用python来抓取“煎蛋网”上面的美女图片,尺度很大哦!哈哈
所用Python环境为:python 3.3.2 用到的库为:urllib.request re
废话不多说,先上代码:
import urllib.request
import re #获得当前页面的页数page_name
def get_pagenum(url):
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36')
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
p = r'<span class="current-comment-page">[^"]+</span>'
temp = re.search(p,html)
page_num = temp.group()[36:39]
return page_num #将此页面上的图片写入我们的mm文件夹中
def get_img(page_url):
req = urllib.request.Request(page_url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36')
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
p = r'<img src="([^"]+\.jpg)"'
url_list = re.findall(p,html)
num = 0
for each in url_list:
file = open('C:/Users/lenovo/Desktop/mm/'+each[-8:]+'.jpg','wb')
if each[0:5] == 'http:':
res = urllib.request.urlopen(each)
else:
res = urllib.request.urlopen('http:'+each)
file.write(res.read())
file.close() #只能直接运行
if __name__ == '__main__':
url = 'http://jandan.net/ooxx/'
page_num = get_pagenum(url)
for i in range(10): #抓取了十个页面上美女图片
page_url = url + 'page-'+str(page_num)+'#comments'
get_img(page_url)
page_num = int(page_num) - 1 #下面是写正则的时候方便看所以粘贴过来的连接
#<img src="//ws3.sinaimg.cn/mw600/006wUWIjgy1fgxrw8goikj30hs0qodh7.jpg" style="max-width: 480px; max-height: 750px;"> #http://jandan.net/ooxx/page-143#comments #<span class="current-comment-page">[141]</span> # http://wx3.sinaimg.cn/mw600/661eb95cly1fgioxk7mk3j20xc1e01f1.jpg #<img src="//wx1.sinaimg.cn/mw600/006wUWIjgy1fgxg2yj5f3j30g70s6dgw.jpg" style="max-width: 480px; max-height: 750px;">
结果如下:
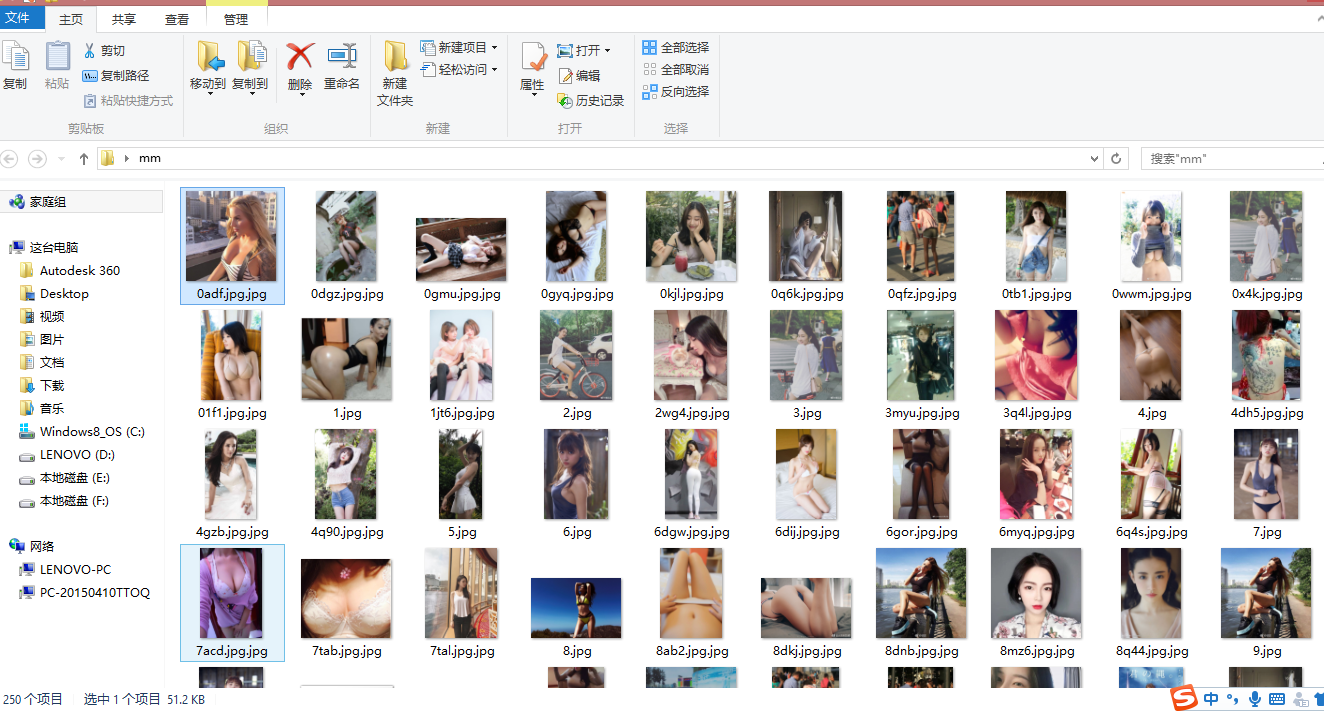
由于时间原因,我只抓取了“煎蛋网”上的十个页面的美女图片罢了,大家可以更改其中的循环次数,可以抓取很多,这里我只抓取了250个图片,一共51.2kb,哈哈,可以很好的欣赏美女图片了,看的都要流鼻血了。。。
当然,此程序还是不够完善,只是我初学python网络爬虫的小作品罢了,以后再些更加完善的。接下来的一段时间真的得好好准备期末考试和考研了,加油!
参考来源: https://zhuanlan.zhihu.com/p/26442105
Note:没有经过我的同意,请勿随便转载!谢谢。
用python来抓取“煎蛋网”上面的美女图片,尺度很大哦!哈哈的更多相关文章
- Python Scrapy 爬取煎蛋网妹子图实例(一)
前面介绍了爬虫框架的一个实例,那个比较简单,这里在介绍一个实例 爬取 煎蛋网 妹子图,遗憾的是 上周煎蛋网还有妹子图了,但是这周妹子图变成了 随手拍, 不过没关系,我们爬图的目的是为了加强实战应用,管 ...
- Python 爬虫 爬取 煎蛋网 图片
今天, 试着爬取了煎蛋网的图片. 用到的包: urllib.request os 分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地.过程简单清晰明了 直接上源代 ...
- python爬虫–爬取煎蛋网妹子图片
前几天刚学了python网络编程,书里没什么实践项目,只好到网上找点东西做. 一直对爬虫很好奇,所以不妨从爬虫先入手吧. Python版本:3.6 这是我看的教程:Python - Jack -Cui ...
- Python Scrapy 爬取煎蛋网妹子图实例(二)
上篇已经介绍了 图片的爬取,后来觉得不太好,每次爬取的图片 都在一个文件下,不方便区分,且数据库中没有爬取的时间标识,不方便后续查看 数据时何时爬取的,所以这里进行了局部修改 修改一:修改爬虫执行方式 ...
- python爬虫爬取煎蛋网妹子图片
import urllib.request import os def url_open(url): req = urllib.request.Request(url) req.add_header( ...
- [Java]使用HttpClient实现一个简单爬虫,抓取煎蛋妹子图
第一篇文章,就从一个简单爬虫开始吧. 这只虫子的功能很简单,抓取到”煎蛋网xxoo”网页(http://jandan.net/ooxx/page-1537),解析出其中的妹子图,保存至本地. 先放结果 ...
- Golang分布式爬虫:抓取煎蛋文章|Redis/Mysql|56,961 篇文章
--- layout: post title: "Golang分布式爬虫:抓取煎蛋文章" date: 2017-04-15 author: hunterhug categories ...
- selenium爬取煎蛋网
selenium爬取煎蛋网 直接上代码 from selenium import webdriver from selenium.webdriver.support.ui import WebDriv ...
- python爬虫学习(1)__抓取煎蛋图片
#coding=utf-8 #python_demo 爬取煎蛋妹子图在本地文件夹 import requests import threading import time import os from ...
随机推荐
- fastclick插件学习(一)之用法
原理 在检测到touchend事件后, 会通过dom自定义事件模拟一个click事件,并把浏览器300ms之后真正触发的点击事件屏蔽掉,fastclick是不会对PC浏览器添加监听事件 使用 1.引入 ...
- 不怕你配置不会,就怕你看的资料不对!MIM 与 SharePoint 同步完全配置指南。
为了更好的同步 User Profile,在 SharePoint 2010 中首次引入了 FIM (ForeFront Identity Manager) 用于编辑 User Profile 的同期 ...
- PPT 设置幻灯片母版
现在我设计了一个PPT背景,我想新建幻灯片的时候,直接就是以这个背景展现,并把这个背景作用于左右的幻灯片. 1.选中第二页幻灯片,CTRL + C 复制一下 2.点击视图,幻灯片母版,背景样式,点击下 ...
- Django restfulframework 开发相关知识 整理
目录 目录 前言 前后端分离 实现前后端分离的方法 前后端分离带来的优点 RESTful十大规范 协议规范 域名规范 版本表示规范 url使用名词 http请求动词 过滤条件 状态码 错误信息 请求方 ...
- Linux ppp 数据收发流程
转:http://blog.csdn.net/yangzheng_yz/article/details/11526671 PPP (Point-to-Point)提供了一种标准的方法在点对点的连接上传 ...
- idou老师教你学istio1:如何为服务提供安全防护能力
之前,已为大家介绍过 Istio 第一主打功能---连接服务. 凡是产生连接关系,就必定带来安全问题,人类社会如此,服务网格世界,亦是如此. 今天,我们就来谈谈Istio第二主打功能---保护服务. ...
- Comparing Sentence Similarity Methods
Reference:Comparing Sentence Similarity Methods,知乎.
- 【LOJ6671】EntropyIncreaser 与 Minecraft
Orz lbt Description https://loj.ac/problem/6671 Solution
- 数据库 Redis:Windows环境安装
1. 下载 Redis (1)前往 GitHub 下载:https://github.com/microsoftarchive/redis (2)点击 release : (3)选择好版本号后,下载文 ...
- mysql基础_操作数据库以及表
1.数据库的操作 create database 数据库名:#一般创建方式 create database 数据库名 show databases;#查看所有数据 drop database 数据库名 ...