CNN结构:用于检测的CNN结构进化-结合式方法
原文链接:何恺明团队提出 Focal Loss,目标检测精度高达39.1AP,打破现有记录 呀
加入Facebook的何凯明继续优化检测CNN网络,arXiv 上发现了何恺明所在 FAIR 团队的最新力作:“Focal Loss for Dense Object Detection(用于密集对象检测的 Focal Loss 函数)”。
孔涛博士在知乎上这么写道:
目标的检测和定位中一个很困难的问题是,如何从数以万计的候选窗口中挑选包含目标物的物体。只有候选窗口足够多,才能保证模型的 Recall。
目前,目标检测框架主要有两种:
一种是 one-stage ,例如 YOLO、SSD 等,这一类方法速度很快,但识别精度没有 two-stage 的高,其中一个很重要的原因是,利用一个分类器很难既把负样本抑制掉,又把目标分类好。
另外一种目标检测框架是 two-stage ,以 Faster RCNN 为代表,这一类方法识别准确度和定位精度都很高,但存在着计算效率低,资源占用大的问题。
Focal Loss 从优化函数的角度上来解决这个问题,实验结果非常 solid,很赞的工作。
也就是说,one-stage 检测器更快更简单,但是准确度不高。two-stage 检测器准确度高,但太费资源。
综合方法:
在训练过程中发现,类别失衡是影响 one-stage 检测器准确度的主要原因。那么,如果能将“类别失衡”这个因素解决掉,one-stage 不就能达到比较高的识别精度了吗?
于是在研究中,何凯明团队采用 Focal Loss 函数 来消除“类别失衡”这个主要障碍。结果怎样呢?通过设计一个新的网络......
为了评估该损失的有效性,该团队设计并训练了一个简单的密集目标检测器—RetinaNet,是由一个骨干网络和两个特定任务子网组成的单一网络,骨干网络负责在整个输入图像上计算卷积特征图,并且是一个现成的卷积网络。 第一个子网在骨干网络的输出上执行卷积对象分类;第二个子网执行卷积边界框回归。
试验结果证明,当使用 Focal Loss 训练时,RetinaNet 不仅能赶上 one-stage 检测器的检测速度,而且还在准确度上超越了当前所有最先进的 two-stage 检测器。
可谓鱼和熊掌兼得之。
论文翻译
摘要
目前准确度最高的目标检测器采用的是一种常在 R-CNN 中使用的 two-stage 方法,这种方法将分类器应用于一个由候选目标位置组成的稀疏样本集。相反, one-stage 检测器则应用于一个由可能目标位置组成的规则密集样本集,而且更快更简单,但是准确度却落后于 two-stage 检测器。在本文中,我们探讨了造成这种现象的原因。
我们发现,在训练密集目标检测器的过程中出现的严重的 foreground-background 类别失衡,是造成这种现象的主要成因。我们解决这种类别失衡(class imbalance) 的方案是,重塑标准交叉熵损失,使其减少分类清晰的样本的损失的权重。Focal Loss 将训练集中在一个稀疏的困难样本集上,并防止大量简单负样本在训练的过程中淹没检测器。为了评估该损失的有效性,我们设计并训练了一个简单的密集目标检测器—RetinaNet。试验结果证明,当使用
Focal Loss训练时,RetinaNet 不仅能赶上 one-stage 检测器的检测速度,而且还在准确度上超越了当前所有最先进的 two-stage 检测器。
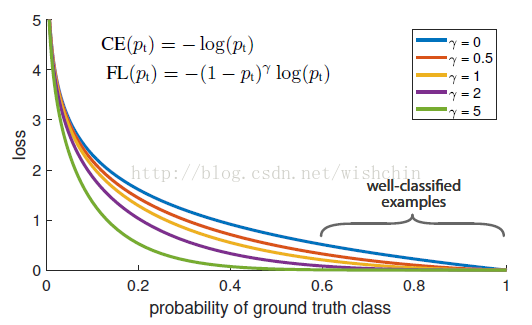
图1:我们提出了一种新的损失函数 Focal Loss(焦点损失),这个损失函数在标准的交叉熵标准上添加了一个因子 (1- pt) γ 。 设定 γ > 0 可以减小分类清晰的样本的相对损失(pt > .5),使模型更加集中于困难的错误分类的样本。试验证明,在存在大量简单背景样本(background example)的情况下,我们提出的 Focal Loss
函数可以训练出准确度很高的密集对象检测器。
1 简介
当前最优秀的目标检测器使用的都是一种由 proposal 驱动的 two-stage 机制。和在 R-CNN 框架中一样,第一个阶段生成一个候选目标位置组成的稀疏样本集,第二个阶段使用一个卷积神经网络将各候选位置归至 foreground 类别或 background 类别。随着一些列的进步,这个 two-stage 框架可以在难度极高的 COCO benchmark 上一直保持很高的准确度。
既然 two-stage 检测器的结果这么好,那么一个很自然的问题是:简单的 one-stage 检测器是否也能实现类似的准确度? one-stage 检测器主要应用在一个由目标位置(object locations)、尺度(scales)和长宽比(aspect ration)组成的规则密集样本集上。最近对 one-stage 检测器(如 YOLO 和 SSD)进行的试验都得出了优秀的结果,相比最优秀的
two-stage 方法,得出的检测器检测速度更快,而且能实现 10%- 40% 的准确度。
本文进一步提高了 one-stage 检测器的性能:我们设计出了一个 one-stage 目标检测器,并首次达到了更复杂的 two-stage 检测器所能实现的最高 COCO 平均精度,例如( 特征金字塔网络,Feature Pyramid Network ,FPN )或 Faster R-CNN 的 Mask R-CNN 变体。我们发现训练过程中的类别失衡是阻碍单阶段检测器实现这个结果的主要障碍,并提出了一种新的损失函数来消除这个障碍。
通过两阶段的级联(cascade)和采样的启发(sampling heuristics),我们解决了像 R-CNN 检测器的类别失衡问题。候选阶段(如Selective Search、EdgeBoxes 、DeepMask 和 RPN )可以快速地将候选目标位置的数目缩至更小(例如 1000-2000),过滤掉大多数背景样本。在第二个分类阶段中,应用抽样启发法(sampling
heuristics),例如一个固定的前景样本背景样本比(1:3),或者在线困难样本挖掘法(online hard example mining),在 foreground 样本和 background 样本之间维持可控的平衡。
相反,one-stage 检测器则必须处理一个由图像中规则分布的候选目标位置组成的大样本集。在实践中,目标位置的总数目通常可达 10 万左右,并且密集覆盖空间位置、尺度和长宽比。虽然还可以应用类似的抽样启发法,但是这些方法可能会失效,如果容易分类的背景样本仍然支配训练过程话。这种失效是目标识别中的一个典型问题,通常使用 bootstrapping 或困难样本挖掘来解决。
在本文中,我们提出了一个新的损失函数,它可以替代以往用于解决类别失衡问题的方法。这个损失函数是一个动态缩放的交叉熵损失函数,随着正确分类的置信度增加,函数中的比例因子缩减至零,见图1。在训练过程中,这个比例因子可以自动地减小简单样本的影响,并快速地将模型集中在困难样本上。
试验证明,Focal Loss 函数可以使我们训练出准确度很高的 one-stage 检测器,并且在性能上超越使用抽样启发法或困难样本挖掘法等以往优秀方法训练出的 one-stage 检测器。最后,我们发现 Focal Loss 函数的确切形式并不重要,并且证明了其他实例(instantiations)也可以实现类似的结果。
为了证明这个 Focal Loss 函数的有效性,我们设计了一个简单的 one-stage 目标检测器—RetinaNet,它会对输入图像中目标位置进行密集抽样。这个检测器有一个高效的 in-network 特征金字塔(feature pyramid),并使用了锚点盒(anchor box)。我们在设计它时借鉴了很多种想法。RetinaNet 的检测既高效又准确。我们最好的模型基于 ResNet-101- FPN 骨干网,在
5fps 的运行速度下,我们在 COCO test-dev 上取得了 39.1 AP 的成绩,如图2 所示,超过目前公开的单一模型在 one-stage 和 two-stage 检测器上取得的最好成绩。

图2:横坐标是检测器在COCO test-dev 上的检测速度(ms),纵坐标是准确度(AP: average precision)的比值。在 Focal Loss 的作用下,我们简单的 one-stage RetinaNet 检测器打败了先前所有的 one-stage 检测器和 two-stage 检测器,包括目前成绩最好的 Faster R-CNN系统。我们在图
2 中按 5 scales(400-800 像素)分别用蓝色圆圈和橙色菱形表示了 ResNet-50-FPN 和 ResNet-101-FPN 的 RetinaNet 变体。忽略准确度较低的情况(AP < 25),RetinaNet 的表现优于当前所有的检测器,训练时间更长时的检测器达到了 39.1 AP 的成绩。
2. Focal Loss
首先,我们介绍下二进制分类(binary classification)的交叉熵(CE)损失开:
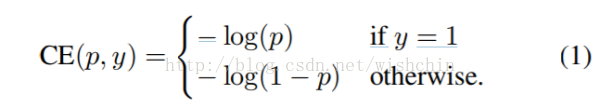
公式1中,y∈{±1} 指定了 ground-truth class,p∈[0,1] 是模型对于标签为 y = 1 的类的估计概率。为了方便起见,我们定义 pt 为:
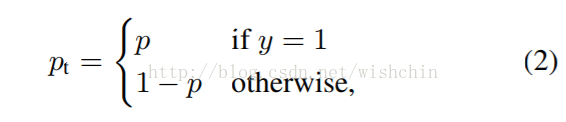
公式2可以转写称:
CE(p,y)=CE(pt)= -log(pt)
解决 class imbalance 的常见方法是分别为 class 1 和 class -1 引入加权因子 α∈[0; 1]、1-α。
α-balanced 的CE损耗可写为:
CE(pt)= -at log(pt)
(3)
更正式地,我们建议为交叉熵损失增加一个调节因子(1 - pt)γ,其中 γ≥0。于是 Focal Loss 可定义为:
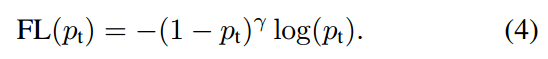
以下是我们在实践中使用的 Focal Loss:
FL(pt)= -at
*(1-pt)^r *log(pt) (5)
3. RetinaNet 检测器
RetinaNet 是由一个骨干网络和两个特定任务子网组成的单一网络。骨干网络负责在整个输入图像上计算卷积特征图,并且是一个现成的卷积网络。 第一个子网在骨干网络的输出上执行卷积对象分类;第二个子网执行卷积边界框回归。如下图所示。

图3:one-stage RetinaNet 网络结构
4. 训练
主要看训练过程,怎么没有翻译出来呢????
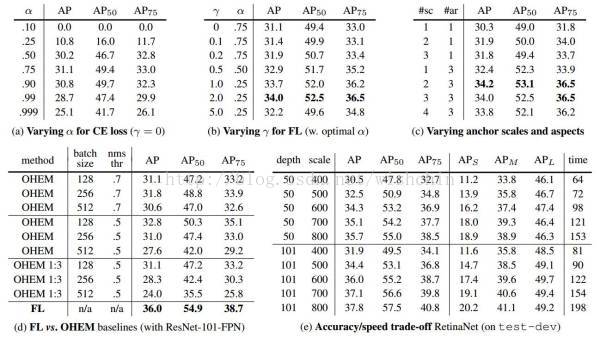
表1: RetinaNet 和 Focal Loss 剥离试验(ablation experiment)
5. 实验
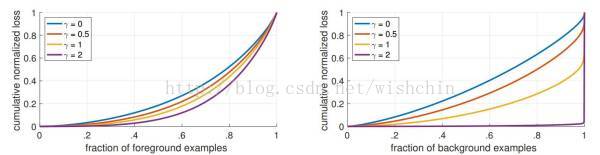
图4:收敛模型的不同 γ 值的正、负样本的归一化损失的累积分布函数。 改变 γ 对于正样本的损失分布的影响很小。 然而,对于负样本来说,大幅增加 γ 会将损失集中在困难的样本上,而不是容易的负样本上。
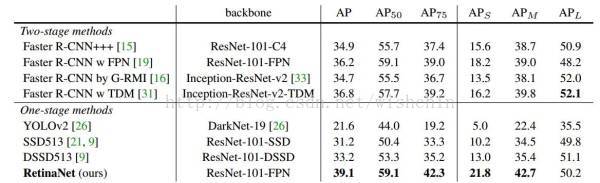
表2:目标检测单模型结果(边界框AP)VS COCO test-dev 最先进的方法
6. 结论
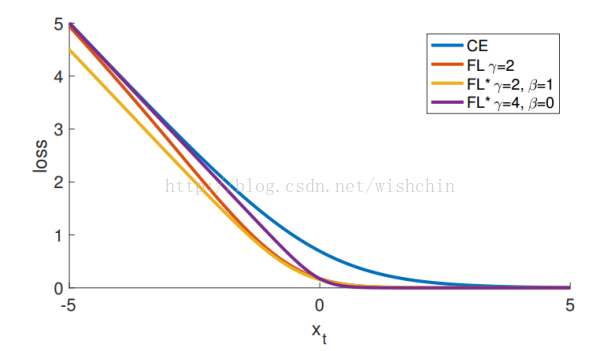
图5:
作为 xt = yx 的函数,Focal Loss 变体与交叉熵相比较。原来的 FL(Focal Loss)和替代变体 FL* 都减少了较好分类样本的相对损失(xt> 0)。
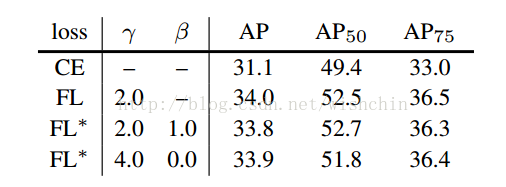
表3:FL 和 FL* VS CE(交叉熵) 的结果。
论文地址:[1708.02002] Focal Loss for Dense
Object Detection
后记:
有没有卵用,还必须看放出源代码的,网络监测的真正效果如何,一时还难以真正评测。
CNN结构:用于检测的CNN结构进化-结合式方法的更多相关文章
- CNN结构:用于检测的CNN结构进化-分离式方法
前言: 原文链接:基于CNN的目标检测发展过程 文章有大量修改,如有不适,请移步原文. 参考文章:图像的全局特征--用于目标检测 目标的检测和定位中一个很困难的问题是,如何从数以万计的候选 ...
- CNN结构:用于检测的CNN结构进化-一站式方法
有兴趣查看原文:YOLO详解 人眼能够快速的检测和识别视野内的物体,基于Maar的视觉理论,视觉先识别出局部显著性的区块比如边缘和角点,然后综合这些信息完成整体描述,人眼逆向工程最相像的是DPM模型. ...
- 使用Dlib来运行基于CNN的人脸检测
检测结果如下 这个示例程序需要使用较大的内存,请保证内存足够.本程序运行速度比较慢,远不及OpenCV中的人脸检测. 注释中提到的几个文件下载地址如下 http://dlib.net/face_det ...
- 【神经网络与深度学习】【计算机视觉】RCNN- 将CNN引入目标检测的开山之作
转自:https://zhuanlan.zhihu.com/p/23006190?refer=xiaoleimlnote 前面一直在写传统机器学习.从本篇开始写一写 深度学习的内容. 可能需要一定的神 ...
- 内核中用于数据接收的结构体struct msghdr(转)
内核中用于数据接收的结构体struct msghdr(转) 我们从一个实际的数据包发送的例子入手,来看看其发送的具体流程,以及过程中涉及到的相关数据结构.在我们的虚拟机上发送icmp回显请求包,pin ...
- RCNN (Regions with CNN) 目标物检测 Fast RCNN的基础
Abstract: 贡献主要有两点1:可以将卷积神经网络应用region proposal的策略,自底下上训练可以用来定位目标物和图像分割 2:当标注数据是比较稀疏的时候,在有监督的数据集上训练之后到 ...
- 基于孪生卷积网络(Siamese CNN)和短时约束度量联合学习的tracklet association方法
基于孪生卷积网络(Siamese CNN)和短时约束度量联合学习的tracklet association方法 Siamese CNN Temporally Constrained Metrics T ...
- Atitit.各种 数据类型 ( 树形结构,表形数据 ) 的结构与存储数据库 attilax 总结
Atitit.各种 数据类型 ( 树形结构,表形数据 ) 的结构与存储数据库 attilax 总结 1. 数据结构( 树形结构,表形数据,对象结构 ) 1 2. 编程语言中对应的数据结构 jav ...
- Linux字符设备驱动结构(一)--cdev结构体、设备号相关知识机械【转】
本文转载自:http://blog.csdn.net/zqixiao_09/article/details/50839042 一.字符设备基础知识 1.设备驱动分类 linux系统将设备分为3类:字符 ...
随机推荐
- Serial Fluent UDF on Windows
test test Table of Contents 1. Serial UDF on Windows OS 1 Serial UDF on Windows OS Note: Udf has to ...
- HTML的基本操作学习----常用标签,特殊符号,列表,表格,表单
什么是HTML 常用标签 标题标签 段落标签 粗体标签+斜体 超链接标签 图片标签 列表标签 无序标签 有序标签 自定义列表 div标签 特殊符号 表格 表单 HTML 什么是 HTML? HTM ...
- JavaSE 学习笔记之StringBuilder(十六)
< java.lang >-- StringBuilder字符串缓冲区:★★★☆ JDK1.5出现StringBuiler:构造一个其中不带字符的字符串生成器,初始容量为 16 个字符.该 ...
- [BZOJ 3796]Mushroom追妹纸
[BZOJ 3796]Mushroom追妹纸 题目 Mushroom最近看上了一个漂亮妹纸.他选择一种非常经典的手段来表达自己的心意——写情书.考虑到自己的表达能力,Mushroom决定不手写情书.他 ...
- RDS MySQL 表上 Metadata lock 的产生和处理
https://help.aliyun.com/knowledge_detail/41723.html?spm=5176.7841698.2.18.vNfPM3
- cat<<EOF获取标准输入到文件中
原文:http://blog.csdn.net/apache0554/article/details/45508631 ---------------------------------------- ...
- java读取中文分词工具(一)
import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.I ...
- Java 递归、尾递归、非递归、栈 处理 三角数问题
import java.io.BufferedReader; import java.io.InputStreamReader; //1,3,6,10,15...n 三角数 /* * # 1 * ## ...
- bzoj5441: [Ceoi2018]Cloud computing
跟着大佬做题.. 这题也是有够神仙了.观察一下性质,c很小而f是一个限制条件(然而我并不会心态爆炸) %了一发,就是把电脑和订单一起做背包,订单的c视为负而电脑的v为负,f由大到小排序做背包 #inc ...
- 使用 Swift 3.0 操控日期
作者:Joe,原文链接,原文日期:2016-09-20译者:Cwift:校对:walkingway:定稿:CMB 当你在想要 大规模重命名 时,一个附带的挑战就是要确保所有相关的文档都必须同步更新.比 ...