Pandas中DataFrame数据合并、连接(concat、merge、join)之concat
一、concat:沿着一条轴,将多个对象堆叠到一起
concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False, copy=True):
objs:需要连接的对象集合,一般是列表或字典;
axis:连接轴向;
join:参数为‘outer’或‘inner’;
join_axes=[]:指定自定义的索引;
keys=[]:创建层次化索引;
ignore_index=True:重建索引
pd.concat()只是单纯的把两个表拼接在一起,参数axis是关键,它用于指定是行还是列,axis默认是0。
当axis=0时,pd.concat([obj1, obj2])的效果与obj1.append(obj2)是相同的;
当axis=1时,pd.concat([obj1, obj2], axis=1)的效果与pd.merge(obj1, obj2, left_index=True, right_index=True, how='outer')是相同的。merge方法的介绍请参看下文。
import pandas as pd
import numpy as np
random = np.random.RandomState(0) #随机数种子,相同种子下每次运行生成的随机数相同
df1=pd.DataFrame(random.randn(3,4),columns=['a','b','c','d'])
df1
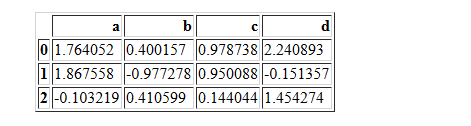
random = np.random.RandomState(0)
df2=pd.DataFrame(random.randn(2,3),columns=['b','d','a'],index=["a1","a2"])
df2

random = np.random.RandomState(1)
df22=pd.DataFrame(random.randn(3,3),columns=['b','d','a'],index=['',"a1","a2"])
df22

当axis=0时
pd.concat([df1,df2],axis=0)
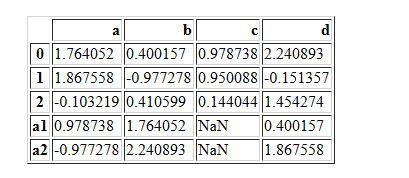
pd.concat([df1,df2],axis=0,join="outer")

df12=df1.append(df2)
df12

pd.concat([df1,df2],axis=0,join="inner")

当axis=1时
pd.concat([df1,df2],axis=1,join='inner')

pd.concat([df1,df1],axis=1,join='inner') #和outer一样
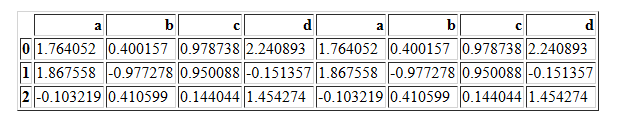
pd.concat([df1,df2],axis=1,join="outer")
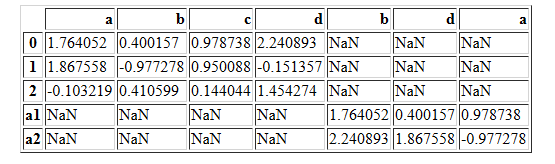
pd.concat([df1,df22],axis=1,join="inner")

pd.concat([df1,df22],axis=1,join="outer")

pd.concat([df1,df1],axis=1,join="outer")

Pandas中DataFrame数据合并、连接(concat、merge、join)之concat的更多相关文章
- Pandas中DataFrame数据合并、连接(concat、merge、join)之merge
二.merge:通过键拼接列 类似于关系型数据库的连接方式,可以根据一个或多个键将不同的DatFrame连接起来. 该函数的典型应用场景是,针对同一个主键存在两张不同字段的表,根据主键整合到一张表里面 ...
- Pandas中DataFrame数据合并、连接(concat、merge、join)之join
pandas.DataFrame.join 自己弄了很久,一看官网.感觉自己宛如智障.不要脸了,直接抄 DataFrame.join(other, on=None, how='left', lsuff ...
- 排序合并连接(sort merge join)的原理
排序合并连接(sort merge join)的原理 排序合并连接(sort merge join)的原理 排序合并连接(sort merge join) 访问次数:两张表都只会访 ...
- Python基础 | pandas中dataframe的整合与形变(merge & reshape)
目录 行的union pd.concat df.append 列的join pd.concat pd.merge df.join 行列转置 pivot stack & unstack melt ...
- Spark与Pandas中DataFrame对比
Pandas Spark 工作方式 单机single machine tool,没有并行机制parallelism不支持Hadoop,处理大量数据有瓶颈 分布式并行计算框架,内建并行机制paral ...
- Spark与Pandas中DataFrame对比(详细)
Pandas Spark 工作方式 单机single machine tool,没有并行机制parallelism不支持Hadoop,处理大量数据有瓶颈 分布式并行计算框架,内建并行机制paral ...
- 将pandas的DataFrame数据写入MySQL数据库 + sqlalchemy
将pandas的DataFrame数据写入MySQL数据库 + sqlalchemy import pandas as pd from sqlalchemy import create_engine ...
- Python3 Pandas的DataFrame数据的增、删、改、查
Python3 Pandas的DataFrame数据的增.删.改.查 一.DataFrame数据准备 增.删.改.查的方法有很多很多种,这里只展示出常用的几种. 参数inplace默认为False,只 ...
- Pandas中DataFrame修改列名
Pandas中DataFrame修改列名:使用 rename df = pd.read_csv('I:/Papers/consumer/codeandpaper/TmallData/result01- ...
随机推荐
- poco编译与运行
1.引言 Poco C++库是: 一系列C++类库,类似Java类库,.Net框架,Apple的Cocoa; 侧重于互联网时代的网络应用程序 使用高效的,现代的标准ANSI/ISO C++,并基于ST ...
- arm-linux的gdb移植
转载于:http://blog.chinaunix.net/uid-23381466-id-309369.html arm-linux的gdb移植分为两种情况.一种是交叉调试版.这一种模式是需要编译一 ...
- 【LOJ】#3119. 「CTS2019 | CTSC2019」随机立方体
题解 用容斥,算至少K个极大值的方案数 我们先钦定每一维的K个数出来,然后再算上排列顺序是 \(w_{k} = \binom{n}{k}\binom{m}{k}\binom{l}{k}(k!)^3\) ...
- LC 752 Open the Lock
由于这个问题,涉及了很多知识,例如数据结构里面的哈希表,c++中的迭代器,因此,需要对于每一个疑惑逐一击破. 问题描述 You have a lock in front of you with 4 c ...
- Web前端开发JavaScript提高
JavaScript 一种直译式脚本语言,是一种动态类型.弱类型.基于原型的语言,内置支持类型,它的解释器被称为JavaScript引擎,是浏览器的一部分,并且是被广泛用于客户端的脚本语言,JavaS ...
- 7.bash作业控制
7.作业控制本节讨论作业控制是什么.它怎么工作.以及 Bash 里面怎么使用这些功能7.1 作业控制基础作业控制是指有选择的停止(暂停)并在后来继续(恢复)执行某个进程的能力.通常,用户通过 Bash ...
- Scala学习三——数组相关操作
一.若长度固定则使用Array,若长度可能有变化则使用ArrayBuffer 固定长度数组: 如val nums=new Array[Int](10) //10个整型数组,所有元素初始化为0; val ...
- 【原创】大叔经验分享(56)hue导出行数限制
/opt/cloudera/parcels/CDH/lib/hue/apps/beeswax/src/beeswax/conf.py # Deprecated DOWNLOAD_CELL_LIMIT ...
- JDBC:JAVA & Oracle
JDBC:JAVA & Oracle 本文中未加标注的资源均来自于PolyU数据库课程的实验材料.仅作为学习使用,如有侵权,请联系删除 JDBC是什么 我之前写过一篇关于数据库和JAVA的博文 ...
- luogu P4428 [BJOI2018]二进制
luogu 先考虑怎样的二进制串才会被3整除.可以发现如果二进制位第\(0,2,4...2n\)位如果为\(1\),那么在模3意义下为1,如果二进制位第\(1,3,5...2n+1\)位如果为\(1\ ...