linux下的进程通信之管道与FIFO
概念:管道是由内核管理的一个缓冲区,相当于我们放入内存中的一个纸条。管道的一端连接一个进程的输出。这个进程会向管道中放入信息。管道的另一端连接一个进程的输入,这个进程取出被放入管道的信息。
优点:不需要加锁,基于字节流不需要定义数据结构
缺点:速度慢,容量有限,只能用于父子进程之间,使用场景狭窄
基本原理:
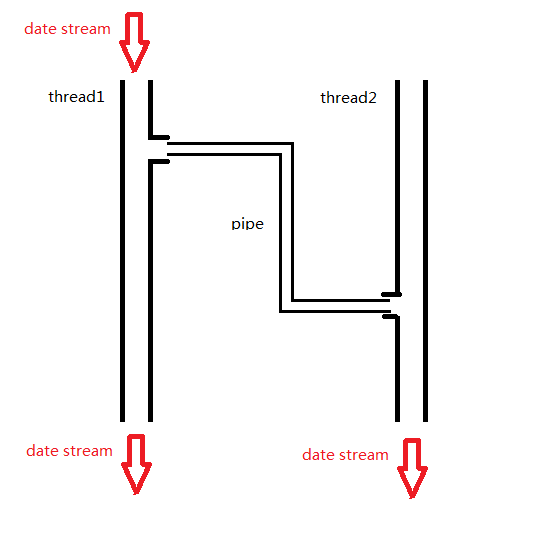
一个缓冲区不需要很大,它被设计成为环形的数据结构,以便管道可以被循环利用。当管道中没有信息的话,从管道中读取的进程会等待,直到另一端的进程放入信息。当管道被放满信息的时候,尝试放入信息的进程会等待,直到另一端的进程取出信息。当两个进程都终结的时候,管道也自动消失。

从原理上,管道利用fork机制建立,从而让两个进程可以连接到同一个PIPE上。最开始的时候,上面的两个箭头都连接在同一个进程Process 1上(连接在Process 1上的两个箭头)。当fork复制进程的时候,会将这两个连接也复制到新的进程(Process 2)。随后,每个进程关闭自己不需要的一个连接 (两个黑色的箭头被关闭; Process 1关闭从PIPE来的输入连接,Process 2关闭输出到PIPE的连接),这样,剩下的红色连接就构成了如上图的PIPE。

实现细节:
在 Linux 中,管道的实现并没有使用专门的数据结构,而是借助了文件系统的file结构和VFS的索引节点inode。通过将两个 file 结构指向同一个临时的 VFS 索引节点,而这个 VFS 索引节点又指向一个物理页面而实现的。如下图

有两个 file 数据结构,但它们定义文件操作例程地址是不同的,其中一个是向管道中写入数据的例程地址,而另一个是从管道中读出数据的例程地址。这样,用户程序的系统调用仍然是通常的文件操作,而内核却利用这种抽象机制实现了管道这一特殊操作。
关于管道的读写
管道实现的源代码在fs/pipe.c中,在pipe.c中有很多函数,其中有两个函数比较重要,即管道读函数pipe_read()和管道写函数pipe_wrtie()。管道写函数通过将字节复制到 VFS 索引节点指向的物理内存而写入数据,而管道读函数则通过复制物理内存中的字节而读出数据。当然,内核必须利用一定的机制同步对管道的访问,为此,内核使用了锁、等待队列和信号。
当写进程向管道中写入时,它利用标准的库函数write(),系统根据库函数传递的文件描述符,可找到该文件的 file 结构。file 结构中指定了用来进行写操作的函数(即写入函数)地址,于是,内核调用该函数完成写操作。写入函数在向内存中写入数据之前,必须首先检查 VFS 索引节点中的信息,同时满足如下条件时,才能进行实际的内存复制工作:
·内存中有足够的空间可容纳所有要写入的数据;
·内存没有被读程序锁定。
如果同时满足上述条件,写入函数首先锁定内存,然后从写进程的地址空间中复制数据到内存。否则,写入进程就休眠在 VFS 索引节点的等待队列中,接下来,内核将调用调度程序,而调度程序会选择其他进程运行。写入进程实际处于可中断的等待状态,当内存中有足够的空间可以容纳写入数据,或内存被解锁时,读取进程会唤醒写入进程,这时,写入进程将接收到信号。当数据写入内存之后,内存被解锁,而所有休眠在索引节点的读取进程会被唤醒。
管道的读取过程和写入过程类似。但是,进程可以在没有数据或内存被锁定时立即返回错误信息,而不是阻塞该进程,这依赖于文件或管道的打开模式。反之,进程可以休眠在索引节点的等待队列中等待写入进程写入数据。当所有的进程完成了管道操作之后,管道的索引节点被丢弃,而共享数据页也被释放。
Linux函数原型:
#include <unistd.h> int pipe(int filedes[]);
filedes[0]用于读出数据,读取时必须关闭写入端,即close(filedes[1]);
filedes[1]用于写入数据,写入时必须关闭读取端,即close(filedes[0])。
程序实例:
int main(void)
{
int n;
int fd[];
pid_t pid;
char line[MAXLINE]; if(pipe(fd) ){ /* 先建立管道得到一对文件描述符 */
exit();
} if((pid = fork()) ) /* 父进程把文件描述符复制给子进程 */
exit();
else if(pid > ){ /* 父进程写 */
close(fd[]); /* 关闭读描述符 */
write(fd[], "\nhello world\n", );
}
else{ /* 子进程读 */
close(fd[]); /* 关闭写端 */
n = read(fd[], line, MAXLINE);
write(STDOUT_FILENO, line, n);
} exit();
}
FIFO放在管道一起是因为FIFO是一种先进先出的管道,任何FIFO都非常类似管道:但是在文件系统中不拥有磁盘块,打开的FIFO总是与一个内核缓冲区相关联,这一缓冲区中临时存放一个或多个进程之间交换的数据。
优点: 可以打开已经存在的管道,使得任意的两个进程可以共享同一个管道
缺点: 和管道一样都是半双工的,都是基于字节流的没有数据结构
基本原理:fifo管道的本质是操作系统中的命名文件(也就是说fifo管道是一个文件.),当然Linux的理念就是万物皆文件,它在操作系统中以命名文件的形式存在,我们可以在操作系统中看见fifo管道,在你有权限的情况下,甚至可以读写他们。
代码示例:
现在我们来尝试写一个fifo的管道的服务器端,我们先创建一个管道,然后以只读的方式打开它,等待客户连接,当有客户链接上以后就会循环的读取管道中的数据,我们创建一个"fifo_server.c"文件
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/stat.h> #define FIFO_NAME "myfifo" int main()
{
int result; int fifo_fd;
char buffer[];
int buffer_len; /* 先删除之前可能遗留的管道文件,然后再次创建它 */
unlink( FIFO_NAME );
result = mkfifo( FIFO_NAME, );
if( result != )
{
printf( "error:can't create a fifo.\n" );
return ;
} /* 以只读的方式打开管道文件 */
fifo_fd = open( FIFO_NAME, O_RDONLY );
if( fifo_fd < )
{
printf( "error:can't open a fifo.\n" );
return ;
} /* 循环从管到文件中读取数据 */
do
{
memset( buffer, , );
buffer_len = read( fifo_fd, buffer, );
buffer[buffer_len] = '\0';
printf( "read:%s\n", buffer );
}
while( memcmp( buffer, "close", ) != ); close( fifo_fd );
unlink( FIFO_NAME ); return ;
}
现在我们来写客户端,客户端会判断一下管道是否存在,如果存在则以只写的方式打开它,然后可以循环的向管道中写入数据,我们来创建一个"fifo_client.c":
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/stat.h> #define FIFO_NAME "myfifo" int main()
{
int result; int fifo_fd;
char buffer[];
int buffer_len; /* 判断一下管道文件是否存在,不存在就退出程序 */
result = access( FIFO_NAME, F_OK );
if( result == - )
{
printf( "error:can't find the fifo.\n" );
return ;
} /* 以只写的方式打开管到文件 */
fifo_fd = open( FIFO_NAME, O_WRONLY );
if( fifo_fd < )
{
printf( "error:can't open a fifo.\n" );
return ;
} /* 循环向管到文件中写入数据 */
do
{
memset( buffer, , );
printf( "Please input something:" );
scanf( "%s", buffer );
buffer_len = write( fifo_fd, buffer, strlen( buffer ) );
printf( "write:%s\n", buffer );
}
while( memcmp( buffer, "close", ) != ); close( fifo_fd );
unlink( FIFO_NAME ); return ; }
好的,现在我们来编译一下这两个文件,并且尝试启动服务器:
root@Server:/home/root/workspace/pipe/fifo# gcc fifo_server.c -o fifos
root@Server:/home/root/workspace/pipe/fifo# gcc fifo_client.c -o fifoc
root@Server:/home/root/workspace/pipe/fifo# ./fifos
现在我们来尝试利用客户端发送信息,我们重新启动一个终端,在上面执行客户端,尝试输入一些数据,最后输入"close"来关闭服务器和客户端:
root@Server:/home/root/workspace/pipe/fifo# ./fifoc
Please input something:hello
write:hello
Please input something:hi
write:hi
Please input something:areyouok?
write:areyouok?
Please input something:funthinkyou
write:funthinkyou
Please input something:close
write:close
root@Server:/home/root/workspace/pipe/fifo#
我们再开看一下服务器那边的情况:
root@Server:/home/root/workspace/pipe/fifo# ./fifos
read:hello
read:hi
read:areyouok?
read:funthinkyou
read:close
root@Server:/home/root/workspace/pipe/fifo#
可以看到服务器收到了我们从客户端发送的所有数据。两个进程能够正常的使用管道进行通信了。
利用管道进行数据交互的最好方法就是创建两个管道,而一个管道只负责一个方向通信。这样是因为我们无法梳理数据的读写顺序,尤其是在拥有多个客户端的情况下。也就是说我们无法保证自己写入的数据不被自己读取,或者是自己想要获得数据不被他人读取。这个法则对fifo管道也同样适用。管道通信往往只应用于进程间的简单数据交流,不需要向互联网通信那样支持多客户端高并发等等,只需要读写对应的文件就可以了。
linux下的进程通信之管道与FIFO的更多相关文章
- linux 进程通信之 管道和FIFO
进程间通信:IPC概念 IPC:Interprocess Communication,通过内核提供的缓冲区进行数据交换的机制. IPC通信的方式: pipe:管道(最简单) fifo:有名管道 mma ...
- linux下的进程通信之信号量semaphore
概念: IPC 信号量和内核信号量非常相似,是内核信号量的用户态版本. 优点:每个IPC信号量可以保护一个或者多个信号量值的集合,而不像内核信号量一样只有一个值,这意味着同一个IPC资源可以保护多个独 ...
- linux的IPC进程通信方式-匿名管道(一)
linux的IPC进程通信-匿名管道 什么是管道 如果你使用过Linux的命令,那么对于管道这个名词你一定不会感觉到陌生,因为我们通常通过符号"|"来使用管道,但是管道的真正定义是 ...
- Linux下多任务间通信和同步-概述
Linux下多任务间通信和同步-概述 嵌入式开发交流群280352802,欢迎加入! 在前面,我们学习了两种多任务的实现手段:进程和线程.由于进程是工作在独立的内存空间中,不同的进程间不能直接访问到对 ...
- Linux下多任务间通信和同步-mmap共享内存
Linux下多任务间通信和同步-mmap共享内存 嵌入式开发交流群280352802,欢迎加入! 1.简介 共享内存可以说是最有用的进程间通信方式.两个不用的进程共享内存的意思是:同一块物理内存被映射 ...
- Linux下多任务间通信和同步-信号
Linux下多任务间通信和同步-信号 嵌入式开发交流群280352802,欢迎加入! 1.概述 信号是在软件层次上对中断机制的一种模拟,是一种异步通信方式.信号可以直接进行用户空间进程和内核进程之间的 ...
- linux下监控进程需掌握的四个命令
linux下监控进程需掌握的四个命令 在LInux系统下,最困难的工作之一就是跟踪正在系统中运行的程序,尤其是现在,图形桌面使用很多的程序,只是为了生成一个桌面环境,系统中运行了太多的进程,幸运的 ...
- Linux下的进程与线程(二)—— 信号
Linux进程之间的通信: 本文主要讨论信号问题. 在Linux下的进程与线程(一)中提到,调度器可以用中断的方式调度进程. 然而,进程是怎么知道自己需要被调度了呢?是内核通过向进程发送信号,进程才得 ...
- Linux下的进程控制块(PCB)
本文转载自Linux下的进程控制块(PCB) 导语 进程在操作系统中都有一个户口,用于表示这个进程.这个户口操作系统被称为PCB(进程控制块),在linux中具体实现是 task_struct数据结构 ...
随机推荐
- GeoJSON与GeoBuf互相转换
GeoJSON格式通常比较大,网页需要较长时间加载,可以使用GeoBuf进行压缩. 使用GeoBuf有很多好处:结构紧凑.文件小.方便编码和解码.能适用各种GeoJSON等等. 使用: 1.安装 ge ...
- Linux监控系统概览
自从Linux系统诞生之始,监控系统就随之出现. 当然说到监控系统,我们就必须聊到SNMP协议,SNMP分为管理端(NMP)和被管理端. 管理端周期性的到被监控端采集数据,被监控端还需要有权限收集数据 ...
- HDU 6162 - Ch’s gift | 2017 ZJUT Multi-University Training 9
/* HDU 6162 - Ch’s gift [ LCA,线段树 ] | 2017 ZJUT Multi-University Training 9 题意: N节点的树,Q组询问 每次询问s,t两节 ...
- 007——转载-MATLAB读取文件夹下的文件名
(一)参考文献:https://blog.csdn.net/liutaojia/article/details/84899923 (二)第一步:获取文件夹下某类型数据的所有文件名 主要包括三个步骤: ...
- HTML div块内剧中
在HTML中有一个块内元素剧中的方法 那就是margin:0 auto; 剧中前 剧中后
- 42 | grant之后要跟着flush privileges吗?
在 MySQL 里面,grant 语句是用来给用户赋权的.不知道你有没有见过一些操作文档里面提到,grant 之后要马上跟着执行一个 flush privileges 命令,才能使赋权语句生效.我最开 ...
- C/C++ -- 判断字符串中存在中文
电脑系统中的英文字符串和中文字符最根本的区别就在于: 1.英文的 ASCII 码,其最高位为 0,占一个字节 注:英文的ASCII码范围是在0到127,二进制为(0000 0000 ~ 0111 11 ...
- pyzabbix
pyzabbix
- getchar 和EOF
本文章基于:http://www.cnblogs.com/QLinux/articles/2465329.html,稍作了修改. 大师级经典的著作,要字斟句酌的去读,去理解.以前在看K&R的T ...
- lightgbm用于排序
一. LTR(learning to rank)经常用于搜索排序中,开源工具中比较有名的是微软的ranklib,但是这个好像是单机版的,也有好长时间没有更新了.所以打算想利用lightgbm进行排序, ...