06_Hive分桶机制及其作用
1.Clustered By
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。
Hive也是针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在
哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体
而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的
实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同
列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一
小部分数据上试运行查询,会带来很多方便。
2.分桶
分桶是相对分区进行更细粒度的划分,它是相当于MapReduce中的分区,分桶将整个数据按照某列属性值的hash
值进行区分,例如如果根据id属性分为3个桶,就是对id属性值的hash值对3取摸,按照取模结果对数据分桶。如取
模结果为0的数据记录存放到一个文件,取模为1的数据存放到一个文件,取模为2的数据存放到一个文件
1.创建带桶的表:导入的数据已经是被分好桶和排好序的

在分桶之前要执行命令:set hive.enforce.bucketing = true; set mapreduce.job.reduces=4;从而设置分桶
为true,并且reduce数量是分桶的数量个数;
关键字clustered by 指定分区依据的列名;
与分区不同的是,分区依据的不是真实数据表文件中的列,而是我们指定的伪列,但是分桶是依据数据表中真实
的列而不是伪列。所以在指定分区依据的列的时候要指定列的类型,因为在数据表文件中不存在这个列,相当于新建
一个列。而分桶依据的是表中已经存在的列,这个列的数据类型显然是已知的,所以不需要指定列的类型
如上只是说明了表会分桶,具体的分区需要在插入数据时产生。最好的插入数据方式是insert into table;
2.带桶的表中插入select数据(Cluster by(id)):表示根据id分桶并排序
cluster by和sort by不能放在一起查询

按照上面的分桶结果会在表目录下产生多个文件:/user/hive/warehouse/test_db/t_buk/
查看文件信息:
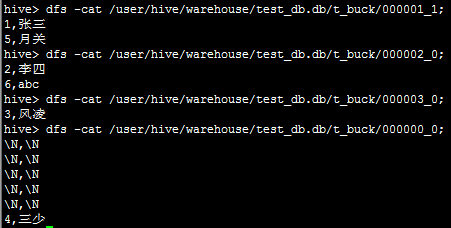
3.带桶的表中插入select数据(distribute by (id) sort by (id)):

按照上面的分桶结果会在表目录下产生多个文件:/user/hive/warehouse/test_db/t_buk/
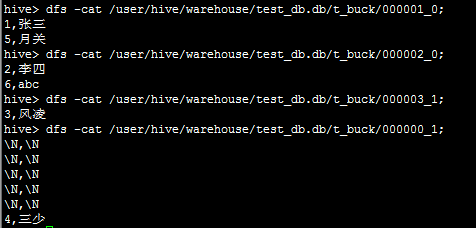
如上的的sql查询语句实际上是根据id作为key进行key.hashcode%4产生四个区,即就是用distribute by (id)
来指定分区字段,使用sort by (id)指定排序字段
总结:
因此,如果分桶和sort字段是同一个时,此时,cluster by = distribute by + sort by
如果将reduce数量设置为4,使用select * from t_test order by name;就会强制将reduce设置为1,会得到全局结果;
SELECT语法操作:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY| ORDER BY col_list]
]
[LIMIT number] 注:1、order by 会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
2、sort by不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1,
则sort by只保证每个reducer的输出有序,不保证全局有序。
3、distribute by(字段)根据指定的字段将数据分到不同的reducer,且分发算法是hash散列。
4、Cluster by(字段) 除了具有Distribute by的功能外,还会对该字段进行排序。 因此,如果分桶和sort字段是同一个时,此时,cluster by = distribute by + sort by 分桶表的作用:最大的作用是用来提高join操作的效率;
(思考这个问题:select a.id,a.name,b.addr from a join b on a.id = b.id;
如果a表和b表已经是分桶表,而且分桶的字段是id字段,那么做这个操作的时候就不需要再进行全表笛卡尔积了。但是如果标注了分桶但是实际上数据并没有分桶,那么结果就会出问题。
06_Hive分桶机制及其作用的更多相关文章
- Hive为什么要分桶
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分.Hive也是针对某一列进行桶的组织.Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记 ...
- Hive学习笔记——Hive中的分桶
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分.Hive也是针对某一列进行桶的组织.Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记 ...
- HIVE—索引、分区和分桶的区别
一.索引 简介 Hive支持索引,但是Hive的索引与关系型数据库中的索引并不相同,比如,Hive不支持主键或者外键. Hive索引可以建立在表中的某些列上,以提升一些操作的效率,例如减少MapRed ...
- Hive里的分区、分桶、视图和索引再谈
福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- Hive(六)【分区表、分桶表】
目录 一.分区表 1.本质 2.创建分区表 3.加载数据到分区表 4.查看分区 5.增加分区 6.删除分区 7.二级分区 8.分区表和元数据对应得三种方式 9.动态分区 二.分桶表 1.创建分桶表 2 ...
- hive从入门到放弃(四)——分区与分桶
今天讲讲分区表和分桶表,前面的文章还没看的可以点击链接: hive从入门到放弃(一)--初识hive hive从入门到放弃(二)--DDL数据定义 hive从入门到放弃(三)--DML数据操作 分区 ...
- Hive 的分桶 & Parquet 概念
分区 & 分桶 都是把数据划分成块.分区是粗粒度的划分,桶是细粒度的划分,这样做为了可以让查询发生在小范围的数据上以提高效率. 分区之后,分区列都成了文件目录,从而查询时定位到文件目录,子数据 ...
- linux_shell_根据网站来源分桶
应用场景: 3kw行url+\t+html记录 [网站混合] 需要:按照网站来源分桶输出 执行shell cat */*pack.html|awk -F '\t' '{ split($1,arr,&q ...
- Hive分桶
1.简介 分桶表是对列值取哈希值的方式将不同数据放到不同文件中进行存储.对于hive中每一个表,分区都可以进一步进行分桶.由列的哈希值除以桶的个数来决定数据划分到哪个桶里. 2.适用场景 1.数据抽样 ...
随机推荐
- iOS- 推送消息
1 ios 如何判断是点击推送信息进入还是点击app图标进入程序? 设备接到apns发来的通知,应用处理通知有以下几种情况: 1. 应用还没有加载 这时如果点击通知的显示按钮,会调用didFinish ...
- 《精通并发与Netty》学习笔记(12 - 详解NIO (三) SocketChannel、Pipe)
一.SocketChannelJava NIO中的SocketChannel是一个连接到TCP网络套接字的通道.可以通过以下2种方式创建SocketChannel: 打开一个SocketChannel ...
- SQL注入(字符型)
靶场:sqli-labs @SQLi最重要的一点:别上来就对着输入框注入,完整语句写出来,始终在语句中写完整的,最后把完整的一部分截取出来作为输入 @URL编码:为避免歧义,URL中,如 %2b ...
- NDK学习笔记-JNI的引用
JNI中的引用意在告知虚拟机何时回收一个JNI变量 JNI引用变量分为局部引用和全局引用 局部引用 局部引用,通过DeletLocalRef手动释放对象 原因 访问一个很大的Java对象,使用之后还用 ...
- POJ 3613 Cow Relays【k边最短路】
题目链接:http://poj.org/problem?id=3613 题目大意: 给出n头牛,t条有向边,起点以及终点,限制每头牛放在一个点上,(一个点上可以放多头牛),从起点开始进行接力跑到终点, ...
- hdoj3586 (树形dp)
题目链接:https://vjudge.net/problem/HDU-3586 题意:一棵边权树,要删掉一些边使得每个叶子结点不能到达树根,且这些边的权值<=上限Max,且边权和小于m,求最小 ...
- [转帖]centos7上设置中文字符集
centos7上设置中文字符集 https://www.cnblogs.com/kaishirenshi/p/10528034.html author: headsen chen date: 201 ...
- oracle——学习之路(select检索)
select语法: select [distinct|all] 列名 from 表名 [where] [group by] [having] [order ...
- LeetCode. 矩阵中的最长递增路径
题目要求: 给定一个整数矩阵,找出最长递增路径的长度. 对于每个单元格,你可以往上,下,左,右四个方向移动. 你不能在对角线方向上移动或移动到边界外(即不允许环绕). 示例: 输入: nums = [ ...
- 数据结构与算法之排序算法(python实现)
1.冒泡排序 冒泡排序的原理是依次比较相邻的两个数,如果前一个数比后一个数大则交换位置,这样一组比较下来会得到该组最大的那个数,并且已经放置在最后,下一轮用同样的方法可以得到次大的数,并且被放置在正确 ...