Hadoop学习(2)-java客户端操作hdfs及secondarynode作用
首先要在windows下解压一个windows版本的hadoop
然后在配置他的环境变量,同时要把hadoop的share目录下的hadoop下的相关jar包拷贝到esclipe
然后Build Path
下面上代码
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.Arrays; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.junit.Before;
import org.junit.Test; public class HdfsClientDemo { public static void main(String[] args) throws Exception {
/**
* Configuration参数对象的机制:
* 构造时,会加载jar包中的默认配置 xx-default.xml
* 再加载 用户配置xx-site.xml ,覆盖掉默认参数
* 构造完成之后,还可以conf.set("p","v"),会再次覆盖用户配置文件中的参数值
*/
// new Configuration()会从项目的classpath中加载core-default.xml hdfs-default.xml core-site.xml hdfs-site.xml等文件
Configuration conf = new Configuration(); // 指定本客户端上传文件到hdfs时需要保存的副本数为:2
conf.set("dfs.replication", "2");
// 指定本客户端上传文件到hdfs时切块的规格大小:64M
conf.set("dfs.blocksize", "64m"); // 构造一个访问指定HDFS系统的客户端对象: 参数1:——HDFS系统的URI,参数2:——客户端要特别指定的参数,参数3:客户端的身份(用户名)
FileSystem fs = FileSystem.get(new URI("hdfs://172.31.2.38:9000/"), conf, "root"); // 上传一个文件到HDFS中
fs.copyFromLocalFile(new Path("D:/install-pkgs/hbase-1.2.1-bin.tar.gz"), new Path("/aaa/")); fs.close();
} FileSystem fs = null; @Before
public void init() throws Exception{
Configuration conf = new Configuration();
conf.set("dfs.replication", "2");
conf.set("dfs.blocksize", "64m"); fs = FileSystem.get(new URI("hdfs://172.31.2.38:9000/"), conf, "root"); } /**
* 从HDFS中下载文件到客户端本地磁盘
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void testGet() throws IllegalArgumentException, IOException{ fs.copyToLocalFile(new Path("/test"), new Path("d:/"));
fs.close(); } /**
* 在hdfs内部移动文件\修改名称
*/
@Test
public void testRename() throws Exception{ fs.rename(new Path("/install.log"), new Path("/aaa/in.log")); fs.close(); } /**
* 在hdfs中创建文件夹
*/
@Test
public void testMkdir() throws Exception{ fs.mkdirs(new Path("/xx/yy/zz")); fs.close();
} /**
* 在hdfs中删除文件或文件夹
*/
@Test
public void testRm() throws Exception{ fs.delete(new Path("/aaa"), true); fs.close();
} /**
* 查询hdfs指定目录下的文件信息
*/
@Test
public void testLs() throws Exception{
// 只查询文件的信息,不返回文件夹的信息
RemoteIterator<LocatedFileStatus> iter = fs.listFiles(new Path("/"), true); while(iter.hasNext()){
LocatedFileStatus status = iter.next();
System.out.println("文件全路径:"+status.getPath());
System.out.println("块大小:"+status.getBlockSize());
System.out.println("文件长度:"+status.getLen());
System.out.println("副本数量:"+status.getReplication());
System.out.println("块信息:"+Arrays.toString(status.getBlockLocations())); System.out.println("--------------------------------");
}
fs.close();
} /**
* 读取hdfs中的文件的内容
*
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void testReadData() throws IllegalArgumentException, IOException { FSDataInputStream in = fs.open(new Path("/test.txt")); BufferedReader br = new BufferedReader(new InputStreamReader(in, "utf-8")); String line = null;
while ((line = br.readLine()) != null) {
System.out.println(line);
} br.close();
in.close();
fs.close(); } /**
* 读取hdfs中文件的指定偏移量范围的内容
*
*
*
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void testRandomReadData() throws IllegalArgumentException, IOException { FSDataInputStream in = fs.open(new Path("/xx.dat")); // 将读取的起始位置进行指定
in.seek(12); // 读16个字节
byte[] buf = new byte[16];
in.read(buf); System.out.println(new String(buf)); in.close();
fs.close(); } /**
* 往hdfs中的文件写内容
*
* @throws IOException
* @throws IllegalArgumentException
*/ @Test
public void testWriteData() throws IllegalArgumentException, IOException { FSDataOutputStream out = fs.create(new Path("/zz.jpg"), false); // D:\images\006l0mbogy1fhehjb6ikoj30ku0ku76b.jpg FileInputStream in = new FileInputStream("D:/images/006l0mbogy1fhehjb6ikoj30ku0ku76b.jpg"); byte[] buf = new byte[1024];
int read = 0;
while ((read = in.read(buf)) != -1) {
out.write(buf,0,read);
} in.close();
out.close();
fs.close(); } }
练习:从一个文件里面不断地采集日志上传到hdfs里面
1.流程介绍
---启动一个定时任务
--定时探测日志原目录
--获取文件上传到一个待上传的临时目录
--逐一上传到hdfs目标路径,同时移动到备份目录里
--启动一个定时任务:
--探测备份目录中的备份数据是否已经超出,如果超出就删除
主类为:
import java.util.Timer;
public class DataCollectMain {
public static void main(String[] args) {
Timer timer = new Timer();
//第一个为task类,第二个开始时间 第三个没隔多久执行一次
timer.schedule(new CollectTask(), 0, 60*60*1000L);
timer.schedule(new BackupCleanTask(), 0, 60*60*1000L);
}
}
CollectTask类:
这个类要继承TimerTask,重写run方法,主要内容就是不断收集日志文件
package cn.edu360.hdfs.datacollect; import java.io.File;
import java.io.FilenameFilter;
import java.net.URI;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
import java.util.Properties;
import java.util.TimerTask;
import java.util.UUID; import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.log4j.Logger; public class CollectTask extends TimerTask { @Override
public void run() {
try {
// 获取配置参数
Properties props = PropertyHolderLazy.getProps(); // 获取本次采集时的日期
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd-HH");
String day = sdf.format(new Date()); File srcDir = new File("d:/logs/accesslog");
// 列出日志源目录中需要采集的文件
//里面传了一个文件过滤器,重写accept方法,return true就要
File[] listFiles = srcDir.listFiles(new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
if (name.startsWith("access.log")) {
return true;
}
return false;
}
});
// 将要采集的文件移动到待上传临时目录
File toUploadDir = new File("d:/logs/toupload");
for (File file : listFiles) { //这里如果是 file.renameTo(toUploadDir)是不对的,因为会生成一个toupload的文件而不是文件夹
//要用renameTo的话你要自己加上文件的新名字比较麻烦
//用FileUtiles是对file操作的一些工具类
//第一个目标文件,第二个路径,第三个是否存在覆盖
FileUtils.moveFileToDirectory(file, toUploadDir, true);
} // 构造一个HDFS的客户端对象
FileSystem fs = FileSystem.get(new URI("hdfs://hdp-01:9000"), new Configuration(), "root"); File[] toUploadFiles = toUploadDir.listFiles(); // 检查HDFS中的日期目录是否存在,如果不存在,则创建
Path hdfsDestPath = new Path("/logs" + day);
if (!fs.exists(hdfsDestPath)) {
fs.mkdirs(hdfsDestPath);
} // 检查本地的备份目录是否存在,如果不存在,则创建
File backupDir = new File("d:/logs/backup" + day + "/");
if (!backupDir.exists()) {
backupDir.mkdirs();
} for (File file : toUploadFiles) {
// 传输文件到HDFS并改名access_log_
fs.copyFromLocalFile(new Path(file.getAbsolutePath()), new Path("/logs"+day+"/access_log_"+UUID.randomUUID()+".log")); // 将传输完成的文件移动到备份目录
//注意这里依然不要用renameTo
FileUtils.moveFileToDirectory(file, backupDir, true);
} } catch (Exception e) {
e.printStackTrace();
} }
/**
* 读取hdfs中的文件的内容
*
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void testReadData() throws IllegalArgumentException, IOException { FSDataInputStream in = fs.open(new Path("/test.txt")); BufferedReader br = new BufferedReader(new InputStreamReader(in, "utf-8")); String line = null;
while ((line = br.readLine()) != null) {
System.out.println(line);
} br.close();
in.close();
fs.close(); } /**
* 读取hdfs中文件的指定偏移量范围的内容
*
*
* 作业题:用本例中的知识,实现读取一个文本文件中的指定BLOCK块中的所有数据
*
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void testRandomReadData() throws IllegalArgumentException, IOException { FSDataInputStream in = fs.open(new Path("/xx.dat")); // 将读取的起始位置进行指定
in.seek(12); // 读16个字节
byte[] buf = new byte[16];
in.read(buf); System.out.println(new String(buf)); in.close();
fs.close(); } /**
* 往hdfs中的文件写内容
*
* @throws IOException
* @throws IllegalArgumentException
*/ @Test
public void testWriteData() throws IllegalArgumentException, IOException { FSDataOutputStream out = fs.create(new Path("/zz.jpg"), false); // D:\images\006l0mbogy1fhehjb6ikoj30ku0ku76b.jpg FileInputStream in = new FileInputStream("D:/images/006l0mbogy1fhehjb6ikoj30ku0ku76b.jpg"); byte[] buf = new byte[1024];
int read = 0;
while ((read = in.read(buf)) != -1) {
out.write(buf,0,read);
} in.close();
out.close();
fs.close(); }
}
BackupCleanTask类
package cn.edu360.hdfs.datacollect; import java.io.File;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.TimerTask; import org.apache.commons.io.FileUtils; public class BackupCleanTask extends TimerTask { @Override
public void run() { SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd-HH");
long now = new Date().getTime();
try {
// 探测本地备份目录
File backupBaseDir = new File("d:/logs/backup/");
File[] dayBackDir = backupBaseDir.listFiles(); // 判断备份日期子目录是否已超24小时
for (File dir : dayBackDir) {
long time = sdf.parse(dir.getName()).getTime();
if(now-time>24*60*60*1000L){
FileUtils.deleteDirectory(dir);
}
}
} catch (Exception e) {
e.printStackTrace();
} } }
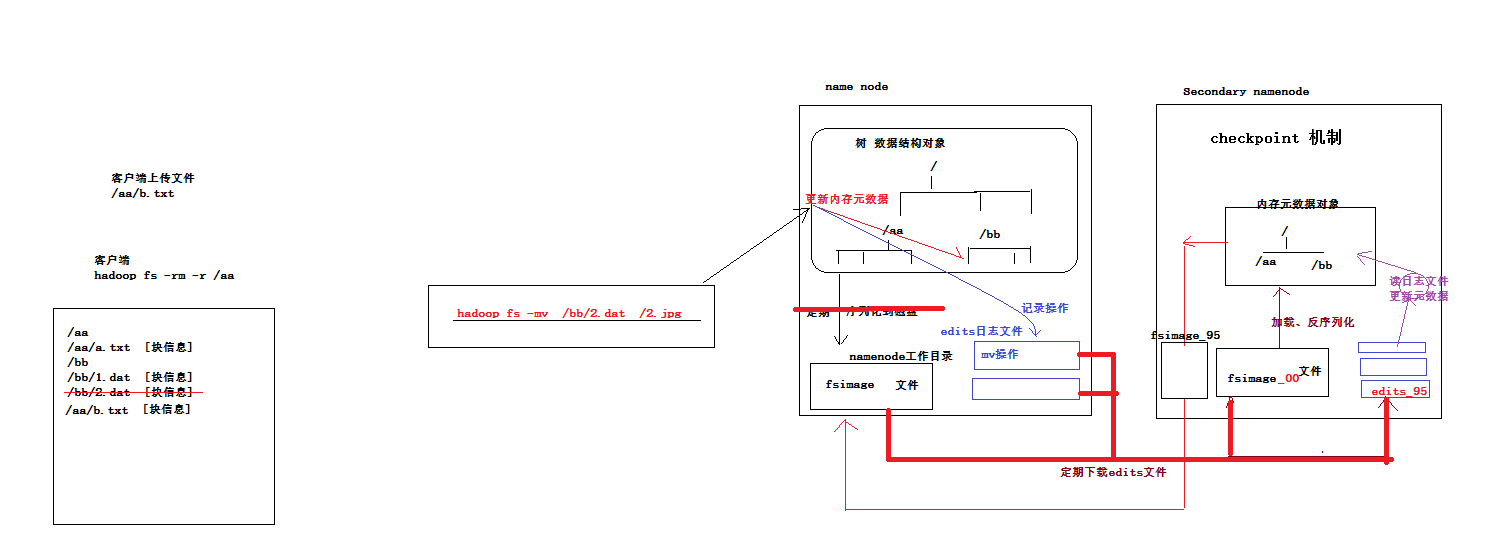
hdfs中namenode中储存元数据(对数据的描述信息)是在内存中以树的形式储存的,并且每隔一段时间都会把这些元数据序列化到磁盘中。序列化的东西在磁盘中叫 fsimage文件。
元数据可能会很大很大,所以只能是定期的序列化
问题1:序列化的时候,发生了元数据的修改怎么办
答:namenode会把每次用户的操作都记录下来,记录成日志文件,存在edits日志文件中
其中edits日志文件也会像log4j滚动日志文件一样,当文件太大的时候会另起一个文件并改名字
问题2:当edits文件太多的时候,一次宕机也会花大量的时间从edits里恢复,怎么办
答:会定期吧edits文件重放fsimage文件,并记录edits的编号,把那些重放过的日志文件给删除。这样也相当于重新序列化了,
所以namenode并不会做这样的事情,是由secondary node做的,他会定期吧namenode的fsimage文件和edits文件下载下来
并把fsimage文件反序列化,并且读日志文件更新元数据,然后序列化到磁盘,然后把他上传给namenode。
这个机制叫做checkpoint机制
这里secondarynode 相当一一个小秘书
客户端写数据到hdfs的流程
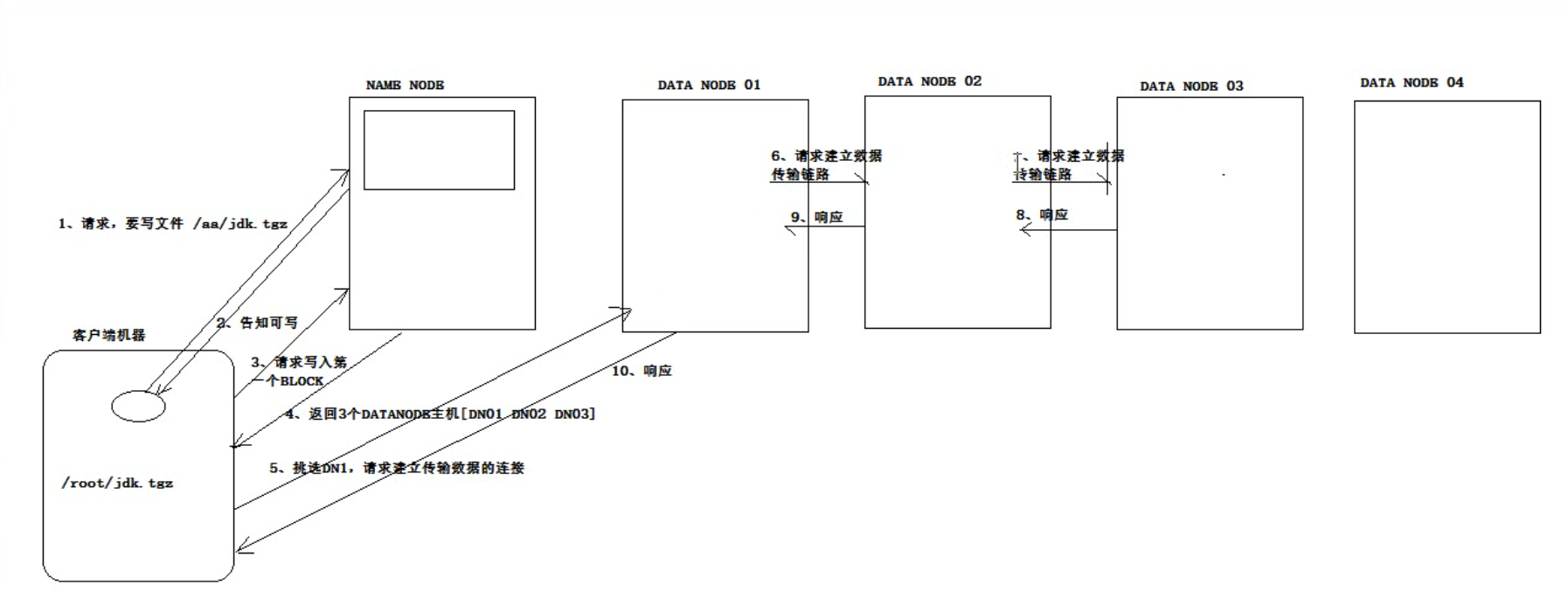
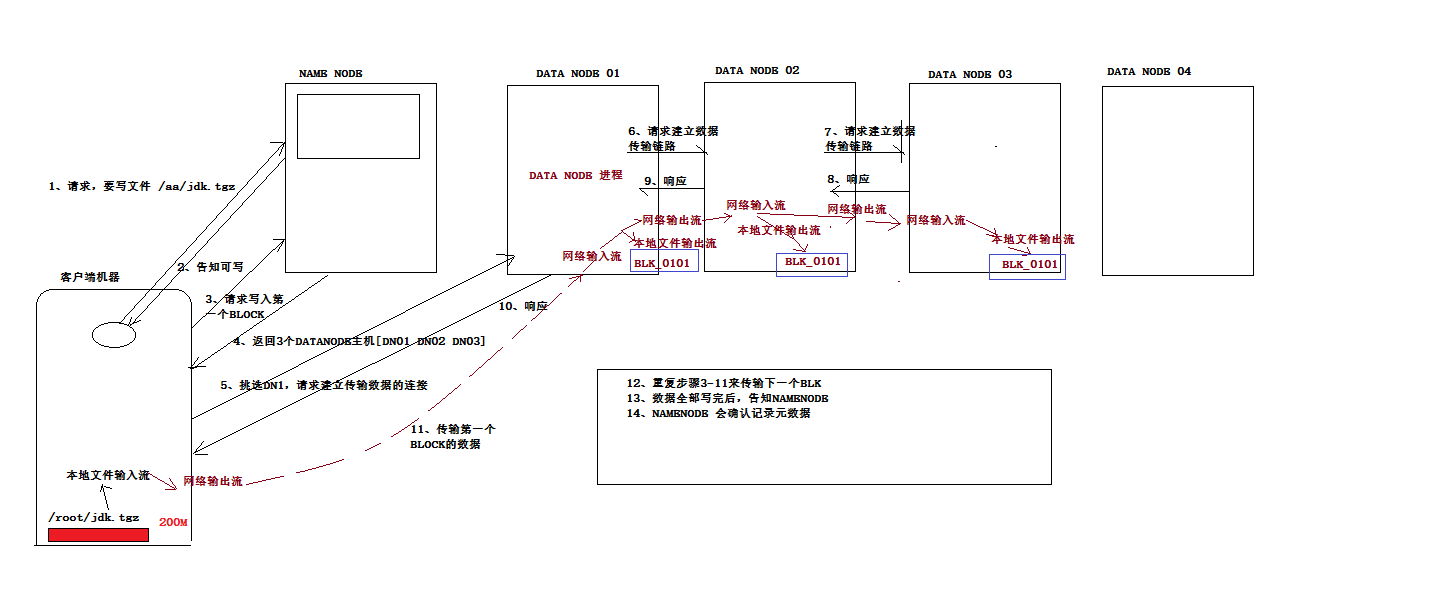
上面是建立响应的过程
然后 是传递文件block块的过程
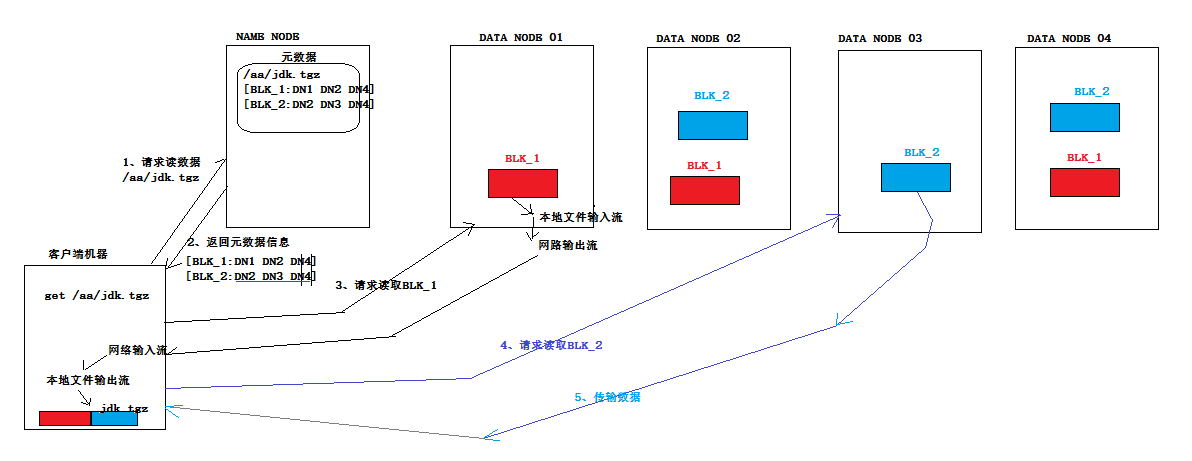
客户端从hdfs读数据流程
额外知识点
注意,在windows里面不要写有些路径不要写绝对路径,因为程序放到linux下面可能会找不到,因此报错
一般使用class加载器,这样当这个class加载的时候就会知道这个class在哪
类加载器的一些使用例子
比如我加载一个配置文件,为了避免出现绝对路径,我们可以是用类加载器
Properties props = new Properties();
//加载配置文件,这样写的目的是为了避免在windows里出现绝对路径,用类加载器,再把文件传化成流
props.load(HdfsWordcount.class.getClassLoader().getResourceAsStream("job.properties"));
而对于一些功能性的类,我们最好在写逻辑的时候也不要直接去导入这个包,而是使用Class.forName
//这样不直接导入这个包,直接用类加载器,是面向接口编程的一种思想。这里我并不是在开始import xxxx.Mapper,这里Mapper是一个接口,这里我用了多态
Class<?> mapper_class = Class.forName(props.getProperty("MAPPER_CLASS"));
Mapper mapper = (Mapper) mapper_class.newInstance();
单例模式
https://www.cnblogs.com/crazy-wang-android/p/9054771.html
只有个一实例,必须自己创建自己这个实例,必须为别人提供这个实例
饿汉式单例:就算没有人调用这个class,他也会加载进去;
如对于一个配置文件的加载
import java.util.Properties; /**
* 单例设计模式,方式一: 饿汉式单例
*
*/
public class PropertyHolderHungery { private static Properties prop = new Properties(); static {
try {
//将一个文件prop.load(stram)
//这里面如果传一个IO流不好,因为要用到绝对路径,使用了类加载器 这种不管有没有使用这个类都会加载
prop.load(PropertyHolderHungery.class.getClassLoader().getResourceAsStream("collect.properties"));
} catch (Exception e) { }
}
public static Properties getProps() throws Exception {
return prop;
} }
懒汉式:只有调用的时候才会有,但会有线程安全问题
/**
* 单例模式:懒汉式——考虑了线程安全
* */ public class PropertyHolderLazy { private static Properties prop = null; public static Properties getProps() throws Exception {
if (prop == null) {
synchronized (PropertyHolderLazy.class) {
if (prop == null) {
prop = new Properties();
prop.load(PropertyHolderLazy.class.getClassLoader().getResourceAsStream("collect.properties"));
}
}
}
return prop;
} }
Hadoop学习(2)-java客户端操作hdfs及secondarynode作用的更多相关文章
- 大数据之路week07--day01(HDFS学习,Java代码操作HDFS,将HDFS文件内容存入到Mysql)
一.HDFS概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 ...
- HDFS的Java客户端操作代码(HDFS的查看、创建)
1.HDFS的put上传文件操作的java代码: package Hdfs; import java.io.FileInputStream; import java.io.FileNotFoundEx ...
- Hadoop Java API操作HDFS文件系统(Mac)
1.下载Hadoop的压缩包 tar.gz https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/ 2.关联jar包 在 ...
- day03-hdfs的客户端操作\hdfs的java客户端编程
5.hdfs的客户端操作 客户端的理解 hdfs的客户端有多种形式: 1.网页形式 2.命令行形式 3.客户端在哪里运行,没有约束,只要运行客户端的机器能够跟hdfs集群联网 文件的切块大小和存储的副 ...
- Hive学习(三)Hive的Java客户端操作
Hive的Java客户端操作分为JDBC和Thrifit Client,首先启动Hive远程服务: hive --service hiveserver 一.JDBC 在MyEclipse中首先创建连接 ...
- 使用Java API操作HDFS文件系统
使用Junit封装HFDS import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org ...
- Java代码操作HDFS测试类
1.Java代码操作HDFS需要用到Jar包和Java类 Jar包: hadoop-common-2.6.0.jar和hadoop-hdfs-2.6.0.jar Java类: java.net.URL ...
- Hadoop基础-通过IO流操作HDFS
Hadoop基础-通过IO流操作HDFS 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.上传文件 /* @author :yinzhengjie Blog:http://www ...
- 使用Java客户端操作elasticsearch(二)
承接上文,使用Java客户端操作elasticsearch,本文主要介绍 常见的配置 和Sniffer(集群探测) 的使用. 常见的配置 前面已介绍过,RestClientBuilder支持同时提供一 ...
随机推荐
- 百度ueditor中复制word图文时图片转存任然保持灰色不可用
官网地址http://ueditor.baidu.com Git 地址 https://github.com/fex-team/ueditor 参考博客地址 http://blog.ncmem.com ...
- (WA)BZOJ 4821: [Sdoi2017]相关分析
二次联通门 : BZOJ 4821: [Sdoi2017]相关分析 2017.8.23 Updata 妈妈!!这道题卡我!!!就是不然我过!!!!! #include <cstdio> # ...
- 【概率论】3-7:多变量分布(Multivariate Distributions Part I)
title: [概率论]3-7:多变量分布(Multivariate Distributions Part I) categories: Mathematic Probability keywords ...
- 一步一步配置AWS ELB Https证书
第一步:生成CSR 要配置证书,我们首先需要创建一个CSR来向证书提供商申请证书.这个过程我们可以通过IIS中的工具来生成. 然后需要填写如下信息: 下一步后选择文件名后我们就可以创建出CSR 文件了 ...
- python 获取远程设备ip地址
python2.7 #!/usr/bin/env python # Python Network Programming Cookbook -- Chapter - # This program is ...
- IDEA版本控制工具VCS中使用Git,以及快捷键总结(不使用命令)
场景介绍: 工作中多人使用版本控制软件协作开发,常见的应用场景归纳如下: 假设小组中有两个人,组长小张,组员小袁 场景一:小张创建项目并提交到远程Git仓库 场景二:小袁从远程Git仓库上获取项目源码 ...
- KVM——以桥接的方式搭建虚拟机网络配置
以桥接的方式搭建虚拟机网络,其优势是可以将网络中的虚拟机看作是与主机同等地位的服务器. 在原本的局域网中有两台主机,一台是win7(IP: 192.168.0.236),一台是CentOS7(IP: ...
- Go 代码审查建议
https://github.com/golang/go/wiki/CodeReviewComments https://studygolang.com/articles/6054
- mac下iterm配色、半透明与样式设置
mac下iterm配色.半透明与样式设置 * {display: table-row!important} .MJXp-surd {vertical-align: top} .MJXp-surd &g ...
- 在arm上执行某个程序时总是提示 not found是怎么回事?
答: 使用ldd查看程序是否缺少库,如果缺少库,那么就从交叉编译工具链中获取并复制到arm的根文件系统中