自学Python八 爬虫大坑之网页乱码
Bug有时候破坏的你的兴致,阻挠了保持到现在的渴望。可是,自己又非常明白,它是一种激励,是注定要被你踩在脚下的垫脚石!
python2.7中最头疼的可能莫过于编码问题了,尤其还是在window环境下,有时候总是出现莫名其妙的问题,有时候明明昨天还好好的,今天却突然。。。遇到这种问题真的是一肚子的火。。。fuck!
首先,在我们编写python代码的时候就要注意一些编码的规范。
1.源码文件用#-*-coding:utf-8-*- 指定编码并把文件保存为utf-8格式
2.文件开头使用from __future__ import unicode_literals 以此避免在中文前面加u,以考虑到迁移到python3。
3.python内部是用Unicode存储的,所有的输入要先decode变成unicode,输入的时候encode变成想要的编码。在window环境下常用到的有utf-8,gbk,gb2312,gb18030等。
4.一般网站基本都是utf-8或者gb2312。可以尝试进行decode,然后encode 当前输出环境的编码格式,系统默认的编码格式通过sys.getfilesystemencoding()。涉及到文件路径的时候要转换为系统默认的编码。
5.unicode字符串在写入文件时必须转换为某种字符编码。
在抓取网页时,我们可以先看看该网页的字符编码,这些内容可以在html代码或者f12看network中看到:

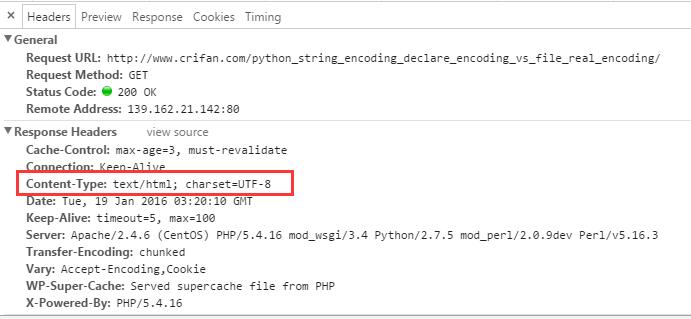
当你得到网页源码后进行print的时候,那么你就要小心了。你可能会得到UnicodeEncodeError!
你可以这样:
type = sys.getfilesystemencoding()
#utf-8为网页编码,可能为gbk等
html = html.decode('utf-8').encode(type)
另外还有一种万能的方式,就是用chardet包确定网页编码。刚试了试 比较慢。。。需要安装chardet包,地址为https://pypi.python.org/pypi/chardet 可以通过pip install chardet 或者 easy_install chardet安装。使用代码如下:
htmlCharsetGuess = chardet.detect(pageCode)
htmlCharsetEncoding = htmlCharsetGuess["encoding"]
htmlCode_decode = pageCode.decode(htmlCharsetEncoding)
type = sys.getfilesystemencoding()
htmlCode_encode = htmlCode_decode.encode(type)
print htmlCode_encode
还有一种可能就是,你得到的网站内容是被gzip压缩过的,这时候我们还需要去解压缩。大部分的服务器是支持gzip压缩的,我更改了一下HttpClient.py。我们默认就去已gzip的方式去访问网站,得到压缩过的内容再处理,这样抓取速度就更快了,下面来看一下HttpClient.py的Get方法:
import zlib
def Get(self, url, refer=None):
try:
req = urllib2.Request(url)
req.add_header('Accept-encoding', 'gzip')#默认以gzip压缩的方式得到网页内容
if not (refer is None):
req.add_header('Referer', refer)
response = urllib2.urlopen(req, timeout=120)
html = response.read()
gzipped = response.headers.get('Content-Encoding')#查看是否服务器是否支持gzip
if gzipped:
html = zlib.decompress(html, 16+zlib.MAX_WBITS)#解压缩,得到网页源码
return html
except urllib2.HTTPError, e:
return e.read()
except socket.timeout, e:
return ''
except socket.error, e:
return ''
写了这么多发现没写到点子上,自己经验比较少,然而字符编码这种事情是需要经验的。总结起来就是一句话,如果出现了UnicodeEncodeError错误了,就说明字符编码出问题了,python解释器也是一个工具,你需要让他明白,所以要decode,然后他为了让你明白所以要encode。 为了万无一失推荐使用chardet包!
自学Python八 爬虫大坑之网页乱码的更多相关文章
- python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]
目录 前言 一.BeautifulSoup的基本语法 二.爬取网页图片 扩展学习 后记 前言 本章同样是解析一个网页的结构信息 在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图 ...
- Python开发爬虫之静态网页抓取篇:爬取“豆瓣电影 Top 250”电影数据
所谓静态页面是指纯粹的HTML格式的页面,这样的页面在浏览器中展示的内容都在HTML源码中. 目标:爬取豆瓣电影TOP250的所有电影名称,网址为:https://movie.douban.com/t ...
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
- 自学Python四 爬虫基础知识储备
首先,推荐两个关于python爬虫不错的博客:Python爬虫入门教程专栏 和 Python爬虫学习系列教程 .写的都非常不错,我学习到了很多东西!在此,我就我看到的学到的进行总结一下! 爬虫就是 ...
- python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]
前言 hello,大家好 本章可是一个重中之重,因为我们今天是要爬取一个图片而不是一个网页或是一个json 所以我们也就不用用到selenium模块了,当然有兴趣的同学也一样可以使用selenium去 ...
- 开发记录_自学Python写爬虫程序爬取csdn个人博客信息
每天刷开csdn的博客,看到一整个页面,其实对我而言,我只想看看访问量有没有上涨而已... 于是萌生了一个想法: 想写一个爬虫程序把csdn博客上边的访问量和评论数都爬下来. 打算通过网络各种搜集资料 ...
- 怎么用Python写爬虫抓取网页数据
机器学习首先面临的一个问题就是准备数据,数据的来源大概有这么几种:公司积累数据,购买,交换,政府机构及企业公开的数据,通过爬虫从网上抓取.本篇介绍怎么写一个爬虫从网上抓取公开的数据. 很多语言都可以写 ...
- 自学Python九 爬虫实战二(美图福利)
作为一个新世纪有思想有文化有道德时刻准备着的屌丝男青年,在现在这样一个社会中,心疼我大慢播抵制大百度的前提下,没事儿上上网逛逛YY看看斗鱼翻翻美女图片那是必不可少的,可是美图虽多翻页费劲!今天我们就搞 ...
- 自学Python六 爬虫基础必不可少的正则
要想做爬虫,不可避免的要用到正则表达式,如果是简单的字符串处理,类似于split,substring等等就足够了,可是涉及到比较复杂的匹配,当然是正则的天下,不过正则好像好烦人的样子,那么如何做呢,熟 ...
随机推荐
- iptables详解(5):iptables匹配条件总结之二(常用扩展模块)
所属分类:IPtables Linux基础 在本博客中,从理论到实践,系统的介绍了iptables,如果你想要从头开始了解iptables,可以查看iptables文章列表,直达链接如下 iptab ...
- perf-perf stat用户层代码分析
perf_event 源码分析 前言 简单来说,perf是一种性能监测工具,它首先对通用处理器提供的performance counter进行编程,设定计数器阈值和事件,然后性能计数器就会在设定事件发 ...
- Use emcli to delete obsolete agent targets in Oracle EM Cloud Control 12c
[oracle@oem ~]$ cd /oem/oms/oms/bin 登录到oms中 [oracle@oem bin]$ ./emcli login -username=sysman Enter ...
- 《啊哈算法》中P81解救小哈
题目描述 首先我们用一个二维数组来存储这个迷宫,刚开始的时候,小哼处于迷宫的入口处(1,1),小哈在(p,q).其实这道题的的本质就在于找从(1,1)到(p,q)的最短路径. 此时摆在小哼面前的路有两 ...
- POJ3278——Catch That Cow
Catch That Cow Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 114140 Accepted: 35715 ...
- Codeforces Round #468 Div. 2题解
A. Friends Meeting time limit per test 1 second memory limit per test 256 megabytes input standard i ...
- Luogu P2866 [USACO06NOV]糟糕的一天Bad Hair Day
P2866 [USACO06NOV]糟糕的一天Bad Hair Day 题目描述 Some of Farmer John's N cows (1 ≤ N ≤ 80,000) are having a ...
- [ZJOJ] 5794 2018.08.10【2018提高组】模拟A组&省选 旅行
Description 悠悠岁月,不知不觉,距那传说中的pppfish晋级泡泡帝已是过 去数十年.数十年 中,这颗泡泡树上,也是再度变得精彩,各种泡泡 天才辈出,惊艳世人,然而,似乎 不论后人如何的出 ...
- Python爬虫基础--分布式爬取贝壳网房屋信息(Server)
1. server_code01 2. server_code02 3. server_code03
- TOC 1. TODO springboot优雅关机
TODO start and stop as a linux service web container(tomcat ,undertow) gracefully shutdown gracefull ...