Computer Vision_33_SIFT:TILDE: A Temporally Invariant Learned DEtector——2014
此部分是计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面。对于自己不太熟悉的领域比如摄像机标定和立体视觉,仅仅列出上google上引用次数比较多的文献。有一些刚刚出版的文章,个人非常喜欢,也列出来了。
33. SIFT
关于SIFT,实在不需要介绍太多,一万多次的引用已经说明问题了。SURF和PCA-SIFT也是属于这个系列。后面列出了几篇跟SIFT有关的问题。
[1999 ICCV] Object recognition from local scale-invariant features
[2000 IJCV] Evaluation of Interest Point Detectors
[2006 CVIU] Speeded-Up Robust Features (SURF)
[2004 CVPR] PCA-SIFT A More Distinctive Representation for Local Image Descriptors
[2004 IJCV] Distinctive Image Features from Scale-Invariant Keypoints
[2010 IJCV] Improving Bag-of-Features for Large Scale Image Search
[2011 PAMI] SIFTflow Dense Correspondence across Scenes and its Applications
[2014 CVPR] TILDE: A Temporally Invariant Learned DEtector
[2015 TGRS] SAR-SIFT: A SIFT-LIKE ALGORITHM FOR SAR IMAGES
[2017 GRSL] Remote Sensing Image Registration With Modified SIFT and Enhanced Feature Matching
[2017 CVPR] GMS :Grid-based Motion Statistics for Fast, Ultra-robust Feature Correspondence
翻译
TILDE:一个时间不变的学习探测器
作者:Yannick Verdie,Kwang Moo Yi
摘要
-我们引入了一种基于学习的方法,可以在天气和光照条件急剧变化的情况下检测可重复的关键点,而最新的关键点检测器对这些关键点的检测器非常敏感。我们首先从相同的角度拍摄的多个训练图像中确定好的关键候选对象。然后,我们训练回归器来预测得分图,其最大点就是那些点,以便可以通过简单的非最大抑制来找到它们。
由于没有标准的数据集可以测试这些变化的影响,因此我们创建了自己的数据集,并将其公开提供。我们将证明,在这种具有挑战性的条件下,我们的方法明显优于最新方法,同时在未经训练的标准牛津数据集上仍能实现最新性能。
1 引言
关键点检测和匹配是解决许多计算机视觉问题(例如图像检索,对象跟踪和图像配准)的重要工具。自从1980年代引入Moravec,Forstner和Harris拐角检测器[24、11、12]以来,已经提出了许多其他建议[37、10、28]。当比例尺和视点改变或图像模糊时,有些会表现出出色的可重复性[23]。但是,如图1所示,当在一天的不同时间,不同的天气或季节在室外采集图像时,其可靠性会大大降低。尝试匹配早晨和傍晚,冬季和夏季在晴天和恶劣天气下拍摄的图像时,这是一个严重的障碍。
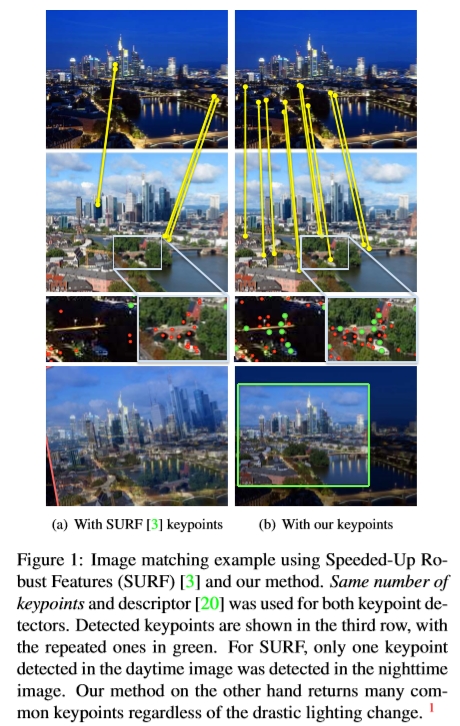
图1:使用加速鲁棒特征(SURF)[3]和我们的方法进行图像匹配的示例。 两个关键点检测器使用相同数量的关键点和描述符[20]。 检测到的关键点显示在第三行中,重复的关键点显示为绿色。 对于SURF,白天图像中仅检测到一个关键点。 另一方面,无论灯光变化如何,我们的方法都会返回许多常见的关键点。1
1 数字最好以彩色显示。
在本文中,我们提出了一种学习关键点检测器的方法,该方法可提取在这种挑战性条件下稳定的关键点,并允许在如图1所示的困难情况下进行匹配。为此,我们首先介绍一种简单但有效的方法来识别训练图像中潜在的稳定点。然后,我们使用它们来训练回归器,该回归器将生成分数图,其值是这些位置的局部最大值。通过首先在新图像上运行它,我们可以通过简单的非最大抑制来提取关键点。我们的方法受到最近提出的算法的启发[31],该算法依靠回归从线性结构的图像中提取中心线。为了我们的目的使用这个基本思想要求我们开发一种对复杂外观变化具有鲁棒性的新型回归器,以便它能够有效,可靠地处理输入图像。
正如成功地将机器学习应用于描述符[5,36]和边缘检测[8]一样,在关键点检测[27,34]的背景下,以前也已经使用了学习方法来减少查找机器学习时所需的操作数量。与手工制作方法相同的要点。然而,尽管进行了广泛的文献搜索,我们仅发现了一种尝试通过学习提高关键点可靠性的方法[35]。该方法侧重于学习分类器以筛选出最初检测到的关键点,但取得的改进有限。这可能是因为他们的方法是基于纯分类的,而且还因为它不容易找到分类员首先要学习的良好关键点。
结果可能是,目前没有设计用于测试关键点检测器对此类时间变化的鲁棒性的标准基准数据集。因此,我们根据许多户外场景存档(AMOS)[15]中的图像和全景图像创建了自己的图像,以验证我们的方法。除了标准的牛津数据集[23]之外,我们还将使用我们的数据集,以证明我们的方法在可重复性方面明显优于最新技术。为了鼓励对此重要主题进行进一步的研究,我们将其与代码一起公开发布。总而言之,我们的贡献是三方面的:
•我们引入了“临时不变学习检测器”(TILDE),这是一种基于回归的新方法,用于提取在天气,季节和一天中的时间变化引起的剧烈光照变化下可重复的特征点。
•我们提出了一种有效的方法来生成所需的“良好学习要点”培训集。
•我们创建了一个新的基准数据集,用于评估在不同时间和季节捕获的室外图像上的特征点检测器。
在本文的其余部分中,我们首先讨论相关工作,概述我们的方法,然后详细介绍基于回归的方法。最后,我们将我们的方法与最新的关键点检测器进行了比较。
2.相关工作
手工关键点探测器
大量工作致力于开发效率更高的特征点检测器。即使出现在1980年代的方法[24、11、12]仍被广泛使用,但此后已经开发了许多新方法。 [10]提出了基于通用螺旋模型的SFOP检测器,以使用结点和斑点。 [14]和[30]的WADE检测器使用对称性来获得可靠的关键点。借助SIFER和D-SIFER,[22,21]使用余弦调制高斯滤波器和10阶高斯导数滤波器来更可靠地检测关键点。总体而言,这些方法始终如一地提高了标准数据集上关键点检测器的性能[23],但在应用于具有时间差异的室外场景时,性能仍然会严重下降。
手工方法的主要缺点之一是它们无法轻松地适应环境,因此缺乏灵活性。例如,当校准摄像机时,SFOP [10]效果很好,而将WADE [30]应用于具有对称性的对象时,效果很好。然而,它们的优势并不容易被我们解决的问题所延续,例如发现类似的户外场景[16]。
学习的关键点检测器尽管关键点检测器的工作主要集中在手工方法上,但已经提出了一些基于学习的方法[27、35、13、25]。通过FAST,[27]引入了机器学习技术来学习快速角检测器。但是,在他们的案例中,学习仅旨在加快关键点提取过程。扩展版本FAST-ER [28]中也考虑了可重复性,但它没有发挥重要作用。 [35]训练WaldBoost分类器[33]在预先对齐的训练集上学习具有高重复性的关键点,然后根据分类器的分数筛选出一组初始关键点。他们的方法称为TaSK,可能与我们的方法最相关,因为他们使用预先对齐的图像来构建训练集。但是,其方法的性能受到所使用的初始关键点检测器的限制。
最近,[13]提出要学习一种分类器,该分类器可以为运动结构(SfM)应用程序检测可匹配的关键点。他们通过观察在SfM管道中保留了哪些关键点来收集可匹配的关键点,并学习这些关键点。尽管他们的方法显示出显着的加速效果,但仍然受到初始关键点检测器质量的限制。 [25]通过随机采样学习卷积滤波器,并寻找应用于立体视觉测距法时姿态估计误差最小的滤波器。
不幸的是,他们的方法仅限于线性滤波器,而线性滤波器在灵活性方面受到限制,目前还不清楚如何将他们的方法应用于立体视觉测距法以外的其他任务。
我们提出了一种学习关键点检测器的通用方案,并为此任务指定了一种新颖的高效回归器。我们将其与最先进的手工方法以及TaSK进行比较,因为它是文献中最接近的方法,在一些数据集上。
3.学习强大的关键点检测器
在本节中,我们首先概述基于回归的方法,然后说明如何构建所需的训练集。我们将在以下部分中对算法进行形式化并更详细地描述回归器。
3.1 我们的方法概述
让我们首先假设我们有一组相同场景的训练图像,它们是从相同的角度捕获的,但在不同的季节和一天中的不同时间,例如图2(a)。让我们进一步假设,我们已经在这些图像中确定了我们认为可以在不同成像条件下一致找到的一组位置。我们在下面的3.2节中提出了一种实用的方法。让我们将正样本称为每个训练图像中位于这些位置的图像块。远离这些位置的贴片是阴性样本。
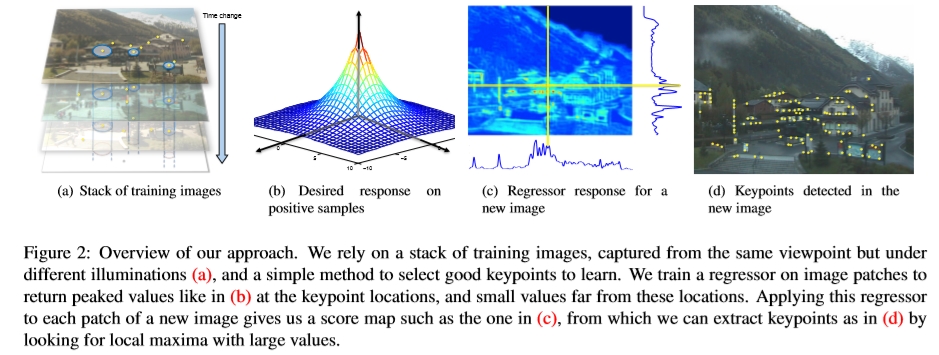
图2:我们的方法概述。 我们依靠一堆训练图像,这些图像是从同一视点但在不同光照下捕获的(a),以及一种选择要学习的关键点的简单方法。 我们在图像块上训练回归器以返回关键点位置处的峰值(b),例如(b),而远离这些位置的小值。 将该回归变量应用于新图像的每个补丁,可以得到一个得分图,例如(c)中的得分图,通过寻找具有较大值的局部最大值,可以从中提取出(d)中的关键点。
为了学习在新的输入图像中找到这些位置,我们建议训练回归器为输入图像的给定尺寸的每个面片返回一个值。这些值应具有与图2(b)所示的正样本相似的峰值形状,并且我们还鼓励回归变量对负样本产生尽可能小的分数。如图2(c)所示,我们可以通过简单地寻找回归器返回值的局部最大值来提取关键点,并通过简单的阈值处理来丢弃低值的图像位置。此外,我们的回归器还经过训练,可以在图像堆栈中的相同位置返回相似的值。这样,即使照明条件发生变化,回归器也会返回一致的值。
3.2 创建训练集
如图3所示,要创建我们的正样本和负样本数据集,我们首先从一天中不同时间和不同季节捕获的室外网络摄像头收集了一系列图像。我们从AMOS数据集[15]中确定了几种合适的网络摄像头-可以长时间固定,不受雨淋等影响的网络摄像头。我们还使用了位于建筑物顶部的摄像头捕获的全景图像。

图3:来自网络摄像头数据集的示例数据。 网络摄像头数据集由来自不同位置的六个场景组成:(a)五个场景取自许多户外场景存档(AMOS)数据集[15],即StLouis,墨西哥,Chamonix,Courbevoie和Frankfurt。 (b)建筑物屋顶的全景场景,可显示360度全景。
为了收集训练样本集,我们首先在该数据集的每个图像中独立检测关键点。我们使用SIFT [20],但是也可以考虑使用其他检测器。然后,我们从具有最小比例的关键点开始迭代检测到的关键点。如果在大多数图像中大约相同的位置检测到关键点,则该位置很可能是学习的不错选择。在实践中,如果两个关键点的距离小于SIFT估计的比例,则我们认为这两个关键点大约位于同一位置,并且我们会保留最佳的100个重复位置。然后,由所有图像(包括未检测到关键点的图像)中的补丁组成一组正样本,并以检测的平均位置为中心。
这种简单的策略具有几个优点:我们仅保留最可重复的关键点进行训练,而丢弃很少发现的关键点。我们还引入了缺少高度可重复关键点的补丁作为阳性样本。这样,我们可以专注于可以在不同条件下可靠检测的关键点,并纠正原始检测器的错误。
要创建一组阴性样本,我们只需在远离用于创建一组阳性样本的关键点的位置处提取补丁。
4.高效的分段线性回归器
在本节中,我们首先介绍我们的回归器的形式,将其有效地应用于图像中的每个面片,然后描述所建议的目标函数的不同术语,以进行可靠地检测关键点的训练,最后我们说明如何我们优化回归器的参数以最小化此目标函数。
4.1 分段线性回归
我们的回归器是使用广义铰链超平面(GHH)表示的分段线性函数[4,38]:
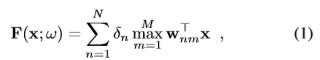
其中x是从图像补丁中提取的图像特征构成的向量,ω是回归参数的向量,可以分解为ω= [w>11T,...,w>MNT,δ1,..., δN] T。所述WNM载体可以被视为线性滤池。 ΔN被约束的参数是-1或+1。 N和M是控制GHH复杂度的元参数。作为图像特征,我们使用LUV色彩空间的三个分量以及在x色块的每个像素处计算出的图像梯度(水平和垂直梯度以及梯度量)。
[38]表明,任何连续的分段线性函数都可以用等式(1)表示。它非常适合我们的关键点检测器学习问题,因为将回归器应用于图像的每个位置仅涉及简单的图像卷积和逐像素最大运算符,而回归树则需要对图像和节点的随机访问,而CNN涉及较高的大多数层的三维卷积。此外,我们将表明,此公式还有助于整合不同的约束,包括对相邻位置的响应之间的约束,这些约束对于提高关键点提取的性能很有用。
与其简单地以类似于[31]的方式来预测从距离最近的关键点的距离而得出的得分,不如说是将区分关键点附近的图像位置和关键点附近的图像位置加以区分也很重要。离这很远。回归器针对接近关键点的图像位置返回的值应该在关键点位置具有局部最大值,而远离关键点的位置的实际值无关紧要,只要它们足够小以通过简单的阈值丢弃它们即可。因此,我们首先引入一个类似于分类的术语,该术语强制将这两种不同类型的图像位置之间进行分隔。我们还依赖于强制响应以在关键点位置具有局部最大值的术语,以及随时间调整回归变量响应的术语。总而言之,我们在回归参数ω上最小的目标函数L可以写成三个项的和:
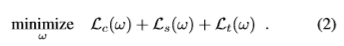
我们在下面详细介绍这三个术语。
4.2 目标函数
在本小节中,我们将详细描述等式(2)中引入的目标函数的三个术语。每个术语的影响都将根据经验进行评估,并在5.4节中进行讨论。
分类损失LC
如上所解释,该术语对于将接近关键点的图像位置与远离关键点的图像位置很好地分开是有用的。如传统的SVM [7]所示,它依赖于最大保证金损失。特别是,我们将其定义为:
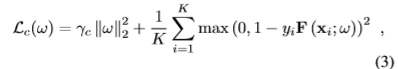
其中γc是一个元参数,yi∈{-1,+ 1}是训练样本xi的标签,K是训练数据的数量。
形状调整器损耗Ls
为了在关键点位置具有局部最大值,我们强制回归器的响应在这些位置具有特定形状。对于每个正样本i,我们通过定义与所需响应形状h相关的损耗项来强制响应形状,类似于[31]中使用的,如图2(b)所示:
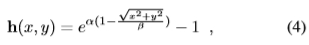
其中,x,y是相对于贴片中心的像素坐标,而α,β元参数会影响形状的清晰度。但是,我们只想强制执行一般形状,而不要强制响应的规模,以不干扰类似分类的术语Lc。因此,我们引入了一个附加术语,定义为: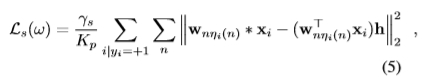
其中*表示卷积,Kp是正样本数; γs是对将通过交叉验证估计的项进行加权的元参数。 ηi(n)= argmaxm wnmT xi 仅用于对影响max算子的回归响应的滤波器施加形状约束。
事实证明,在傅立叶域中对该术语进行优化更为方便。如果我们将wnm,xi 和 h 的2D傅立叶变换分别表示为Wnm,Xi 和H,则通过应用Parseval定理和卷积定理,方程(5)变为2。
2 参见附录补充材料中的附录。
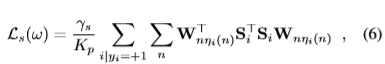
其中
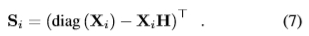
加强响应形状的这种方式是[26]方法对任何类型形状的概括。在实践中,我们用有效学习的所有积极训练样本的平均值来近似Si。为了简化计算,我们还使用了Parseval定理和Ashraf等人的工作[2]中提出的特征映射。
时间调节器Lt
为了增强回归器随时间的可重复性,我们强制回归器在训练图像堆栈上的相同位置具有相似的响应。只需添加定义为的Lt即可:
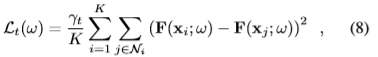
其中Ni是与xi相同的图像位置处的样本集,但来自堆栈的其他训练图像。 γt仍然是对该项进行加权的元参数。
4.3 学习分段线性回归器
优化在对训练样本应用主成分分析(PCA)进行降维以减少要优化的参数数量之后,我们通过类似于梯度提升的贪婪方法求解方程(2)。我们最初从一组空的超平面wn,m开始,然后迭代添加新的超平面,以使目标函数最小化,直到达到所需的数量(在实验中使用N = 4和M = 4)。为了估计要添加的超平面,我们像广泛使用的LibLinear库[9]中一样,应用了一个信任区域牛顿法[19]。

图4:(a)通过我们的方法在StLouis序列上学习的原始96个线性滤波器。 每行对应于一个不同的图像特征,分别是水平图像梯度,垂直图像梯度,梯度的大小以及LUV颜色空间中的三个颜色分量。 (b)使用[32]的方法为每个维度分别学习24个可分离的滤波器。 每个原始过滤器都可以近似为可分离过滤器的线性组合,可以非常有效地将其与输入图像进行卷积。
初始化后,我们随机地一次遍历超平面,并使用相同的牛顿优化方法对其进行更新。图4(a)显示了我们的方法在StLouis序列上学习的滤波器。我们使用对数尺度的网格搜索执行简单的交叉验证,以估计验证集上的元参数γc,γs和γt。
逼近为了进一步加快回归器的速度,我们使用[32]中提出的方法用可分离滤波器的线性组合来近似学习的线性滤波器。具有可分离滤波器的卷积比具有不可分离滤波器的卷积明显快得多,并且近似值通常很好。图4(b)显示了这种近似滤波器的一个例子。
5.Results
在本节中,我们首先描述我们的实验设置,并在网络摄像头数据集和更标准的Oxford数据集上给出定量和定性结果。
5.1 实验设置
我们将我们的方法与SIFT,SURF,SFOP,WADE,MSER,FAST-9,LCF,SIFER和TaSK 3进行比较。在下文中,我们的完整方法将表示为TILDE-P。在使用24个可分离的滤波器对分段线性回归滤波器进行近似之后,TILDE-P24表示相同的方法。
3有关比较方法的实施细节,请参见补充材料中的附录。
为了评估回归器本身,我们还将其与其他两个回归器进行了比较。第一个回归标记为TILDE-GB,基于增强回归树,是[31]中用于中心线检测的关键点到关键点检测的改编,其实现所用的参数与原始工作相同。我们尝试的第二个回归器,称为TILDE-CNN,是一个卷积神经网络,其架构类似于LeNet-5网络[17],但具有一个额外的卷积层和一个最大池层。第一,第三和第五层是卷积层。第一层的分辨率为28×28,过滤器的尺寸为5×5,第三层的过滤器的尺寸为10,尺寸为12×12,过滤器的尺寸为5×5,第五层的过滤器,尺寸为50,尺寸为4×4,和尺寸为3×3的滤镜。第二,第四和第六层是大小为2×2的最大合并层。第七层是一个与前一层完全连接的500个神经元的层,其后是第八层,是具有S形激活功能的完全连接的层,最后是最后的输出层。对于输出层,我们使用l2 回归成本函数。
5.2 定量结果
我们在网络摄像头数据集和牛津数据集上使用与[28]相同的可重复性度量,彻底评估了我们方法的性能。可重复性定义为在两个对齐的图像中一致检测到的关键点数。如[28]中所述,当重复投影到同一张图像时,我们考虑的关键点间隔小于5个像素。但是,可重复性度量有两个警告:首先,可以多次计算接近几个预测的关键点。而且,如果关键点的数量足够多,则随着关键点的密度变高,即使是简单的随机采样也可以实现高可重复性。
因此,我们通过两个修改使该度量更能代表性能:首先,我们只允许将关键点与其最近的邻居关联,换句话说,在评估可重复性时不能多次使用关键点。其次,我们将关键点的数量限制为一个给定的小数目,这样在随机位置选择关键点的结果的可重复性得分仅为2%,在实验中报告为可重复性(随机2%)。
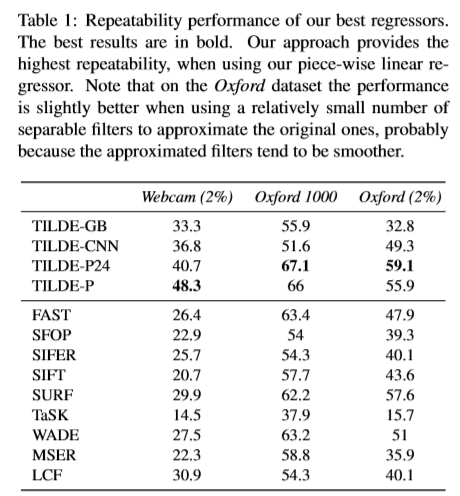
请注意,当为所有图像使用1000个关键点时,我们还包括结果,我们将其称为Oxford 1000,以与先前的论文进行比较,例如[28]。表1汇总了定量结果。
表1:我们最好的回归器的可重复性性能。 最好的结果以粗体显示。 当使用分段线性回归器时,我们的方法可提供最高的可重复性。 请注意,在牛津数据集上,使用相对少量的可分离过滤器近似原始过滤器时,性能会稍好一些,这可能是因为近似过滤器趋于平滑。
5.2.1网络摄像头数据集的可重复性
图5给出了我们网络摄像头数据集的可重复性得分。图5-顶部显示了我们的方法在每个序列上进行训练并在相同序列上进行测试时的结果,图像集分为不相交的序列,验证和测试集。图5的底部显示了将我们在一个序列上训练的检测器应用于Webcam数据集中看不到的序列时的结果。当使用专门针对每个序列训练的检测器时,我们的性能明显优于最新技术。此外,尽管在我们对看不见的序列进行测试时差距缩小了,但我们仍然比所有比较的方法都差很多,显示了我们方法的泛化能力。
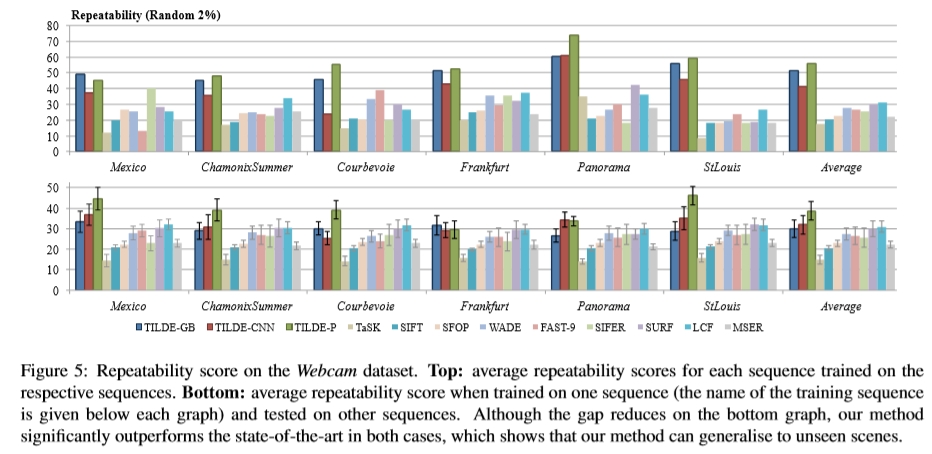
图5:网络摄像头数据集的重复性得分。 上:在相应序列上训练的每个序列的平均重复性得分。 下:在一个序列上进行训练时的平均重复性得分(训练序列的名称在每个图下方给出),并在其他序列上进行了测试。 尽管底图上的间隙减小了,但是在两种情况下,我们的方法都明显优于最新技术,这表明我们的方法可以推广到看不见的场景。
5.2.2牛津数据集的可重复性
在图6中,我们还在牛津数据集上评估了我们的方法。从这个意义上讲,该数据集更简单,因为它不会显示网络摄像头数据集的剧烈变化,但它是评估关键点检测器的参考。因此,在此数据集上评估我们的方法很有趣。
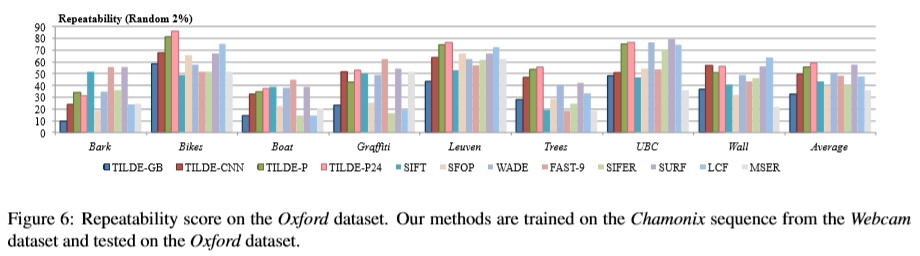
图6:牛津数据集的重复性得分。 我们的方法在Webcam数据集的Chamonix序列上进行了训练,并在Oxford数据集上进行了测试。
与其在此数据集上学习新的关键点检测器,不如使用从网络摄像头数据集中使用Chamonix序列学习的检测器。我们的方法仍然可以达到最先进的性能。在自行车,树木和鲁汶影像(它们是室外场景)的情况下,我们甚至明显优于最新方法。请注意,尽管我们目前在学习和检测中不考虑规模,但对于规模变化较大的Boat也可以获得良好的结果。由于我们认为较少的关键点,因此此处显示的可重复性得分低于先前的工作[23,28]。如前所述,考虑大量关键点可以人工提高可重复性得分。
5.3 定性结果
在图7中,我们还给出了在不同天气条件下匹配在不同日期捕获的具有挑战性的图像对的任务的一些定性结果。我们的匹配流程如下:我们首先使用要比较的不同方法在两个图像中提取关键点,计算关键点描述符,然后使用RANSAC计算两个图像之间的单应性。由于此比较的目的是评估关键点而不是描述符,因此我们将SIFT描述符用于所有方法。请注意,我们也尝试使用其他描述符[3,29,6,1,18],但是由于匹配图像之间的巨大差异,只有具有地面真实方向和比例尺的SIFT描述符才起作用。我们将我们的方法与SIFT [20],SURF [3]和FAST-9 [28]检测器进行比较,所有方法使用相同数量的关键点(300)。即使在场景外观如此剧烈的变化下,我们的方法也可以检索图像之间的正确变换。

图7:来自不同序列的几幅图像的定性结果。 从上到下:Courbevoie,法兰克福和StLouis。 (a)使用地面真相变换,(b)SIFT检测器,(c)SURF检测器,(d)FAST-9检测器和(e)我们的TILDE检测器获得的转换对图像。
5.4 三个损失项的影响
图8通过评估没有每个项的检测器的性能,给出了对等式(2)的每个损失项的影响的评估结果。当仅使用分类损失作为TILDE-PC,同时使用分类损失和时间正则化作为TILDE-PT,以及使用分类损失和形状正则化作为TILDE-PS时,我们将使用我们的方法。当所有三个术语一起使用时,我们将获得最佳性能。请注意,形状正则化可增强牛津(一个完全看不见的数据集)的可重复性,而时间正则化在我们测试与训练集相似的图像时会有所帮助。
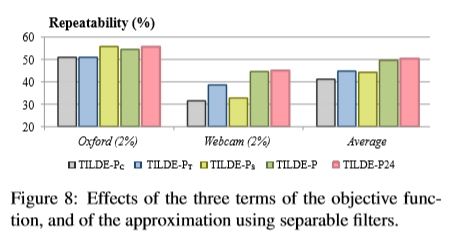
图8:目标函数的三个项以及使用可分滤波器的近似项的影响。
5.5 计算时间
图9给出了SIFT的计算时间以及我们方法的每个变体。 TILDE-P24离SIFT不太远。请注意,我们的方法是高度可并行化的,而我们当前的实现并不受益于任何并行化。因此,我们认为可以通过更好的实现显着加快我们的方法。

图9:我们的各种回归器的完整流水线与SIFT检测器的时间比较。 评估是在同一台计算机上以640×418图像进行的。
6 结论
我们引入了一种学习方案,可以在天气和光照条件急剧变化的情况下可靠地检测关键点。我们提出了一种有效的方法来生成训练回归者的训练集。我们学习了三个回归器,其中分段线性回归器显示了最好的结果。我们在新的室外关键点基准数据集中评估了回归指标。在我们的新基准数据集上,我们的回归变量的性能明显优于当前最新水平,并且在标准牛津数据集上也达到了最新水平的性能,证明了它们的泛化能力。
一个有趣的未来研究方向是扩展我们的方法以扩展空间。例如,在[18]中应用于FAST的策略也可以直接应用于我们的方法。
参考文献
[1] A. Alahi, R. Ortiz, and P. Vandergheynst. FREAK: Fast Retina Keypoint. In Conference on Computer Vision and Pattern Recognition, 2012. 7
[2] A. B. Ashraf, S. Lucey, and T. Chen. Reinterpreting the ApplicationofGaborFiltersasaManipulationoftheMarginin LinearSupportVectorMachines. IEEETransactionsonPattern Analysis and Machine Intelligence, 32(7):1335–1341, 2010. 5
[3] H. Bay, A. Ess, T. Tuytelaars, and L. Van Gool. SURF: Speeded Up Robust Features. Computer Vision and Image Understanding, 10(3):346–359, 2008. 1, 7
[4] L. Breiman. Hinging Hyperplanes for Regression, Classification, and Function Approximation. IEEE Transactions on Information Theory, 39(3):999–1013, 1993. 4
[5] M. Brown, G. Hua, and S. Winder. Discriminative Learning of Local Image Descriptors. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011. 2
[6] M. Calonder, V. Lepetit, C. Strecha, and P. Fua. BRIEF: Binary Robust Independent Elementary Features. In European Conference on Computer Vision, September 2010. 7
[7] C.CortesandV.Vapnik. Support-VectorNetworks. Machine Learning, 20(3):273–297, 1995. 4
[8] P. Dollar, Z. Tu, and S. Belongie. Supervised Learning of Edges and Object Boundaries. In Conference on Computer Vision and Pattern Recognition, 2006. 2
[9] R.-E. Fan, K.-W. Chang, C.-J. Hsieh, X.-R. Wang, and C.-J. Lin. LIBLINEAR:ALibraryforLargeLinearClassification. JournalofMachineLearningResearch,9:1871–1874,2008. 5
[10] W. F¨orstner, T. Dickscheid, and F. Schindler. Detecting InterpretableandAccurateScale-InvariantKeypoints. InInternational Conference on Computer Vision, September 2009. 1, 2
[11] W. F¨orstner and G. E. A Fast Operator for Detection and Precise Location of Distinct Points, Corners And Centres of Circular Features. In ISPRS Intercommission Conference on Fast Processing of Photogrammetric Data, 1987. 1, 2
[12] C. Harris and M. Stephens. A Combined Corner and Edge Detector. In Fourth Alvey Vision Conference, 1988. 1, 2
[13] W. Hartmann, M. Havlena, and K. Schindler. Predicting Matchability. In Conference on Computer Vision and Pattern Recognition, June 2014. 2
[14] D. Hauagge and N. Snavely. Image Matching Using Local Symmetry Features. In Conference on Computer Vision and Pattern Recognition, June 2012. 2
[15] N. Jacobs, N. Roman, and R. Pless. Consistent Temporal VariationsinManyOutdoorScenes. InConferenceonComputer Vision and Pattern Recognition, 2007. 2, 3, 4
[16] P.-Y. Laffont, Z. Ren, X. Tao, C. Qian, and J. Hays. Transient Attributes for High-level Understanding and Editing of OutdoorScenes. ACMTransactionsonGraphics,33(4):149, 2014. 2
[17] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. GradientBased Learning Applied to Document Recognition. Proceedings of the IEEE, 1998. 6
[18] S. Leutenegger, M. Chli, and R. Siegwart. BRISK: Binary Robust Invariant Scalable Keypoints. In International Conference on Computer Vision, 2011. 7, 8
[19] C. J. Lin, R. C. Weng, and S. S. Keerthi. Trust Region Newton Method for Logistic Regression. Journal of Machine Learning Research, 9:627–650, 2008. 5
[20] D. Lowe. Distinctive Image Features from Scale-Invariant Keypoints. International Journal of Computer Vision, 20(2):91–110, 2004. 1, 3, 7
[21] P. Mainali, G. Lafruit, K. Tack, L. V. Gool, and R. Lauwereins. Derivative-Based Scale Invariant Image Feature Detector With Error Resilience. IEEE Transactions on Image Processing, 23(5):2380–2391, 2014. 2
[22] P. Mainali, G. Lafruit, Q. Yang, B. Geelen, L. V. Gool, and R. Lauwereins. SIFER: Scale-Invariant Feature Detector with Error Resilience. International Journal of Computer Vision, 104(2):172–197, 2013. 2
[23] K. Mikolajczyk, T. Tuytelaars, C. Schmid, A. Zisserman, J. Matas, F. Schaffalitzky, T. Kadir, and L. Van Gool. A ComparisonofAffineRegionDetectors. InternationalJournal of Computer Vision, 65(1/2):43–72, 2005. 1, 2, 7
[24] H.Moravec. ObstacleAvoidanceandNavigationintheReal WorldbyaSeeingRobotRover. Intech.reportCMU-RI-TR80-03, Robotics Institute, Carnegie Mellon University, Stanford University, September 1980. 1, 2
[25] A. Richardson and E. Olson. Learning Convolutional Filters for Interest Point Detection. In International Conference on Robotics and Automation, pages 631–637, May 2013. 2
[26] A. Rodriguez, V. N. Boddeti, B. V. Kumar, and A. Mahalanobis. Maximum Margin Correlation Filter: A New Approach for Localization and Classification. IEEE Transactions on Image Processing, 22(2):631–643, 2013. 5
[27] E. Rosten and T. Drummond. Machine Learning for HighSpeed Corner Detection. In European Conference on Computer Vision, 2006. 2
[28] E. Rosten, R. Porter, and T. Drummond. Faster and Better: A Machine Learning Approach to Corner Detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32:105–119, 2010. 1, 2, 6, 7
[29] E. Rublee, V. Rabaud, K. Konolidge, and G. Bradski. ORB: An Efficient Alternative to SIFT or SURF. In International Conference on Computer Vision, 2011. 7
[30] S. Salti, A. Lanza, and L. D. Stefano. Keypoints from Symmetries by Wave Propagation. In Conference on Computer Vision and Pattern Recognition, June 2013. 2
[31] A. Sironi, V. Lepetit, and P. Fua. Multiscale Centerline Detection by Learning a Scale-Space Distance Transform. In Conference on Computer Vision and Pattern Recognition, 2014. 1, 4, 5, 6
[32] A. Sironi, B. Tekin, R. Rigamonti, V. Lepetit, and P. Fua. Learning Separable Filters. IEEE Transactions on Pattern Analysis and Machine Intelligence, 99, 2014. 5
[33] J. ˇSochman and J. Matas. Waldboost - Learning for Time Constrained Sequential Detection. In Conference on Computer Vision and Pattern Recognition, pages 150–157, June 2005. 2
[34] J. ˇSochman and J. Matas. Learning a Fast Emulator of a Binary Decision Process. In Asian Conference on Computer Vision, pages 236–245, 2007. 2
[35] C. Strecha, A. Lindner, K. Ali, and P. Fua. Training for Task Specific Keypoint Detection. In DAGM Symposium on Pattern Recognition, 2009. 2
[36] T. Trzcinski, M. Christoudias, P. Fua, and V. Lepetit. Boosting Binary Keypoint Descriptors. In Conference on Computer Vision and Pattern Recognition, June 2013. 2
[37] T. Tuytelaars and K. Mikolajczyk. Local Invariant Feature Detectors: A Survey. Found. Trends. Comput. Graph. Vis., 3(3):177–280, July 2008. 1
[38] S. Wang and X. Sun. Generalization of Hinging Hyperplanes. IEEE Transactions on Information Theory, 51(12):4425–4431, 2005. 4
Computer Vision_33_SIFT:TILDE: A Temporally Invariant Learned DEtector——2014的更多相关文章
- 特征点检测--基于CNN:TILDE: A Temporally Invariant Learned DEtector
TILDE: A Temporally Invariant Learned DEtector Yannick Verdie1,∗ Kwang Moo Yi1,∗ Pascal Fua1 Vincent ...
- Computer Vision_33_SIFT:LIFT: Learned Invariant Feature Transform——2016
此部分是计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面.对于自己不太熟悉的领域比如摄像机标定和立体视觉,仅仅列出上google上引用次数比较多的文献.有一些刚刚出版的 ...
- Computer Vision_33_SIFT: A novel point-matching algorithm based on fast sample consensus for image registration——2015
此部分是计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面.对于自己不太熟悉的领域比如摄像机标定和立体视觉,仅仅列出上google上引用次数比较多的文献.有一些刚刚出版的 ...
- Computer Vision_33_SIFT:Fast Adaptive Bilateral Filtering——2018
此部分是计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面.对于自己不太熟悉的领域比如摄像机标定和立体视觉,仅仅列出上google上引用次数比较多的文献.有一些刚刚出版的 ...
- Computer Vision_33_SIFT:A novel coarse-to-fine scheme for automatic image registration based on SIFT and mutual information——2014
此部分是计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面.对于自己不太熟悉的领域比如摄像机标定和立体视觉,仅仅列出上google上引用次数比较多的文献.有一些刚刚出版的 ...
- Computer Vision_33_SIFT:An Improved RANSAC based on the Scale Variation Homogeneity——2016
此部分是计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面.对于自己不太熟悉的领域比如摄像机标定和立体视觉,仅仅列出上google上引用次数比较多的文献.有一些刚刚出版的 ...
- Computer Vision_33_SIFT:ORB_An efficient alternative to SIFT or SURF——2012
此部分是计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面.对于自己不太熟悉的领域比如摄像机标定和立体视觉,仅仅列出上google上引用次数比较多的文献.有一些刚刚出版的 ...
- Computer Vision_33_SIFT:An efficient SIFT-based mode-seeking algorithm for sub-pixel registration of remotely sensed images——2015
此部分是计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面.对于自己不太熟悉的领域比如摄像机标定和立体视觉,仅仅列出上google上引用次数比较多的文献.有一些刚刚出版的 ...
- Computer Vision_33_SIFT:Robust scale-invariant feature matching for remote sensing image registration——2009
此部分是计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面.对于自己不太熟悉的领域比如摄像机标定和立体视觉,仅仅列出上google上引用次数比较多的文献.有一些刚刚出版的 ...
随机推荐
- Python数据抓取技术与实战 pdf
Python数据抓取技术与实战 目录 D11章Python基础1.1Python安装1.2安装pip1.3如何查看帮助1.4D1一个实例1.5文件操作1.6循环1.7异常1.8元组1.9列表1.10字 ...
- 通过pathinfo返回扩展名
strtolower(pathinfo(abs.php,PATHINFO_EXTENSION)); 小写 通过pathinfo返回扩展名 pathinfo() 函数以数组的形式返回文件路径的信息. p ...
- Nginx - upstream sent invalid chunked response while reading upstream 异常问题
一个 post 的请求,直接调接口服务数据正常返回,但是通过 nginx 代理后, 什么都没有返回. nginx 配置如下: 使用 postman 调用,返回如下: 于是检查日志报错信息,如下: ng ...
- class类名在webpack项目中的两种引用方式
一.问题描述 在项目工程中,我们通常既用到css module,也用到普通的less文件引用方式,代码及webpack配置如下,运行时,发现只有css module起作用,如何让两者都起作用呢? // ...
- docker中的fastdfs
准备环节)(本文遗漏当初出现的一个问题由于是docker装的fastdfs所以tracker storage client,nginx,nginx module都在同一个容器中只需要修改配置 特别注意 ...
- 安装Windows和Ubuntu双系统2
安装Windows和Ubuntu双系统 0.552016.12.10 15:54:41字数 2101阅读 6644 这几天开始动手做毕设啦,打算好好过把Linux瘾,接下来便是这两天我在联想电脑上安装 ...
- 微信小程序,内容组件中兼容的H5组件
受信任的HTML节点及属性 全局支持class和style属性,不支持id属性. 节点 属性 a abbr address article aside b bdi bdo ...
- Java IO把一个文件中的内容以字符串的形式读出来
代码记录(备查): /** * 把一个文件中的内容以字符串的形式读出来 * * @author zhipengs * */ public class FileToString { public sta ...
- SQL触发器中的inserted表和deleted表
开发也有年头了,但是触发器确实用的比较少,但是无容置疑触发器确实不错, 最近项目要求需要用到的触发器特别多.频繁,觉得很有必要记录和积累下. 在触发器语句中用两个特殊的表一个是deleted表和ins ...
- SORRY_FOR_MY_LIFE
人生最大的痛苦不在于真正的痛苦, 而是没有确切的人生方向, 我们总是想的很多, 但是最后才发现, 我们一直拿自己的弱点与别人的长处竞争, 因为,我们总是得不到自己想要的, 但是最多的是对于没有目标的人 ...