配置BeautifulSoup4+lxml+html5lib
序

Windows平台 + Python3.5
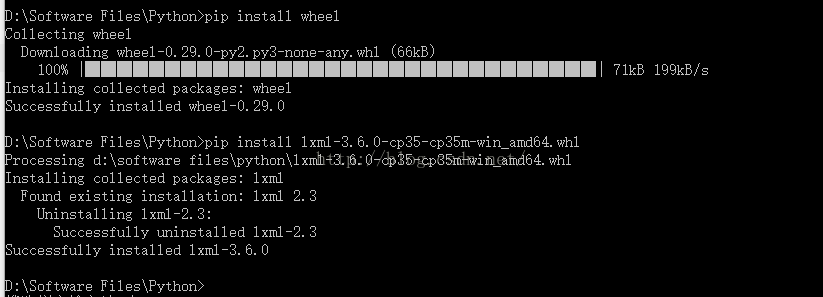
安装BeautifulSoup4

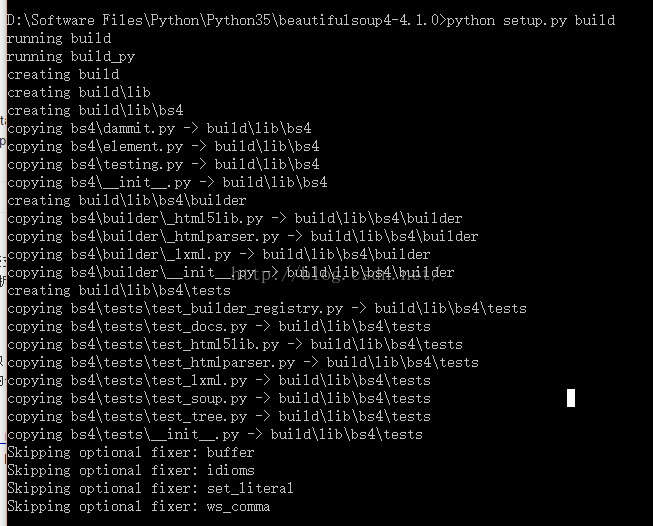
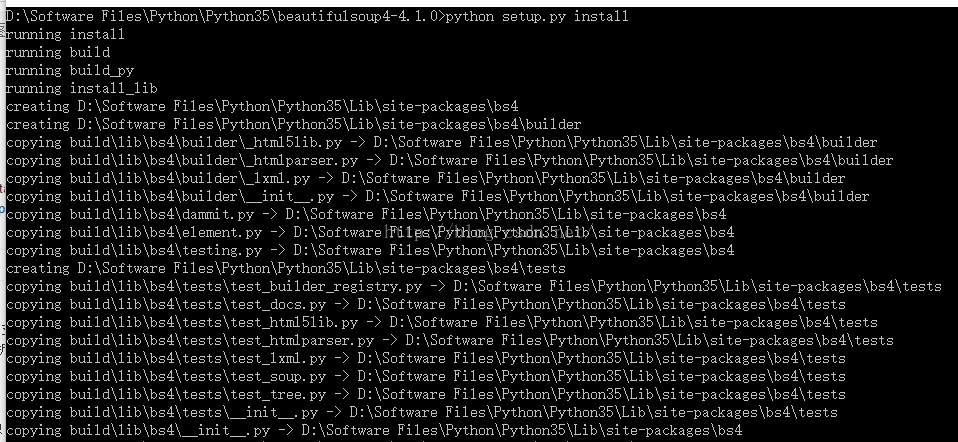
安装html5lib
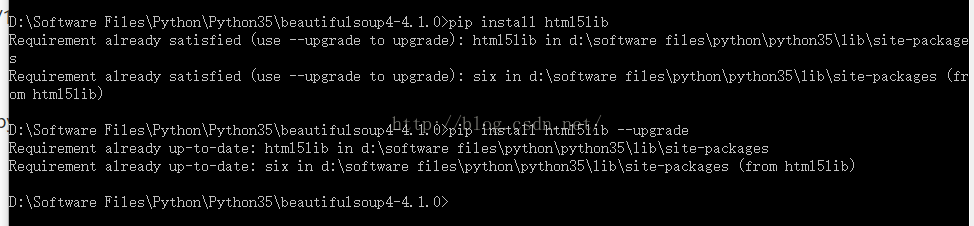
安装lxml
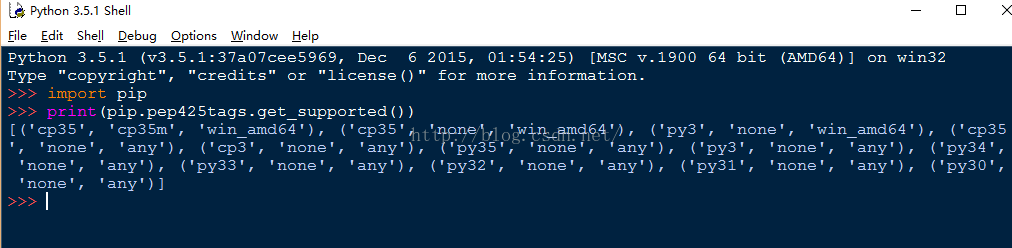
Lxml, a binding for the libxml2 and libxslt libraries.
lxml‑3.4.4‑cp27‑none‑win32.whl
lxml‑3.4.4‑cp27‑none‑win_amd64.whl
lxml‑3.4.4‑cp33‑none‑win32.whl
lxml‑3.4.4‑cp33‑none‑win_amd64.whl
lxml‑3.4.4‑cp34‑none‑win32.whl
lxml‑3.4.4‑cp34‑none‑win_amd64.whl
lxml‑3.4.4‑cp35‑none‑win32.whl
lxml‑3.4.4‑cp35‑none‑win_amd64.whl
cp后面是Python的版本号,27表示2.7,根据你的Python版本选择下载。
- pip install BeautifulSoup4 或 easy_install BeautifulSoup4
- pip install html5lib
- pip install lxml
使用BeautifulSoup
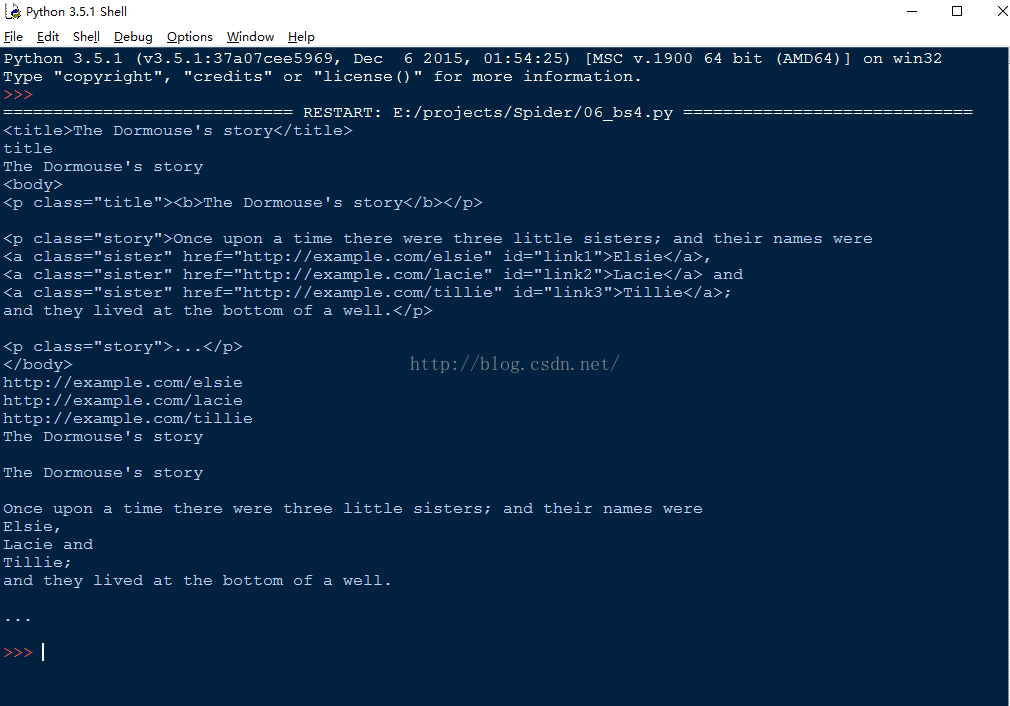
- html = """
- <html><head><title>The Dormouse's story</title></head>
- <body>
- <p class="title"><b>The Dormouse's story</b></p>
- <p class="story">Once upon a time there were three little sisters; and their names were
- <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
- <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
- <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
- and they lived at the bottom of a well.</p>
- <p class="story">...</p>
- """
- from bs4 import BeautifulSoup
- #添加一个解析器
- soup = BeautifulSoup(html,'html5lib')
- print(soup.title)
- print(soup.title.name)
- print(soup.title.text)
- print(soup.body)
- #从文档中找到所有<a>标签的内容
- for link in soup.find_all('a'):
- print(link.get('href'))
- #从文档中找到所有文字内容
- print(soup.get_text())
注意:
配置BeautifulSoup4+lxml+html5lib的更多相关文章
- Python爬虫beautifulsoup4常用的解析方法总结
摘要 如何用beautifulsoup4解析各种情况的网页 beautifulsoup4的使用 关于beautifulsoup4,官网已经讲的很详细了,我这里就把一些常用的解析方法做个总结,方便查阅. ...
- Python爬虫beautifulsoup4常用的解析方法总结(新手必看)
今天小编就为大家分享一篇关于Python爬虫beautifulsoup4常用的解析方法总结,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧摘要 如何用beau ...
- 爬虫基础以及 re,BeatifulSoup,requests模块使用
爬虫基础以及BeatifulSoup模块使用 爬虫的定义:向网站发起请求,获取资源后分析并提取有用数据的程序 爬虫的流程 发送请求 ---> request 获取响应内容 ---> res ...
- 【学习笔记】PYTHON网络爬虫与信息提取(北理工 嵩天)
学习目的:掌握定向网络数据爬取和网页解析的基本能力the Website is the API- 1 python ide 文本ide:IDLE,Sublime Text集成ide:Pychar ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- 1 python大数据挖掘系列之基础知识入门
preface Python在大数据行业非常火爆近两年,as a pythonic,所以也得涉足下大数据分析,下面就聊聊它们. Python数据分析与挖掘技术概述 所谓数据分析,即对已知的数据进行分析 ...
- 转:Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时 ...
- 【bs4】安装beautifulsoup
Debian/Ubuntu,install $ apt-get install python-bs4 easy_install/pip $ easy_install beautifulsoup4 $ ...
- requests和BeautifulSoup
一:Requests库 Requests is an elegant and simple HTTP library for Python, built for human beings. 1.安装 ...
随机推荐
- 小数据玩转Pyspark(2)
一.客户画像 客户画像应用:精准营销(精准预测.个性化推荐.联合营销):风险管控(高风险用户识别.异常用户识别.高可疑交易识别):运营优化(快速决策.产品组合优化.舆情分析.服务升级):业务创新(批量 ...
- KVM虚拟机快照链创建,合并,删除及回滚研究
1 QEMU,KVM,libvirt关系 QEMU QEMU提供了一个开源的服务器全虚拟化解决方案,它可以使你在特定平台的物理机上模拟出其它平台的处理器,比如在X86 CPU上虚拟出Power的CPU ...
- 【OF框架】使用OF框架创建应用项目
开始:准备工作 开发环境已经安装Visual Studio,包含Web开发负载.Python开发负载.NodeJs开发负载 开发环境已经安装Visual Studio Code 开发环境已经安装Nod ...
- Java线程(1)
多线程快速入门 线程与进程区别 每个正在系统上运行的程序都是一个进程.每个进程包含一到多个线程.线程是一组指令的集合,或者是程序的特殊段,它可以在程序里独立执行.也可以把它理解为代码运行的上下文.所以 ...
- jmap与jstat工具实战分析
在上一节[https://www.cnblogs.com/webor2006/p/10662363.html]最后其实是抛出了infoq关于元空间介绍的文章中所涉及到JDK自带的一些工具的使用,这次咱 ...
- psql主主复制
主主是mysql的概念,通常在mysql中为保证事务一致也是一台主写,一台做读.pg主从可以互为切换 之前没做数据库部署这部分,一个同事离职暂时没人,接受过来的!mysql做的是主主复制,我理解是可以 ...
- JAVA API连接HDFS HA集群
使用JAVA API连接HDFS时我们需要使用NameNode的地址,开启HA后,两个NameNode可能会主备切换,如果连接的那台主机NameNode挂掉了,连接就会失败. HDFS提供了names ...
- JS创建SVG的问题
在线编辑的一个东西,用的是js+svg,遇到了这样一个问题,就是说我监听页面的单击事件,然后记录下来鼠标单击的位置,给svg添加子标签,然后页面上展示出来 说的可能不大清楚,上代码吧 <!DOC ...
- [Ynoi2017]由乃的OJ
题意 由乃正在做她的OJ.现在她在处理OJ上的用户排名问题.OJ上注册了n个用户,编号为1-",一开始他们按照编号 排名.由乃会按照心情对这些用户做以下四种操作,修改用户的排名和编号:然而由 ...
- PL/SQL复合类型
一.PL/SQL记录:一条记录. 可简化单行多列的数据的处理.当使用pl/sql记录时,应用开发人员即可以自定义记录类型和记录变量,也可以使用%rowtype属性直接定义记录变量. 1.当使用自定义的 ...