第五章:Python基础の生成器、迭代器、序列化和虚拟环境的应用
本课主题
- 生成器介紹和操作实战
- 迭代器介紹和操作实战
- 序例化和反序例化
- Json 和 Pickle 操作实战
- 字符串格式化的应用
- 创建虚拟环境实战
- 本周作业
生成器介紹和操作实战
什么是生成器,生成器是一个对象,当只有循还它的时候才会生成数据,在Python2.7 有一个 range( ) 和 xrange ( ) 函数,它们是负责生成数据的,range( ) 会直接在內存中生成一个有数据的列表,然后xrange( ) 会生成一个对象,当你循还它的时候才会生成数据,它有垃圾回收机制把没用的数据回收。
# range( )
>>> li = range(10)
>>> li
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> type(li)
<type 'list'> # xrange( )
>>> li2 = xrange(10)
>>> li2
xrange(10)
>>> type(li2)
<type 'xrange'>
Python2.7里range( ) 和 xrange( )
对于生产来说是使用函数把它创造的,只有函数里存在一个关键事: "yield" 它便叫做生成器。但执行以下程序时,其实什么都没有打印出来,因为生成器返回的是一个对象,你需要循还它的时候才会生成数据。它第一次循还的時候,会找第一个 yield 后面的值然后就停下来,第二次循还会再次找下一个 yield 后面的值,然后打印出来,直到没无再找到 yield就会终止。

>>> def func():
... print("start")
... yield 1
... yield 2
... yield 3 >>> ret = func()
>>> print(ret, type(ret))
(<generator object func at 0x100708b40>, <type 'generator'>) >>> for i in ret:
... print(i) start
1
2
3
生成器基本概念
现在可以结合 __next__( )函数来调用生成器,__next__( ) 的功能进入函数然后找到 yield,只有找到 yield 便退出,并且获取yield后面的数据,直到找不到 yield,如果没有 yield 但是你还调用 __next__( )的话便会报错!! 也可以说是保存上一次执行的位置 (默认是 Yield 后面的数据位置),当下一次再执行的时候,会在当前那个位置继续往下走。
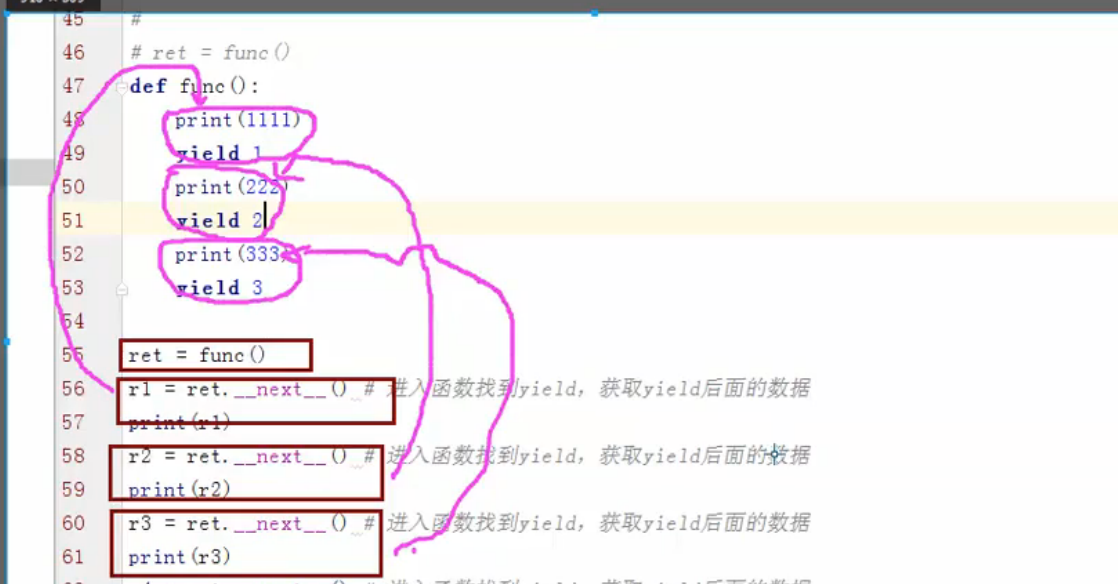
def func():
print(111)
yield 1
print(222)
yield 2
print(333)
yield 3 ret = func()
r = ret.__next__() #进入函数找到 yield,并获取yield后面的数据
print("r:",r)
r1 = ret.__next__() #进入函数找到 yield,并获取yield后面的数据
print("r1:",r)
生成器結合__next__( )例子
動手自己寫一個生成器
具有生产能力的叫生成器,具有获取能力的叫迭代器,迭代器每一次迭代目的是取一個值
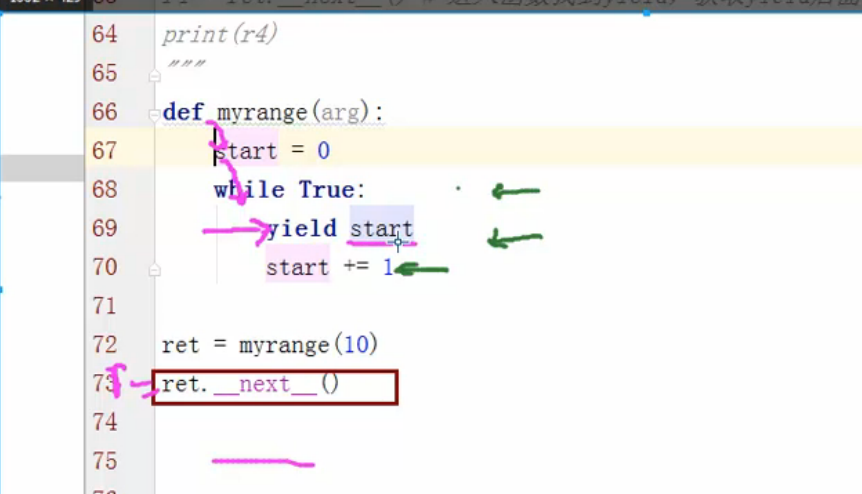
def myrange(args):
start = 0
while True:
if start > args:
return
yield start
start += 1 r = myrange(3)
ret = r.__next__()
print(ret) # ret = r.__next__()
print(ret) # ret = r.__next__()
print(ret) # ret = r.__next__()
print(ret) #
生成器
迭代器介紹和操作实战
当你用生成器生成一个东西之后,它返回的是具有生成指定条件数据成员的一个对象,这个对象是一个可迭代的对象,然后你可以调用循还或者是__next__( )函数来获取这个对象里的值。
总结:生成器负责生成,返回的可迭代的对象叫迭代器!!!!
** Python 的 For = 其他語言的 Foreach
import lib.common
lib.common .f1()
Module
import sys
for file in sys.path:
print(file) #/Users/jcchoiling/PycharmProjects/s13/day5
#/Users/jcchoiling/PycharmProjects/s13
#/usr/local/Cellar/python3/3.5.1/Frameworks/Python.framework/Versions/3.5/lib/python35.zip
#/usr/local/Cellar/python3/3.5.1/Frameworks/Python.framework/Versions/3.5/lib/python3.5
#/usr/local/Cellar/python3/3.5.1/Frameworks/Python.framework/Versions/3.5/lib/python3.5/plat-darwin
#/usr/local/Cellar/python3/3.5.1/Frameworks/Python.framework/Versions/3.5/lib/python3.5/lib-dynload
Module:sys
序例化与反序例化
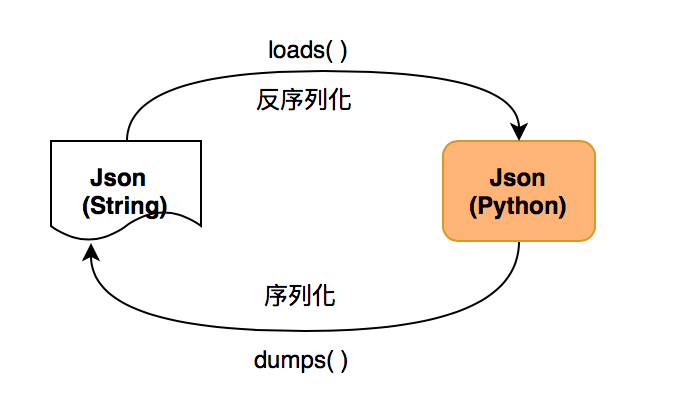
Json
字符串 <--> Python 的基本数据类型之间的转换
序列化 - dumps( ): 把 Python 的字典变成字符串,将 Python 基本数据类型转化成字符串形式
>>> import json
>>> dic = {"k1":"v1"}
>>> print(dic, type(dict))
{'k1': 'v1'} <class 'type'> >>> ret = json.dumps(dic) #把 Json 转换成字典
>>> print(ret, type(ret))
{"k1": "v1"} <class 'str'>
序例化
反序列化 - loads( ):把字符串转化成 Python 基本的数据类型
>>> s1 = '{"k1":"v1"}'
>>> dic = json.loads(s1)
>>> print(s1, type(s1))
{"k1":"v1"} <class 'str'>
>>> print(dic, type(dic))
{'k1': 'v1'} <class 'dict'>
反序列化
不同语言之间对引号的定义都不同,有些时单引号代表字符,双引号则代表字符串,在进行序例化的时候,外面的括号必顺是单引号,里面的内容必顺是双引号,因为Json是一种可以跨平台进行信息传递的一种格式,这是确保能够在不同语言中Json 都能够进行序例化和反序例化。
>>> import json
>>> r = json.dumps([11,22,33]) # 把基本数据类型转换成字符串(序例化)
>>> print(r, type(r))
[11, 22, 33] <class 'str'> >>> li = '["alex","eric"]'
>>> ret = json.loads(li) # 把字符串转换成列表(反序例化)
>>> print(ret,type(ret))
['alex', 'eric'] <class 'list'>
综合例子
对于dumps( ) 和 loads( ) 的操作是发生在内存里,但 Json 也有一个叫 dump( ) 和 load( ) 的函数,它们主要比前面的两个函数多了一个步骤,如果是dump( )的话,它会先进行序例化(基本类型--> 字符串),然后把结果写到另外一个文件里。如果是 load( )的话,它会先把结果写进文件然后从文件里获取信息,然后进行反序例化(字符串 --> 基本类型)。
import json
li = [11,22,33]
json.dump(li,open("db","w")) #第一步:先序例代, 第二步:把序例代後的結果寫列文件裡e.g. db li = json.load(open("db","r"))
print(li,type(li))
#[11, 22, 33] <class 'list'>
dump和load的操作
Pickle
Python 的 Pickle 有特殊的序例化和反序例化功能,它也有 dumps()和 loads()的方法,Pickle 只能在 Python 語言用,序列化后返回一个 pickle 认识的字符串,它也只支持以字節的方式來操作
>>> import pickle
>>> li = [11,22,33]
>>> r=pickle.dumps(li)
>>> print(r)
b'\x80\x03]q\x00(K\x0bK\x16K!e.' >>> ret = pickle.loads(r)
>>> print(ret)
[11, 22, 33]
pickle的dumps和loads操作
>>> import pickle
>>> li = [11,22,33]
>>> r=pickle.dump(li,open("db","wb")) >>> ret = pickle.load(open("db","rb"))
>>> print(ret)
[11, 22, 33]
pickle的dump和load操作
Json 和 Pickle 的对比:
- Json 更适合跨平台/语言的操作
- Pickle 适合复杂类型的操作
import pickle class Foo():
def __init__(self):
pass f = Foo()
p = pickle.dumps(f)pickle dumps 一个对象
实战例子
一般来说信息之间通信是通过发送Http-request 来获取的,我给你请求你给我字符串、它们会返回一个Json形式的字符串,然后你要通过反序例化把它转换成 Python 的字典来进行下一步的操作,调用 request.get( )时会把你需要的信息,比如说请求状态、Cookie、Header, etc. 都封装到response对象里(e.g. response = request.get("http//...."),然后调用 response.text( ) 來获取这次请求返回的内容。
import requests
import json #获取天气数据API
#通过 http request 取天气的数据
response = requests.get("http://wthrcdn.etouch.cn/weather_mini?city=上海")
response.encoding = 'utf-8'
print("Before", type(response)) #把它变成字符串 #然后进行反序列化,把字符串转换成 Python 的数据类型:字典
ret = json.loads(response.text)
print("After", type(ret)) #把它由字符串变成字典
print(ret) #Before <class 'requests.models.Response'>
#After <class 'dict'> #{'status': 1000, 'data': {'city': '上海', 'yesterday': {'date': '2日星期五', 'type': '晴', 'fl': '微风', 'low': '低温 25℃', 'high': '高温 34℃', 'fx': '西风'}, 'forecast': [{'date': '3日星期六', 'type': '晴', 'low': '低温 25℃', 'high': '高温 35℃', 'fengli': '微风级', 'fengxiang': '东北风'}, {'date': '4日星期天', 'type': '多云', 'low': '低温 25℃', 'high': '高温 33℃', 'fengli': '微风级', 'fengxiang': '东北风'}, {'date': '5日星期一', 'type': '阴', 'low': '低温 24℃', 'high': '高温 32℃', 'fengli': '微风级', 'fengxiang': '东北风'}, {'date': '6日星期二', 'type': '阴', 'low': '低温 24℃', 'high': '高温 29℃', 'fengli': '微风级', 'fengxiang': '东北风'}, {'date': '7日星期三', 'type': '阵雨', 'low': '低温 23℃', 'high': '高温 29℃', 'fengli': '微风级', 'fengxiang': '东北风'}], 'ganmao': '各项气象条件适宜,发生感冒机率较低。但请避免长期处于空调房间中,以防感冒。', 'aqi': '115', 'wendu': '31'}, 'desc': 'OK'}
获取天气数据API
字符串格式化的应用
[更新中...]
创建虚拟环境实战
创建虚拟环境是有很多好处的,它可以对不同project 中的模块进行版本控制
- 首先是安装虚拟环境
pip install virtualenv
- 进行project的目录中
cd my_project_folder
- 初始化虚拟环境,venv 是虚拟环境的名称
virtualenv venv
- 要开始使用虚拟环境,其需要被激活
source venv/bin/activate
- 为了保持你的环境的一致性,“冷冻住(freeze)”环境包当前的状态是个好主意
pip freeze > requirements.txt
Project Respository Structure
Viuflix/
|----README.txt
|----Doc/
| |----documentation.txt
|----viuflix/
| |----__init__.py
| |----foo.py
| |----bar.py
| |----utils/
| | |----__init__.py
| | |----spam.py
| | |----grok.py
|----examples/
| |----helloviuflix.py
|----tests/
| |----test_viuflix.py
|----setup.py
|----MANIFEST.in
|----requirement.txt
Viuflix project
本周作业
ATM 作業
- 额度15000 或自定义
- 实现购物商城,卖东西加入购物车,调用信用卡接口结账
- 可以提现,手续费 5%
- 每月 22号出粮,每月10号为还款日、过期未还,按欠款总额 5% 每日利息
- 支持多账户登录
- 支持账户间转账
- 记录每月日常流水
- 提供还款接口
- ATM记录操作日志
- 接供管理接口,包括添加账户,用户额度,冻结账户等

第五章:Python基础の生成器、迭代器、序列化和虚拟环境的应用的更多相关文章
- 0004-20180422-自动化第五章-python基础学习笔记
内容回顾:1.数据类型 2.for和while循环 continue break #如下循环将怎么打印结果? for i in range(1,10): print(i) for i in range ...
- python基础 生成器 迭代器
列表生成式: a=[1,2,3] print a b=[i*2 for i in range(10)] #i循环10次,每一个i的值乘2就是列表中的值.列表生成式 print b >>[1 ...
- (转)python基础之迭代器协议和生成器(一)
一 递归和迭代 二 什么是迭代器协议 1.迭代器协议是指:对象必须提供一个next方法,执行该方法要么返回迭代中的下一项,要么就引起一个StopIteration异常,以终止迭代 (只能往后走不能往前 ...
- 0003.5-20180422-自动化第四章-python基础学习笔记--脚本
0003.5-20180422-自动化第四章-python基础学习笔记--脚本 1-shopping """ v = [ {"name": " ...
- [Python笔记][第一章Python基础]
2016/1/27学习内容 第一章 Python基础 Python内置函数 见Python内置函数.md del命令 显式删除操作,列表中也可以使用. 基本输入输出 input() 读入进来永远是字符 ...
- 五、Python基础(2)
五,Python基础(2) 1.数据类型基础 (一)什么是数据类型? 用于区分变量值的不同类型. (二)为何对数据分类? 针对不同状态就应该用不同类型的数据去标识. (三)数据类型分类 1.数字类型 ...
- Python基础之迭代器和生成器
阅读目录 楔子 python中的for循环 可迭代协议 迭代器协议 为什么要有for循环 初识生成器 生成器函数 列表推导式和生成器表达式 本章小结 生成器相关的面试题 返回顶部 楔子 假如我现在有一 ...
- python基础之迭代器协议和生成器
迭代器和生成器补充:http://www.cnblogs.com/luchuangao/p/6847081.html 一 递归和迭代 略 二 什么是迭代器协议 1.迭代器协议是指:对象必须提供一个ne ...
- python基础8 -----迭代器和生成器
迭代器和生成器 一.迭代器 1.迭代器协议指的是对象必须提供一个next方法,执行该方法要么返回迭代中的下一项,要么就引起一个StopIteration异常,以终止迭代 (只能往后走不能往前退) 2. ...
随机推荐
- 移动 云MAS 发短信 .net HTTP 请求
本人开发移动云MAS .net Http 请求 代码如下 using Newtonsoft.Json.Linq; using System; using System.Collections.Gen ...
- 【ASP.NET MVC】MVC概述
描述 本篇文章主要概述ASP.NET MVC,具体包括如下内容: 1.MVC模式概述 2.WebForm概述 3.WebForm与MVC区别 4.ASP.NET MVC发展历程 5.运用程序结构 6. ...
- jersey框架实现文件上传
jersey框架是一个开源的RESTful的框架,实现了实现了JAX-RS规范,进一步地简化 RESTful service 和 client 开发.当然而且是必须的,jersey对文件的上传和下载也 ...
- Python之Metaclass详解,Python之元类
本人Java程序员一枚,这几天闲来无事就自学了下Python,学到Metaclass感觉有点迷惑,就在网上查相关资料,在栈溢出(stackoverflow)网站上看到一个关于metaclass的回答, ...
- 【java】控制台实现贪吃蛇小游戏-LinkedList、Scanner
package com.myproj.snake; public class Node { private int i,j; public Node(){} public Node(int i, in ...
- Python网络爬虫与信息提取(二)—— BeautifulSoup
BeautifulSoup官方介绍: Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式. 官方 ...
- scala-Future和Promise
首先说明同步与异步,阻塞与非阻塞的问题: Asynchronous vs. Synchronous A method call is considered synchronous if the cal ...
- 使用Libmicrohttpd搭建内嵌(本地)服务器
Libmicrohttpd简介 GNU Libmicrohttpd是一个用来在项目中内嵌http服务器的C语言库,它具有以下几个非常鲜明的特点: C语言库,小而快. API非常简单,且都是可重入的. ...
- geoserver安装部署步骤
方式一:直接在geoserver官网下载zip源代码解压包,直接部署在tomcat里面运行geoserver: 方式二:下载安装包方式 以GeoServer2.8.5版本为准,安装之前必须要保证你机子 ...
- centOS7 jdk安装
1.查找需要卸载的OpenJDK: # rpm -qa | grep java 2:依次卸载 rpm -e --nodeps javapackages-tools-3.4.1-6.el7_0.noa ...