java虚拟机的基本结构如图
1 java虚拟机的基本结构如图:
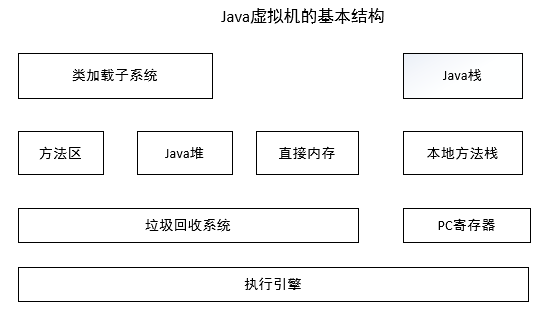
1)类加载子系统负责从文件系统或者网络中加载Class信息,加载的类信息存放于一块称为方法区的内存空间。除了类的信息外,方法区中可能还会存放运行时常量池信息,包括字符串字面量和数字常量(这部分常量信息是Class文件中常量池部分的内存映射)。
2)java堆在虚拟机启动的时候建立,它是java程序最主要的内存工作区域。几乎所有的java对象实例都存放在java堆中。堆空间是所有线程共享的,这是一块与java应用密切相关的内存空间。
3)java的NIO库允许java程序使用直接内存。直接内存是在java堆外的、直接向系统申请的内存空间。通常访问直接内存的速度会优于java堆。因此出于性能的考虑,读写频繁的场合可能会考虑使用直接内存。由于直接内存在java堆外,因此它的大小不会直接受限于Xmx指定的最大堆大小,但是系统内存是有限的,java堆和直接内存的总和依然受限于操作系统能给出的最大内存。
4)垃圾回收系统是java虚拟机的重要组成部分,垃圾回收器可以对方法区、java堆和直接内存进行回收。其中,java堆是垃圾收集器的工作重点。和C/C++不同,java中所有的对象空间释放都是隐式的,也就是说,java中没有类似free()或者delete()这样的函数释放指定的内存区域。对于不再使用的垃圾对象,垃圾回收系统会在后台默默工作,默默查找、标识并释放垃圾对象,完成包括java堆、方法区和直接内存中的全自动化管理。
5)每一个java虚拟机线程都有一个私有的java栈,一个线程的java栈在线程创建的时候被创建,java栈中保存着帧信息,java栈中保存着局部变量、方法参数,同时和java方法的调用、返回密切相关。
6)本地方法栈和java栈非常类似,最大的不同在于java栈用于方法的调用,而本地方法栈则用于本地方法的调用,作为对java虚拟机的重要扩展,java虚拟机允许java直接调用本地方法(通常使用C编写)
7)PC(Program Counter)寄存器也是每一个线程私有的空间,java虚拟机会为每一个java线程创建PC寄存器。在任意时刻,一个java线程总是在执行一个方法,这个正在被执行的方法称为当前方法。如果当前方法不是本地方法,PC寄存器就会指向当前正在被执行的指令。如果当前方法是本地方法,那么PC寄存器的值就是undefined
8)执行引擎是java虚拟机的最核心组件之一,它负责执行虚拟机的字节码,现代虚拟机为了提高执行效率,会使用即时编译技术将方法编译成机器码后再执行。
2 java堆
java堆是和应用程序关系最为密切的内存空间,几乎所有的对象都存放在堆上。并且java堆是完全自动化管理的,通过垃圾回收机制,垃圾对象会被自动清理,而不需要显示的释放。
根据java回收机制的不同,java堆有可能拥有不同的结构。最为常见的一种构成是将整个java堆分为新生代和老年代。其中新生代存放新生对象或者年龄不大的对象,老年代则存放老年对象。新生代有可能分为eden区、s0区、s1区,s0区和s1区也被称为from和to区,他们是两块大小相同、可以互换角色的内存空间。
如下图:显示了一个堆空间的一般结构:
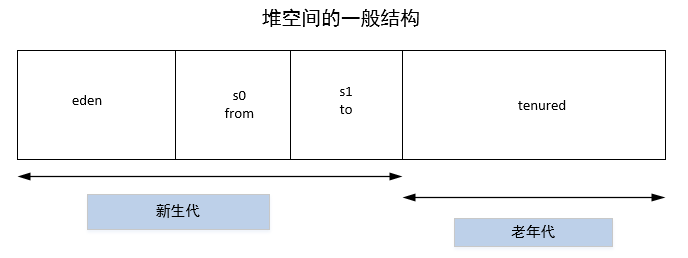
在绝大多数情况下,对象首先分配在eden区,在一次新生代回收之后,如果对象还存活,则进入s0或者s1,每经过一次新生代回收,对象如果存活,它的年龄就会加1。当对象的年龄达到一定条件后,就会被认为是老年对象,从而进入老年代。其具体的垃圾回收算法在后面会介绍。
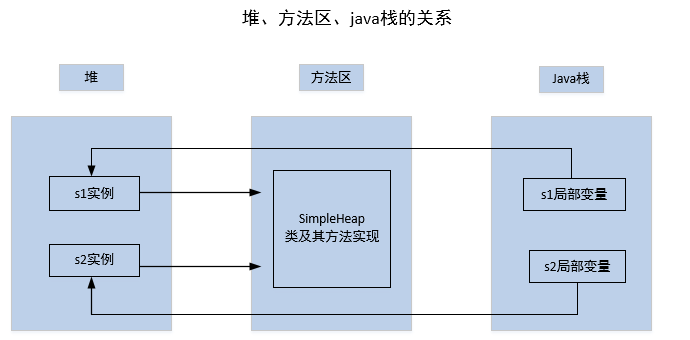
例1 :通过简单的示例,展示java堆、方法区和java栈之间的关系
package com.jvm;
public class SimpleHeap {
private int id;
public SimpleHeap(int id){
this.id = id;
}
public void show(){
System.out.println("My id is "+id);
}
public static void main(String[] args) {
SimpleHeap s1 = new SimpleHeap(1);
SimpleHeap s2 = new SimpleHeap(2);
s1.show();
s2.show();
}
}
该代码声明了一个类,并在main函数中创建了两个SimpleHeap实例。此时,各对象和局部变量的存放情况如图:
SimpleHeap实例本身分配在堆中,描述SimpleHeap类的信息存放在方法区,main函数中的s1 s2局部变量存放在java栈上,并指向堆中两个实例。
3 java栈
java栈是一块线程私有的内存空间。如果说,java堆和程序数据密切相关,那么java栈就是和线程执行密切相关。线程执行的基本行为是函数调用,每次函数调用的数据都是通过java栈传递的。
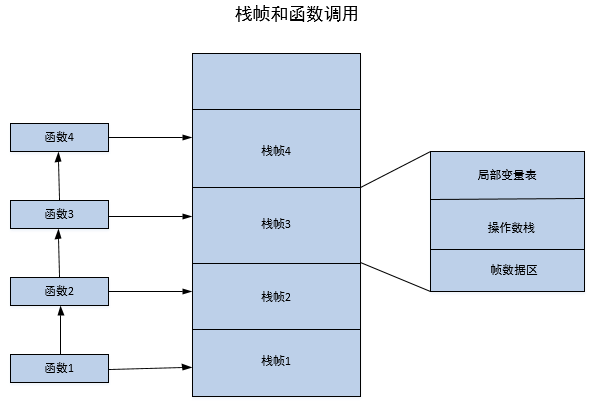
java栈与数据结构上的栈有着类似的含义,它是一块先进后出的数据结构,只支持出栈和进栈两种操作,在java栈中保存的主要内容为栈帧。每一次函数调用,都会有一个对应的栈帧被压入java栈,每一个函数调用结束,都会有一个栈帧被弹出java栈。如下图:栈帧和函数调用。函数1对应栈帧1,函数2对应栈帧2,依次类推。函数1中调用函数2,函数2中调用函数3,函数3调用函数4.当函数1被调用时,栈帧1入栈,当函数2调用时,栈帧2入栈,当函数3被调用时,栈帧3入栈,当函数4被调用时,栈帧4入栈。当前正在执行的函数所对应的帧就是当前帧(位于栈顶),它保存着当前函数的局部变量、中间计算结果等数据。
当函数返回时,栈帧从java栈中被弹出,java方法区有两种返回函数的方式,一种是正常的函数返回,使用return指令,另一种是抛出异常。不管使用哪种方式,都会导致栈帧被弹出。
在一个栈帧中,至少包含局部变量表、操作数栈和帧数据区几个部分。
提示:由于每次函数调用都会产生对应的栈帧,从而占用一定的栈空间,因此,如果栈空间不足,那么函数调用自然无法继续进行下去。当请求的栈深度大于最大可用栈深度时,系统会抛出StackOverflowError栈溢出错误。
例2 使用递归,由于递归没有出口,这段代码可能会抛出栈溢出错误,在抛出栈溢出错误时,打印最大的调用深度
package com.jvm;
public class TestStackDeep {
private static int count =0;
public static void recursion(){
count ++;
recursion();
}
public static void main(String[] args) {
try{
recursion();
}catch(Throwable e){
System.out.println("deep of calling ="+count);
e.printStackTrace();
}
}
}
使用参数-Xss128K执行上面代码(在eclipse中右键选择Run As-->run Configurations....设置Vm arguments),部分结果如图:

可以看出,在进行大约1079次调用之后,发生了栈溢出错误,通过增大-Xss的值,可以获得更深的层次调用,尝试使用参数-Xss256K执行上述代码,可能产生如下输出,很明显,调用层次有明显的增加:

注意:函数嵌套调用的层次在很大程度上由栈的大小决定,栈越大,函数支持的嵌套调用次数就越多。
3.1 栈帧组成之局部变量表
局部变量表是栈帧的重要组成部分之一。它用于保存函数的参数以及局部变量,局部变量表中的变量只在当前函数调用中有效,当函数调用结束,随着函数栈帧的弹出销毁,局部变量表也会随之销毁。
由于局部变量表在栈帧之中,因此,如果函数的参数和局部变量很多,会使得局部变量表膨胀,从而每一次函数调用就会占用更多的栈空间,最终导致函数的嵌套调用次数减少。
示例3:一个recursion函数含有3个参数和10个局部变量,因此,其局部变量表含有13个变量,而第二个recursion函数不再含有任何参数和局部变量,当这两个函数被嵌套调用时,第二个recursion函数可以拥有更深的调用层次。
package com.jvm;
public class TestStackDeep2 {
private static int count = 0;
public static void recursion(long a,long b,long c){
long e=1,f=2,g=3,h=4,i=5,k=6,q=7,x=8,y=9,z=10;
count ++;
recursion(a,b,c);
}
public static void recursion(){
count++;
recursion();
}
public static void main(String[] args) {
try{
recursion(0L,0L,0L);
//recursion();
}catch(Throwable e){
System.out.println("deep of calling = "+count);
e.printStackTrace();
}
}
}
使用参数-Xss128K执行上述代码中的第一个带参recursion(long a,long b,long c)函数,输出结果为:

使用虚拟机参数-Xss128K执行上述代码中第二个不带参数的recursion()函数(当然需要把第一个函数注释掉),输出结果为:

可以看出,在相同的栈容量下,局部变量少的函数可以支持更深的函数调用。
使用jclasslib工具可以查看函数的局部变量表,如下图:最大局部变量表大小
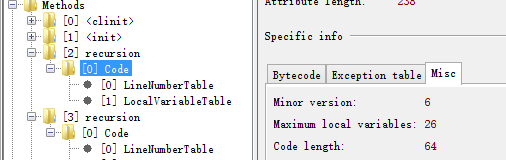
该图显示了第一个带参recursion(long a,long b,long c)的最大局部变量表的大小为26个字,因为该函数包含总共13个参数和局部变量,且都为long型,long和double在局部变量表中需要占用2个字,其他如int short byte 对象引用等占用一个字。
说明:字(word)指的是计算机内存中占据一个单独的内存单元编号的一组二进制串,一般32位计算机上一个字为4个字节长度。
通过jclasslib工具查看该类的Class文件中局部变量表的内容,(这里说的局部变量表和上述说的局部变量表不同,这里指Class文件的一个属性,而上述的局部变量表指java栈空间的一部分)

可以看到,在Class文件的局部变量表中,显示了每个局部变量的作用域范围、所在槽位的索引(index列)、变量名(name列)和数据类型(J表示long型)
栈帧中局部变量表中的槽位是可以重用的,如果一个局部变量过了其作用域,那么在其作用域之后申明的新的局部变量就很有可能会复用过期局部变量的槽位,从而达到节省资源的目的。
示例4 :显示局部变量表的复用,在localvar1函数中,局部变量a和b都作用到了函数的末尾,故b无法复用a所在的位置。而在localvar2()函数中,局部变量a在第?行不再有效,故局部变量b可以复用a的槽位(1个字)
package com.jvm;
public class TestReuse {
public static void localvar1(){
int a=0;
System.out.println(a);
int b=0;
}
public static void localvar2(){
{
int a=0;
System.out.println(a);
}
int b=0;
}
}
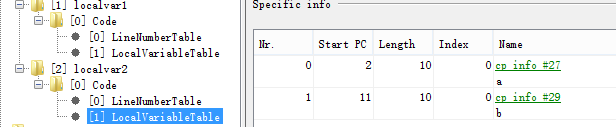
如图显示localvar1()函数的局部变量表,该函数局部变量大小为2个字,(最大局部变量表中一般第一个局部变量槽位是this引用)第一个槽位是变量a,第二个槽位是变量b,每个变量占一个字。

而localvar2()函数的局部变量表信息如下图,虽然和localvar1()一样,但是b复用了a的槽位,(从他们都占用同一个槽位index都是0可以看出),因此在整个函数执行中,同时存在的局部变量为1字。
局部变量表中的变量也是垃圾回收根节点,只要被局部变量表中直接或者间接引用的对象都是不会被回收的。
示例5:通过一个简单示例,展示局部变量对垃圾回收的影响
package com.jvm;
public class LocalvarGC {
public void localvarGc1(){
byte[] a = new byte[6*1024*1024];//6M
System.gc();
}
public void localvarGc2(){
byte[] a = new byte[6*1024*1024];
a = null;
System.gc();
}
public void localvarGc3(){
{
byte[] a = new byte[6*1024*1024];
}
System.gc();
}
public void localvarGc4(){
{
byte[] a = new byte[6*1024*1024];
}
int c = 10;
System.gc();
}
public void localvarGc5(){
localvarGc1();
System.gc();
}
public static void main(String[] args) {
LocalvarGC ins = new LocalvarGC();
ins.localvarGc1();
}
}
每一个localvarGcN()函数都分配了一块6M的堆内存,并使用局部变量引用这块空间。
在localvarGc1()中,在申请空间后,立即进行垃圾回收,很明显由于byte数组被变量a引用,因此无法回收这块空间。
在localvarGc2()中,在垃圾回收前,先将变量a置为null,使得byte数组失去强引用,故垃圾回收可以顺利回收byte数组。
在localvarGc3()中,在进行垃圾回收前,先使局部变量a失效,虽然变量a已经离开了作用域,但是变量a依然存在于局部变量表中,并且也指向这块byte数组,故byte数组依然无法被回收。
对于localvarGc4(),在垃圾回收之前,不仅使变量a失效,更是声明了变量c,使变量c复用了变量a的字,由于变量a此时被销毁,故垃圾回收器可以顺利回收数组byte
对于localvarGc5(),它首先调用了localvarGc1(),很明显,在localvarGc1()中并没有释放byte数组,但在localvarGc1()返回后,它的栈帧被销毁,自然也包含了栈帧中的所有局部变量,故byte数组失去了引用,在localvarGc5()的垃圾回收中被回收。
可以使用-XX:+printGC执行上述几个函数,在输出日志里,可以看到垃圾回收前后堆的大小,进而推断出byte数组是否被回收。
下面的输出是函数localvarGc4()的运行结果:
[GC (System.gc()) 7618K->624K(94208K), 0.0015613 secs]
[Full GC (System.gc()) 624K->526K(94208K), 0.0070718 secs]
从日志中可以看出,堆空间从回收前的7618K变为回收后的624K,释放了>6M的空间,byte数组已经被回收释放。
参考:https://www.cnblogs.com/zwbg/p/6194470.html
java虚拟机的基本结构如图的更多相关文章
- Java虚拟机的内存结构
我们都知道虚拟机的内存划分了多个区域,并不是一张大饼.那么为什么要划分为多块区域呢,直接搞一块区域,所有用到内存的地方都往这块区域里扔不就行了,岂不痛快.是的,如果不进行区域划分,扔的时候确实痛快,可 ...
- [二]Java虚拟机 jvm内存结构 运行时数据内存 class文件与jvm内存结构的映射 jvm数据类型 虚拟机栈 方法区 堆 含义
前言简介 class文件是源代码经过编译后的一种平台中立的格式 里面包含了虚拟机运行所需要的所有信息,相当于 JVM的机器语言 JVM全称是Java Virtual Machine ,既然是虚拟机, ...
- Java虚拟机——类的结构与加载
1.为什么Java可以跨平台 因为有java虚拟机,跨平台是因为字节码即class文件具有平台无关性,java代码会经过java虚拟机转换为字节码 2.class文件的结构 class文件主要是以8位 ...
- 深入理解java虚拟机---对象的结构(九)
注意: 我们可以看到的就是InstanceData的数据. 先转载一篇文章作为开头,因为讲的非常详细,我就简单加工下放到这里: 对象结构 在HotSpot虚拟机中,对象在内存中存储的布局可以分为3块区 ...
- [java] 虚拟机(JVM)底层结构详解[转]
本文来自:曹胜欢博客专栏.转载请注明出处:http://blog.csdn.net/csh624366188 在以前的博客里面,我们介绍了在java领域中大部分的知识点,从最基础的java最基本语法到 ...
- Java 虚拟机的内存结构
Java虚拟机运行时数据区 整个程序执行过程中,JVM会用一段空间来存储程序执行期间需要用到的数据和相关信息,这段空间一般被称作为Runtime Data Area(运行时数据区),也就是我们常说的J ...
- JVM虚拟机(一):java虚拟机的基本结构
1: 类加载子系统(负责从文件系统或者网络中加载class信息,加载的类信息存放于一块成为方法区的内存空间.除了类信息外,方法区中可能还存放运行时常量池信息,包括字符串字面量和数字常量(这部分常量信息 ...
- 《深入理解java虚拟机》-目录结构
第一部分 走进Java第1章 走进Java 第二部分 自动内存管理机制 第2章 Java内存区域与内存溢出异常2.1 概述2.2 运行时数据区域2.2.1 程序计数器2.2.2 java虚拟机栈2.2 ...
- 深入理解Java虚拟机—JVM内存结构
1.概述 jvm内存分为线程共享区和线程独占区,线程独占区主要包括虚拟机栈.本地方法栈.程序计数器:线程共享区包括堆和方法区 2.线程独占区 虚拟机栈 虚拟机栈描述的是java方法执行的动态内存模型, ...
随机推荐
- SpringCloud学习(三)服务消费者(Feign)(Finchley版本)
上一篇文章,讲述了如何通过RestTemplate+Ribbon去消费服务,这篇文章主要讲述如何通过Feign去消费服务. Feign简介 Feign是一个声明式的伪Http客户端,它使得写Http客 ...
- 常用小功能js函数-函数防抖
函数防抖:在事件被触发n秒后再执行回调,如果在这n秒内又被触发,则重新计时.这个我经常用到/** * 函数防抖 * fun 需要延时执行的函数 * delayTime 延时时间 * **/export ...
- poj3714 Raid(分治求平面最近点对)
题目链接:https://vjudge.net/problem/POJ-3714 题意:给定两个点集,求最短距离. 思路:在平面最近点对基础上加了个条件,我么不访用f做标记,集合1的f为1,集合2的f ...
- spy++工具
vs工具的spy++和第三方spy4win工具下载地址: https://files.cnblogs.com/files/zhangmo/spytools.rar https://files.cnbl ...
- vi操作笔记一
vi命令 gg 到首行 shift + 4 跳到该行最后一个字符 shift + 6 跳到该行首个字符 shift + g 到尾行 vi 可视 G 全选 = 程序对齐 gg 到首行 vi 可视 ...
- Linux安装redis logstash
一.安装redis tar -zxvf redis-3.2.8.tar.gz cd redis-3.2.8 make && make install PREFIX=/usr/loca ...
- Linux 下使用 rar 进行压缩和解压缩
1. 下载安装文件 https://www.rarlab.com/download.htm 注意下载 64位的 2. 2019.8 时的下载命令为: wget https://www.rarlab. ...
- SqlServer判断表中某列是否包含中文,英文,纯数字
原文:SqlServer判断表中某列是否包含中文,英文,纯数字 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog ...
- PHP以table形式导出数据表实现单元格内换行
<br style='mso-data-placement:same-cell;'>
- Codeforces 1238G. Adilbek and the Watering System
传送门 最关键的想法就是每个位置一定用的是当前能用的最便宜的水,因为到后面可能有更便宜的 然后其他还没用上的水我们也留着,假装此时已经买了,但是如果发现后面有更优的再反悔也不迟 每相邻两个朋友之间我们 ...