors
l.biases = calloc(total * , sizeof(float));
//对应如上anchors中n对应需要用到的索引
if (mask) l.mask = mask;
else {
l.mask = calloc(n, sizeof(int));
for (i = ; i < n; ++i) {
l.mask[i] = i;
}
}
l.bias_updates = calloc(n * , sizeof(float));
//当前层batch为1的所有输出特征图包含的元素个数,每个元素为一个float
l.outputs = h * w*n*(classes + + );
//当前层batch为1时所有输入特征图包含的元素个数,每个元素为一个float
l.inputs = l.outputs;
//标签(真实)数据,这里90表示如上w*h(19*19中)每个格子最多有90个label。
//而每个label前面4个float表示box的四个点,后面1个float表示当前类别
l.truths = * ( + );
//计算误差(数据单个的误差描述),用来表示 期望输出-真实输出
l.delta = calloc(batch*l.outputs, sizeof(float));
l.output = calloc(batch*l.outputs, sizeof(float));
for (i = ; i < total * ; ++i) {
l.biases[i] = .;
} l.forward = forward_yolo_layer;
l.backward = backward_yolo_layer;
#ifdef GPU
l.forward_gpu = forward_yolo_layer_gpu;
l.backward_gpu = backward_yolo_layer_gpu;
l.output_gpu = cuda_make_array(l.output, batch*l.outputs);
l.delta_gpu = cuda_make_array(l.delta, batch*l.outputs);
#endif fprintf(stderr, "yolo\n");
srand(); return l;
}
make_yolo_layer
以主支来做分析,每张特征图有19*19个元素,c表示特征图个数,结合上图,一共有3*(80+4+1)=255,简单来说,分别对应116,90, 156,198, 373,326这三个聚类簇,其中前85个就是116,90这框的结果,其中前85个就是116,90这框的结果,85个特征图中前4个是边框坐标,1个置信度,80个类别概率,一共三个这种85特征图就是255个,还有标签(真实)数据,这里90表示如上w*h(19*19中)每个格子最多有90个label,而每个label前面4个float表示box的四个点,后面1个float表示当前类别,搞清楚这二个对应排列,在如下的forward_yolo_layer里,我们才能明白如何计算的delta,代码加上注释有点多,这段就不贴了,代码部分说明下。
主要有二部分,还是先说下,在这里delta表示 期望输出-out(不同框架可能不同,我看caffe里的yolo实现,就是out-期望输出)。
第一部分,前面查找所有特征图(在这1batch是三张)里的所有元素(19*19)里的所有confidence,准确来说是主支的19*19个元素,每个元素有三个大框预测,检测对应所有框里真实数据最好的box的iou,如果iou大于设定的ignore_thresh,则设delta为0,否则就是0-out(0表示没有,我们期望输出是0)。
第二部分,在对照所有真实label中,先找到这个label是否是大框,如果不是,这个yolo层不管,如果是,继续看是上面6,7,8中的那一个,我们假设是7,根据真实框的位置确定在特征图的位置(19*19中),其对应255张特征图中间的85-170这85张图,然后比较真实的BOX与对应特征图预测的box,算出对应box的 delta,然后是confidence的delta(可以知道,正确的box位置上的元素会算二次confidence损失),然后是类别的delta。各delta比较简单,如果认为是真的,delta=1-out,如果是错的,delta=0-out,简单来说就是期望输出-out,最后网络cost就是每层yolo的delta的平方和加起来的均值。
然后是yolo训练时输出的各项参数(这图用的是yolov3-tiny训练,所以只有16和23这二个yolo层),对比如上16层检测大的,23检测小的。

可以看到,count是表示当前层与真实label正确配对的box数,其中所有参数都是针对这个值的平均值,除no obj外,不过从代码上来,这个参数意义并不大,所以当前yolo层如果出现nan这个的打印,也是正常的,只是表示当前batch刚好所有图片都是大框或是小框,所以提高batch的数目可以降低nan出现的机率,不过相应的是,batch提高,可能显存就暴了,我用的2070一次用默认的64张显存就不够,只能改成32张。其中avg iou表示当前层正确配对的box的交并比的平均值,class表示表示当前层正确配对类别的平均机率,obj表示confidence = P(object)* IOU,表示预测box包含对象与IOU好坏的评分,0.5R/0.7R:表示iou在0.5/0.7上与正确配对的box的比率。
搞明白darknet框架各层后,回到我们需求,引入检测模型,只检测人物,然后是图像能侧立,这样人物在里面占比更多,也更清晰,也不需要检测人占比小的情况。先说明下,用的yolov3-tiny,因为可能要每桢检查并不需要占太多资源,故使用简化模型。
首先筛选满足条件的数据集,本来准备用coco数据自带api分析,发现还麻烦些,数据全有了,逻辑并不复杂,用winform自己写了就行了。
/// <summary>
/// 数据经过funcFilterLabel过滤,过滤后的数据需要全部满足discardFilterLabel
/// </summary>
/// <param name="instData"></param>
/// <param name="funcFilterLabel">满足条件就采用</param>
/// <param name="discardFilterLabel">需要所有标签满足的条件</param>
/// <returns></returns>
public List<ImageLabel> CreateYoloLabel(instances instData,
Func<annotationOD, image, bool> funcFilterLabel,
Func<annotationOD, image, bool> discardFilterLabel)
{
List<ImageLabel> labels = new List<ImageLabel>();
//foreach (var image in instData.images)
Parallel.ForEach(instData.images, (image image) =>
{
var anns = instData.annotations.FindAll(p => p.image_id == image.id && funcFilterLabel(p, image));
bool bReserved = anns.TrueForAll((annotationOD ao) => discardFilterLabel(ao, image));
if (anns.Count > && bReserved)
{
ImageLabel iml = new ImageLabel();
iml.imageId = image.id;
iml.name = image.file_name;
float dw = 1.0f / image.width;
float dh = 1.0f / image.height;
foreach (var ann in anns)
{
BoxIndex boxIndex = new BoxIndex();
boxIndex.box.xcenter = (ann.bbox[] + ann.bbox[] / 2.0f) * dw;
boxIndex.box.ycenter = (ann.bbox[] + ann.bbox[] / 2.0f) * dh; boxIndex.box.width = ann.bbox[] * dw;
boxIndex.box.height = ann.bbox[] * dh;
//注册
boxIndex.catId = findCategoryId(instData.categories, ann.category_id);
if (boxIndex.catId >= )
iml.boxs.Add(boxIndex);
}
if (iml.boxs.Count > )
{
lock (labels)
{
labels.Add(iml);
}
}
} });
return labels;
} public async void BuildYoloData(DataPath dataPath, string txtListName)
{
instances instance = new instances();
if (!File.Exists(dataPath.AnnotationPath))
{
setText(dataPath.AnnotationPath + " 路径不存在.");
return;
}
setText("正在读取文件中:" + Environment.NewLine + dataPath.AnnotationPath);
var jsonTex = await Task.FromResult(File.ReadAllText(dataPath.AnnotationPath));
setText("正在解析文件中:" + Environment.NewLine + dataPath.AnnotationPath);
instance = await Task.FromResult(JsonConvert.DeserializeObject<instances>(jsonTex));
setText("正在分析文件包含人物图像:" + instance.images.Count + "个");
List<ImageLabel> labels = await Task.FromResult(COCODataManager.Instance.CreateYoloLabel(
instance,
(annotationOD at, image image) =>
{
//是否人类
return at.category_id == ;
},
(annotationOD at, image image) =>
{
//是否满足所有人类标签都面积占比都大于十分之一
return (at.bbox[] / image.width) * (at.bbox[] / image.height) > 0.1f;
}));
setText("正在生成label文件:" + Environment.NewLine + dataPath.LabelPath);
if (!Directory.Exists(dataPath.LabelPath))
{
Directory.CreateDirectory(dataPath.LabelPath);
}
await Task.Run(() =>
{
Parallel.ForEach(labels, (ImageLabel imageLabel) =>
{
string fileName = Path.Combine(dataPath.LabelPath,
Path.GetFileNameWithoutExtension(imageLabel.name) + ".txt");
using (var file = new StreamWriter(Path.Combine(dataPath.LabelPath, fileName), false))
{
foreach (var label in imageLabel.boxs)
{
file.WriteLine(label.catId + " " + label.box.xcenter + " " + label.box.ycenter +
" " + label.box.width + " " + label.box.height + " ");
}
}
});
string path = Path.Combine(Directory.GetParent(dataPath.LabelPath).FullName,
txtListName + ".txt");
using (var file = new StreamWriter(path, false))
{
foreach (var label in labels)
{
string lpath = Path.Combine(dataPath.DestImagePath, label.name);
file.WriteLine(lpath);
}
}
});
setText("正在复制需要的文件到指定目录:" + dataPath.AnnotationPath);
await Task.Run(() =>
{
Parallel.ForEach(labels, (ImageLabel imageLabel) =>
{
string spath = Path.Combine(dataPath.SourceImagePath, imageLabel.name);
string dpsth = Path.Combine(dataPath.DestImagePath, imageLabel.name);
if (File.Exists(spath))
File.Copy(spath, dpsth, true);
});
});
setText("全部完成");
}
CreateYoloLabel
只有一点需要注意,我们只记录人类box标签数据,但是这些标签需要全部大于特定面积的图,如果你选择的上面还有小面积人物,又不给box标签训练,最后yolo层并没面板的损失函数,会造成干扰,在这本来也没有检查小面积人物的需求,yolov3-tiny层数本也不多,需求泛化后精度很低。
darknet本身并没有针对侧立做适配,我们需要修改相应逻辑来完成,很简单,一张图四个方向旋转后,同样修改相应的truth box就行了是,darknet数据加载主要在data.c这部分,找到我们使用的加载逻辑load_data_detection里,主要针对如下修改。
data load_data_detection(int n, char **paths, int m, int w, int h, int boxes, int classes,
float jitter, float hue, float saturation, float exposure)
{
....................
random_distort_image(sized, hue, saturation, exposure); int flip = rand() % ;
if (flip)
flip_image(sized);
int vflip = rand() % ;
if (vflip)
vflip_image(sized);
int trans = rand() % ;
if (trans)
transpose_image(sized);
d.X.vals[i] = sized.data; fill_truth_detection(random_paths[i], boxes, d.y.vals[i], classes, flip,
-dx / w, -dy / h, nw / w, nh / h, vflip, trans); free_image(orig);
....................
} void correct_boxes(box_label *boxes, int n, float dx, float dy, float sx,
float sy, int flip, int vflip, int trans)
{
int i;
for (i = ; i < n; ++i) {
if (boxes[i].x == && boxes[i].y == ) {
boxes[i].x = ;
boxes[i].y = ;
boxes[i].w = ;
boxes[i].h = ;
continue;
}
boxes[i].left = boxes[i].left * sx - dx;
boxes[i].right = boxes[i].right * sx - dx;
boxes[i].top = boxes[i].top * sy - dy;
boxes[i].bottom = boxes[i].bottom* sy - dy; if (flip)
{
float swap = boxes[i].left;
boxes[i].left = . - boxes[i].right;
boxes[i].right = . - swap;
}
if (vflip)
{
float swap = boxes[i].top;
boxes[i].top = . - boxes[i].bottom;
boxes[i].bottom = . - swap;
} boxes[i].left = constrain(, , boxes[i].left);
boxes[i].right = constrain(, , boxes[i].right);
boxes[i].top = constrain(, , boxes[i].top);
boxes[i].bottom = constrain(, , boxes[i].bottom); boxes[i].x = (boxes[i].left + boxes[i].right) / ;
boxes[i].y = (boxes[i].top + boxes[i].bottom) / ;
boxes[i].w = (boxes[i].right - boxes[i].left);
boxes[i].h = (boxes[i].bottom - boxes[i].top); boxes[i].w = constrain(, , boxes[i].w);
boxes[i].h = constrain(, , boxes[i].h); if (trans)
{
float temp = boxes[i].x;
boxes[i].x = boxes[i].y;
boxes[i].y = temp;
temp = boxes[i].w;
boxes[i].w = boxes[i].h;
boxes[i].h = temp;
}
}
}
load_data_detection
然后拿到yolov3-tiny.cfg文件,先把burn_in修改成1,我们没有预精确数据,最开始就以原始学习率开始训练,对应二个yolo层里的classes改成一,记的前面说过,这个层就是分析上面的卷积层,故上面的输出filters=3*(4+1+1)=18,第一次训练后发现五W次就没怎么收敛了,分析了下,应该是anchors导致的,当图像侧立后,这里的也应该有类似数据,故选择全大面积人物二种特定框,分别取侧立,这里正确的搞法应该是用k-means再重新取K=2算一下所有现在特定图的框,分别对应大框与小框,然后侧立下,大框就有二个,小框二个,num=4,mask每层设二个索引,或是K=4,然后让上面来,后面抽出时间完善这步,现暂时用如下数据anchors = 100,100, 119,59, 59,119, 200,200, 326,373, 373,326,这些调整后,现训练21W次,也还一直收敛中。
训练与验证根据他自身的train_yolo/validata_yolo修改下,自己可以打印出自己想要的信息,验证可以结合opencv显示我们想要的各种图形比对效果。
Yolov3代码分析与训练自己数据集的更多相关文章
- tensorflow笔记:多层LSTM代码分析
tensorflow笔记:多层LSTM代码分析 标签(空格分隔): tensorflow笔记 tensorflow笔记系列: (一) tensorflow笔记:流程,概念和简单代码注释 (二) ten ...
- tensorflow笔记:多层CNN代码分析
tensorflow笔记系列: (一) tensorflow笔记:流程,概念和简单代码注释 (二) tensorflow笔记:多层CNN代码分析 (三) tensorflow笔记:多层LSTM代码分析 ...
- yolov5训练自定义数据集
yolov5训练自定义数据 step1:参考文献及代码 博客 https://blog.csdn.net/weixin_41868104/article/details/107339535 githu ...
- Android4.0图库Gallery2代码分析(二) 数据管理和数据加载
Android4.0图库Gallery2代码分析(二) 数据管理和数据加载 2012-09-07 11:19 8152人阅读 评论(12) 收藏 举报 代码分析android相册优化工作 Androi ...
- 手机自动化测试:Appium源码分析之跟踪代码分析五
手机自动化测试:Appium源码分析之跟踪代码分析五 手机自动化测试是未来很重要的测试技术,作为一名测试人员应该熟练掌握,POPTEST举行手机自动化测试的课程,希望可以训练出优秀的手机测试开发工 ...
- 实践详细篇-Windows下使用VS2015编译的Caffe训练mnist数据集
上一篇记录的是学习caffe前的环境准备以及如何创建好自己需要的caffe版本.这一篇记录的是如何使用编译好的caffe做训练mnist数据集,步骤编号延用上一篇 <实践详细篇-Windows下 ...
- 【转载】word2vec原理推导与代码分析
本文的理论部分大量参考<word2vec中的数学原理详解>,按照我这种初学者方便理解的顺序重新编排.重新叙述.题图来自siegfang的博客.我提出的Java方案基于kojisekig,我 ...
- 开源项目kcws代码分析--基于深度学习的分词技术
http://blog.csdn.net/pirage/article/details/53424544 分词原理 本小节内容参考待字闺中的两篇博文: 97.5%准确率的深度学习中文分词(字嵌入+Bi ...
- 使用py-faster-rcnn训练VOC2007数据集时遇到问题
使用py-faster-rcnn训练VOC2007数据集时遇到如下问题: 1. KeyError: 'chair' File "/home/sai/py-faster-rcnn/tools/ ...
随机推荐
- Js跨域小总结
教程 以下的例子包含的文件均为为http://www.a.com/a.html.http://www.a.com/c.html 与http://www.b.com/b.html ,要做的都是从a.ht ...
- 在当前页获取父窗口中母版页中的服务器控件的ID
parent.document.getElementById("ctl00_ContentPlaceHolder1_txt_name").value=""; A ...
- Android开发Eclipse中DDMS中Heap使用及GC_EXTERNAL_ALLOC含义
一.先说DDMS中的Heap的使用,通过可以观察VM中的Java内存,但是无法查看通过JNI分配的内存. 直接上图,废话少说... 图一:将要查看内存使用情况的项目Update heap 图二:操作项 ...
- 在.net core 的webapi项目中将对象序列化成json
问题:vs2017 15.7.6创建一个基于.net core 2.1的webapi项目,默认生成的控制器继承自ControllerBase类 在此情况下无法使用Json()方法 将一个对象转成jso ...
- Python 函数调用性能记录
之前用 JS 写项目的时候,项目组用的组件模式,一直感觉很不错.最近用 Python 做新项目,项目结构也延续了组件模式.一直没有对函数调用的性能作了解,今天突发奇想测试了一下,写了一些测试代码 首先 ...
- 构建自己的PHP框架(Twig模板引擎)
完整项目地址:https://github.com/Evai/Aier Twig 模板引擎 模版引擎 twig 的模板就是普通的文本文件,也不需要特别的扩展名,.html .htm .twig 都可以 ...
- WPF Path实现虚线流动效果
原文:WPF Path实现虚线流动效果 最近闲来无事,每天上上网,看看博客生活也过得惬意,这下老总看不过去了,给我一个任务,叫我用WPF实现虚线流动效果,我想想,不就是虚线流动嘛,这简单于是就答应下来 ...
- Android bluetooth介绍(两): android 蓝牙源架构和uart 至rfcomm过程
关键词:蓝牙blueZ UART HCI_UART H4 HCI L2CAP RFCOMM 版本号:基于android4.2先前版本 bluez内核:linux/linux3.08系统:an ...
- web开发中../、./、/的区别
原文:web开发中../.././的区别 最近在业余时间慢慢玩起了网站开发,觉得挺有意思的.在开发过程中,老是分不清 ../.././三者之间的区别,也老是弄混,最后仔细搜索研究了一下,现在终于懂了. ...
- EF context.SaveChanges()特点
EF context.SaveChanges()特点 1 一次连接保存多条数据(工作单元模式): 2 内部通过事务来执行,如果一条数据保存失败,执行回滚操作: 3 延时加载 var userList= ...