初试spark java WordCount
初始环境:OS X 10.10.5
准备:boot2docker
进入boot2docker后安装 docker-spark 地址: https://github.com/sequenceiq/docker-spark 里面有很详细的介绍
我启动这个镜像的命令是
- docker run -it -p 8088:8088 -p 8080:8080 -p 9000:9000 -p 50070:50070 -p 8042:8042 -p 7077:7077 -p 4040:4040 -h sandbox sequenceiq/spark bash
还没大整明白,端口映射比较多
然后进入到下面的目录里
- cd /usr/local/spark/examples/src/main/java/org/apache/spark/examples/
可以看到经典的JavaWordCount.java 的代码
我们在idea中建立一个JAVA的maven工程,只有一个依赖如下
- <dependencies>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-core_2.10</artifactId>
- <version>1.6.0</version>
- </dependency>
- </dependencies>
将上面的代码JavaWordCount代码复制出来
打包前有一个地方需要注意下,勾选红框
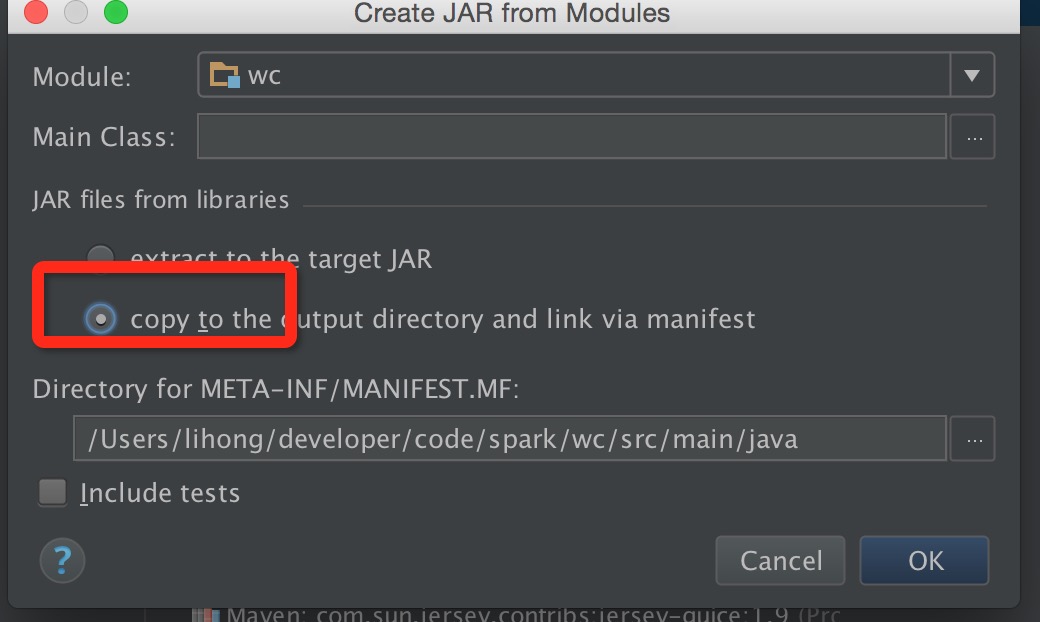
然后在out目录下把跟module同名的jar文件上传到docker-spark中
准备测试文件:
随便建一个文本文件
然后上传到hdfs中
先创建一个目录
- hdfs dfs -mkdir testdata
然后上传测试文件
- hdfs dfs -put .txt /user/root/testdata
我们使用单机Spark Standalone Mode的方式来运行
进入
- /usr/local/spark-1.6.-bin-hadoop2./sbin
启动master
- ./start-master.sh
启动slave
- ./start-slave.sh sandbox:
准备就绪,进入到上传的jar文件目录下运行
- spark-submit --master spark://sandbox:7077 --name WordCountByDH --class com.dh.WordCount --executor-memory 1G --total-executor-cores 2 wc.jar /user/root/testdata/1.txt
这样你就能看到运行的结果了

问题:再idea下运行是遇到下面这个问题,有几个内部类找不到了,还没解决:
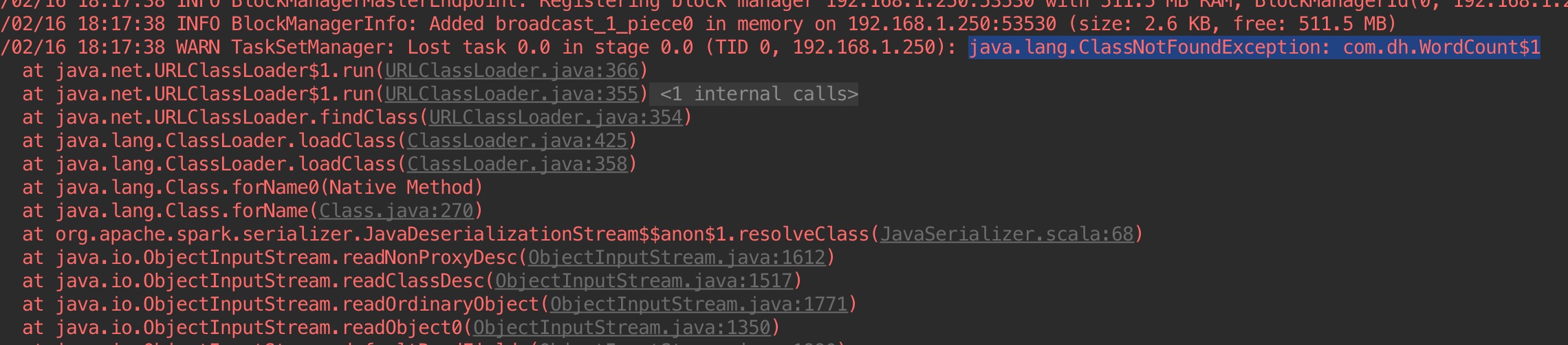
初试spark java WordCount的更多相关文章
- spark java wordCount实例
1. 算子 package com.test; import java.util.Arrays; import java.util.List; import org.apache.spark.Spar ...
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- [转] 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? [sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需 ...
- 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需要 ...
- 1.spark的wordcount解析
一.Eclipse(scala IDE)开发local和cluster (一). 配置开发环境 要在本地安装好java和scala. 由于spark1.6需要scala 2.10.X版本的.推荐 2 ...
- windows下 eclipse搭建spark java编译环境
环境: win10 jdk1.8 之前有在虚拟机或者集群上安装spark安装包的,解压到你想要放spark的本地目录下,比如我的目录就是D:\Hadoop\spark-1.6.0-bin-hadoop ...
- Spark Java API 计算 Levenshtein 距离
Spark Java API 计算 Levenshtein 距离 在上一篇文章中,完成了Spark开发环境的搭建,最终的目标是对用户昵称信息做聚类分析,找出违规的昵称.聚类分析需要一个距离,用来衡量两 ...
- Spark Java API 之 CountVectorizer
Spark Java API 之 CountVectorizer 由于在Spark中文本处理与分析的一些机器学习算法的输入并不是文本数据,而是数值型向量.因此,需要进行转换.而将文本数据转换成数值型的 ...
- spark JAVA 开发环境搭建及远程调试
spark JAVA 开发环境搭建及远程调试 以后要在项目中使用Spark 用户昵称文本做一下聚类分析,找出一些违规的昵称信息.以前折腾过Hadoop,于是看了下Spark官网的文档以及 github ...
随机推荐
- BZOJ3331压力
码量略大. 题意就是求路径必经点. tarjan缩点,所有的非割点只有是起点终点时才必经,直接开个ans数组就OK了. 至于割点,因为缩完点之后的图是vDcc和割点共同组成的,而且题目说连通,那就是棵 ...
- vue中如何刷新页面
vue中刷新页面的方法 1. 不能使用 this.$router.go(0) 或者 window.reload() 不起作用还特别恶心 这个才是有效果的刷新页面,只要照图敲,就能有效果 我们在 app ...
- yum 时一直停在Determining fastest mirrors 界面
[root@fanyk ~]# yum redis Loaded plugins: fastestmirror Determining fastest mirrors 在yum makecache时, ...
- Linux 命令速记本
# 比较1.txt和2.txt的差异 comm [---] .txt .txt # 求1.txt和2.txt的MD5用于区分两个文件是否相同 md5sum .txt .txt #tr 用于转换或删除文 ...
- vue echarts圆角阴影效果
series: [ { name: '销量', type: 'bar', data: [5, 20, 36, 10, 10, 20], itemStyle: { normal: { barBorder ...
- Linux 通道
简单地说,一个通道接受一个工具软件的输出,然后把那个输出输入到其它工具软件.使用UNIX/Linux的词汇,这个通道接受了一个过程的标准输出,并把这个标准的输出作为另一个过程的标准输入.如果你没有重新 ...
- java:面向对象(接口(续),Compareble重写,Comparator接口:比较器的重写,内部类,垃圾回收机制)
接口: *接口定义:使用interface关键字 * [修饰符] interface 接口名 [extends 父接口1,父接口2...]{ * //常量的声明 * //方法的声明 * } *接口成员 ...
- jquery中this与$(this)的用法区别
jquery中this与$(this)的用法区别.先看以下代码: $("#textbox").hover( function() { this.title = "Test ...
- 【HANA系列】【第七篇】SAP HANA XS使用Data Services查询CDS实体【一】
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列][第七篇]SAP HANA XS ...
- 【神经网络与深度学习】【C/C++】比较OpenBLAS,Intel MKL和Eigen的矩阵相乘性能
比较OpenBLAS,Intel MKL和Eigen的矩阵相乘性能 对于机器学习的很多问题来说,计算的瓶颈往往在于大规模以及频繁的矩阵运算,主要在于以下两方面: (Dense/Sparse) Matr ...