基于Python使用scrapy-redis框架实现分布式爬虫
1.首先介绍一下:scrapy-redis框架
scrapy-redis:一个三方的基于redis的分布式爬虫框架,配合scrapy使用,让爬虫具有了分布式爬取的功能。github地址: https://github.com/darkrho/scrapy-redis ,
mongodb 、mysql 或其他数据库:针对不同类型数据可以根据具体需求来选择不同的数据库存储。结构化数据可以使用mysql节省空间,非结构化、文本等数据可以采用mongodb等非关系型数据提高访问速度。具体选择可以自行百度谷歌,有很多关于sql和nosql的对比文章。
2.介绍一下分布式原理:
scrapy-redis实现分布式,其实从原理上来说很简单,这里为描述方便,我们把自己的核心服务器称为master,而把用于跑爬虫程序的机器称为slave。
我们知 道,采用scrapy框架抓取网页,我们需要首先给定它一些start_urls,爬虫首先访问start_urls里面的url,再根据我们的具体逻辑,对里面的元素、或者是其他的二级、三级页面进行抓取。而要实现分布式,我们只需要在这个starts_urls里面做文章就行了。
我们在master上搭建一个redis数据库(注意这个数据库只用作url的存储,不关心爬取的具体数据,不要和后面的mongodb或者mysql混淆),并对每一个需要爬取的网站类型,都开辟一个单独的列表字段。通过设置slave上scrapy-redis获取url的地址为master地址。这样的结果就是,尽管有多个slave,然而大家获取url的地方只有一个,那就是服务器master上的redis数据库。
并且,由于scrapy-redis自身的队列机制,slave获取的链接不会相互冲突。这样各个slave在完成抓取任务之后,再把获取的结果汇总到服务器上(这时的数据存储不再在是redis,而是mongodb或者 mysql等存放具体内容的数据库了)
这种方法的还有好处就是程序移植性强,只要处理好路径问题,把slave上的程序移植到另一台机器上运行,基本上就是复制粘贴的事情。
3.分布式爬虫的实现:
1.使用两台机器,一台是win10,一台是centos7(详情请看http://www.111cn.net/sys/CentOS/63645.htm),分别在两台机器上部署scrapy来进行分布式抓取一个网站
2.centos7的ip地址为192.168.1.112,用来作为redis的master端,win10的机器作为slave
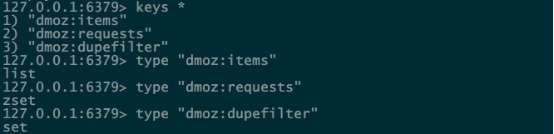
3.master的爬虫运行时会把提取到的url封装成request放到redis中的数据库:“dmoz:requests”,并且从该数据库中提取request后下载网页,再把网页的内容存放到redis的另一个数据库中“dmoz:items”
4.slave从master的redis中取出待抓取的request,下载完网页之后就把网页的内容发送回master的redis
5.重复上面的3和4,直到master的redis中的“dmoz:requests”数据库为空,再把master的redis中的“dmoz:items”数据库写入到mongodb中
6.master里的reids还有一个数据“dmoz:dupefilter”是用来存储抓取过的url的指纹(使用哈希函数将url运算后的结果),是防止重复抓取的
4.scrapy-redis框架的安装:
安装redis(http://blog.fens.me/linux-redis-install/)
windows安装redis
下载地址:https://github.com/rgl/redis/downloads
选择最新版和你电脑的对应版本下载安装
安装完成后,
运行redis服务器的命令:安装目录下的redis-server.exe
运行redis客户端的命令:安装目录下的redis-cli.exe
centos7安装redis
直接运行命令:yum install redis -y即可,安装完成后默认启动redis服务器
安装完成后,redis默认是不能被远程连接的,此时要修改配置文件/etc/redis.conf
#注释bind #bind 127.0.0.1
修改后,重启redis服务器
systemctl restart redis
在centos7环境下启动redis服务器的命令:systemctl start redis,启动客户端的命令:redis-cli
如果要增加redis的访问密码,修改配置文件/etc/redis.conf
#取消注释requirepass requirepass redisredis # redisredis就是密码(记得自己修改)
增加了密码后,启动客户端的命令变为:redis-cli -a redisredis
测试是否能远程登陆
使用windows的命令窗口进入redis安装目录,用命令进行远程连接centos7的redis:
redis-cli -h 192.168.1.112 -p 6379

在本机上测试是否能读取master的redis

在远程机器上读取是否有该数据

可以确信redis安装完成
安装部署scrapy-redis
安装scrapy-redis命令(https://github.com/rolando/scrapy-redis)
pip install scrapy-redis
部署scrapy-redis:
slave端:在windows上的settings.py文件的最后增加如下一行
REDIS_URL = 'redis://192.168.1.112:6379'
master端:在centos7上的settings.py文件的最后增加如下两行
REDIS_HOST = 'localhost' REDIS_PORT = 6379
在windows中配置好了远程的redis地址后启动两个爬虫(启动爬虫没有顺序限制),此时在windows上查看redis,可以看到windows上运行的爬虫的确是从远程的reids里获取request的(因为本地的redis没有东西)

由此确认好了scrapy-redis安装配置完成
使用redis-dump将redis的数据导出来查看(可选)
在centos7上安装redis-dump (https://github.com/delano/redis-dump)
yum -y install gcc ruby-devel rubygems compass gem
修改rvm安装源(http://genepeng.com/index.php/346)

gem sources --remove https://rubygems.org/ gem sources -a https://ruby.taobao.org/ gem sources -l gem install redis-dump -y
运行了example里的dmoz之后,连接redis,查看到生成了以下的三个数据库,并且每个value对应的类型如下
在centos7上使用redis-dump命令(redis-dump -u 127.0.0.1:6379 > db_full.json)导出该数据库,再查看存储到的数据(在这里我只提取了每个数据库的前几条)
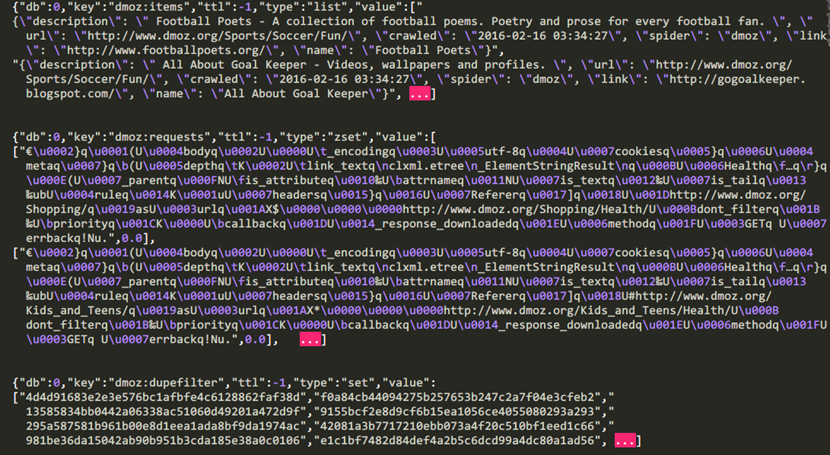
下图就是上面数据库“dmoz:items”里所爬取的内容
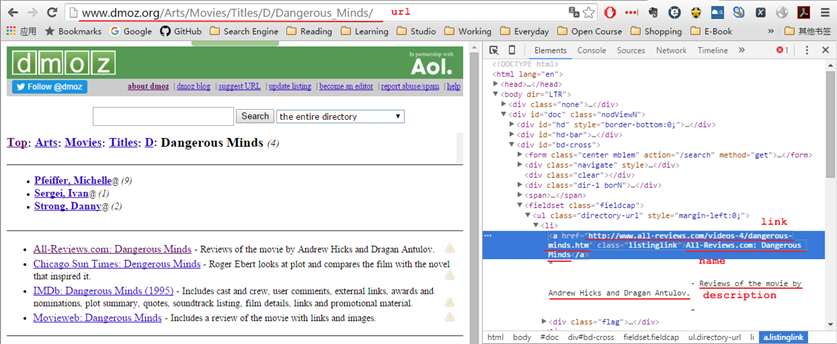
将爬取到的数据导入到mongodb中
等到爬虫结束后,此时运行process_items.py来把位于master的redis中的“dmoz:items”逐一读取到json中,所以如果要把item存储到mongodb中,就应该修改process_items.py文件,如下
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import json
import redis
import pymongo
def main():
# r = redis.Redis()
r = redis.Redis(host='192.168.1.112',port=6379,db=0)
client = pymongo.MongoClient(host='localhost', port=27017)
db = client['dmoz']
sheet = db['sheet']
while True:
# process queue as FIFO, change `blpop` to `brpop` to process as LIFO
source, data = r.blpop(["dmoz:items"])
item = json.loads(data)
sheet.insert(item)
try:
print u"Processing: %(name)s <%(link)s>" % item
except KeyError:
print u"Error procesing: %r" % item
if __name__ == '__main__':
main()
其实可以在爬虫一边运行的时候,一边运行process_items.py文件
基于Python使用scrapy-redis框架实现分布式爬虫的更多相关文章
- 基于redis的简易分布式爬虫框架
代码地址如下:http://www.demodashi.com/demo/13338.html 开发环境 Python 3.6 Requests Redis 3.2.100 Pycharm(非必需,但 ...
- 基于scrapy框架的分布式爬虫
分布式 概念:可以使用多台电脑组件一个分布式机群,让其执行同一组程序,对同一组网络资源进行联合爬取. 原生的scrapy是无法实现分布式 调度器无法被共享 管道无法被共享 基于 scrapy+redi ...
- Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~ 首先介绍一下这个标题吧~ 1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待 ...
- 基于Python项目的Redis缓存消耗内存数据简单分析(附详细操作步骤)
目录 1 准备工作 2 具体实施 1 准备工作 什么是Redis? Redis:一个高性能的key-value数据库.支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使 ...
- Appium基于Python unittest自动化测试 & 自动化测试框架 -- PO并生成html测试报告
基于python单元测试框架unittest完成appium自动化测试,生成基于html可视化测试报告 代码示例: #利用unittest并生成测试报告 class Appium_test(unitt ...
- 符号执行-基于python的二进制分析框架angr
转载:All Right 符号执行概述 在学习这个框架之前首先要知道符号执行.符号执行技术使用符号值代替数字值执行程序,得到的变量的值是由输入变 量的符号值和常量组成的表达式.符号执行技术首先由Kin ...
- ShutIt:一个基于 Python 的 shell 自动化框架
ShutIt是一个易于使用的基于shell的自动化框架.它对基于python的expect库(pexpect)进行了包装.你可以把它看作是“没有痛点的expect”.它可以通过pip进行安装. Hel ...
- Python 用Redis简单实现分布式爬虫
Redis通常被认为是一种持久化的存储器关键字-值型存储,可以用于几台机子之间的数据共享平台. 连接数据库 注意:假设现有几台在同一局域网内的机器分别为Master和几个Slaver Master连接 ...
- python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
之前我们的爬虫都是单机爬取,也是单机维护REQUEST队列, 看一下单机的流程图: 一台主机控制一个队列,现在我要把它放在多机执行,会产生一个事情就是做重复的爬取,毫无意义,所以分布式爬虫的第一个难点 ...
随机推荐
- 【JAVA各版本特性】JAVA 1.0 - JAVA 12
make JDK Version 1.01996-01-23 Oak(橡树) 初代版本,伟大的一个里程碑,但是是纯解释运行,使用外挂JIT,性能比较差,运行速度慢. JDK Version 1.119 ...
- 使用python下载图片(福利)
刚学python 没多久, 代码处处是漏洞,也希望各位大佬理解一下 爬出来的图片... 使用的 是 https://www.tianapi.com/ 接口下的 美女图片... (需要自己注册一个账号 ...
- web开发:形变、表格及多行文本操作
一.2d形变 二.动画 三.表格 四.多个文本垂直居中 五.小米形变案例 一.2d形变 /*1.形变参考点: 三轴交界点*/transform-origin: x轴坐标 y轴坐标; /*2.旋转 ro ...
- Codeforces Round #588 (Div. 1) C. Konrad and Company Evaluation
直接建反边暴力 复杂度分析见https://blog.csdn.net/Izumi_Hanako/article/details/101267502 #include<bits/stdc++.h ...
- TCP/IP协议簇 端口 三次握手 四次挥手 11种状态集
第一章:概念介绍 1.1 VLAN 1.1.1 什么是VLAN VLAN (Virturl LAN) ,翻译成中文是:“虚拟局域网”.VLAN可以是由少数几台家用计算机构成的网络,也可以是数以百计的计 ...
- CSS3 -- column 实现瀑布流布局
本例使用 CSS column 实现瀑布流布局 关键点,column-count: 元素内容将被划分的最佳列数 关键点,break-inside: 避免在元素内部插入分页符 html div.g-co ...
- VSS使用技巧
理由很简单:迁出锁定!之所以强调这个,是因为这方面吃过的亏太多,我举几个例子:1.比如两个程序员增加了同一个功能,但是实现方法不同,比如甲:func1,乙 func2,两者代码也不一样第二个人在迁入代 ...
- numba初体验
numba初体验 今天在知乎上发现了一个很神奇的包numba,可以用jit的方式大幅提高计算型python代码的效率,一起来看一下 安装 numba的安装方式很简单,使用pip或者anacoda都可以 ...
- SQL Server孤立用戶
如何解决孤立用户问题 http://blog.csdn.net/zzl1120/article/details/7394468 SQL SERVER孤立用户问题解决方法 http://www.2cto ...
- atom Editor文本自动选择问题
问题:如图中,我光标最初在42行,向上滑动鼠标,会自动选中42到所滑动行之间的文本 ,一般编辑器 都是要按shift 然后滑动鼠标 才有这个效果 解决方法: 是由于atom安装了atom-termin ...