【深度学习】keras + tensorflow 实现猫和狗图像分类
本文主要是使用【监督学习】实现一个图像分类器,目的是识别图片是猫还是狗。
从【数据预处理】到 【图片预测】实现一个完整的流程, 当然这个分类在 Kaggle 上已经有人用【迁移学习】(VGG,Resnet)做过了,迁移学习我就不说了,我自己用 Keras + Tensorflow 完整的实现了一遍。
准备工作:
- 数据集:Dogs vs. Cats注册激活困难,自己想想办法,Ps:实在注册不了百度云有下载自己搜搜
- 使用编程语言:当然是Python 3,你问我为什么,当然是人生苦短。
- 使用机器学习库:Numpy(科学计算的库,主要是矩阵运算,真特么好用),sklearn( 机器学习库), Keras(高层神经网络API,真特么好用,马云用了都说好),Tensorflow-GPU版(深度学习框架,用的人都说好,没用的也说好)
- 编辑器:Visual studio code (巨硬大法好),安装Python插件
Ps:NVIDIA的显卡才支持GPU加速运算,具体哪些卡,看它的官网,使用GPU比CPU要节省四五倍的时间。
先导入用到的库:
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import numpy as np
from keras import callbacks
from keras.models import Sequential, model_from_yaml, load_model
from keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPool2D
from keras.optimizers import Adam, SGD
from keras.preprocessing import image
from keras.utils import np_utils, plot_model
from sklearn.model_selection import train_test_split
from keras.applications.resnet50 import preprocess_input, decode_predictions
注意: os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
这一行代码是为了不让在控制钱显示Tensorflow输出的一堆信息,不写就可以看到 tensorflow 输出的一堆日志。
- 加载数据:下载的压缩包解压出来,目录下面有25,000 猫和狗的图片
线上代码,后面解释
def load_data():
path = './data/train/'
files = os.listdir(path)
images = []
labels = []
for f in files:
img_path = path + f
img = image.load_img(img_path, target_size=image_size)
img_array = image.img_to_array(img)
images.append(img_array) if 'cat' in f:
labels.append(0)
else:
labels.append(1) data = np.array(images)
labels = np.array(labels) labels = np_utils.to_categorical(labels, 2)
return data, labels
因为计算机不能直接对图片,视频,文字等直接进行运算,所以首先要把图片转成数值类型的矩阵,并且保证你训练的图片大小一样,我在这里使用keras自带的图片处理类 from keras.preprocessing import image ,主要是就是两个函数 :
image.load_img(img_path, target_size=image_size) 第一个参数图片的路径,第二个参数target_size 是个tuple 类型,(img_w,img_h)
image.img_to_array(img) 图片转成矩阵,当然你也可以使用Numpy的 asarray 效果应该一样
- 构建模型:图片分类肯定是卷积模型最好,这个目前位置不用质疑,应该Imagenet 已经证明了,下面先看代码:
model = Sequential()
model.add(Conv2D(32, kernel_size=(5, 5), input_shape=(img_h, img_h, 3), activation='relu', padding='same'))
model.add(MaxPool2D())
model.add(Dropout(0.3))
model.add(Conv2D(64, kernel_size=(5, 5), activation='relu', padding='same'))
model.add(MaxPool2D())
model.add(Dropout(0.3))
model.add(Conv2D(128, kernel_size=(5, 5), activation='relu', padding='same'))
model.add(MaxPool2D())
model.add(Dropout(0.5))
model.add(Conv2D(256, kernel_size=(5, 5), activation='relu', padding='same'))
model.add(MaxPool2D())
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(2, activation='softmax'))
model.summary() //这一句只是输出网络结构
模型:使用序贯模型,然后加了4个卷积层,Conv2D 第一个参数就是卷基层的输出维度,为什么我写了32呢,因为我电脑渣啊,GPU显存太小了,否则我就写64了。参考了VGG,Resnet 等的网络结构
激活函数:卷基层的激活函数使用非线性激活函数: relu。输出层的激活函数使用 softmax, 多分类就用这个。
池化层(MaxPool2D):主要是降维,减少参数加速运算,防止过拟合,为了防止过拟合还加入了 Dropout 层
- 编译设计的模型:
sgd = Adam(lr=0.0003)
model.compile(loss='binary_crossentropy',optimizer=sgd, metrics=['accuracy'])
讲一下优化器: Adam(lr=0.0003) 效果最好,基本都是用这个,lr:学习速率,学习速率越小,理论上来说损失函数越小,精度越高,但是计算越慢,默认是 0.001
注意:不加 metrics=['accuracy'] 参数不会输出日志,在控制台看不到变化。
- 切分数据:从训练数据分割80% 用来训练,20%训练验证
images, lables = load_data()
images /= 255
x_train, x_test, y_train, y_test = train_test_split(images, lables, test_size=0.2)
除以 255 是为了数据归一化,理论上来说归一化,会减少损失函数的震荡,有助于减小损失函数提高精度。
- 训练:加了Tensorlow 可视化,使用的是 TensorBoard,可以清晰的看到 损失函数和精度的变化趋势
print("train.......")
tbCallbacks = callbacks.TensorBoard(log_dir='./logs', histogram_freq=1, write_graph=True, write_images=True)
model.fit(x_train, y_train, batch_size=nbatch_size, epochs=nepochs, verbose=1, validation_data=(x_test, y_test), callbacks=[tbCallbacks])
运行 TensorBoard 只需要两行代码,在cmd,cd D:\Learning\learn_python\ 先切到你的logs目录的上一级,然后执行 tensorboard --logdir="logs" 即可。
- 评估:返回两个数据,这个没什么说的
scroe, accuracy = model.evaluate(x_test, y_test, batch_size=nbatch_size)
print('scroe:', scroe, 'accuracy:', accuracy)
- 保存模型:保存是为了可以方便的迁移学习,把网络结构和权重分开保存,当然也可以直接一起保存,需要的导入: from keras.models import model_from_yaml, load_model
yaml_string = model.to_yaml()
with open('./models/cat_dog.yaml', 'w') as outfile:
outfile.write(yaml_string)
model.save_weights('./models/cat_dog.h5')
- 调参:调参其实就是在对抗过拟合和欠拟合,欠拟合可以消除,但是过拟合只能缓解没办法消除。有人说
深度学习工程师50%的时间在调参数,49%的时间在对抗过/欠拟合,剩下1%时间在修改网上down下来的程序
深以为然啊,刚开始我的网络结构不是这样的,卷基层只有2层,kernel_size=(3,3), 学习速率采用的默认参数,全连接层是: Dense(256),训练之后发现欠拟合,精度只有86%左右,后来增加了卷积层数量,调小学习速率等几轮的调参,精度接近93%,还可以继续提升,但我不想调了,因为笔记本的GPU太渣(1050ti)训练一次差不多需要一个多小时。
调参也没什么好办法,只能一次次的去试,如果采用迁移学习,VGG,Resnet的网络结构和权重的话,分分钟能上98%,毫无难度。
- 预测真实数据:保存的网络结构.yaml文件 和权重 .h5 文件先加载进来,然后编译,然后直接预测
def pred_data():
with open('./models/cat_dog.yaml') as yamlfile:
loaded_model_yaml = yamlfile.read()
model = model_from_yaml(loaded_model_yaml)
model.load_weights('./models/cat_dog.h5')
sgd = Adam(lr=0.0003)
model.compile(loss='categorical_crossentropy',optimizer=sgd, metrics=['accuracy'])
images = []
path='./data/test/'
for f in os.listdir(path):
img = image.load_img(path + f, target_size=image_size)
img_array = image.img_to_array(img)
x = np.expand_dims(img_array, axis=0)
x = preprocess_input(x)
result = model.predict_classes(x,verbose=0)
print(f,result[0])
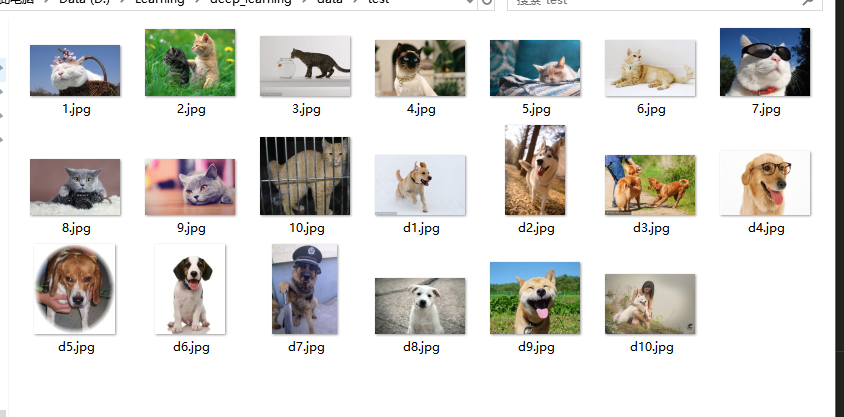
因为做的分类任务,我在加载数据的时候写的是 cat 索引为 0 ,dog索引为 1,所以输出的时候,预测的值与之对应,我从百度找了20张图片猫狗个10张,图片长这样:
预测的结果如下:
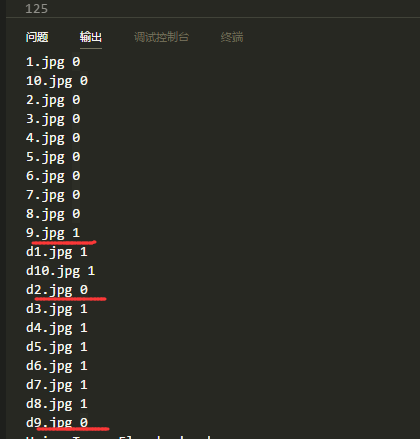
可以看到,猫 有一张错误,狗 有两张错误,这个精度在小样本数据集不适用迁移学习的情况下还是可以的。
完整代码:https://github.com/jarvisqi/deep_learning
参考:http://keras-cn.readthedocs.io/en/latest/
【深度学习】keras + tensorflow 实现猫和狗图像分类的更多相关文章
- 深度学习与TensorFlow
深度学习与TensorFlow DNN(深度神经网络算法)现在是AI社区的流行词.最近,DNN 在许多数据科学竞赛/Kaggle 竞赛中获得了多次冠军. 自从 1962 年 Rosenblat 提出感 ...
- 深度学习调用TensorFlow、PyTorch等框架
深度学习调用TensorFlow.PyTorch等框架 一.开发目标目标 提供统一接口的库,它可以从C++和Python中的多个框架中运行深度学习模型.欧米诺使研究人员能够在自己选择的框架内轻松建立模 ...
- 金玉良缘易配而木石前盟难得|M1 Mac os(Apple Silicon)天生一对Python3开发环境搭建(集成深度学习框架Tensorflow/Pytorch)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_189 笔者投入M1的怀抱已经有一段时间了,俗话说得好,但闻新人笑,不见旧人哭,Intel mac早已被束之高阁,而M1 mac已经 ...
- 深度学习之TensorFlow构建神经网络层
深度学习之TensorFlow构建神经网络层 基本法 深度神经网络是一个多层次的网络模型,包含了:输入层,隐藏层和输出层,其中隐藏层是最重要也是深度最多的,通过TensorFlow,python代码可 ...
- 深度学习(TensorFlow)环境搭建:(三)Ubuntu16.04+CUDA8.0+cuDNN7+Anaconda4.4+Python3.6+TensorFlow1.3
紧接着上一篇的文章<深度学习(TensorFlow)环境搭建:(二)Ubuntu16.04+1080Ti显卡驱动>,这篇文章,主要讲解如何安装CUDA+CUDNN,不过前提是我们是已经把N ...
- 【原创 深度学习与TensorFlow 动手实践系列 - 4】第四课:卷积神经网络 - 高级篇
[原创 深度学习与TensorFlow 动手实践系列 - 4]第四课:卷积神经网络 - 高级篇 提纲: 1. AlexNet:现代神经网络起源 2. VGG:AlexNet增强版 3. GoogleN ...
- 【原创 深度学习与TensorFlow 动手实践系列 - 3】第三课:卷积神经网络 - 基础篇
[原创 深度学习与TensorFlow 动手实践系列 - 3]第三课:卷积神经网络 - 基础篇 提纲: 1. 链式反向梯度传到 2. 卷积神经网络 - 卷积层 3. 卷积神经网络 - 功能层 4. 实 ...
- 分享《机器学习实战基于Scikit-Learn和TensorFlow》中英文PDF源代码+《深度学习之TensorFlow入门原理与进阶实战》PDF+源代码
下载:https://pan.baidu.com/s/1qKaDd9PSUUGbBQNB3tkDzw <机器学习实战:基于Scikit-Learn和TensorFlow>高清中文版PDF+ ...
- 深度学习(TensorFlow)环境搭建:(二)Ubuntu16.04+1080Ti显卡驱动
前几天把刚拿到了2台GPU机器组装好了,也写了篇硬件配置清单的文章——<深度学习(TensorFlow)环境搭建:(一)硬件选购和主机组装>.这两台也在安装Ubuntu 16.04和108 ...
随机推荐
- 201521123060 《Java程序设计》第10周学习总结
1.本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结异常与多线程相关内容. 异常: 1.不要乱用异常: 2.异常发生时:确定异常类型,异常位置: 3.尽量使用已有的异常类. 多线程: 2 ...
- 201521123018 《Java程序设计》第14周学习总结
1. 本章学习总结 2. 书面作业 1. MySQL数据库基本操作 建立数据库,将自己的姓名.学号作为一条记录插入.(截图,需出现自己的学号.姓名) 在自己建立的数据库上执行常见SQL语句(截图) 添 ...
- 201521123050 《Java程序设计》第14周学习总结
1. 本周学习总结 2. 书面作业 1. MySQL数据库基本操作 1.1立数据库,将自己的姓名.学号作为一条记录插入.(截图,需出现自己的学号.姓名) 在自己建立的数据库上执行常见SQL语句(截图) ...
- 201521123039 《java程序设计》第一周学习总结
#1.本章学习总结 Java是面向对象的程序语言,它一切定义都是对象.我们所编写的Java程序经过编译后生成了*.class的文件,再经过JVM对*.class解释运行就可以得到Java程序,所以Ja ...
- Eclipse rap 富客户端开发总结(12) :Rap 优化之组件的销毁
一.概述 经过几个月的rap 项目实战,总结了一些小经验,在这里总结一下,希望对大家有所帮助. 二.销毁的处理 相信学习rap 的同学都知道,swt 中提供了许多的组件,像lab ...
- ecshop商城系统登录出现登录闪退问题
症状:ecshop商城系统提示登录成功,而且状态也是登录,一刷新,自动退出了,真坑爹 解决方案: 1.点着点着经常无故退出,感觉session被清空了.查找原因:ecshop中有用ip地址来验证,而公 ...
- 再起航,我的学习笔记之JavaScript设计模式24(备忘录模式)
备忘录模式 概念介绍 备忘录模式(Memento): 在不破坏对象的封装性的前提下,在对象之外捕获并保存该对象内部的状态以便日后对象使用或者对象恢复到以前的某个状态. 简易分页 在一般情况下我们需要做 ...
- 优秀的CSS预处理----Less
Less语法整理 本人邮箱:kk306484328@163.com,欢迎交流讨论. 欢迎转载,转载请注明网址:http://www.cnblogs.com/kk-here/p/7601058.html ...
- 认识:ThinkPHP的编译缓存文件~runtime.php
1.定义单入口文件(index.php) 在单入口index.php中不定义这两项时,会生成编译缓存文件~runtime.php define('RUNTIME_PATH','./App/Temp/' ...
- apollo实现c#与android消息推送(四)
4 Android代码只是为了实现功能,比较简单,就只是贴出来 package com.myapps.mqtttest; import java.util.concurrent.Executors; ...