python 爬虫之爬取大街网(思路)
由于需要,本人需要对大街网招聘信息进行分析,故写了个爬虫进行爬取。这里我将记录一下,本人爬取大街网的思路。
附:爬取得数据仅供自己分析所用,并未用作其它用途。
附:本篇适合有一定 爬虫基础 crawler 观看,有什么没搞明白的,欢迎大家留言,或者私信博主。
首先,打开目标网址www.dajie.com ,在职位搜索中 输入所需职业或关键信息 (我这演示的是 程序员),然后可得到新的链接地址 https://so.dajie.com/job/search?keyword=%E7%A8%8B%E5%BA%8F%E5%91%98&from=job
我们可以看到 ,数据的排序方式有2种,一种是 默认 ,一种是 时间 ,当你点击的时候你可以看到 数据的排序方式发生了变化,但是网页链接却没有变化,而且点击 下一页 的时候页面的链接也没有发生变化,其原因是 当你对其操作时,它通过
JS获取ajax数据进行变换填充,所以如果你要获取所需数据,你只能通过获取其ajax数据。(当然还有模拟JS渲染,得到页面,我没有尝试过,这里也不做多述)
那么如何获取到其数据呢?
当你单击 下一页 等操作时,通过抓包(XHR中)可以查看到ajax数据的来源,查看的时候可以看到其返回的是200(所需的数据),但当你在新的页面打开时,却发现返回的是299,不是你想要的结果。如一下这个链接就是对其进行时间排序所得
的ajax(https://so.dajie.com/job/ajax/search/filter?keyword=%E7%A8%8B%E5%BA%8F%E5%91%98&order=1&city=&recruitType=&salary=&experience=&page=1&positionFunction=&_CSRFToken=&ajax=1)
但是如果你是单独打开它的时候,它返回的是一个错误的页面,这应该是 大街网 反爬虫的一种手段。
找到了返回的ajax地址链接,我们该如何正确的打开这个链接呢?
当我们打开这个 链接时(https://so.dajie.com/job/search?keyword=%E7%A8%8B%E5%BA%8F%E5%91%98&from=job)会发现服务器端回返回一个 Cookie
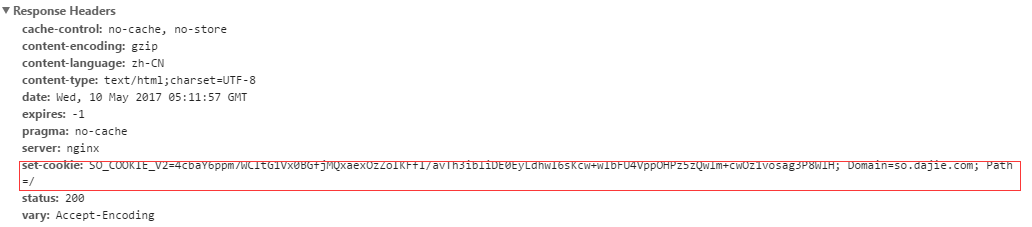
因此 当你访问 (https://so.dajie.com/job/ajax/search/filter?keyword=%E7%A8%8B%E5%BA%8F%E5%91%98&order=1&city=&recruitType=&salary=&experience=&page=1&positionFunction=&_CSRFToken=&ajax=1)
链接时,你必须要传入服务器返回的cookie 才能够获取到正确的结果。

下面附上本人写的代码,仅供参考。
其中需要注意的是:这些代码仅提供一个思路,里面的很多变量、类都是我项目里面的。
这里统一做一下解释
#from myproject.dajie import Jobs, IpAgentPool 指引入 Ip 池,Jobs所需要爬取得 关键字集合.(下面演示时用不到的)
#from myproject import agentPool 引入 Agent池, 用作伪装浏览器使用
from myproject.dajie import Jobs, IpAgentPool
from myproject import agentPool
import http.cookiejar
import urllib.request
import urllib.parse
import random
import re
#import pymssql class dj(): def __init__(self):
# -----BASEURL 为目标网站的URL
# -----ToSearchJob 为需要搜寻的工作
# -----Agent 为Agent池,用于伪装浏览器
# -----opener 为自己建造的一个opener,配合cookiejar可用于存储cookies
def Myopener(self):
cookie = http.cookiejar.CookieJar()
return urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie)) self.BASEURL = "https://www.dajie.com/"
# self.ToSearchJob=Jobs.TheJobNeedToSearch
self.AgentPool = agentPool.userAgent
self.IpPool = IpAgentPool.ipPool self.opener = Myopener(self=self) pass def getContext(self):
url="https://so.dajie.com/job/search?keyword=%E7%A8%8B%E5%BA%8F%E5%91%98&from=job" header=\
{
"User-Agent":agentPool.userAgent[int(random.random()*4)],
"Referer":"https://so.dajie.com/job/search?keyword=%E7%A8%8B%E5%BA%8F%E5%91%98&from=job"
} head=[] for key,value in header.items():
head.append((key,value)) self.opener.addheaders=head #session_cookie用于保存服务器返回的cookie,并将其保存
#
#其实只需要保存 session_cookie["SO_COOKIE_V2"] 即可,其余的是多余的。服务器在进行验证的时候,只会验证 SO_COOKIE_V2
#
session_cookie={}
session=self.opener.open("https://so.dajie.com/job/search?keyword=%E7%A8%8B%E5%BA%8F%E5%91%98&from=job")
print((session.info())) session_cookie["DJ_RF"]= re.findall(r"DJ_RF=.+?;",str(session.info()))[0].split("=")[1]
session_cookie["DJ_EU"]=re.findall(r"DJ_EU=.+?;",str(session.info()))[0].split("=")[1]
session_cookie["DJ_UVID"] = re.findall(r"DJ_UVID=.+?;", str(session.info()))[0].split("=")[1]
session_cookie["SO_COOKIE_V2"] = re.findall(r"SO_COOKIE_V2=.+?;", str(session.info()))[0].split("=")[1] #data 包含的是所需要传入的 cookie
data=\
{
"DJ_RF":session_cookie["DJ_RF"].strip(";"),
"DJ_EU":session_cookie["DJ_EU"].strip(";"),
"DJ_UVID":session_cookie["DJ_UVID"].strip(";"),
"SO_COOKIE_V2":session_cookie["SO_COOKIE_V2"].strip(";"),
"__login_tips":1,
}
#将 数据解析为传入数据的格式
_data=urllib.parse.urlencode(data,"utf-8")
print("______________")
print(_data)
#
#_url 指的是ajax的链接地址
_url="https://so.dajie.com/job/ajax/search/filter?keyword=%E7%A8%8B%E5%BA%8F%E5%91%98&order=1&city=&recruitType=&salary=&experience=&page=1&positionFunction=&_CSRFToken=&ajax=1"
req=self.opener.open(_url,data=_data.encode("utf-8")) print("-----------------")
print(req.read().decode("utf-8")) #print(req.read().decode("utf-8")) if __name__=="__main__":
_dj=dj()
_dj.getContext()
最后附上运行结果的截图

python 爬虫之爬取大街网(思路)的更多相关文章
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- Python爬虫项目--爬取自如网房源信息
本次爬取自如网房源信息所用到的知识点: 1. requests get请求 2. lxml解析html 3. Xpath 4. MongoDB存储 正文 1.分析目标站点 1. url: http:/ ...
- 简单python爬虫案例(爬取慕课网全部实战课程信息)
技术选型 下载器是Requests 解析使用的是正则表达式 效果图: 准备好各个包 # -*- coding: utf-8 -*- import requests #第三方下载器 import re ...
- 网络爬虫之定向爬虫:爬取当当网2015年图书销售排行榜信息(Crawler)
做了个爬虫,爬取当当网--2015年图书销售排行榜 TOP500 爬取的基本思想是:通过浏览网页,列出你所想要获取的信息,然后通过浏览网页的源码和检查(这里用的是chrome)来获相关信息的节点,最后 ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
随机推荐
- 【Alpha】第一次项目冲刺
今日站立式会议照片 每个人的工作 小组成员 昨天完成的工作 今天计划完成的工作 李志霖 继续访问用户以深入了解他们的需求,分别采用面访,qq等不同方式对意见进行了采集,面访了30个人,qq空间以链接的 ...
- 201521123035《Java程序设计》第二周学习总结
1.本周学习总结 这周学习了各种类与对象,还有基本类型的打包器,最主要的是字符串对象,老师还特地花了一节课时间讲解代码与习题. 2.书面作业 1.使用Eclipse关联jdk源代码,并查看String ...
- 201521123101 《Java程序设计》第1周学习总结
1. 本周学习总结 在学习Java之前要做好准备工作,了解Java从研发后开始如何一步步完善,其与C++.C语言的异同,然后下载JDK.Eclipse.Notepad等软件,以便于未来的学习. 2. ...
- 201521123016 《Java程序设计》第13周学习总结
1. 本周学习总结 2. 书面作业 1. 网络基础 1.1 比较ping www.baidu.com与ping cec.jmu.edu.cn,分析返回结果有何不同?为什么会有这样的不同? ping w ...
- [js高手之路]Node.js模板引擎教程-jade速学与实战2-流程控制,转义与非转义
一.转义与非转义 jade模板文件代码: doctype html html head meta(charset='utf-8') title jade学习-by ghostwu body h3 转义 ...
- 监听器第一篇【基本概念、Servlet各个监听器】
什么是监听器 监听器就是一个实现特定接口的普通java程序,这个程序专门用于监听另一个java对象的方法调用或属性改变,当被监听对象发生上述事件后,监听器某个方法将立即被执行. 为什么我们要使用监听器 ...
- eclipse复制到IDEA中文不匹配,编译失败
今天使用把eclipse的包复制到Intellij Idea下,结果在编译的时候,它说我的数据是GBK,而Idea默认的数据是UTF-8,因此出错了... 解决:在项目中直接把对象的encoding. ...
- OSGi-入门篇之服务层(03)
前言 作为OSGi框架中最上面的一层,服务层带给了我们更多的动态性,并且使用了大家或多或少都曾了解过的面向服务编程模型,其好处是显而易见的. 1 什么是服务 简单的说,服务就是“为别人所做的工作”,比 ...
- 在eclipse上使用github,向github中提交项目
1.下载egit插件 打开Eclipse,git需要eclipse授权,通过网页是无法下载egit的安装包的.在菜单栏依次打开eclipse→help→install new software→add ...
- pig报错
pig failed to read data from....... 错误可能1:load data的目录不在,或者引用出错,load data '/in/train'这里的红色/应该去掉,因为默认 ...