sklearn线性回归实现房价预测模型
题目要求
建立房价预测模型:利用ex1data1.txt(单特征)和ex1data2.txt(多特征)中的数据,进行线性回归和预测。
作散点图可知,数据大致符合线性关系,故暂不研究其他形式的回归。
两份数据放在最后。
单特征线性回归
ex1data1.txt中的数据是单特征,作一个简单的线性回归即可:\(y=ax+b\)。
根据是否分割数据,产生两种方案:方案一,所有样本都用来训练和预测;方案二,一部分样本用来训练,一部分用来检验模型。
方案一
对ex1data1.txt中的数据进行线性回归,所有样本都用来训练和预测。
代码实现如下:
"""
对ex1data1.txt中的数据进行线性回归,所有样本都用来训练和预测
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 数据格式:城市人口,食品经销商利润
# 读取数据
data = np.loadtxt('ex1data1.txt', delimiter=',')
data_X = data[:, 0]
data_y = data[:, 1]
# 训练模型
model = LinearRegression()
model.fit(data_X.reshape([-1, 1]), data_y)
# 利用模型进行预测
y_predict = model.predict(data_X.reshape([-1, 1]))
# 结果可视化
plt.scatter(data_X, data_y, color='red')
plt.plot(data_X, y_predict, color='blue', linewidth=3)
plt.xlabel('城市人口')
plt.ylabel('食品经销商利润')
plt.title('线性回归——城市人口与食品经销商利润的关系')
plt.show()
# 模型参数
print(model.coef_)
print(model.intercept_)
# MSE
print(mean_squared_error(data_y, y_predict))
# R^2
print(r2_score(data_y, y_predict))
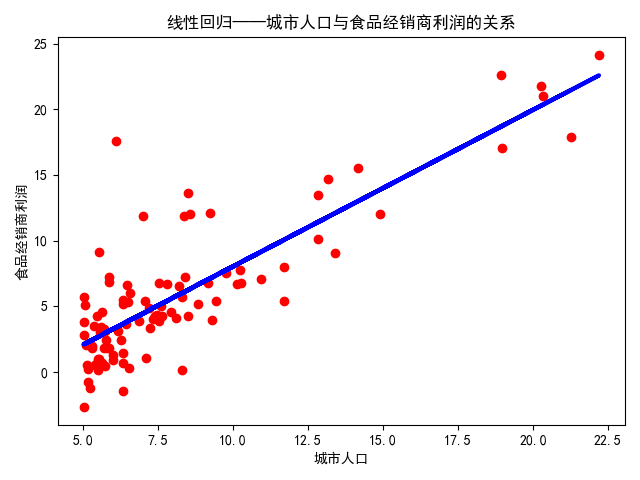
结果如下:
由下可知函数形式以及\(R^2\)为0.70
[1.19303364]
-3.89578087831185
8.953942751950358
0.7020315537841397
方案二
对ex1data1.txt中的数据进行线性回归,部分样本用来训练,部分样本用来预测。
实现如下:
"""
对ex1data1.txt中的数据进行线性回归,部分样本用来训练,部分样本用来预测
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 数据格式:城市人口,食品经销商利润
# 读取数据
data = np.loadtxt('ex1data1.txt', delimiter=',')
data_X = data[:, 0]
data_y = data[:, 1]
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(data_X, data_y)
# 训练模型
model = LinearRegression()
model.fit(X_train.reshape([-1, 1]), y_train)
# 利用模型进行预测
y_predict = model.predict(X_test.reshape([-1, 1]))
# 结果可视化
plt.scatter(X_test, y_test, color='red') # 测试样本
plt.plot(X_test, y_predict, color='blue', linewidth=3)
plt.xlabel('城市人口')
plt.ylabel('食品经销商利润')
plt.title('线性回归——城市人口与食品经销商利润的关系')
plt.show()
# 模型参数
print(model.coef_)
print(model.intercept_)
# MSE
print(mean_squared_error(y_test, y_predict))
# R^2
print(r2_score(y_test, y_predict))
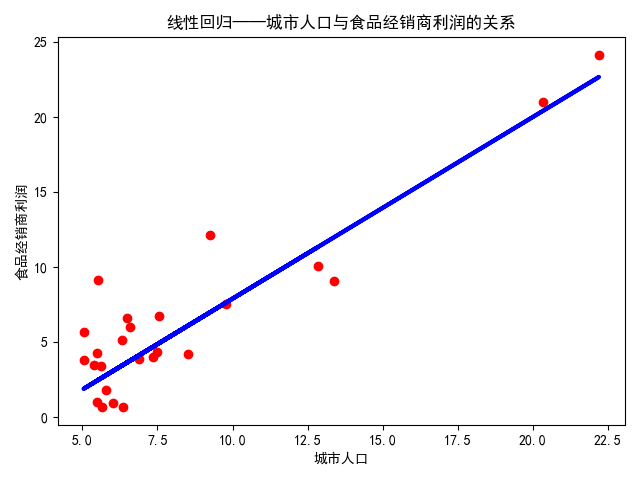
结果如下:
由下可知函数形式以及\(R^2\)为0.80
[1.21063939]
-4.195481965945055
5.994362667047617
0.8095125123727652
多特征线性回归
ex1data2.txt中的数据是二个特征,作一个最简单的多元(在此为二元)线性回归即可:\(y=a_1x_1+a_2x_2+b\)。
对ex1data2.txt中的数据进行线性回归,所有样本都用来训练和预测。
代码实现如下:
"""
对ex1data2.txt中的数据进行线性回归,所有样本都用来训练和预测
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from mpl_toolkits.mplot3d import Axes3D # 不要去掉这个import
from sklearn.metrics import mean_squared_error, r2_score
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 数据格式:城市人口,房间数目,房价
# 读取数据
data = np.loadtxt('ex1data2.txt', delimiter=',')
data_X = data[:, 0:2]
data_y = data[:, 2]
# 训练模型
model = LinearRegression()
model.fit(data_X, data_y)
# 利用模型进行预测
y_predict = model.predict(data_X)
# 结果可视化
fig = plt.figure()
ax = fig.gca(projection='3d')
ax.scatter(data_X[:, 0], data_X[:, 1], data_y, color='red')
ax.plot(data_X[:, 0], data_X[:, 1], y_predict, color='blue')
ax.set_xlabel('城市人口')
ax.set_ylabel('房间数目')
ax.set_zlabel('房价')
plt.title('线性回归——城市人口、房间数目与房价的关系')
plt.show()
# 模型参数
print(model.coef_)
print(model.intercept_)
# MSE
print(mean_squared_error(data_y, y_predict))
# R^2
print(r2_score(data_y, y_predict))
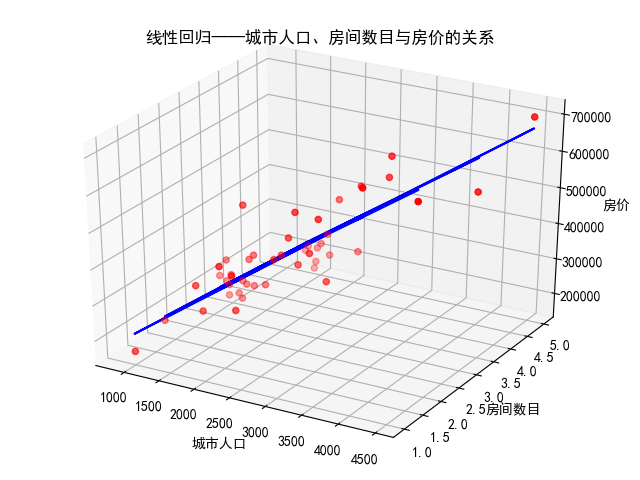
结果如下:
由下可知函数形式以及\(R^2\)为0.73
[ 139.21067402 -8738.01911233]
89597.90954279748
4086560101.205658
0.7329450180289141
两份数据
ex1data1.txt
6.1101,17.592
5.5277,9.1302
8.5186,13.662
7.0032,11.854
5.8598,6.8233
8.3829,11.886
7.4764,4.3483
8.5781,12
6.4862,6.5987
5.0546,3.8166
5.7107,3.2522
14.164,15.505
5.734,3.1551
8.4084,7.2258
5.6407,0.71618
5.3794,3.5129
6.3654,5.3048
5.1301,0.56077
6.4296,3.6518
7.0708,5.3893
6.1891,3.1386
20.27,21.767
5.4901,4.263
6.3261,5.1875
5.5649,3.0825
18.945,22.638
12.828,13.501
10.957,7.0467
13.176,14.692
22.203,24.147
5.2524,-1.22
6.5894,5.9966
9.2482,12.134
5.8918,1.8495
8.2111,6.5426
7.9334,4.5623
8.0959,4.1164
5.6063,3.3928
12.836,10.117
6.3534,5.4974
5.4069,0.55657
6.8825,3.9115
11.708,5.3854
5.7737,2.4406
7.8247,6.7318
7.0931,1.0463
5.0702,5.1337
5.8014,1.844
11.7,8.0043
5.5416,1.0179
7.5402,6.7504
5.3077,1.8396
7.4239,4.2885
7.6031,4.9981
6.3328,1.4233
6.3589,-1.4211
6.2742,2.4756
5.6397,4.6042
9.3102,3.9624
9.4536,5.4141
8.8254,5.1694
5.1793,-0.74279
21.279,17.929
14.908,12.054
18.959,17.054
7.2182,4.8852
8.2951,5.7442
10.236,7.7754
5.4994,1.0173
20.341,20.992
10.136,6.6799
7.3345,4.0259
6.0062,1.2784
7.2259,3.3411
5.0269,-2.6807
6.5479,0.29678
7.5386,3.8845
5.0365,5.7014
10.274,6.7526
5.1077,2.0576
5.7292,0.47953
5.1884,0.20421
6.3557,0.67861
9.7687,7.5435
6.5159,5.3436
8.5172,4.2415
9.1802,6.7981
6.002,0.92695
5.5204,0.152
5.0594,2.8214
5.7077,1.8451
7.6366,4.2959
5.8707,7.2029
5.3054,1.9869
8.2934,0.14454
13.394,9.0551
5.4369,0.61705
ex1data2.txt
2104,3,399900
1600,3,329900
2400,3,369000
1416,2,232000
3000,4,539900
1985,4,299900
1534,3,314900
1427,3,198999
1380,3,212000
1494,3,242500
1940,4,239999
2000,3,347000
1890,3,329999
4478,5,699900
1268,3,259900
2300,4,449900
1320,2,299900
1236,3,199900
2609,4,499998
3031,4,599000
1767,3,252900
1888,2,255000
1604,3,242900
1962,4,259900
3890,3,573900
1100,3,249900
1458,3,464500
2526,3,469000
2200,3,475000
2637,3,299900
1839,2,349900
1000,1,169900
2040,4,314900
3137,3,579900
1811,4,285900
1437,3,249900
1239,3,229900
2132,4,345000
4215,4,549000
2162,4,287000
1664,2,368500
2238,3,329900
2567,4,314000
1200,3,299000
852,2,179900
1852,4,299900
1203,3,239500
作者:@臭咸鱼
转载请注明出处:https://www.cnblogs.com/chouxianyu/
欢迎讨论和交流!
sklearn线性回归实现房价预测模型的更多相关文章
- 使用sklearn进行数据挖掘-房价预测(5)—训练模型
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
- 02-11 RANSAC算法线性回归(波斯顿房价预测)
目录 RANSAC算法线性回归(波斯顿房价预测) 一.RANSAC算法流程 二.导入模块 三.获取数据 四.训练模型 五.可视化 更新.更全的<机器学习>的更新网站,更有python.go ...
- 使用sklearn进行数据挖掘-房价预测(4)—数据预处理
在使用机器算法之前,我们先把数据做下预处理,先把特征和标签拆分出来 housing = strat_train_set.drop("median_house_value",axis ...
- 使用sklearn进行数据挖掘-房价预测(6)—模型调优
通过上一节的探索,我们会得到几个相对比较满意的模型,本节我们就对模型进行调优 网格搜索 列举出参数组合,直到找到比较满意的参数组合,这是一种调优方法,当然如果手动选择并一一进行实验这是一个十分繁琐的工 ...
- 使用sklearn进行数据挖掘-房价预测(1)
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
- 使用sklearn进行数据挖掘-房价预测(2)—划分测试集
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
- 使用sklearn进行数据挖掘-房价预测(3)—绘制数据的分布
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
- Sklearn线性回归
Sklearn线性回归 原理 线性回归是最为简单而经典的回归模型,用了最小二乘法的思想,用一个n-1维的超平面拟合n维数据 数学形式 \[y(w,x)=w_0+w_1x_1+w_2x_2+-+w_nx ...
- 基于sklearn的波士顿房价预测_线性回归学习笔记
> 以下内容是我在学习https://blog.csdn.net/mingxiaod/article/details/85938251 教程时遇到不懂的问题自己查询并理解的笔记,由于sklear ...
随机推荐
- 《Fluid Engine Development》 学习笔记2-基础
断断续续花了一个月,终于把这本书的一二两章啃了下来,理解流体模拟的理论似乎不难,无论是<Fluid Simulation for Computer Graphics>还是<计算流体力 ...
- 【计算机视觉】BING: Binarized Normed Gradients for Objectness Estimation at 300fps
BING: Binarized Normed Gradients for Objectness Estimation at 300fps Ming-Ming Cheng, Ziming Zhang, ...
- Object Detection in 20 Years: A Survey【持续更新中】
原文:https://www.cnblogs.com/zhaojunjie/p/10886099.html 论文链接:https://arxiv.org/pdf/1905.05055.pdf 1. 引 ...
- nssm使用,安装服务、删除服务
安装服务参考 nssm设置solr开机启动服务 删除服务 Windows删除服务 sc delete 服务名 nssm删除服务 nssm remove 服务名 nssm常用命令: nssm insta ...
- [转载]ftp和http区别
本文围绕以下三个部分展开: 一.HTTP协议 二.FTP协议 三.HTTP与FTP的异同点 一.HTTP协议简介 1. 概念 HTTP: HyperText Transfer Protocal,超文本 ...
- 在Settings.db数据库中添加一项新的设置(Settings默认设置)
Settiings的数据默认存放在com.android.providers.settings/database/settings.db中 数据库中的默认数据在frameworks/base/pack ...
- JS 通过注册表调用启动本地软件
(关键点:所有软件安装的注册表路径是不会变化的,这个注册表路径需沟通软件商家获取或者通过自己安装在注册表中查找得到) // 调用 注册表编辑类 方法 function run_jxpgj(){//进项 ...
- Python【编码】
编码 ————————————————————————————————让只认识0和1的计算机,能够理解我们人类使用的语言符号,并且将数据转换为二进制进行存储和传输 人类语言到计算机语言转换的形式,就叫 ...
- Python 第一式
@Codewars Python练习 question ** Dashatize it ** Given a number, return a string with dash'-'marks bef ...
- 【BFS】斗地主
斗地主 题目描述 众所周知,小 X 是一个身材极好.英俊潇洒.十分贪玩成绩却依然很好的奆老.这不,他又找了他的几个好基友去他家里玩斗地主了……身为奆老的小 X 一向认为身边人和自己一样的厉害,他坚信你 ...