【网络爬虫入门04】彻底掌握BeautifulSoup的CSS选择器
【网络爬虫入门04】彻底掌握BeautifulSoup的CSS选择器
广东职业技术学院 欧浩源 2017-10-21
1、引言
目前,除了官方文档之外,市面上及网络详细介绍BeautifulSoup使用的技术书籍和博客软文并不多,而在这仅有的资料中介绍CSS选择器的少之又少。在网络爬虫的页面解析中,CCS选择器实际上是一把效率甚高的利器。虽然资料不多,但官方文档却十分详细,然而美中不足的是需要一定的基础才能看懂,而且没有小而精的演示实例。不过,在本文中,你可以看到......绝对的干活!
2、CSS选择器概述
BeautifulSoup支持大部分的CSS选择器。
语法为:向tag对象或BeautifulSoup对象的.select()方法中传入字符串参数,选择的结果以列表形式返回,即返回类型为list。
tag.select("string")
BeautifulSoup.select("string")
注意:在取得含有特定CSS属性的元素时,标签名不加任何修饰,类名前加点,id名前加 #。
3、CSS测试样例

4、通过标签查找
例1:选择所有的title标签。
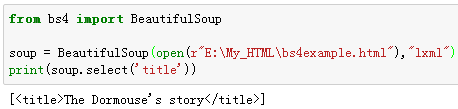
例2:选择所有的p标签中的第3个标签。

例3:选择body标签下的所有a标签。

例4:选择body标签下的直接子标签a。

例5:选择id=link1后的所有兄弟节点标签。类名前加点,id名前加 #。

例6:选择id=link1后的下一个兄弟节点标签。
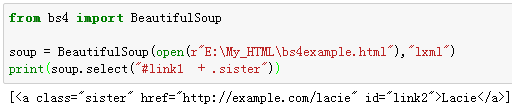
5、通过CSS类名查找
例7:查找class类名为sister的标签。

例8:查找P标签下class类名为title的标签。

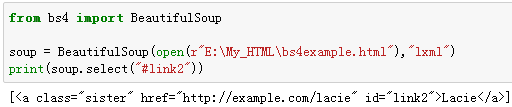
6、通过标签的id属性查找
例9:选择id属性为link2的所有标签。
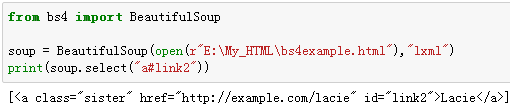
例10:选择a标签,其id属性为link2的标签。
7、同时用多种CSS选择器查询元素
例11:选择id属性为link2和id属性为link3的所有标签。

例12:选择class属性为red、id属性为link2和id属性为link3的所有标签。

8、通过是否存在某个属性来查找
例13:查找a标签下存在herf属性的标签。
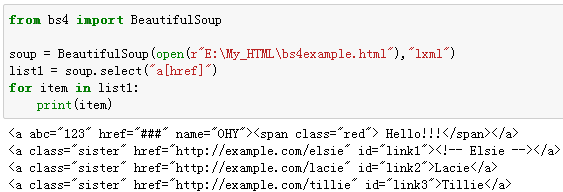
9、通过属性的值来查找
例14:选择a标签,其属性href=http://example.com/lacie的所有标签。

例15:选择a标签,其href属性以http开头的所有标签。
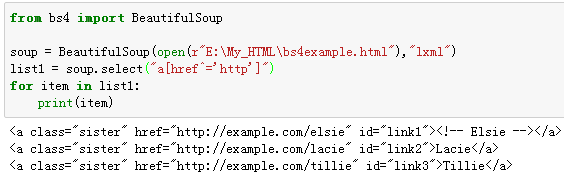
例16:选择a标签,其href属性以lie结尾的所有标签。

例17:选择a标签,其href属性包含.com的标签。

10、通过标签逐层查找
例18:首先选中所有的p标签中的第3个标签,然后在该标签中查找name的属性值为OHY的标签。

例19:首先选中所有的p标签中的第3个标签,然后在该标签列表中查找a标签,并将该列表中的第1个标签的文本取出。

11、返回查找到的元素的第一个标签
例20:选择class类名为sister的所有标签中的第一个。

12、小结
如果你想快速的实现功能更强大的网络爬虫,那么BeautifulSoupCSS选择器将是你必备的利器之一。BeautifulSoup整合了CSS选择器的语法和自身方便使用API。在网络爬虫的开发过程中,对于熟悉CSS选择器语法的人,使用CSS选择器是个非常方便的方法。
【网络爬虫入门04】彻底掌握BeautifulSoup的CSS选择器的更多相关文章
- 【网络爬虫入门03】爬虫解析利器beautifulSoup模块的基本应用
[网络爬虫入门03]爬虫解析利器beautifulSoup模块的基本应用 1.引言 网络爬虫最终的目的就是过滤选取网络信息,因此最重要的就是解析器了,其性能的优劣直接决定这网络爬虫的速度和效率.B ...
- 【网络爬虫入门01】应用Requests和BeautifulSoup联手打造的第一条网络爬虫
[网络爬虫入门01]应用Requests和BeautifulSoup联手打造的第一条网络爬虫 广东职业技术学院 欧浩源 2017-10-14 1.引言 在数据量爆发式增长的大数据时代,网络与用户的沟 ...
- 【网络爬虫入门05】分布式文件存储数据库MongoDB的基本操作与爬虫应用
[网络爬虫入门05]分布式文件存储数据库MongoDB的基本操作与爬虫应用 广东职业技术学院 欧浩源 1.引言 网络爬虫往往需要将大量的数据存储到数据库中,常用的有MySQL.MongoDB和Red ...
- 【网络爬虫入门02】HTTP客户端库Requests的基本原理与基础应用
[网络爬虫入门02]HTTP客户端库Requests的基本原理与基础应用 广东职业技术学院 欧浩源 1.引言 实现网络爬虫的第一步就是要建立网络连接并向服务器或网页等网络资源发起请求.urllib是 ...
- python网络爬虫入门范例
python网络爬虫入门范例 Windows用户建议安装anaconda,因为有些套件难以安装. 安装使用pip install * 找出所有含有特定标签的HTML元素 找出含有特定CSS属性的元素 ...
- Python网络爬虫入门篇
1. 预备知识 学习者需要预先掌握Python的数字类型.字符串类型.分支.循环.函数.列表类型.字典类型.文件和第三方库使用等概念和编程方法. 2. Python爬虫基本流程 a. 发送请求 使用 ...
- Python网络爬虫入门实战(爬取最近7天的天气以及最高/最低气温)
_ 前言 本文文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Bo_wen 最近两天学习了一下python,并自己写了一个 ...
- python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]
目录 前言 一.BeautifulSoup的基本语法 二.爬取网页图片 扩展学习 后记 前言 本章同样是解析一个网页的结构信息 在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图 ...
- python网络爬虫入门(二)
刚去看了一下,18年2月份写了第一篇关于爬虫的文章(仅仅介绍了使用requests库去获取HTML代码),一年多之后看来很稚嫩也没有多少参考的意义,但没想着要去修改它,留着也是一个回忆吧.至少证明着我 ...
随机推荐
- 团队作业8----第二次项目冲刺(beta阶段)5.20
Day2--5.20 1.每日讨论 会议内容:1.新成员乔桦和周迪慢慢了解项目. 2.组内负责主要编程的益靖对代码进行了大概的说明. 3.对昨天的工作进行了几点总结. 4.组长对每个成员的任务完成了分 ...
- 201521123050 《Java程序设计》第4周学习总结
1. 本周学习总结 2. 书面作业 1.注释的应用 1.1使用类的注释与方法的注释为前面编写的类与方法进行注释,并在Eclipse中查看.(截图) 2.面向对象设计(大作业1,非常重要) 2.1 将在 ...
- 201521123001《Java程序设计》第3周学习总结
1. 本周学习总结 2. 书面作业 1. 代码阅读 public class Test1 { private int i = 1;//这行不能修改 private static int j = 2; ...
- 201521123031 《Java程序设计》第一周学习总结
1. 本周学习总结 a.使用notepad++和eclipse编写程序b.对jav的运行环境jdk.jre有了初步的认识c.学习如何使用码云代码库 2. 书面作业 Q1.为什么java程序可以跨平台运 ...
- 201521123064 《Java程序设计》第14周学习总结
本次作业参考文件 数据库PPT MySql操作视频与数据库相关jar文件请参考QQ群文件. 1. 本章学习总结 1.1 以你喜欢的方式(思维导图.OneNote或其他)归纳总结数据库相关内容. 1.数 ...
- 201521123012 《Java程序设计》第十二周学习总结
作业参考文件 1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多线程相关内容. 2. 书面作业 将Student对象(属性:int id, String name,int ag ...
- 201521123012 《Java程序设计》第十周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结异常与多线程相关内容. 2. 书面作业 1.本次PTA作业题集异常.多线程 finally 题目4-2 1.1 截图你的提交结果(出 ...
- could not get next sequence value
1.触发事件 在电脑A上敲项目代码,数据库原始资料是直接使用别人写好的sql导入(建表和导入表数据等): 将电脑A上数据库的资料,使用PL/SQL Developer导出项目中所用表(此时未导出Ora ...
- Maven仓库搜索jar包依赖网址
可在该网站搜索jar包依赖 http://search.maven.org/
- NOIP算法总结与复习
NOIP算法总结与复习 (看了看李总的蓝皮书,收获颇多,记下此文,以明志--) (一)数论 1.最大公约数,最小公倍数 2.筛法球素数 3.mod规律公式 4.排列组合数,错排 5.Catalan数 ...