C++ STL 中 map 容器
C++ STL 中 map 容器
Map是STL的一个关联容器,它提供一对一(其中第一个可以称为关键字,每个关键字只能在map中出现一次,第二个可能称为该关键字的值)的数据 处理能力,由于这个特性,它完成有可能在我们处理一对一数据的时候,在编程上提供快速通道。这里说下map内部数据的组织,map内部自建一颗红黑树(一 种非严格意义上的平衡二叉树),这颗树具有对数据自动排序的功能,所以在map内部所有的数据都是有序的,后边我们会见识到有序的好处。
1、map简介
map是一类关联式容器。它的特点是增加和删除节点对迭代器的影响很小,除了那个操作节点,对其他的节点都没有什么影响。
对于迭代器来说,可以修改实值,而不能修改key。
2、map的功能
自动建立Key - value的对应。key 和 value可以是任意你需要的类型。
根据key值快速查找记录,查找的复杂度基本是Log(N),如果有1000个记录,最多查找10次,1,000,000个记录,最多查找20次。
快速插入Key -Value 记录。
快速删除记录
根据Key 修改value记录。
遍历所有记录。
3、使用map
使用map得包含map类所在的头文件
- #include <map> //注意,STL头文件没有扩展名.h
map对象是模板类,需要关键字和存储对象两个模板参数:
- std:map<int,string> personnel;
这样就定义了一个用int作为索引,并拥有相关联的指向string的指针.
为了使用方便,可以对模板类进行一下类型定义,
- typedef map<int,CString> UDT_MAP_INT_CSTRING;
- UDT_MAP_INT_CSTRING enumMap;
4、map的构造函数
map共提供了6个构造函数,这块涉及到内存分配器这些东西,略过不表,在下面我们将接触到一些map的构造方法,这里要说下的就是,我们通常用如下方法构造一个map:
- map<int, string> mapStudent;
5、数据的插入
在构造map容器后,我们就可以往里面插入数据了。这里讲三种插入数据的方法:
第一种:用insert函数插入pair数据(C++学习之Pair),下面举例说明(以下代码虽然是随手写的,应该可以在VC和GCC下编译通过,大家可以运行下看什么效果,在VC下请加入这条语句,屏蔽4786警告 #pragma warning (disable:4786) )
- //数据的插入--第一种:用insert函数插入pair数据
- #include <map>
- #include <string>
- #include <iostream>
- using namespace std;
- int main()
- {
- map<int, string> mapStudent;
- mapStudent.insert(pair<int, string>(, "student_one"));
- mapStudent.insert(pair<int, string>(, "student_two"));
- mapStudent.insert(pair<int, string>(, "student_three"));
- map<int, string>::iterator iter;
- for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
- cout<<iter->first<<' '<<iter->second<<endl;
- return ;
- }
第二种:用insert函数插入value_type数据
每个STL中的类都有value_type这种东西,通俗的说value_type 就是stl容器盛装的数据的数据类型,例如:
- vector<int> vec;
- vector<int>::value_type x;
上述两句代码,第一句是声明一个盛装数据类型是int的数据的vector,第二句是使用vector<int>::value_type定义一个变量x,这个变量x实际上是int类型的,因为vector<int>::value_type中声明的为int型。
相应的,假设有:
- vector<C> vec; //假设C是自定义类型
- vector<C>::value_type x;
那么第二句定义的变量x的数据类型是C。
每个STL容器类(感觉应该是迭代器类更加准确),都有一句相同的代码:
- typede T value_type;
其中T则是类模板中使用的参数 :
template <class T>
以STL的list容器为例,那么它的类定义就应该有下面的语句:
- template<class T>
- class list{
- publict:
- typedef T value_type;
- //……
- };
下面举例说明:
- //第二种:用insert函数插入value_type数据,下面举例说明
- #include <map>
- #include <string>
- #include <iostream>
- using namespace std;
- int main()
- {
- map<int, string> mapStudent;
- mapStudent.insert(map<int, string>::value_type (, "student_one"));
- mapStudent.insert(map<int, string>::value_type (, "student_two"));
- mapStudent.insert(map<int, string>::value_type (, "student_three"));
- map<int, string>::iterator iter;
- for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
- cout<<iter->first<<' '<<iter->second<<endl;
- return ;
- }
第三种:用数组方式插入数据,下面举例说明
- //第三种:用数组方式插入数据,下面举例说明
- #include <map>
- #include <string>
- #include <iostream>
- using namespace std;
- int main()
- {
- map<int, string> mapStudent;
- mapStudent[] = "student_one";
- mapStudent[] = "student_two";
- mapStudent[] = "student_three";
- map<int, string>::iterator iter;
- for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
- cout<<iter->first<<' '<<iter->second<<endl;
- }
以上三种用法,虽然都可以实现数据的插入,但是它们是有区别的,当然了第一种和第二种在效果上是完成一样的,用insert函数插入数据,在数据的 插入上涉及到集合的唯一性这个概念,即当map中有这个关键字时,insert操作是插入数据不了的,但是用数组方式就不同了,它可以覆盖以前该关键字对 应的值,用程序说明
- mapStudent.insert(map<int, string>::value_type (, "student_one"));
- mapStudent.insert(map<int, string>::value_type (, "student_two"));
上面这两条语句执行后,map中1这个关键字对应的值是“student_one”,第二条语句并没有生效,那么这就涉及到我们怎么知道insert语句是否插入成功的问题了,可以用pair来获得是否插入成功,程序如下
- pair<map<int, string>::iterator, bool> Insert_Pair;
- Insert_Pair = mapStudent.insert(map<int, string>::value_type (, "student_one"));
我们通过pair的第二个变量来知道是否插入成功,它的第一个变量返回的是一个map的迭代器,如果插入成功的话Insert_Pair.second应该是true的,否则为false。
6、 map的大小
在往map里面插入了数据,我们怎么知道当前已经插入了多少数据呢,可以用size函数,用法如下:
Int nSize = mapStudent.size();
7、 数据的遍历
这里也提供三种方法,对map进行遍历
第一种:应用前向迭代器
第二种:应用反相迭代器
第三种,用数组的形式
- #include<map>
- #include<iostream>
- #include<string>
- using namespace std;
- int main()
- {
- map<int,string> myString;
- myString.insert(pair<int,string>(,"xiaoming"));
- myString.insert(map<int,string>::value_type (,"xiaohong"));
- myString[] = "xiaoli";
- cout<<"向前迭代:"<<endl;
- map<int,string>::iterator iter;//向前迭代
- for(iter = myString.begin();iter != myString.end();iter++)
- {
- cout<<iter->first<<","<<iter->second<<endl;
- }
- cout<<"反向迭代器:"<<endl;
- map<int,string>::reverse_iterator iter2;
- for(iter2 = myString.rbegin();iter2 != myString.rend();iter2++)
- cout<<iter2->first<<","<<iter2->second<<endl;
- cout<<"数组迭代:"<<endl;
- int Length = myString.size();
- for(int i = ;i <= Length;i++)
- cout<<i<<","<<myString[i]<<endl;
- return ;
- }
运行结果:

8、查找并获取map中的元素(包括判定这个关键字是否在map中出现)
在这里我们将体会,map在数据插入时保证有序的好处。
要判定一个数据(关键字)是否在map中出现的方法比较多,这里标题虽然是数据的查找,在这里将穿插着大量的map基本用法。
这里给出三种数据查找方法
第一种:用count函数来判定关键字是否出现,其缺点是无法定位数据出现位置,由于map的特性,一对一的映射关系,就决定了count函数的返回值只有两个,要么是0,要么是1,出现的情况,当然是返回1了
第二种:用find函数来定位数据出现位置,它返回的一个迭代器,当数据出现时,它返回数据所在位置的迭代器,如果map中没有要查找的数据,它返回的迭代器等于end函数返回的迭代器。
查找map中是否包含某个关键字条目用find()方法,传入的参数是要查找的key,在这里需要提到的是begin()和end()两个成员,
分别代表map对象中第一个条目和最后一个条目,这两个数据的类型是iterator.
- #include <map>
- #include <string>
- #include <iostream>
- using namespace std;
- int main()
- {
- map<int, string> mapStudent;
- mapStudent.insert(pair<int, string>(, "student_one"));
- mapStudent.insert(pair<int, string>(, "student_two"));
- mapStudent.insert(pair<int, string>(, "student_three"));
- map<int, string>::iterator iter;
- iter = mapStudent.find();
- if(iter != mapStudent.end())
- cout<<"Find, the value is "<<iter->second<<endl;
- else
- cout<<"Do not Find"<<endl;
- return ;
- }
通过map对象的方法获取的iterator数据类型是一个std::pair对象,包括两个数据 iterator->first和 iterator->second分别代表关键字和存储的数据。
第三种:Equal_range
ForwardIter lower_bound(ForwardIter first, ForwardIter last,const _Tp& val)算法返回一个非递减序列[first, last)中的第一个大于等于值val的位置。这个函数用来返回要查找关键字的下界(是一个迭代器)
ForwardIter upper_bound(ForwardIter first, ForwardIter last, const _Tp& val)算法返回一个非递减序列[first, last)中第一个大于val的位置。这个函数用来返回要查找关键字的上界(是一个迭代器)
lower_bound和upper_bound如下图所示:
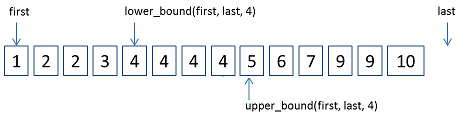
例如:map中已经插入了1,2,3,4的话,如果lower_bound(2)的话,返回的2,而upper-bound(2)的话,返回的就是3
Equal_range函数返回一个pair,pair里面第一个变量是Lower_bound返回的迭代器,pair里面第二个变量是Upper_bound返回的迭代器,如果这两个迭代器相等的话,则说明map中不出现这个关键字。
- #include <map>
- #include <string>
- #include <iostream>
- using namespace std;
- int main()
- {
- map<int, string> mapStudent;
- mapStudent[] = "student_one";
- mapStudent[] = "student_three";
- mapStudent[] = "student_five";
- map<int, string>::iterator iter;
- iter = mapStudent.lower_bound();
- //返回的是下界1的迭代器
- cout<<iter->second<<endl;
- iter = mapStudent.lower_bound();
- //返回的是下界2的迭代器
- cout<<iter->second<<endl;
- iter = mapStudent.lower_bound();
- //返回的是下界3的迭代器
- cout<<iter->second<<endl;
- iter = mapStudent.upper_bound();
- //返回的是上界0的迭代器
- cout<<iter->second<<endl;
- iter = mapStudent.upper_bound();
- //返回的是上界1的迭代器
- cout<<iter->second<<endl;
- iter = mapStudent.upper_bound();
- //返回的是上界2的迭代器
- cout<<iter->second<<endl;
- iter = mapStudent.upper_bound();
- //返回的是上界3的迭代器
- cout<<iter->second<<endl;
- pair<map<int, string>::iterator, map<int, string>::iterator> mappair;
- mappair = mapStudent.equal_range();
- if(mappair.first == mappair.second)
- cout<<"Do not Find"<<endl;
- else
- cout<<"Find"<<endl;
- mappair = mapStudent.equal_range();
- if(mappair.first == mappair.second)
- cout<<"Do not Find"<<endl;
- else
- cout<<"Find"<<endl;
- return ;
- }
运行结果:

9、从map中删除元素
移除某个map中某个条目用erase()
该成员方法的定义如下:
- iterator erase(iterator it);//通过一个条目对象删除
- iterator erase(iterator first,iterator last);//删除一个范围
- size_type erase(const Key&key);//通过关键字删除
- clear()就相当于enumMap.erase(enumMap.begin(),enumMap.end());
这里要用到erase函数,它有三个重载了的函数,下面在例子中详细说明它们的用法
- #include <map>
- #include <string>
- #include <iostream>
- using namespace std;
- int main()
- {
- map<int, string> mapStudent;
- mapStudent.insert(pair<int, string>(, "student_one"));
- mapStudent.insert(pair<int, string>(, "student_two"));
- mapStudent.insert(pair<int, string>(, "student_three"));
- //如果你要演示输出效果,请选择以下的一种,你看到的效果会比较好
- //如果要删除1,用迭代器删除
- map<int, string>::iterator iter;
- iter = mapStudent.find();
- mapStudent.erase(iter);
- //如果要删除1,用关键字删除
- int n = mapStudent.erase();//如果删除了会返回1,否则返回0
- //用迭代器,成片的删除
- //一下代码把整个map清空
- mapStudent.erase( mapStudent.begin(), mapStudent.end() );
- //成片删除要注意的是,也是STL的特性,删除区间是一个前闭后开的集合
- //自个加上遍历代码,打印输出吧
- }
10、map中的swap用法
map中的swap不是一个容器中的元素交换,而是两个容器所有元素的交换。
11、 排序 map中的sort问题
map中的元素是自动按Key升序排序,所以不能对map用sort函数;
这里要讲的是一点比较高深的用法了,排序问题,STL中默认是采用小于号来排序的,以上代码在排序上是不存在任何问题的,因为上面的关键字是int 型,它本身支持小于号运算,在一些特殊情况,比如关键字是一个结构体,涉及到排序就会出现问题,因为它没有小于号操作,insert等函数在编译的时候过 不去,下面给出两个方法解决这个问题。
第一种:小于号重载
- #include <iostream>
- #include <string>
- #include <map>
- using namespace std;
- typedef struct tagStudentinfo
- {
- int niD;
- string strName;
- bool operator < (tagStudentinfo const& _A) const
- { //这个函数指定排序策略,按niD排序,如果niD相等的话,按strName排序
- if(niD < _A.niD) return true;
- if(niD == _A.niD)
- return strName.compare(_A.strName) < ;
- return false;
- }
- }Studentinfo, *PStudentinfo; //学生信息
- int main()
- {
- int nSize; //用学生信息映射分数
- map<Studentinfo, int>mapStudent;
- map<Studentinfo, int>::iterator iter;
- Studentinfo studentinfo;
- studentinfo.niD = ;
- studentinfo.strName = "student_one";
- mapStudent.insert(pair<Studentinfo, int>(studentinfo, ));
- studentinfo.niD = ;
- studentinfo.strName = "student_two";
- mapStudent.insert(pair<Studentinfo, int>(studentinfo, ));
- for (iter=mapStudent.begin(); iter!=mapStudent.end(); iter++)
- cout<<iter->first.niD<<' '<<iter->first.strName<<' '<<iter->second<<endl;
- return ;
- }
第二种:仿函数的应用,这个时候结构体中没有直接的小于号重载
- //第二种:仿函数的应用,这个时候结构体中没有直接的小于号重载,程序说明
- #include <iostream>
- #include <map>
- #include <string>
- using namespace std;
- typedef struct tagStudentinfo
- {
- int niD;
- string strName;
- }Studentinfo, *PStudentinfo; //学生信息
- class sort
- {
- public:
- bool operator() (Studentinfo const &_A, Studentinfo const &_B) const
- {
- if(_A.niD < _B.niD)
- return true;
- if(_A.niD == _B.niD)
- return _A.strName.compare(_B.strName) < ;
- return false;
- }
- };
- int main()
- { //用学生信息映射分数
- map<Studentinfo, int, sort>mapStudent;
- map<Studentinfo, int>::iterator iter;
- Studentinfo studentinfo;
- studentinfo.niD = ;
- studentinfo.strName = "student_one";
- mapStudent.insert(pair<Studentinfo, int>(studentinfo, ));
- studentinfo.niD = ;
- studentinfo.strName = "student_two";
- mapStudent.insert(pair<Studentinfo, int>(studentinfo, ));
- for (iter=mapStudent.begin(); iter!=mapStudent.end(); iter++)
- cout<<iter->first.niD<<' '<<iter->first.strName<<' '<<iter->second<<endl;
- return ;
- }
由于STL是一个统一的整体,map的很多用法都和STL中其它的东西结合在一起,比如在排序上,这里默认用的是小于号,即less<>,如果要从大到小排序呢,这里涉及到的东西很多,在此无法一一加以说明。
还要说明的是,map中由于它内部有序,由红黑树保证,因此很多函数执行的时间复杂度都是log2N的,如果用map函数可以实现的功能,而STL Algorithm也可以完成该功能,建议用map自带函数,效率高一些。
下面说下,map在空间上的特性,否则,估计你用起来会有时候表现的比较郁闷,由于map的每个数据对应红黑树上的一个节点,这个节点在不保存你的 数据时,是占用16个字节的,一个父节点指针,左右孩子指针,还有一个枚举值(标示红黑的,相当于平衡二叉树中的平衡因子),我想大家应该知道,这些地方 很费内存了吧,不说了……
12、 map的基本操作函数:
C++ maps是一种关联式容器,包含“关键字/值”对
begin() 返回指向map头部的迭代器
clear() 删除所有元素
count() 返回指定元素出现的次数
empty() 如果map为空则返回true
end() 返回指向map末尾的迭代器
equal_range() 返回特殊条目的迭代器对
erase() 删除一个元素
find() 查找一个元素
get_allocator() 返回map的配置器
insert() 插入元素
key_comp() 返回比较元素key的函数
lower_bound() 返回键值>=给定元素的第一个位置
max_size() 返回可以容纳的最大元素个数
rbegin() 返回一个指向map尾部的逆向迭代器
rend() 返回一个指向map头部的逆向迭代器
size() 返回map中元素的个数
swap() 交换两个map
upper_bound() 返回键值>给定元素的第一个位置
value_comp() 返回比较元素value的函数
本文章由以下博客或文章地址整理而成,目的为了方便自己和大家的查阅、理解。
http://blog.csdn.net/uqapuqap/archive/2009/08/14/4448067.aspx
http://www.360doc.com/content/13/0912/18/3373961_314006267.shtml#
http://blog.csdn.net/shawn_hou/article/details/38035577###;
C++ STL 中 map 容器的更多相关文章
- C++STL中map容器的说明和使用技巧(杂谈)
1.map简介 map是一类关联式容器.它的特点是增加和删除节点对迭代器的影响很小,除了那个操作节点,对其他的节点都没有什么影响.对于迭代器来说,可以修改实值,而不能修改key. 2.map的功能 自 ...
- STL中map与hash_map容器的选择收藏
这篇文章来自我今天碰到的一个问题,一个朋友问我使用map和hash_map的效率问题,虽然我也了解一些,但是我不敢直接告诉朋友,因为我怕我说错了,通过我查询一些帖子,我这里做一个总结!内容分别来自al ...
- C++ STL中Map的按Key排序和按Value排序
map是用来存放<key, value>键值对的数据结构,可以很方便快速的根据key查到相应的value.假如存储学生和其成绩(假定不存在重名,当然可以对重名加以区 分),我们用map来进 ...
- C++ STL中Map的相关排序操作:按Key排序和按Value排序 - 编程小径 - 博客频道 - CSDN.NET
C++ STL中Map的相关排序操作:按Key排序和按Value排序 - 编程小径 - 博客频道 - CSDN.NET C++ STL中Map的相关排序操作:按Key排序和按Value排序 分类: C ...
- STL中的容器介绍
STL中的容器主要包括序列容器.关联容器.无序关联容器等. 一]序列容器 (1) vector vector 是数组的一种类表示,提供自动管理内存的功能,除非其他类型容器有更好满足程序的要求,否则,我 ...
- C++中的STL中map用法详解(转)
原文地址: https://www.cnblogs.com/fnlingnzb-learner/p/5833051.html C++中的STL中map用法详解 Map是STL的一个关联容器,它提供 ...
- [C++]STL中的容器
C++11 STL中的容器 一.顺序容器: vector:可变大小数组: deque:双端队列: list:双向链表: forward_list:单向链表: array:固定大小数组: string: ...
- STL中的容器
STL中的容器 一. 种类: 标准STL序列容器:vector.string.deque和list. 标准STL关联容器:set.multiset.map和multimap. 非标准序列容器slist ...
- C++ STL中Map的按Key排序跟按Value排序
C++ STL中Map的按Key排序和按Value排序 map是用来存放<key, value>键值对的数据结构,可以很方便快速的根据key查到相应的value.假如存储学生和其成绩(假定 ...
随机推荐
- Asp.Net Server.MapPath()用法
做了一个上传文件的功能 本地测试没问题 部署到服务器之后 一直报错 由于 某些历史原因 看不到错误信息 最后发现是路径的问题 其实这么简单的问题 最早该想到的 ...... Server.MapPat ...
- 服务器端升级为select模型处理多客户端
流程图: select会定时的查询socket查询有没有新的网络连接,有没有新的数据需要读,有没有新的请求需要处理,一旦有新的数据需要处理,select就会返回,然后我们就可以处理相应的数据,sele ...
- PAT Basic 1030 完美数列 (25 分)
给定一个正整数数列,和正整数 p,设这个数列中的最大值是 M,最小值是 m,如果 M≤mp,则称这个数列是完美数列. 现在给定参数 p 和一些正整数,请你从中选择尽可能多的数构成一个完美数列. 输入格 ...
- “联邦对抗技术大赛”9月开战 微众银行呼唤开发者共同“AI创新”
“联邦对抗技术大赛”9月开战 微众银行呼唤开发者共同“AI创新” 从<第五元素>中的智能系统到<超体>中的信息操控,在科幻电影中人工智能已经发展到了极致.而在现实中,目前 ...
- Sereja and Brackets CodeForces - 380C (线段树+分治思路)
Sereja and Brackets 题目链接: CodeForces - 380C Sereja has a bracket sequence s1, s2, ..., *s**n, or, in ...
- Winforms界面开发DevExpress v19.2:Map、Pivot Grid等功能增强
DevExpress Winforms Controls 内置140多个UI控件和库,完美构建流畅.美观且易于使用的应用程序.无论是Office风格的界面,还是分析处理大批量的业务数据,DevExpr ...
- 放大镜如何用js
例如: let imgs = { small: ["imgA_1.jpg", "imgB_1.jpg", "imgC_1.jpg"], mi ...
- idea操作mysql数据库添加汉字时出现乱码解决方案
首先 然后 最后 在连接数据库后面加一个指定编码格式 编码格式: characterEncoding=UTF-8
- guava的一些用法
package guavaTest; import com.google.common.base.CharMatcher; import com.google.common.base.Joiner; ...
- logback导入依赖 NoSuchMethodException
1.我遇到的问题是Spring版本和logback低版本冲突的问题 如何解决:把logback.classic和logback.core等依赖换成1.2.2以上版本的依赖