HDU - 2196(树形DP)
题目:
Hint: the example input is corresponding to this graph. And from the graph, you can see that the computer 4 is farthest one from 1, so S1 = 3. Computer 4 and 5 are the farthest ones from 2, so S2 = 2. Computer 5 is the farthest one from 3, so S3 = 3. we also get S4 = 4, S5 = 4.
InputInput file contains multiple test cases.In each case there is natural number N (N<=10000) in the first line, followed by (N-1) lines with descriptions of computers. i-th line contains two natural numbers - number of computer, to which i-th computer is connected and length of cable used for connection. Total length of cable does not exceed 10^9. Numbers in lines of input are separated by a space.OutputFor each case output N lines. i-th line must contain number Si for i-th computer (1<=i<=N).Sample Input
5
1 1
2 1
3 1
1 1
Sample Output
2
3
4
4 题意:
不知道多少组测试样例,第一行一个n,代表有多少台电脑,接下来有n-1行,每行两个数a,b,第i行(2<=i<=n)表示编号为i的电脑连接编号为a的电脑,他们的距离是b(即电缆长度),问每台电脑到其最远点距离 思路:树形DP(感谢大佬的视频讲解 https://www.bilibili.com/video/av12194537?t=1863)
我们定义f【i】表示编号为i的节点第一步向儿子方向走的最远距离
g【i】表示编号为i的节点第一步向父亲方向走的最远距离
p【i】表示编号为i的节点的父亲节点编号
w(a,b)表示编号a节点到编号b节点的距离,a和b是一条边连接的,即边权
用2个dfs求出这三个数组
递推式:f【u】=max(f【v】,w(u,v))//v是u的孩子
g【u】=w(u,p【u】)+max(g【p【u】】,f【v】+w(p【u】,u))//v是u的兄弟
两个递推式在下面讲解
对于第i个节点,答案就是max(f【i】,g【i】)
因为对一个节点来说,它的第一步只能是向孩子方向走(可能有多个孩子)或者向父亲方向走 第一遍dfs求出f和p数组,我们默认1节点是根节点,它的父亲节点是0(假想)
这个深搜很容易理解,直接上代码
long long int dfs1(int u,int fa)
{//u节点走孩子方向的最大距离
for(int i=;i<E[u].size();++i){
int v=E[u][i].first;
int w=E[u][i].second;
if(v!=fa)
f[u]=max(f[u],dfs1(v,p[v]=u)+w);
/*要么是当前值(可能有多个孩子),要么是当前点到孩子点的距离加上f【v】*/
}
return f[u];
}
第二遍dfs求出g数组,看图(假设边权都为1)
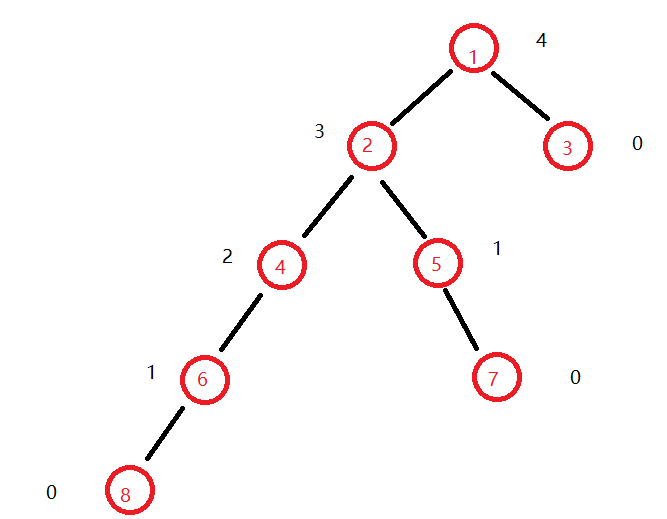
图中红色数字为节点编号,黑色数字表示f【u】的值(第一遍dfs求出),即当前节点第一步向孩子方向走的最大距离
第一遍dfs,相当于从下往上进行动态规划,而第二遍dfs,则是从上往下进行动态规划
怎么用f和p数组算出g数组呢
假设我们要求节点u的g,令fa是u节点的父亲节点
首先,g【u】=g【fa】(假设第一步往上走且第二步也是往上走的距离最大)
然后遍历fa连接的所有节点
若找到fa的父亲节点,跳过,因为我们一开始就假设走这条路
若找到u节点,跳过,跑回来干嘛
若找到其他节点(必然为u节点的兄弟节点,我们设为v,v可能有多个,也可能没有)
则比较g【u】和w(fa,v)+f【v】的大小,即比较第二步往上走好一点还是往下走好一点
遍历完之后,g【u】加上w(fa,u),就成功把g【u】算出来了
我们看出,要想求g【u】,就要先知道g【fa】,即要先知道上面节点的g,才能求下面节点的g
所以,这是一个从上往下走的过程
对于根节点的计算,我们不存在w(0,1)所以还要注意一下边界问题
代码实现:
void dfs2(int u,int fa)
{
int t=;
g[u]=g[fa];
for(int i=;i<E[fa].size();++i){
int v=E[fa][i].first;
int w=E[fa][i].second;
if(v==p[fa]) continue;//fa的父亲节点,跳过
if(v==u) t=w;//又跑回来了,跳过
else g[u]=max(g[u],f[v]+w);//更新
}
g[u]+=t;
for(int i=;i<E[u].size();++i){//dfs孩子节点,更新下面的g
int v=E[u][i].first;
int w=E[u][i].second;
if(v!=fa) dfs2(v,u);
}
}
我们模拟跑一下dfs2,从根节点开始
首先g【1】=g【0】=0;然后编号0节点是虚拟的,没有连接任何点,所以g【1】=0;
求节点2,g【2】=g【1】=0;然后遍历编号1节点连接的所有点
找到节点2,跳过,找到节点3,更新g【2】=max(g【2】,w(1,3)+f【3】)=max(0,1+0)=1;
遍历完后,我们加上w(1,2)=1,所以g【2】=1+1=2;
求节点4,g【4】=g【2】=2;然后遍历编号2节点连接的所有点
找到节点1,1是2的父亲节点,跳过
找到节点4,跳过
找到节点5,更新g【4】=max(g【4】,w(2,5)+f【5】)=max(2,1+1)=2;
遍历完后,我们加上w(2,4)=1,所以g【4】=2+1=3;
......
这样就更新好了g数组
然后答案就是max(f【i】,g【i】)啦,第一步要么向孩子方向走,要么向父亲方向走,找二者最大就行了
完整代码:
#include <bits/stdc++.h>
#define mp make_pair
using namespace std;
typedef long long int ll;
const int maxn=1e5+;
vector<pair<int,int> > E[maxn];
long long int f[maxn],g[maxn],p[maxn];
long long int dfs1(int u,int fa)
{//u节点走孩子方向的最大距离
for(int i=;i<E[u].size();++i){
int v=E[u][i].first;
int w=E[u][i].second;
if(v!=fa)
f[u]=max(f[u],dfs1(v,p[v]=u)+w);
}
return f[u];
}
void dfs2(int u,int fa)
{
int t=;
g[u]=g[fa];
for(int i=;i<E[fa].size();++i){
int v=E[fa][i].first;
int w=E[fa][i].second;
if(v==p[fa]) continue;
if(v==u) t=w;
else g[u]=max(g[u],f[v]+w);
}
g[u]+=t;
for(int i=;i<E[u].size();++i){
int v=E[u][i].first;
int w=E[u][i].second;
if(v!=fa) dfs2(v,u);
}
} int main()
{
int n;
while(cin>>n)
{
for(int i=;i<=n;++i)
E[i].clear();
memset(f,,sizeof(f));
memset(g,,sizeof(g));
memset(p,,sizeof(p));
for(int i=;i<=n;++i){
int a,b;
scanf("%d%d",&a,&b);
E[a].push_back(mp(i,b));
E[i].push_back(mp(a,b));
}
dfs1(,);
dfs2(,);
for(int i=;i<=n;++i){
printf("%lld\n",max(f[i],g[i]));
}
}
return ;
}
HDU - 2196(树形DP)的更多相关文章
- HDU 2196树形DP(2个方向)
HDU 2196 [题目链接]HDU 2196 [题目类型]树形DP(2个方向) &题意: 题意是求树中每个点到所有叶子节点的距离的最大值是多少. &题解: 2次dfs,先把子树的最大 ...
- HDU 2196 树形DP Computer
题目链接: HDU 2196 Computer 分析: 先从任意一点开始, 求出它到其它点的最大距离, 然后以该点为中心更新它的邻点, 再用被更新的点去更新邻点......依此递推 ! 代码: ...
- hdu 2196 树形dp
思路:先求以1为根时,每个节点到子节点的最大长度.然后再次从1进入进行更新. #include<iostream> #include<cstring> #include< ...
- hdu 4123 树形DP+RMQ
http://acm.hdu.edu.cn/showproblem.php? pid=4123 Problem Description Bob wants to hold a race to enco ...
- HDU 1520 树形dp裸题
1.HDU 1520 Anniversary party 2.总结:第一道树形dp,有点纠结 题意:公司聚会,员工与直接上司不能同时来,求最大权值和 #include<iostream> ...
- HDU 1561 树形DP入门
The more, The Better Time Limit: 6000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Oth ...
- HDU 1520 树形DP入门
HDU 1520 [题目链接]HDU 1520 [题目类型]树形DP &题意: 某公司要举办一次晚会,但是为了使得晚会的气氛更加活跃,每个参加晚会的人都不希望在晚会中见到他的直接上司,现在已知 ...
- codevs 1380/HDU 1520 树形dp
1380 没有上司的舞会 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 钻石 Diamond 题解 查看运行结果 回到问题 题目描述 Description Ural大学有N个职员 ...
- HDU 5834 [树形dp]
/* 题意:n个点组成的树,点和边都有权值,当第一次访问某个点的时候获得利益为点的权值 每次经过一条边,丢失利益为边的权值.问从第i个点出发,获得的利益最大是多少. 输入: 测试样例组数T n n个数 ...
- hdu 4267 树形DP
思路:先dfs一下,找出1,n间的路径长度和价值,回溯时将该路径长度和价值清零.那么对剩下的图就可以直接树形dp求解了. #include<iostream> #include<al ...
随机推荐
- ORM SQLAlchemy - 基本关系模式
1 一对多 一个parent对多个child,一对多关系添加一个外键到child表,用于保存对应parent.id的值,引用parent.relationship()在parent中指定,引用/保存 ...
- 卸载Ambari集群
清理ambari安装的hadoop集群 本文针对redhat或者centos 对于测试集群,如果通过ambari安装hadoop集群后,想重新再来一次的话,需要清理集群. 对于安装了很多hadoop组 ...
- 从源码看Java集合之ArrayList
Java集合之ArrayList - 吃透增删查改 从源码看初始化以及增删查改,学习ArrayList. 先来看下ArrayList定义的几个属性: private static final int ...
- mysql CONCAT函数
有时候我们需要使用coacat函数拼接一些字段的生成一个字符串,比如:select concat(field1,field2,field3) from xxx: 这时候我们就会的到一个这些字段的值拼 ...
- 我的新书,ArcGIS从0到1,京东接受预定,有160个视频,851分钟
我的新书,ArcGIS从0到1,京东接受预定,8月08日至08月16日发货https://item.jd.com/53669213250.html当当网 http://product.dangdan ...
- CCF认证历年试题
CCF认证历年试题 不加索引整理会死星人orz 第一题: CCF201712-1 最小差值(100分) CCF201709-1 打酱油(100分) CCF201703-1 分蛋糕(100分) CCF2 ...
- SQL-W3School-高级:SQL IN 操作符
ylbtech-SQL-W3School-高级:SQL IN 操作符 1.返回顶部 1. IN 操作符 IN 操作符允许我们在 WHERE 子句中规定多个值. SQL IN 语法 SELECT col ...
- BitmapDrawable
对Bitmap的一种封装,可以设置它包装的bitmap在BitmapDrawable区域中的绘制方式,有: 平铺填充,拉伸填或保持图片原始大小!以<bitmap>为根节点! 可选属性如下: ...
- HTML文档的组成和标签的规范
Html文档的组成 (1): <html></html>来明确html文档的范围 (2): <head></head>标签可以设置一个内容比如: < ...
- EasyUI入门配置
EasyUI是一款基于jQuery的前端插件,简化了开发,免去编写复杂的js和css即可实现不错的显示效果. 基本配置: index.html <!DOCTYPE html> <ht ...